

2024年に提供開始となるSF3プロセスの詳細 サムスン 半導体ロードマップ
ASCII.jp / 2023年7月17日 12時0分

前回に引き続き、2023 Symposium on VLSI Technology and Circuitの内容をお伝えする。
Samsungはロジック回路周りだけでもSF3プロセスの詳細(*1)とSF4Xプロセスの詳細(*2)や、BS-PDNの実装(*3)、そのBS-PDNに利用されるViaに関する分析(*4)と4件もの発表を行なっている。今回はそのうち、冒頭のSF3プロセスの詳細について説明しよう。

(*1) T1-2:World's First GAA 3nm Foundry Platform Technology (SF3) with Novel Multi-Bridge-Channel-FET (MBCFET) Process (*2) T16-3:Highly Reliable/Manufacturable 4nm FinFET Platform Technology (SF4X) for HPC Application with Dual-CPP/HP-HD Standard Cells (*3) T4-1:Breakthrough Design Technology Co-Optimization Using BSPDN and Standard Cell Variants for Maximizing Block Level PPA (*4) TFS2-5:Structural Reliability and Performance Analysis of Backside PDN
Samsungのロードマップ推移
そもそもSamsungのプロセスロードマップを取り上げるのがひさびさ(前回は2017年の連載418回だった)ので、アップデートも兼ねてまずロードマップ全般について。
2017年の時には14nmに加え、10nm(10LPE/10LPP)を量産開始し、その微細化版である8LPPを追加。一方最初のEUVを利用した7nmの7LPPの後に、6LPPを追加するというあたりまでを説明した。
そのSamsungの2018年におけるロードマップが下の画像だ。2017年には、4nm世代でGAAを導入するという話だったのが、一世代ずれて3nm世代に移行。4nm世代は5nm世代の改良版のFinFETプロセスのままという形になった。
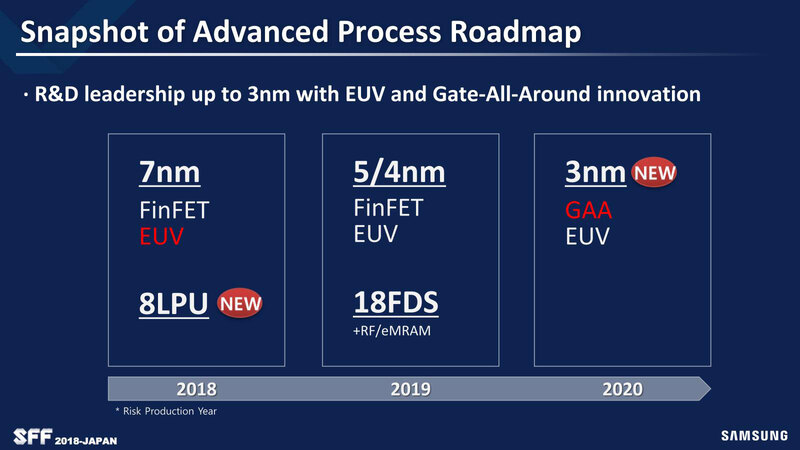
この当時の説明は「4nmはGAA(Gate All Around)を使わなくても実現できる目途が立った」とのことだったが、要するにまだこの当時はGAAの技術的難易度が高かったので1年先送りした、という形だろう。2018年10月に開催されたArm TechConの際に開示されたロードマップは下の画像のようになっていた。
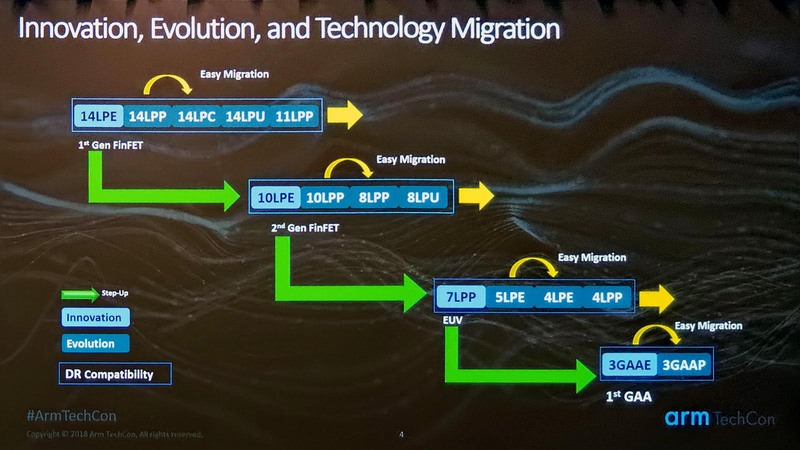
これが2019年になるとどう変わったか? というのが下の画像である。7LPPからすぐに5LPEに移るのではなく、6LPPが追加になった。また4LPPがラインナップから消えている。逆に3nmに関しては特に変更はない。

2020年はCovid-19の影響などもあってSFF(Samsung Foundry Forum)が開催されず、そのため特にロードマップの開示もないが、この2020年は大きな変更はなく、4LPEをやるかどうか怪しいといった話が漏れ伝わってきた程度だ。
このロードマップが更新されたのは2021年である。SFFがオンラインで開催され、ここでいくつか更新があった。最大のものは4LPPが復活したことと、3GAPの後に2GAPが明示されたことだろう。
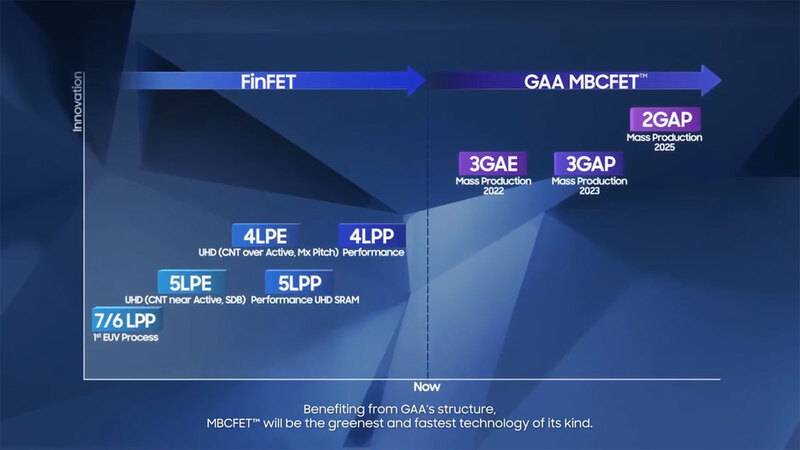
そして2022年であるが、6月末に3GAEプロセスの量産開始が公式に発表された。もっともこれは、当初は歩留まりが10%台というすさまじい数字だったらしいが、その後の改良も目覚ましく年末には40%まで達したらしい。
いや40%で満足してしまってはまずい気もしなくはないのだが、もともと3GAEは“3nm GAA Early”という、いわばGAAの評価用とでもいうべき最初のプロセスで、顧客の量産は次の3GAP(3nm GAA Performance)で手掛ける予定になっていたので、これは大きな問題ではないともいえる。
その2022年の10月にSFF 2022が開催されたが、ここで示された新しいロードマップが下の画像だ。名称が従来のものからSFxxに切り替わったのは、TSMCのプロセスなどと混乱しないように、頭にSamsung Foundryの頭文字としてSFを追加したということのようだ。
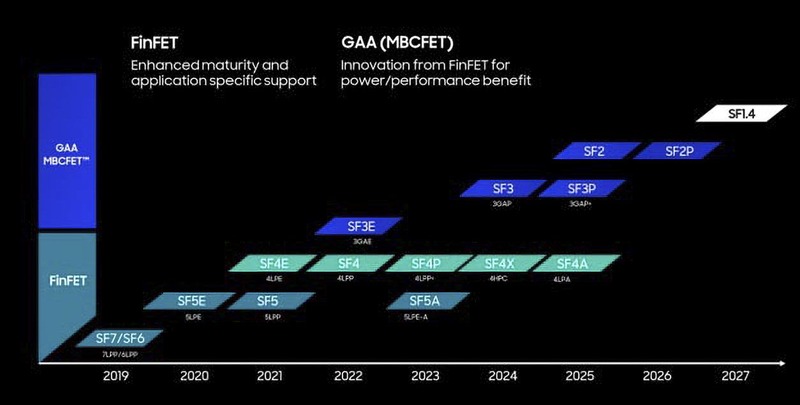
そしてプロセスであるが、まず旧3GAPであるSF3が2024年提供開始と1年後送りになり、また2025年にはSF3PというSF3/3GAPの改良版が投入されることが明示された。同じ2025年に旧2GAPがSF2として投入され、2026年にはその改良型であるSF2Pが投入されること、そして2027年には1.4nmプロセスに相当するSF1.4が投入されると明示されたことだ。
このSF3P/SP2Pの存在の公開と、2027年にSF1.4を投入という時期の公開が初めて行なわれた形になる。
ということで駆け足でここ数年のSamsungの先端ロジックのロードマップ変遷を解説し終わったところで、SF3の話に移りたい。
新技術によりリーク電流を大幅に削減
ここまで説明してきたようにSF3はGAA(Samsung用語ではMBCFET:Multi Bridge Channel FET)を採用しているが、これはインテルのRibbonFETなどと同じようにNano Sheetをゲートに使う構造になっている。この構造のメリットを端的に示したのが下の画像だ。
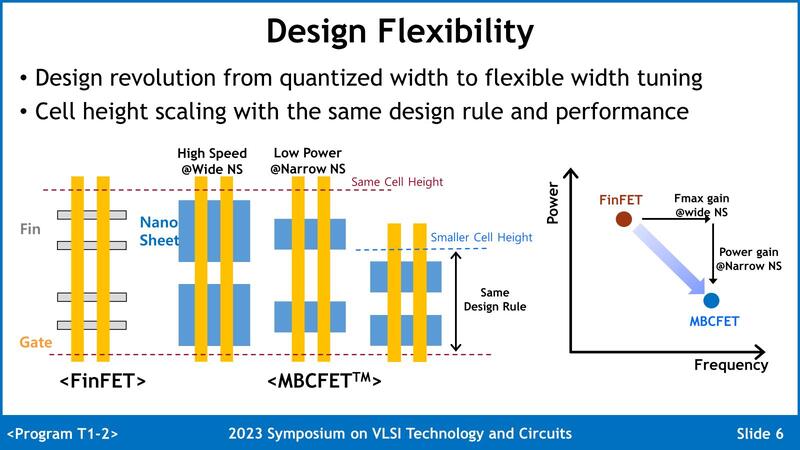
FinFETの場合、駆動電流を増やす(=高速化する)場合にはFinの数を増やすことになるが、これは底面積がそれだけ増えることになる。ところがNano Sheetの場合、Sheetを垂直方向に積み重ねる形なので、3枚重ねようが4枚重ねようが底面積は不変である。したがって同じ底面積でより高速化が可能である。
また高密度版の場合は底面積が減らせるので、それだけセルの高さを抑えられることになる。この底面積と速度の関係をまとめたのが下の画像である。
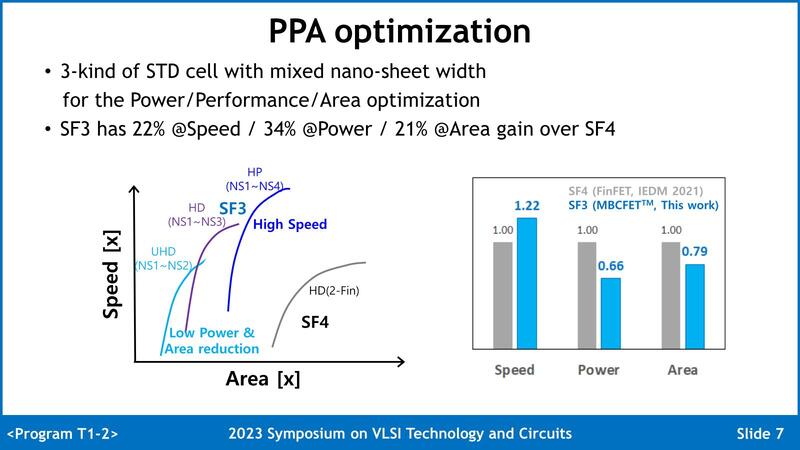
UHD(超高密度)は1~2 Sheet、HD(高密度)は1~3 Sheet、HP(高性能)は1~4 Sheetと、Sheetの枚数を増やすとそれだけ動作周波数を上げやすくなるし、FinFETと異なりゲートの周囲が完全に絶縁層で覆われている(*5)分リーク電流に起因する消費電力を削減でき、また上で述べたようにNano Sheetを垂直に積層する関係で、特に高速のトランジスタの場合には底面積削減にも貢献する。
(*5) FinFETは、Finそのものは絶縁層で覆われているが、Finの根本は絶縁層がないのでそこからのリークを止められない。
このNano Sheetの幅と特性に関する結果が下の画像だ。
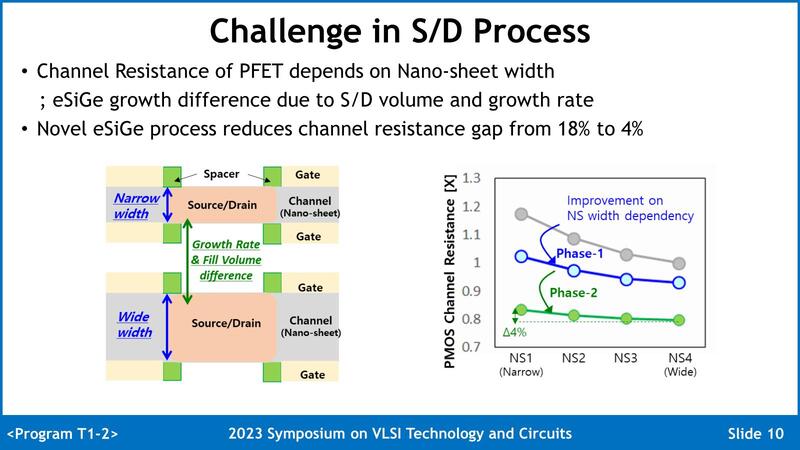
別にNano Sheetに限った話ではないが、配線の幅は広いほど抵抗値が低くなる。したがって一番狭いNS1と一番広いNS4を比較した場合はNS1が一番抵抗が高くなり、NS4が低くなることそのものは当然の原理だが、一番最初(上の画像の右グラフのグレー)では、NS4の抵抗値を1とするとNS1の抵抗値の差が18%となっていた。
ところがこれを2回(Phase-1/Phase-2)見直しを掛けて製造方法(growth rate)やソース/ドレインの比率を調整することで、最終的にNS1とNS4の抵抗値の差を4%まで縮めることに成功した、とされる。
先ほどGAAだとリーク電流が減る、という話をしたがこれに関する詳細が下の画像である。
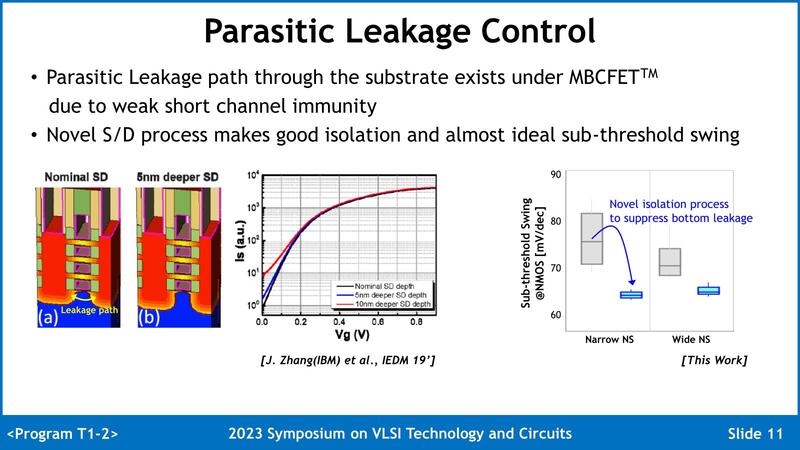
一般論としてソースとドレインの距離が近いと、ソースとドレインの間でのリークが問題になってくるが、これも新しい技術(具体的な手法は未公開)により大幅に削減した結果として、リーク電流の絶対値と、リーク電流のバラつきの幅、両方が大幅に削減されたとする。
ちなみにグレーが従来のリーク電流(の最大値と最小値、中央値)、青がSF3のものである。Wide Nano Sheetの方が若干リーク電流は多いが、それでも従来に比べると大幅削減されているのがわかる。
GAAを利用するための3つの困難とその解決策
今回の講演の中では、GAAの製造の難しさについても説明があった。
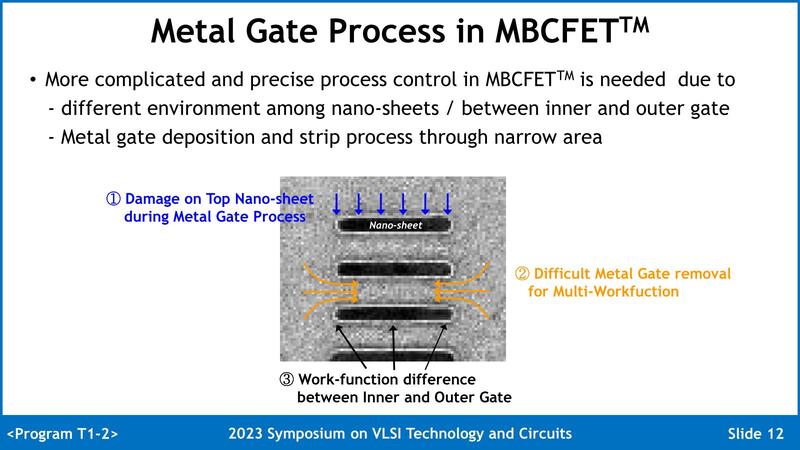
まずはトランジスタの製造後に配線層を積層するわけだが、その配線層の積層プロセスの工程が最上位のNano Sheetにダメージを与えるというもの、2つ目がSheet間のメタルゲートの削除が面倒なこと、最後がNano Sheetの幅が広くなると、両端と中央で特性が変わってきてしまうことの3つが言及された。
その問題に対する回答は、当然ながら詳細はまさにGAAを利用するためのノウハウになるので開示はされていないのだが、まず1つ目の問題は“Soft Metal Gate Removal”を利用することで、ゲートからのリーク電流をSF4と比べた場合PMOSは1.58倍だったものを0.28倍に、NMOSでは1.06倍だったものを0.43倍にできたとする。
要するに従来だと最上位のNano SheetがMetal Gate Removableで傷んでしまい、そこからのリークがけっこう多く発生したのが、これでだいぶ緩和された。またMetal Gateの製法にも改良を加えたことで、Nano Sheetの幅に起因する電圧の差も大幅に削減できたとしている。
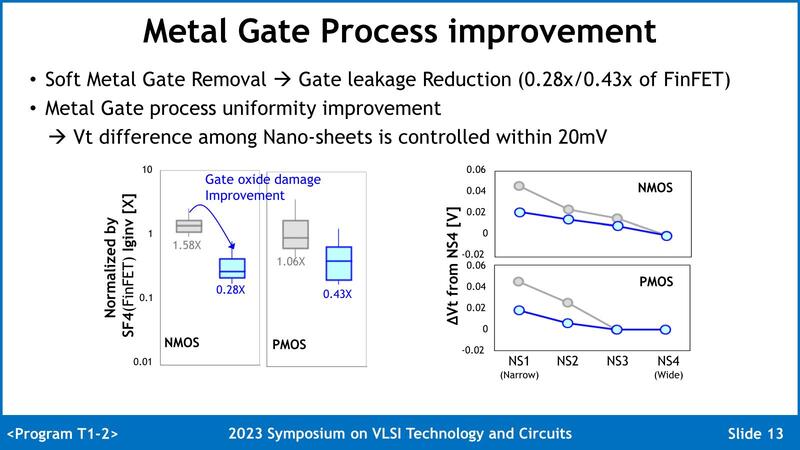
2つ目の問題については、直接的な回答ではないのだが示されたのはMOL(Middle Of Line:中間層)の製造プロセスの改良である。Metal Gateと接続するコンタクト部を、より細長い形状にするとともに、ソース/ドレインの接続部分の組成の最適化をすることで、寄生容量を5%、抵抗を23%削減したとする。
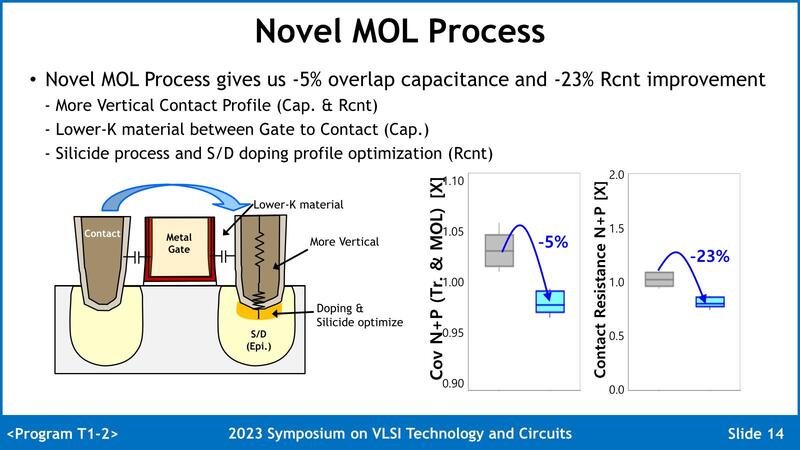
3つ目の問題はDTCO(Design Technology Co-Optimization)の採用で解決した、という。Nano Sheetの構造だけで問題を解決するのではなく、回路側の最適化と組み合わせることで対応したという話で、同じ駆動電流の場合NANDゲートで2.5%、NORゲートで4.5%の高速動作が可能になったとされる。
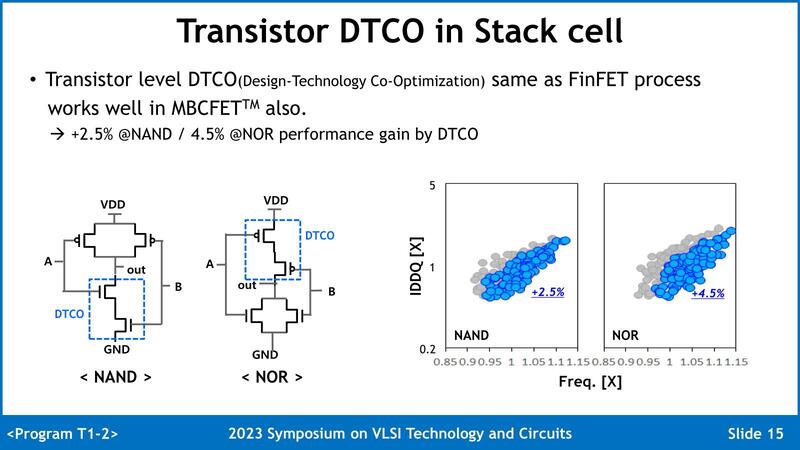
ちなみにこうした工夫の結果として、SF4と比較した場合、SF3では特性のバラつきが大きく減ったとされる。これを実現できた理由の1つはチャネルをCMPではなくエピタキシャル成長に切り替えたことがある。ただ確かに特性はそろいそうだが、CMPに比べると時間が掛かりそうな気がするのだが、そのあたりについては言及がなかった。
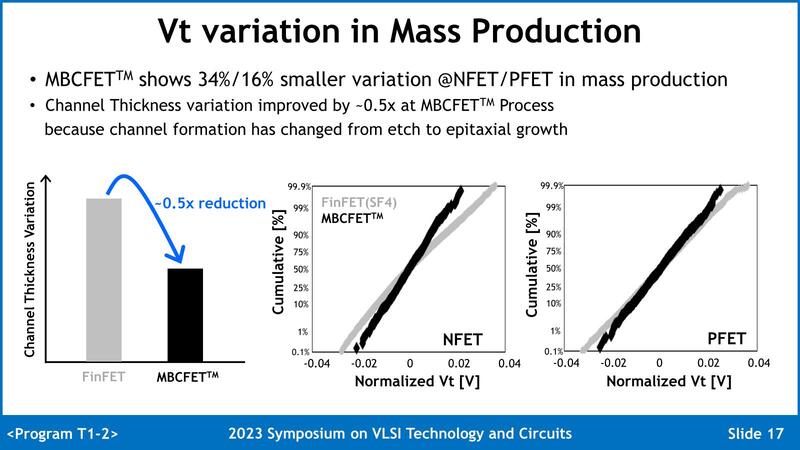
今回はこのSF3の歩留まりについては説明がなかったし、SF3Eの当初の歩留まりを考えれば、立ち上がりはやや鈍い(プロセス立ち上げ時の歩留まりが低いのは、すでにSamsungの御家芸になっている気もしなくはない)とは思うが、それでも技術的な完成度にはそれなりの自信を感じさせる。
ちなみに今回説明はしないが、T4-1の結論は、BS-PDNを使うことで動作周波数を3.6%向上させ、一方でブロックレベルでのエリアサイズを14.8%削減できるとしている。
動作周波数が上がるのは電流供給能力が改善したことに起因する話で、エリアサイズ削減は電源層を裏面に追いやれることで配線層にゆとりが生まれたためだろう。
インテルはこのBS-PDNをIntel 20AプロセスでGAAと一緒に導入する予定だが、Samsungはより確実性を狙ってかSF3にはBS-PDNは導入しないようだ。ただSF3Pなどは、ひょっとするとSF3+BS-PDNかもしれない。あとは顧客が付くかどうかがSamsungにとって最大の問題かもしれない。

この記事に関連するニュース
-
「遅い」のに高効率な情報処理技術を開発
共同通信PRワイヤー / 2024年11月28日 14時0分
-
【千葉工業大学】スパイキングニューラルネットワークによるテンポラルコーディングの実現
PR TIMES / 2024年11月27日 18時15分
-
米エネルギー省、産業部門の環境対応・競争力強化へロードマップ発表(米国)
ジェトロ・ビジネス短信 / 2024年11月20日 13時25分
-
オンセミ、業界最先端のアナログおよびミックスドシグナル・プラットフォームを発表
PR TIMES / 2024年11月13日 15時40分
-
スマホ、ウェアラブル機器向け1セルバッテリー保護IC「S-821A/S-821Bシリーズ」発売
@Press / 2024年10月31日 10時0分
ランキング
-
1LINEアルバム、他人の写真が誤表示される不具合で続報 「30日午前には解消予定」 Android版はアップデートを
ITmedia NEWS / 2024年11月29日 18時51分
-
2イオンカード、不正利用に関するNHK報道を受け声明 「1日も速く調査結果を報告できるようにする」
ITmedia NEWS / 2024年11月29日 16時52分
-
3NHKのネット受信契約(案)が“ダークパターン”過ぎて見過ごせない件(前編) NHKの見解は?
ITmedia NEWS / 2024年11月28日 19時9分
-
4“年利実質18%”で話題、ヤマダ積立のページが閲覧できない状態に 今後の方針、同社に聞いた
ITmedia NEWS / 2024年11月29日 19時35分
-
5“セクシー女優”が「明日花キララから詐欺にあった」と主張→“虚偽”認め謝罪 「多大なご迷惑」「誠に申し訳ございません」
ねとらぼ / 2024年11月29日 19時46分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





