

マイクロソフトが「OpenAI」に巨額を投じる理由
ASCII.jp / 2023年1月24日 18時0分


1月初旬、マイクロソフトがチャットボットAI「ChatGPT」や画像生成AI「Dall-E2」の開発で有名なOpenAIに100億ドル(約1兆2800億円)の投資をする可能性が報じられました。1月24日には同社から継続投資に関する発表もありましたが、報じられた金額の大きさに驚いた方も多いのではないかと思われます。
https://www.bloomberg.co.jp/news/articles/2023-01-23/ROXZ7KDWX2PT01
今回の記事ではマイクロソフトが今回のような巨額投資をする程にOpenAI、ひいては「AI技術への期待値をなぜ今抱いているのか?」を理解するために、「現状のAI発展トレンドを俯瞰する」ことで考えてみたいと思います。
結論から言えば、マイクロソフトはOpenAIとの関わりの中で、「指示待ち人間レベル(≒proto-AGI)の知能がほんの数年以内に実現し、現状のAI技術は控えめに言っても産業革命レベルの技術になる」ことを確信したものと思われます。
次世代のAIは「指示待ち人間レベル」になる
ここでproto-AGIという言葉は掲示板型ソーシャルニュースサイトRedditにて2021年11月頃使われ始めた言葉で、「機能が広いドメインに分散しているコンピューター システムまたはモデル」として定義されています。
https://www.reddit.com/r/singularity/comments/uaj496/we_are_very_close_to_protoagi_in_fact_it_may_be_a/
大まかに言えば、マルチモーダル(言語、音、映像、アクションと言った幅広いドメイン)でそこそこ広いタスクを実用的にこなせるAIと言えるでしょう。
しかし、AGI(汎用人工知能)というにはすべてのタスクで人間レベルには至っていない(自己改善能力はないなど)という意味で、AGI未満の知能と言えます。よって、proto-AGIはある特定のタスクのみをこなすAI(狭いAI)と人間レベルの知能を真に持つ(定義は難しいですが)AGIの中間に位置する知能ということができるでしょう。
個人的にはproto-AGIは指示されたことについてはそこそこ何でもやってくれるが、自己改善能力などは無い知能とほぼ同義だと考えているため、「指示待ち人間レベル」という表現を使わせていただいています。
2022年夏ごろからジェネレーティブAIが急速に発展した
AIトレンドに敏感な方ならご存知のように、2022年夏頃からジェネレーティブAI(生成AI)と呼ばれる技術の発展と実装が急速に展開しています。
ジェネレーティブAIの定義は、ガートナーが発表した2022年のテクノロジートレンドに遡ると「コンテンツやモノについてデータから学習し、それを使用して創造的かつ現実的な、まったく新しいアウトプットを生み出す機械学習手法」。
https://www.gartner.co.jp/ja/articles/5-impactful-technologies-from-the-gartner-emerging-technologies-and-trends-impact-radar-for-2022
ジェネレーティブAIは、
- 画像(Stable diffusion)
- テキスト(ChatGPT)
- ソフトウェアコード(Copilot)
- 動画(Phenaki)、音楽(Mubert)
- 音声(VALL-E)
- 3Dオブジェクト(DreamFusion)
など、さまざまな種類の新規コンテンツを生成可能で、その応用先も応用サービスの数も爆発的に増えている状況です。
ASCIIの記事でも以下順に、画像生成AIとChatGPT(チャットボット)について紹介がされています。
https://ascii.jp/elem/000/004/107/4107997/ https://ascii.jp/elem/000/004/120/4120502/
AIツールは同時的に進化している
メディアやSNSでは主に前述したジェネレーティブAIの状況が取りざたされることが多くなっていますが、他にも今後、世界の産業構造を変えるタネとなるようなAI技術が多く発表されています。特に進展が著しいのが「マルチモーダルAI」です。
- 視覚言語モデル(Flamingo、PaLI)
- 映像基盤モデル(VideoCoca,、lavender、InternVideo)
- 自然言語で指示可能なロボット(Saycan、RT-1、VIMA)
- 様々なゲームやロボット操作や対話も可能なGenerarlist Agenet Gato
など複数ドメインにまたがった幅広いタスクを実行できるAIのことで、2022年から技術開発が盛んになってきています。
一方で自然言語処理も躍進を続けており、たとえばグーグルの開発したMed-PaLMは前者は臨床医に肉薄する専門的な回答ができるようになり、Minervaはポーランドの全国数学試験で平均点以上をマークしました。
Med-PaLM performs encouragingly on several axes such as scientific and clinical precision, reading comprehension, recall of medical knowledge, medical reasoning and utility compared to Flan-PaLM. pic.twitter.com/syExjsIsqO
— Vivek Natarajan (@vivnat) December 27, 2022
🦉 achieves: 1) 50% acc on the challenging MATH dataset which consists of competition math problems! 2) 65% acc in 2022 Poland’s National Math Exam which is more than the national average! 3) 30% acc on “undergrad” problems in physics, biology, chemistry, economics, etc. 2/ pic.twitter.com/sJjEFLsLwC
— Behnam Neyshabur (@bneyshabur) June 30, 2022
科学支援AIツールも発展してきていて、
- Alphatensor(行列演算高速化)
- Alphafold(たんぱく質立体構造予測)
- Theoremprover(数学の定理証明)
- Matlantis(量子力学計算)
- Bionemo(大規模言語モデル製薬利用)
など、枚挙にいとまがありません。
ジェネレーティブAI、特にコンテンツ生成の動向のみを見ていると、「クリエイティブ領域に便利なツールが出てきたんだな」という印象になりがちです。しかし上記例を見てもわかる通り、AIトレンドは業界職種関係なく、ほとんどの人の生活や仕事に大きな影響を及ぼすものであると考えられます。
世界に衝撃を与えたOpenAIの「GPT-3」
一方で、マイクロソフトは現在のAIトレンドだけでなく、少なくとも数年先のAIトレンドを見据えてOpenAIへの投資を検討したものと推察できます。ここからは今後のAIトレンドについて、特に「言語モデル」を中心に推測していきましょう。
なぜ言語モデルかといえば、1つは言語がすべてのモーダルに共通するインターフェースになると考えているためです。また、言語モデルの能力が上がれば、他のモーダルとの連携が強化され、AIの能力も上がるものと考えられるためです。そこでOpenAIの言語モデル「GPT」シリーズに焦点を当てたいと思います。
GPTは、OpenAIが開発した「Transformer」というアルゴリズムを備えた言語モデルの一種です。自然言語文を言語モデルに入力すると、次に入るだろう文章を予測して多様な返答を出力します。OpenAIは2019年に「GPT-2」、2020年に「GPT-3」というバージョンをそれぞれリリースしてきました。パラメーター数は、GPT-2が15億、GPT3が1750億(大規模言語モデル)となっています。
GPT-2はフェイクニュース作成に利用される恐れから、モデル公開が一時中止されたことなどが話題になりましたが、GPT-3はモデルの規模と学習データ量を拡大することでその能力を飛躍させています。会話だけでなく、翻訳、コード生成、質問応答、要約などの幅広いタスクを、GPT-2以上の性能で実行可能になりました。
GPTシリーズが出る前まで、自然言語処理の分野では基本的に、大量の教師なしデータで事前学習をしておいて、やりたいタスク(分類、翻訳、要約など)に応じて微調整(再学習)をする必要がありました。
しかし、GPTシリーズでは「one-shot,few-shot learning」と呼ばれる、質問や回答例を直接言語モデルに入力するだけで様々なタスクができるようになりました。具体的なGPT-3の衝撃を知るには以下の記事や、GPT-3使用例が参考になるでしょう。
https://deeplearning.hatenablog.com/entry/gpt3 https://airtable.com/shrndwzEx01al2jHM/tblYMAiGeDLXe35jC
この大規模言語モデルの衝撃は「GPT-3以前・以後」で分けられるほど強いものでした。このトレンドは2021年に、Bommasaniらのスタンフォード大学のワーキンググループに「基盤モデル(foundation model)」と命名されています。
https://trail.t.u-tokyo.ac.jp/ja/blog/22-12-01-foundation-model/
計算リソースとデータ量が増えるほど性能が上がる「Scaling Law」
それでは今後、言語モデルの性能をGPT-3以上にどこまで伸ばしていけるのかを考えたいと思います。結論から言えば、2023年以降に開発される言語モデルはGPT-3と同等の驚きをもたらす可能性が高いでしょう(※ただし新モデルは「GPT-4」とは限らず、また2023年内に一般に提供されるとも限りません)。
性能の外挿推定に使用したのは「Scaling Law(スケーリング則)」と呼ばれる法則。簡単に言えば、大規模言語モデルに関してデータ量とそのモデルのパラメータ数を同程度に増やしていけば、性能もべき乗的に上がっていくという法則です。
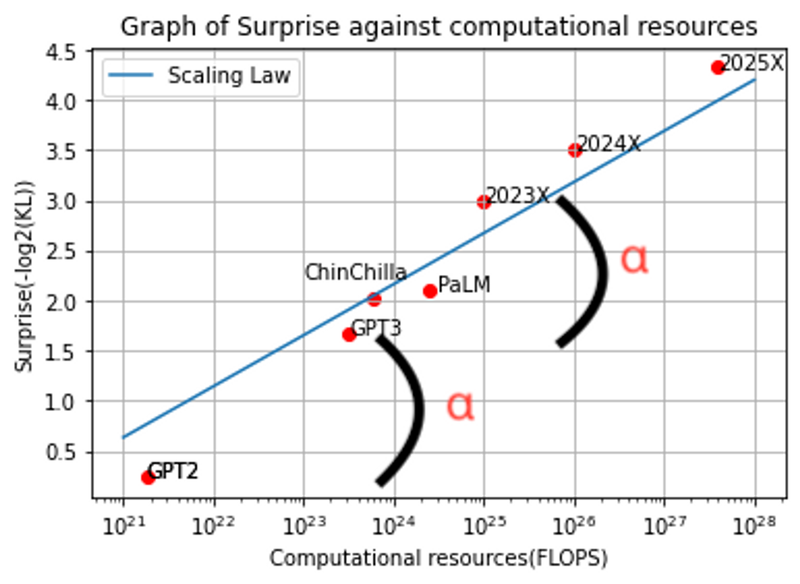
図の横軸は言語モデルの学習に費やした計算量を意味します。データ量とパラメータ数が増えるほど学習に必要な計算量FLOPSが増大し、それに伴い「Surprise」と定義される、性能に対するある種の「驚き」が上がることになります。
以下言語モデルの性能を未来に外挿した拙著考察記事となりますので詳しく知りたい方はこちらをご覧ください。 https://futurist.cross-community.net/2023/01/01/estimate-ai-language-skills/
もしScaling Lawを用いた言語モデル性能の外挿推定が正しければ、感覚的にはもう多くの人は言語処理でできるタスクなら、指示したらほとんど人間レベルにこなしてくれると感じる可能性が高いと思われます。
すでにChatGPTは多くの人を驚かせる言語処理能力を保持していますが、まだ時折トンチンカンな推論をすることもあります(「幻覚(ハルシネーション)」と呼ばれています)。しかし、そうした欠点は学習データ量とパラメータ数の拡大によって目立たなくなるでしょう。
言語モデルの性能を上げる方法は他にもある
また、今年1月には、幻覚を低減させる手法として、ドキュメントやデータベース、プログラムや電卓など外部のツールや知識を利用する手法も注目されました。言語モデルを外部のツールや知識に接続するための「LangChain」「GPT-Index」といったツールも普及を始めているため、幻覚は徐々に目立たなくなるでしょう。
https://langchain.readthedocs.io/en/latest/ https://gpt-index.readthedocs.io/en/latest/guides/index_guide.html
さらに、人間の好みにあった出力をするように言語モデルを強化学習することも可能になってきています。強化学習を施された言語モデル「InstructGPT」は、13億パラメータにも関わらず、1750億パラメータのGPT-3よりもはるかに人間好みの文を出力するという結果を今年の1月に発表しました。他の自然言語処理タスクについても、パラメーター低下の影響は最小限だとしています。
https://openai.com/blog/instruction-following/
言語モデルの能力を大幅に高める方法は他にも、
- CoT(思考の連鎖:ステップバイステップで考えましょうとプロンプトで命令)
- Self-consistency(複数解答を生成して多数決)
といったメジャーな手法を始めとして、多数発見され続けています。
このように、言語モデルは単純に計算リソースを上げること以外にも、様々な手法によって性能を改善することが可能になっています。AIや機械学習関連の論文自体、毎日100本以上が発表されると推定されているため、上記のような改善手法はこれからも多く出てくると考えられます。
AI分野での発展は加速し続けている。この論文の図1によれば、人工知能(AI)や機械学習(ML)の分野では、月あたりの論文数が約23ヶ月ごとに倍になってきており、指数関数的に増加してきた。今では毎月4000本ペース?https://t.co/0r4guYamJopic.twitter.com/14DT6qwrDg
— 小猫遊りょう(たかにゃし・りょう) (@jaguring1) October 5, 2022
3年以内にそこそこ汎用的で実用的なロボットが開発される
こうした背景から、少なくとも自然言語処理においては、指示待ち人間レベル、proto-AGIレベルのAIが1年以内に開発される可能性が高いと考えられます。
また今回はあまり触れられませんでしたが、マルチモーダルAIやAIのロボティクス応用も発展が著しく、おそらく3年以内にはそこそこ汎用的で、かつ実用的に自然言語で指示命令を受けられる汎用ロボットが開発されていると思われます。
マルチモーダルAIやAIのロボティクス応用に関する予測は、現状の技術のクオリティを見ていたらそうなる感覚値があるということで、言語モデルのようには定量的な予測にはなっていません。
しかし、DeepMindの最新の強化学習手法であるAlgorithm Distillation(AD)、Dreamer V3、AdAや、OpenAIが開発したMineCraftAIのVPTは、ロボティクスに応用される技術の芽であると考えられます。また、グーグル(Saycan、Code as Policies、InstructRL、RT-1)や、エヌビディア(Peract、VIMA)、MetaAI(VIP、PGDM、StructDiffusion)は既に実際にロボティクス技術にAIを応用した基礎研究結果を出し始めています。
先述したマルチモーダルAI研究が進めばロボティクスにも応用されるでしょう。OpenAIに関しては現状ロボティクスに関する研究はほとんどしていないようですが、音、映像、言語などのマルチモーダルな基盤モデルを作成した後、ロボティクス分野に移行する算段なのではないかと個人的には踏んでいます。
現状のAIトレンドは産業革命レベルとマイクロソフトは考えているはず
このように大局的な視野でAIトレンドを見ると、マイクロソフトはOpenAIの技術が少なくとも言語というドメインでも1年以内に相当人間レベルに近い性能を持つようになることを、幹部同士での話し合いや、何らかの技術デモから確信したのではないかと考えます(ただし汎用AIではないことに注意)。
また、マルチモーダルAIの展望も近い将来にあることから、世界に対して言語というドメインを超えた影響力を持てることも期待し、現時点で大規模な投資に踏み切ったものと推定できます。
現状の生成AIの状況は様々なメディアで取り上げられていますが、どこか「クリエイティブ領域の便利ツール、またはちょっとした業務のサポートをしてくれるボット」といったニュアンスで報道されています。
しかし、マイクロソフト幹部を含めAIトップ研究機関は現状生成AIと呼ばれるムーブメント(正確には生成AIを含む現状のAIトレンド)は単なる流行ではなく、控えめに言っても産業革命レベル、そして恐らくは人類史を根本から変えるレベルの技術になるのではないかと一部考えているものと思われます。
これを読んでいる方は上記事実を信じられないかもしれません。令和の時代になっても、まだFAXを使っている会社があったり、デジタル化さえままならない企業が多く存在する時代です。AIへの印象もあまり興味のない多くの人にとっては「ちょっとおしゃべりできたり、そこそこの精度で画像認識できるくらいでしょ」という感覚値が正直なラインになっているかもしれません。
しかし様々なレポートや論文から推定するに、ちょっと便利なツールが今後出てくるといった印象を超えて、社会構造や産業構造をこれから10年でAIが大きく変えていくことが想定されます。
このような急激な変化が社会全体を良い方向に導くのか悪い方向に導くのかはひとまず置いておき、マイクロソフトの巨額投資のモチベーションを知ることで、多くの人に現状のAIトレンドがたどるだろう未来への認識と、それが及ぼす社会的影響を考えるきっかけとなればと本記事を書かせていただきました。
何か不明点等ございましたら、TwitterでAIの最新動向から中長期的な技術トレンドの展望まで発信させていただいていますのでお気軽にご連絡ください。
筆者紹介──bioshok
IoTエンジニア。大学で物理学、大学院でAIを学んだのちに個人的な趣味でAIトレンドの最新動向をTwitter/ブログ/Youtubeで発信。フューチャリストコミュニティにてAIの最新動向だけではなく、中長期技術トレンドの推定なども行なっている。Twitterアカウントは@bioshok3。

この記事に関連するニュース
-
法人向け生成AIサービス「Tachyon 生成AI」に最新の高性能LLM「Claude 3」と「Gemini」を搭載
PR TIMES / 2024年4月22日 12時15分
-
イーロン・マスク氏のLLM「Grok」、1.5更新で画像認識可能に
ITmedia NEWS / 2024年4月14日 6時53分
-
<AIトレンド通信 3月>政府がデジタル化で職を失うホワイトカラーの労働移動を支援!話題のClaude3、ChatGPTとどちらが優秀?
PR TIMES / 2024年4月13日 13時40分
-
LLMによる視覚読解技術を確立 ~グラフィカルな文書を理解する「tsuzumi」実現に向けて~
Digital PR Platform / 2024年4月12日 0時0分
-
企業用ChatGPTサービス「ChatPro」が「GPT-4 Turbo」の最新版に対応予定。GPT-4の改良版モデル。数学・コーディングでの性能が向上。
PR TIMES / 2024年4月11日 10時0分
ランキング
-
120歳未満も活動、アイドルグループに「加熱式タバコ」写り込み イベント運営「主催スタッフの私物」と釈明
ねとらぼ / 2024年5月6日 14時55分
-
2AndroidのVPN接続にDNSトラフィック漏洩する不具合、Googleは調査開始
マイナビニュース / 2024年5月6日 17時41分
-
3改札で困らないように モバイルSuicaで「オートチャージ」を設定する方法
ITmedia Mobile / 2024年5月6日 15時9分
-
4鎌倉名物「クルミッ子」の百貨店限定「ミニ缶」がめちゃくちゃかわいい! 5月7日から高島屋などで販売
ねとらぼ / 2024年5月5日 10時30分
-
5複数のAndroidアプリにパストラバーサルの脆弱性、40億回以上ダウンロード
マイナビニュース / 2024年5月6日 19時43分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





