

日本発のエッジAI向けチップ「別府」「秩父」ことAiOnIc AIプロセッサーの昨今
ASCII.jp / 2021年11月1日 12時0分

日本発のベンチャー企業に、ArchiTekという会社がある。創業は2011年であるが、実は創業メンバーはPanasonicのスピンアウト組である。実際役員構成を見ると、CFOを務める藤中達也氏以外は全員がPanasonic出身となっている。代表取締役兼CTOを務める高田周一氏にしても、40代でPanasonicを辞してArchiTekを立ち上げている。
ただArchiTek、これまであまりニュースに上がることはなかった。ASCII.jpの過去記事を探しても、2018年にさくらインターネットと協業した記事が見つかった程度である。ところが今年2月に、やっとbeppuことAiOnIcのサンプルチップが完成したリリースが出たあたりからいろいろと会社アピールを始めたようで、創業者インタビュー記事なども出てくるようになった。
もっとも肝心のAiOnIc(アイオニック、と呼ぶようだ)チップの詳細などは明らかにされておらず、ウェブページから入手できるホワイトペーパーの解説図も、今一つ内部がわからない感じになっている。
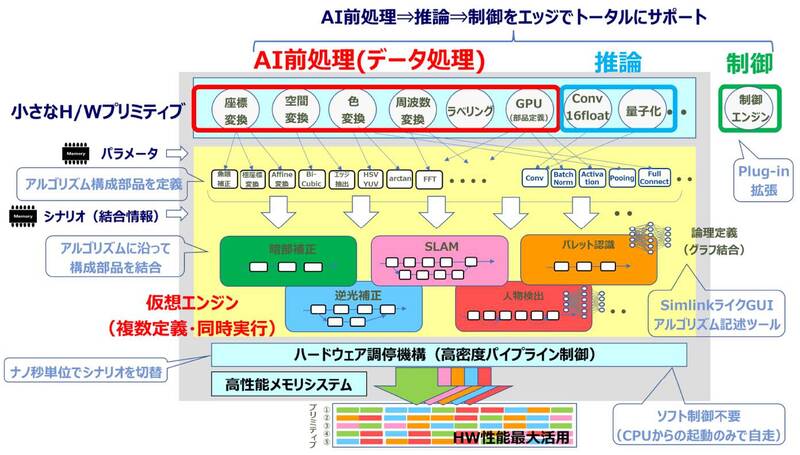
ところが今年10月20日から開催されたLinley Fall Processor Conference 2021でこのAiOnICの詳細が明らかになったので、この資料を基に内部を説明したい。
試作チップの「beppu」と量産チップの「chichibu」
まずAiOnICチップの目的である。ArchiTekはエッジAI向けの製品を志向しており、これに向けて低価格・低消費電力で、それでありながらそこそこの性能(2TOPS以上、というのは結構高い目標に思える)を実現することが必要、としている。

もっともここに挙がっている項目は、どんなエッジAIチップでもだいたい目標とするようなものだが、量産コストで10ドル以内というのはベンチャーには厳しい。
とりあえず設計やソフトウェアのコストを考えずに、純粋にウェハー製造コストだけで言えば、TSMCの12nmプロセスの場合はだいたい1枚4000ドルとされる(2020年の推定)。ということは、300mmのウェハーで400個のチップを取れないと、10ドルにはならない計算だ。
実際には歩留まりの問題などもあるため、もう少し多めに450~500個くらいチップを取れないと難しい。300mmウェハーで450個のチップを取ろうとすると、120mm2以下にダイサイズを抑える必要がある。100mm2というのは、MCUを見慣れた目にはかなり大きいダイに見えるが、AI向けに多数の演算器とSRAMを搭載するとなると、相当厳しい数字である。
それに加えて、ベンチャー企業の場合はそんなに多数のウェハーをいきなり発注したりできないから、シャトルサービスを利用しての混載(1枚のウェハーを複数の顧客のチップでシェアする方式。例えば右半分はA社の、左半分はB社の製品のマスクでそれぞれチップを製造し、完成後のダイシングの段階で別々に分ける格好になる)での製造になる公算が高い。
そうなるとどうしても価格が高くなりがちであり、それを前提に10ドルで抑えようとすると、実際のダイサイズはさらに小さな、それこそ80mm2や90mm2に抑えないとかなり厳しい気がする。当然その分回路規模も小さくなるので、性能を上げにくい。しかも2TOPSという絶対性能と2W以下の消費電力を満足させる必要があるわけで、普通に力技で作ったら要求は満たせないだろう。
異様にアクセラレーターが充実している「chichibu」
さてこれらの目標に向けて試作したbeppuチップ、まずは一般的な評価ボードと、AIカメラ向け評価ボードの2つの開発キットが用意された。
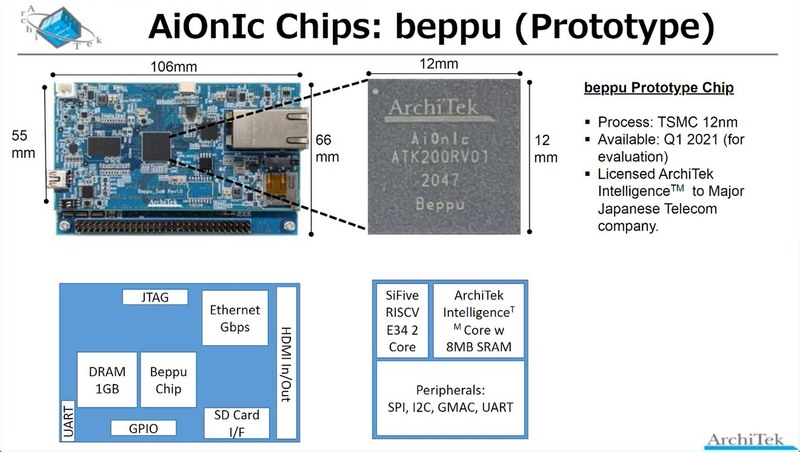

ただ今回はそのbeppuチップの中身ではなく、beppuチップを基にしたchichibuチップの内部構造が紹介されたのだが、少し変である。Processor GroupはRISC-VエンジンとGPGPUエンジン、GEMMエンジン、それとGEMM用のDMAからなるが、それとは別に異様に充実したアクセラレーターが搭載されている。
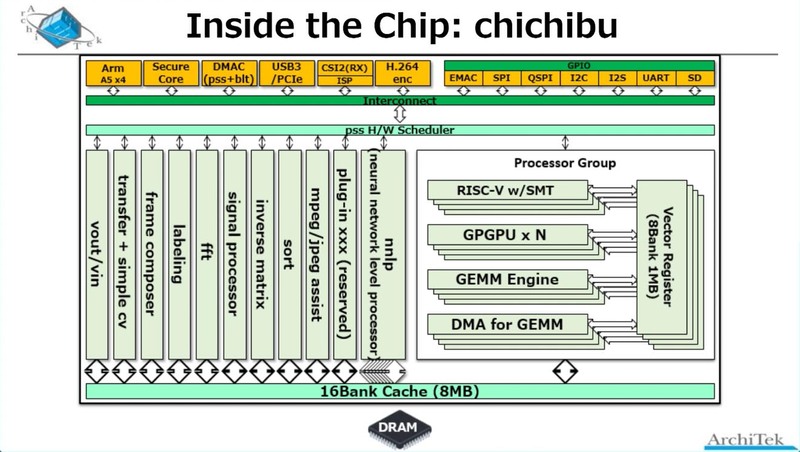
AiOnIcでは暗部補正、逆光補正といった撮影映像の補正や、SLAM(Simultaneous Localization and Mapping:自走ロボットの制御などで使われる自己位置推定と環境地図作成)、人物検出、パレット認識など、いくつかのアプリケーションシナリオが用意され、そのシナリオに応じてこの豊富なアクセラレーターとProcessor Groupで提供されるAIエンジンを適時組み合わせ、必要な処理を行なう。この際のデータの受け渡しは16バンク構成の8MBキャッシュ経由になる模様だ。
ちなみにそのアクセラレーターの中で、nnlp(Neural Network Level Processor)なるものだけは複数存在しているように見えるが、これがなにをしているのかは説明がなかった。名前からすると、畳み込みニューラルネットワークの重みというかネットワークの係数のハンドリングを処理するプロセッサーだろうか?
逆に詳細が説明されたのがFrame Composerで、これはOpenCVの処理をハンドリングできるものという話であった。これらの固定機能アクセラレーターを組み合わせることで、例えばAffine変換(画像の拡大縮小や回転、平行移動など)は1命令で処理可能としている。
特徴的なのはこのアクセラレーターとAIプロセッサーは同じ扱いであり、全部スケジューラー(上の画像で“pss H/W Scheduler”と書かれている部分)から制御され、おそらくはサイクルレベルでこれらを順次切り替えることで、同時に多数のスレッドを動かすことだ。
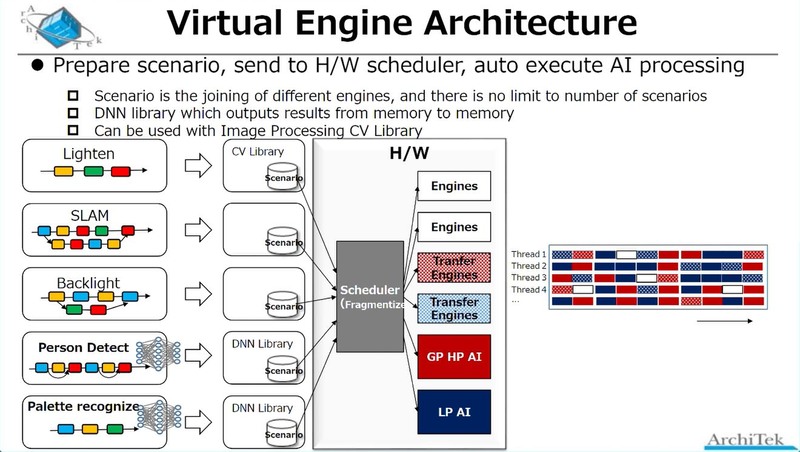
つまり、1つのAiOnIcで、複数のアプリケーションを同時に動かすことが可能というわけだ。実際、下の画像のように12種類のアルゴリズムを同時に動かすというデモも示された。

逆に言えば、1種類だけのアプリケーションを高速に動かすようなケースでは、特定のアクセラレーターあるいはAIプロセッサーの能力が先に飽和してしまいそうではある。このあたりはバーターなのであろう。
2種類のプロセッサーを搭載するAiOnIc
肝心のAIプロセッサーであるが、なんとAiOnIcは2種類のプロセッサーを搭載している。もともと、“RISC-V w/SMT”とGPGPUの2つのプロセッサーコアが存在することが、前ページにあるchichibuチップの内部構造の画像で明らかにされているが、Int 2/4/8を使った(つまり精度がそれほど必要ない)用途向けにLow Power AIプロセッサーが、fp8/fp16を使った精度が必要な用途向けには汎用プロセッサーが用意されている。
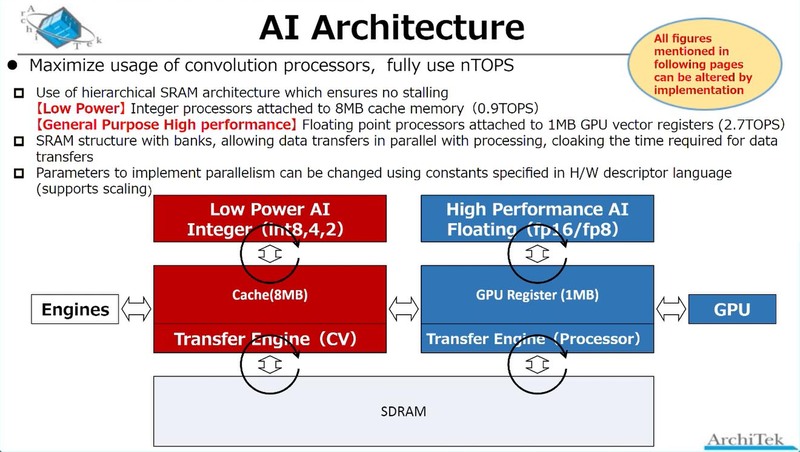
まずLow Power AIの方であるが、前ページにあるchichibuチップの内部構造画像でGPGPUという書き方をしていた。実際は? というと、下の画像のように16bitのMACエンジンの塊になっており、なるほどこれはDSPというよりはGPGPUに近いなと思う。
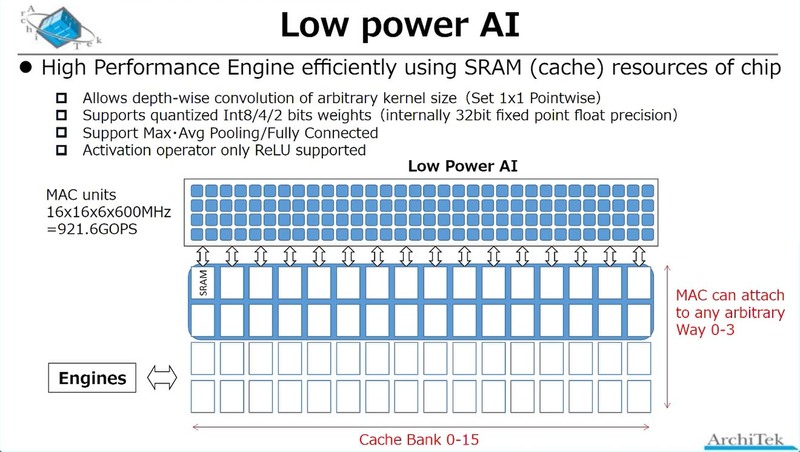
本当にもう畳み込みをするだけに特化したエンジンという感じである。また最大/平均のプーリングや全結合などもハードウェア的に実装されており、余分な手間なしで処理できる。その一方で、活性化関数はReLUのみ実装、というあたりはいろいろ割り切ったことが見られる。
一方High Performance AIの方であるが、先のchichibuチップの内部構造画像と併せて考えると、これはSMTに対応したRISC-Vコア(おそらくこちらもRV32系だろう)にVector Extensionを付けたコアが実装されており、このVector Extensionをブン廻すことで対応する形だ。
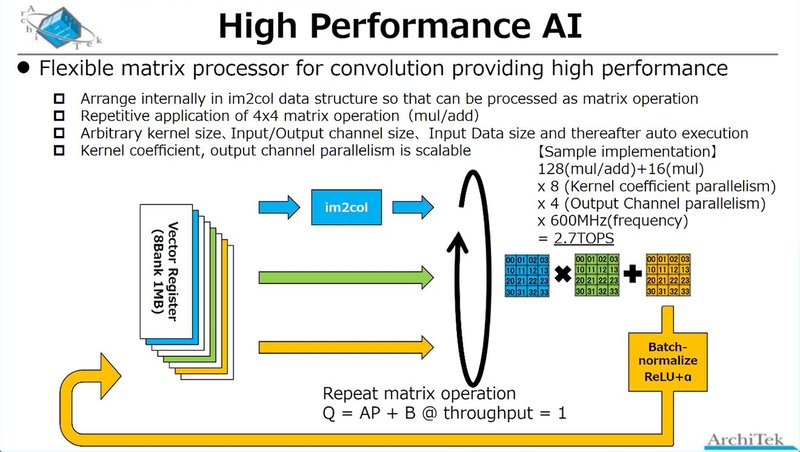
市販のIPでこの目的に適うものは存在しないが、例えば連載594回で紹介したEsperantoのET-Mineonは、こちらもSMTに対応したRV32コアで、ただしRVV(RISC-V Vector)をサポートしている。SMTの目的はメモリーアクセス待ちなどのレイテンシー遮蔽であり、これはAiOnIcでも同じことだと思われる。
おそらくRV32コアそのものは、アプリケーションプロセッサー(兼システム制御用)のSiFive E34コアと同等の、In-Order Single Issueで5~6段程度のパイプラインという比較的小さなコアで、このコアそのもののエリアサイズはそう大きくはないと思うのだが、問題はVector UnitとLoad/Store Unitはそれなりの面積になりそうなことだ。
これを4つも入れたら冒頭に書いた「80~90mm2前後」どころか「120mm2」も怪しそうな気はするのだが、これはプロセスの微細化が前提なのだろう。逆に言えばbeppuチップは、おそらくRISC-Vコアは1つだけだろうし、Low Power AIの方ももう少し規模が小さいと思われる。
そのあたりのロードマップが下の画像だ。現在はTSMCのN12でbeppuチップを製造しているが、おそらくchichibuチップはTSMCだとするとN7あたりに移行して製造されるものと思われる。
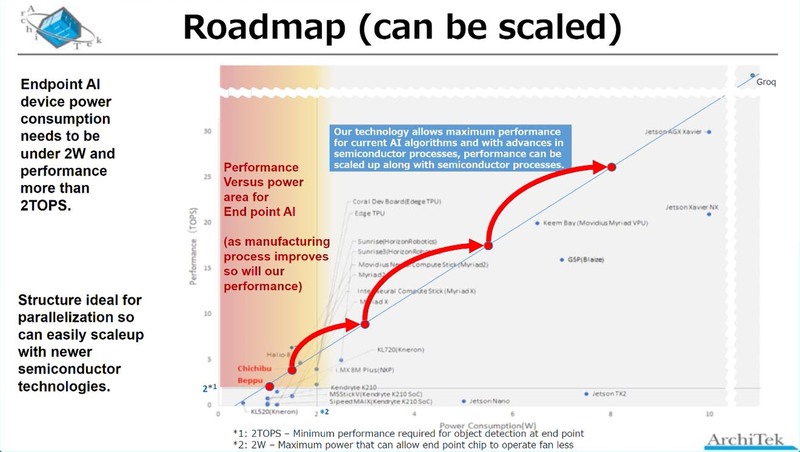
ちなみにN7を使う場合、ウェハーの製造コストは9300ドルほどになる。したがって、冒頭に出て来たチップ単価10ドルを実現するためには、最低でもウェハー1枚から900個、実際には1000個程度取らないと実現できないことになる。
1000個だとするとダイサイズは最大で70mm2、実際には50~60mm2あたりで抑える必要があるだろう。幸いにもN12→N7でトランジスタ密度そのものは3倍程度になるため、ダイサイズが減っても利用できるトランジスタ数は1.5倍近くになるので、一応微細化の意味はあると言える。
もっとも、プロセス微細化よりも(単価アップには目をつむって)回路規模を大きくする方が性能をスケーラブルに上げられるとしており、実際同社からこのAiOnIcのIPの提供を受けた顧客の場合、400TOPSのチップを製造しているとする。
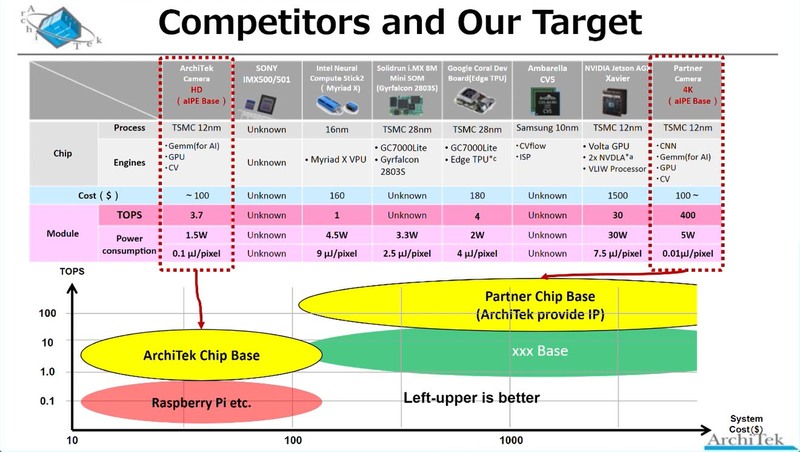
同社はチップを提供、というよりもソリューションを提供することを志向しているようで、ただなにもないと開発にも困るのでとりあえずbeppuチップを製造、ついで本番向けにchichibuチップを製造する予定ではあるが、むしろbeppuチップを評価の上でIPの供給を受けて自社でAiOnIcベースのチップを製造する顧客を増やす、というのがビジネスの方向性のように思われる。
ベンチャー企業がチップの製造をメインに据えるといろいろ難しさが出てくるというのは、例えばETA Computeのケースでも紹介した通りで、IP売りをベースにSoC設計サービスなども行ないつつ基本はソリューション提供、というのは堅実な方法なのかもしれない。

この記事に関連するニュース
-
Core Ultra 200H/U/Sをあえて組み込み向けに投入するのはあの強敵に対抗するため インテル CPUロードマップ
ASCII.jp / 2025年1月20日 12時0分
-
RISC-Vのブレークスルー:SpacemiT、次世代AIアプリケーション向けサーバCPUチップV100を開発
共同通信PRワイヤー / 2025年1月9日 9時42分
-
ホンダとルネサスが提携、次世代EV向け高性能SoC開発へ…CES 2025
レスポンス / 2025年1月8日 13時30分
-
1万5000以上のチップレットを数分で構築する新技法SLTは従来比で100倍以上早い! IEDM 2024レポート
ASCII.jp / 2025年1月6日 12時0分
-
PCテクノロジートレンド 2025 - CPU編「Intel」と「AMD」
マイナビニュース / 2025年1月3日 10時0分
ランキング
-
1ポケモンGOで改善してほしいこと:「課金なくても楽しみたい」「伝説ポケモンをソロで討伐したい」
ITmedia Mobile / 2025年1月21日 18時49分
-
2東京都の新アプリ、マイナカード本人認証で7000円分ポイント付与 報道
ASCII.jp / 2025年1月20日 14時30分
-
3PCケースのサイドパネルをバキバキに粉砕してしまうユーザーたち…起こりがちなミスとその対処法は?
Game*Spark / 2025年1月21日 12時45分
-
4セゾンカード、不正懸念の顧客に「ご利用内容確認のお願い」動画送信へ
ITmedia NEWS / 2025年1月17日 16時56分
-
5【編み物】7色の毛糸でパターンを作りつなげると…… 色鮮やかな圧巻の大作に「元気がでる」「素晴らしい色」【海外】
ねとらぼ / 2025年1月15日 19時30分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





