

コアの実行効率を高めたZen 4のアーキテクチャー詳細 AMD CPUロードマップ
ASCII.jp / 2022年10月3日 12時0分

9月30日より、Ryzen 7000シリーズの店頭発売が開始された。いきなりAMDマニアの林先生がTSUKUMOeX.の店頭に並んでいてさすがと思った、という話は置いておいて……。
すでにKTU氏による性能ベンチマークが公開されているので、その性能と消費電力の評価結果は記事をお読みいただければと思う。大雑把にまとめると、「性能も上がったが消費電力も上がった」というあたりである。
消費電力の方は、1つにはチップセット(X670Eの場合、2チップ構成になっている)が理由でもあるが、基本的には5nmプロセスを省電力化に振るのではなく、動作周波数向上の方に振ったのが最大の要因であろう。
一方の性能の方だが、これが以前説明したよりも、もう少し踏み込んだ情報が説明されたので、このあたりを今回説明しよう。まずZen~Zen 4の変遷をまとめたのが下の画像だ。

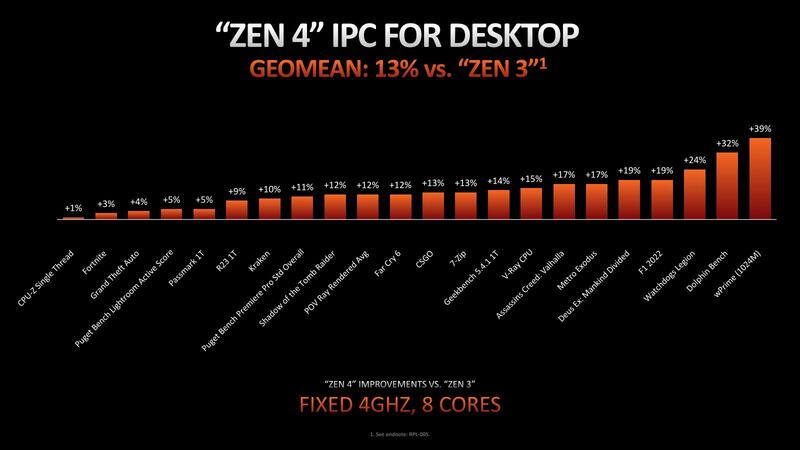
Zen 4では13%のIPC向上、と説明されているが、その内訳はこれまで明らかにされてこなかった。さてその内訳であるが、Zen 4のマイクロアーキテクチャーが下の画像だ。
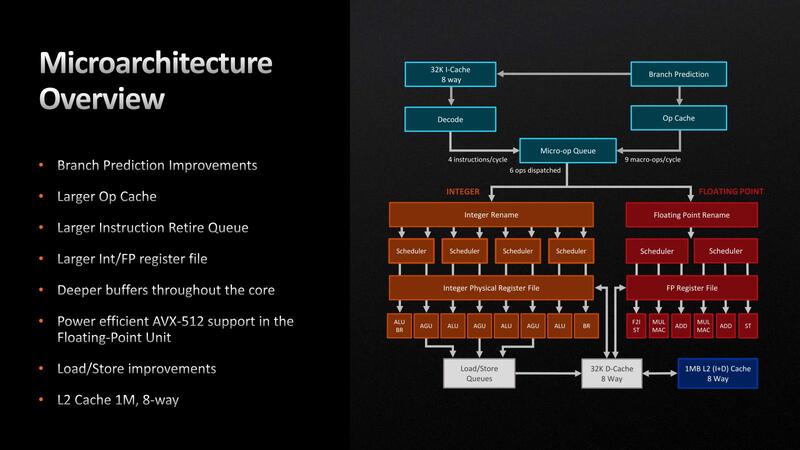
ちなみにZen 3のマイクロアーキテクチャーが下の画像である。見比べてみると、実は実行ユニットの数などはまったく同じで、デコード段は4命令/cycleの速度でx86命令を解釈するのも、Dispatch Unitからは最大6命令/サイクルで発行されるのも同じである。
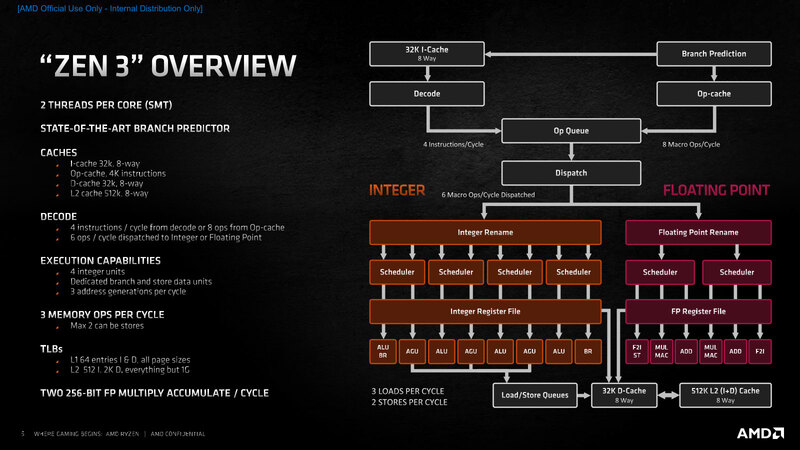
スケジューラーの入り方もZen 3とZen 4はまったく同じである。ただ実はここにも少し書いてあるが、Op CacheからMicro-op Queueへの帯域が、Zen 3の8 MacroOps/サイクルからZen 4では9 MacroOps/サイクルに増強されている。
要するに8 MacroOps/サイクルの命令供給では、依存関係を解消しての6命令同時発行を十分に生かし切れておらず、この効率向上を目的としたものと考えられる。
もう少し細かく見てみよう。まずフロントエンドだが、基本的な構成は変わらないものの以下のような変更点がある。
- Op Cacheが4K Opsから6.75K Opsと大幅に増量され、かつOp CacheからMicro-op Queueへの帯域が8 Ops/cycle→9 Ops/cycleに拡大された。
- 分岐予測に利用するBTB(Branch Target Buffer)が、L1が2×1K Entry→2×1.5K Entryに、L2が2×6.5K Entry→2×7K Entryにそれぞれ大型化された。
BTBが2×なのは、Zenでは同時に2スレッドを実行できるから、それぞれのスレッド用に別々のBTBが用意されるためである。BTBに限らずキャッシュ類は一般に、大型化するとそれだけHit率が上がる(=BTBなら正しく飛び先を認識しやすい)一方で、大型化の弊害としてレイテンシーが増えやすい(大きくなると、それだけテーブルを全件検索するのに時間がかかる)という弊害もあるが、おそらくこの程度では目立って遅くはならないだろう。
ただBTBも構造的にはキャッシュやRegister Fileと同じくSRAMで構成されるから、大型化するとそれだけエリアサイズを喰ってしまう。このあたりはZen 3→Zen 4でプロセスを微細化したことで、多少ゆとりができたことで実現したと考えられる。といったあたりだ。ちなみに“Predict 2 taken branches per cycle”そのものはZen 3の時点ですでに実現されている。
レジスターを増やしてスケジューラーの待機時間を減らす
次がバックエンド。こちらは構造的には大きな違いはないが、以下が異なる。
- 整数レジスターは160→192に、浮動小数点レジスターは256→320にそれぞれ増量
- ROB(Re-Order Buffer)は256→320に増量
- FPUはAVX512FとVNNIをサポート
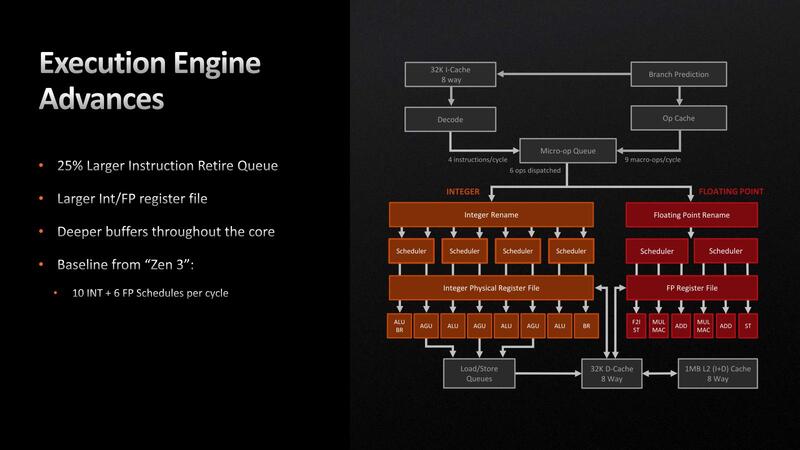
レジスターの増量は、In-Flight(命令を実行可能状態にして、実行ユニットが空くのを待つ状態:実行中の命令もここには含まれる)できる命令数を増やすことが可能になる。レジスターが一杯だと、In-Flight状態として登録できないからだ。
スケジューラーのエントリー数そのものは増えていないが、レジスターを増やしたということは、これまではレジスター数がネックになってスケジューラーがフルに活用できていなかったということと思われる。
ROBの増量もこれと同じである。ROBは命令を実行し終わった後で、その後処理を完了するまで保持をするためのものである。アウト・オブ・オーダーの場合、必ずしも命令の実行順序はプログラムの実行順序とは限らず、しかもある処理結果を別の命令で利用したりする。
あと、結果をメモリーに書き出したりする場合もあるので、それを書き出し終わる(書き出しには時間がかかる)までは命令完了とならない。そこで実行はしたけど完了していない命令を保持するのがROBである。これがあふれると、それ以上命令を実行できなくなるのでパイプラインが一時的に停まることになる。ROBを増やすことで、こうした状況に陥る確率を減らせるわけだ。
それと大きな違いはFPUの構成である。初代Zenの世代でFPUが非対称構成になっており、本来4つのFPUを全部連動させれば256bitのSIMD演算が可能(初代はSSEのみの対応で、256bit幅のAVXは未対応だった)はずながら、FP3がFP1と異なる構成になっている関係で連動できない、という妙な設計思想だった。

以前この件でAMDのどなたか(誰に聞いたのかは忘れてしまった)に質問したのだが「いやリソースを最適化した結果こうなった」という、あまり明確でない返事が戻ってきた記憶がある。その後、Zen 2でFPUの幅は倍増し、AVXに対応したが、相変わらず非対称構成は変わらずであり、これはZen 3にも引き継がれた。
まだ筆者はZen 4のFPUの構成を確認できてはいないのだが、2組4つのFPUが連動して動作するようになったことでAVX512F(F:Fundamental AVX512の基本的な命令セット)をサポートできるようになったということから考えると、やっとFP1とFP3が対称構成となったのではないかと考えられる。
加えてこのFPUではVNNIのサポートも追加された。VNNIはCascade Lake世代のXeonで搭載されたAVX512の拡張命令で、元はIntel DL Boost(Intel Deep Learning Boost)という名前で説明されていた。実をいうとVNNIは、当初AVX512の拡張として提供され始めたが、これをAVX2にバックポートしたAVX2 VNNIという命令セットも存在している。
VNNIは要するに畳み込み演算を高速に行なうもので、例えば積和演算はAVX512Fならば、
VPMADDUBSW(Multiply and Add Packed Signed and Unsigned Bytes) VPMADDWD(Multiply and Add Packed Integers) VPADDD(Add Packed Integers)
この3つの命令を順番に実行することで実現できるが、これをVPDPBUSD(Multiply and Add Unsigned and Signed Bytes) という1つの命令で代替できる。単純に命令数で数えても3分の1になるわけで、これによってAI処理に付き物の畳み込み演算を高速化できる、というものだ。
これを利用することでAI/機械学習処理をAVX512ベースで高速に処理できるという謳い文句であるが、正直言うとインテルがAlder LakeでAVX512そのもののサポートを外しており、AVX2 VNNIのみなので、サーバー向けはともかくコンシューマー向けにAVX512-VNNIを利用したAIアプリケーションがどの程度出てくるのか? はちょっと不明確である。
もちろんZen 4コアはRyzen 7000シリーズだけでなくGenoaベースのEPYCでも利用されるから、こちらで活用の余地はあるとは思うのだが、コンシューマー向けとしてはあまり期待しない方が良いかもしれない。
ただ、Skylake以降の世代で、AVX-512の動作にはペナルティーがあった(AVX512の連続動作をかける場合、最大動作周波数をやや下げる必要がある)のに対し、はっきりと“No frequency impact”と断じているあたりは、絶対性能よりも性能/消費電力比を取った構成と考えられる。
※お詫びと訂正:記事初出時、Alder Lakeに関する記載で一部誤りがありました。記事を訂正してお詫びします。(2022年10月8日)
2次キャシュを倍増
最後がロード/ストアーユニットである。基本的にはこちらもZen 3のままから変わっていないが、Load Queueが72 Entryから88 Entryに強化されているのが違いとなる。また、L2 Data TLBが2K Entryから3K Entryに強化されている。
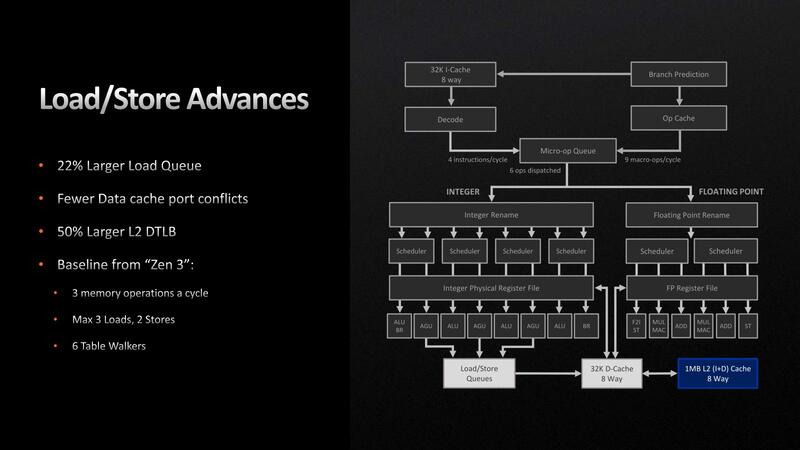
“Fewer Data cache port conflicts”に関しては詳細な説明がなかったが、よりポート同士の競合が少なくなるような工夫が施された模様だ。
パイプライン外部で言えば、L2が512KBから1MBに増量された。単に増量されただけでなく、同時に多くのoutstanding miss(Cache Missが発生し、L2ならL3に、L3ならメモリーにそれぞれCache Fillを要求する動作のこと:これが同時に多発した場合、Cache Fillが解決するまでキャッシュそのもののアクセスが止まることになる)を扱えるようになったとしている。
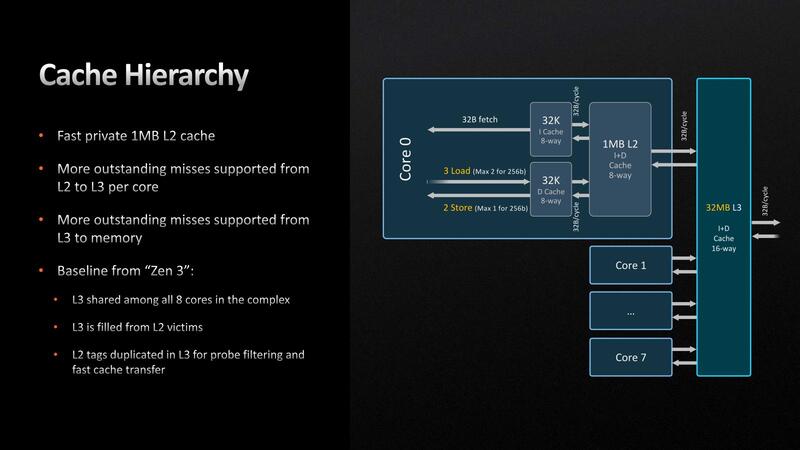
ちなみにこの代償として
L2 Latency 12サイクル→14サイクル L3 Latency 46サイクル→50サイクル
と微妙にCache Accessのレイテンシーが増えてしまっているが、そもそもL2を倍増した時点である程度レイテンシーが増えるのは避けられないわけで、このあたりはバーターということになるだろう。
以上簡単にZen 4の内部構造の違いを紹介してきたが、まとめれば「Zen 3の4 x86命令/サイクルのコアの実行効率を、さらに高めた」ということになる。5 x86命令/サイクルはZen 5以降までお預けで、それ以前にまだ4 x86命令/サイクルでやれることがあり、それを全部実装したという感じになっている。
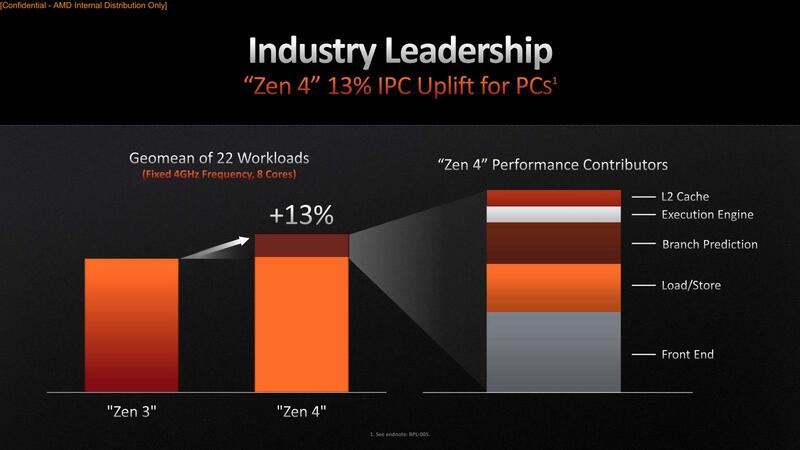
実際IPCの比較で言えば平均して13%程の向上とされるが、そのIPCの増分の内訳が下の画像だ。最大のものはフロントエンドで、ついでロード/ストアー、Branch Predictrionときて、Execution Unitの改良やL2キャッシュの増量などは一応効果がないわけではないが、フロントエンドに比べるとその効果はわずかである。それだけフロントエンド周りの改良が大きかった、というわけだ。
ちなみにAVX-512周りの性能比較が下の画像だ。ONNX Runtime Performanceで1.3倍~2.5倍とされる。

もちろんこれは大きな性能向上ではあるのだが、そもそも元のRyzen 5000シリーズでの性能が低い事を考えると、確かに性能は向上したとは言えどの程度使えるのか、というのは微妙な線だ。まぁそのあたりが判っているから、Zen 5ではXDNAとしてAI Engineを統合することにしたのであろう。
Zen 4世代ではもう1つ大きな違いとして、GPUコアの統合が挙げられる。これはCCDではなくIODの方に統合される形である。

その内部だが2CU、つまり1 WGP構成である。要するにRDNA 2の最小構成である。またディスクリートのRDNA 2製品と異なり、以下のようになっている。
- インフィニティ・キャッシュは搭載されない
- レイトレーシング・エンジンも搭載されない

本当にデスクトップの表示には十分だが、これでゲームをやるのは厳しい程度と考えておけば良いだろう。ということで駆け足であるが、まずはZen 4の内部構造をお届けした。まだRyzen 7000シリーズでは説明すべきことがあるのだが、それは別の記事で。

この記事に関連するニュース
-
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分
-
G-Tune、 Ryzen 7 9800X3D搭載モデル発売 - Zen 5ベースのゲーマー向けプロセッサ
マイナビニュース / 2024年11月15日 13時33分
-
【FRONTIER】 AMDの最新プロセッサ「Ryzen 7 9800X3D」を搭載したデスクトップパソコンの販売を11月15日(金)午前11時より開始
PR TIMES / 2024年11月15日 13時15分
-
相変わらずゲームシーンでは“チート級”の実力 11月15日発売の高コスパCPU「Ryzen 7 9800X3D」(約8.7万円)を試して分かったこと
ITmedia PC USER / 2024年11月6日 23時5分
-
Ryzen 7 9800X3Dを試す - ゲーミングCPUの本命か? 第2世代3D V-Cacheの威力を徹底検証
マイナビニュース / 2024年11月6日 23時0分
ランキング
-
1【最新】Wi-Fiルーターだけはいいものを買え、今ならこれでキマリだ
ASCII.jp / 2024年11月23日 17時0分
-
2Switchで遊べるヴァンサバ系ゲーム5選!強化しまくって大量の敵を一掃する「俺TUEEE!」が超気持ちいい
インサイド / 2024年11月23日 15時0分
-
3普段は塩対応の柴犬に大好きな人が会いに来たら……? 別犬のような喜び方が270万再生を突破「お散歩ってワードにも、それで頼む」
ねとらぼ / 2024年11月23日 7時0分
-
4プロが教える「PCをオフにする時はシャットダウンとスリープ、どっちがいいの?」 理想の選択肢は意外にも…… 「有益な情報ありがとう」「感動しました
ねとらぼ / 2024年11月20日 22時0分
-
5「しぬwww」「怖すぎ」 かわいいカメを“絵文字ミックス”したら…… 爆誕した“バケモノ”が2200万表示 衝撃ビジュアルに「笑いすぎて涙」
ねとらぼ / 2024年11月23日 20時20分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





