

AIプロセッサー「GAUDI 2」と「GRECO」が年内に登場予定 インテルCPUロードマップ
ASCII.jp / 2022年9月26日 12時0分

今月、インテルはイスラエルでIntel Tech Tour.ilと題したTech Dayを開催した。なぜイスラエルか? というと、実は間もなく詳細が公開されるRaptor Lakeの設計と製造はイスラエルが主導しており、それもあってキーパーソンインタビューやDeep Diveなども開催されたのだが、このあたりの詳細はまた回を改めてお届けする。
イスラエルと言えば、インテルが買収したMobileyeやHabana Labsなども全部イスラエルの企業であり、それもあって今回のTech DayではHabana Labsによる製品アップデートも説明があった。
Habana Labsの話は連載575回で紹介したが、この時はGAUDIとGOYAという、同社にとって第1世代の製品の説明に留まった。ただ同社(というのか、同部門というのか)はこれに続いて第2世代製品をすでに出荷しているので、このあたりを中心に説明したい。
クライアント向けにVPUを導入
Habana Labsの話を中心に、と書きながら最初はクライアント側の話である。インテルはIce Lake世代でGNAと呼ばれるAIアクセラレーターを導入したが、これは連載665回で説明したように、非常に限られた用途向けのもので、汎用というには性能的に不十分なものだった。その一方で、クライアントではさまざまなところでAIを利用しよう、という機運が急速に高まりつつあるとする。

これに向けて、インテルとしてもクライアント向けに本腰を入れてAIを実装していこう、としている。具体的には、クライアントにもVPUを標準で導入する、というのが今回の大きな発表である。
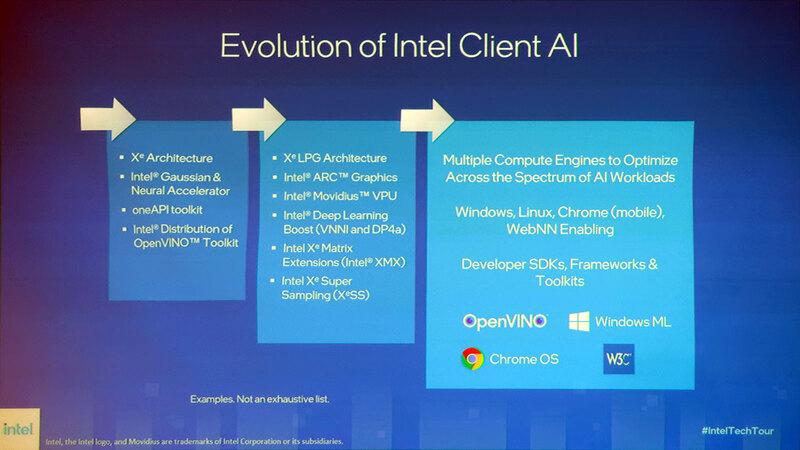
VPUはVision Processing Unitの略で、インテルが買収したMovidiusのMyriadシリーズのアクセラレーターに採用されている名称だが、これを全面的にクライアントに導入することを正式に発表した。

まずRaptor Lake世代が最初の導入プラットフォームになる。そしてMeteor LakeではこれがCPU側に統合されることが明確にされた。

もともと今年2月に開催されたInvestor Meetingの際に、Raptor Lakeには“AI M.2 Module”なるものが追加されると明らかにされていた。
連載657回でも「現時点で一番可能性が高いのはこのMyriad X VPUベースということになる」と書いたが、上の画像でMicrosoft(おそらくWindows MLのVPU対応をするのだろう)のほかにDell/HP/Lenovo/Acerのロゴがあるのは、この4社から投入されるRaptor Lakeベースのクライアント機には、Myriad X VPUを搭載したM.2 Moduleが搭載されると考えていいだろう。
実際にさまざまなアプリケーションがVPU対応になるのはまだまだ先のことであろうが、AMDもZen 5世代でXNAという名称で旧XilinxのAI Engineを搭載することを発表しており、クライアントにAIアクセラレーターが標準搭載される日が近づいたことになる。もっともスマートフォン向けのSoCではもうNPU(Neural Processing Unit)を標準搭載するのが当たり前の昨今からすると、むしろ動きが遅いともいえるが。
GAUDI 2は管理維持の経費削減に効果大
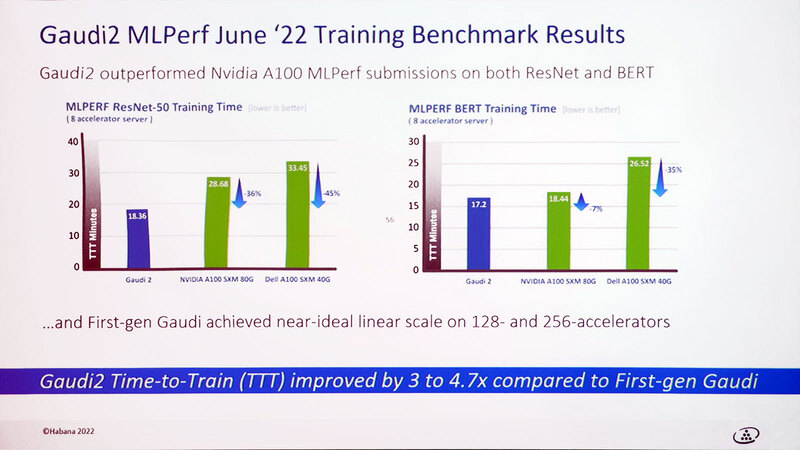
今年5月に行なわれたIntel Vision 2022で、インテルはGAUDI 2を初公開した。といっても詳細はあまり明らかになっておらず、唯一示されたのはNVIDIAのA100と比較して約2倍のスループットを実現できるということだけだった。


A100の2倍というのは新製品としては全然十分ではない(H100の3分の2の性能ということになる)わけだが、ここでHabana Labsはおもしろい見解を出してきた。
昨今のデータセンターでは、ディープラーニングに要するコストがどんどん上がっているとする。理由はより複雑なモデルと繰り返し回数の増加、アプリケーション利用の広がりなどだ。

ところが、GAUDI 2はディープラーニングに要するコストの削減に大きな効果がある、というのがHabana Labsの主張である。要するに絶対性能だけでなく、TCOの削減に効果が大きいとしたわけだ。

GAUDI 2そのものはプロセスの微細化と処理エンジン強化(3倍)、メモリーの容量増加と高速化、ネットワーク強化(100G×10→100G×24)と、猛烈に内部構造を強化したGAUDIといった形になっている。その内部構造が下の画像だ。

TPC(Tensor Processing Cores)が3倍に増やされた以外に、新たにMME(Matrix Multiplication Engine)が2つ追加されている。またHEVC/H.264/VP9/JPEGなどのデコードが可能なMedia Engineも新たに追加された。
ちなみに図には出ていないが、初代GAUDIでは24MBの共有SRAMが搭載されており、これを利用して送受信やTPC間でのデータ共有などを行なっていたが、GAUDI 2ではこれも48MBに増やされている。
GAUDI2が他のAIアクセラレーターと異なることの1つは、マルチチップ構成でのインターコネクトである。制御そのものはホスト(Ice Lake-SPサーバーをここでは念頭に置いている)からPCIeレーンでつながるが、カード同士は100GbEで接続する、という独特の構成である。
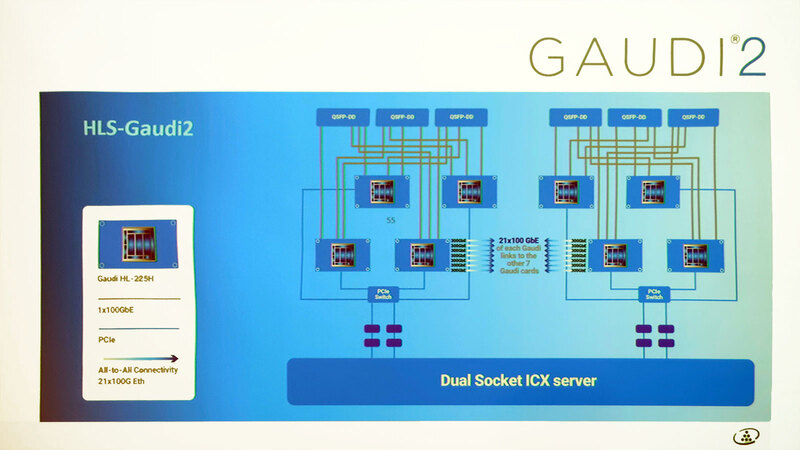
なにせ1つのGAUDIから24本の100GbEが取り出せるので、そのうち3本はネットワーク接続用に回すとして、残り21本は丸々余っている。これを300GbE×7構成にして、GAUDI 2同士の相互接続に使う、という構成である。下手な独自インターコネクトを作るより、100GbEを流用した方が効率的と考えたのだろう。
さてGAUDI 2の性能であるが、これはIntel Innovationで示されたものと大差ない。
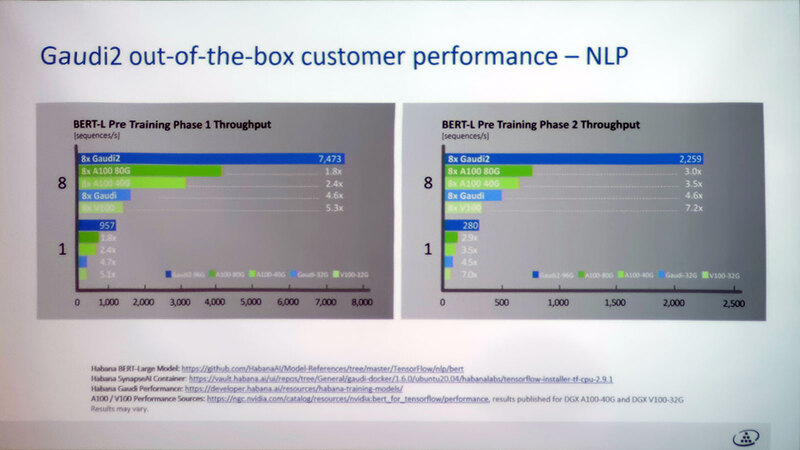
今回新たに示されたのはスケーラビリティーで、複数枚のカード(初代GAUDIを含む)を利用したケースで、枚数に応じてリニアに性能が増えるとしている。
GAUDI 2は2022年第4四半期に出荷
出荷に関しては、オンプレミス向けにはSuper Microが8枚のGAUDI 2を搭載したシステムが今年第4四半期に出荷するとしている。このシステム(の下半分)は会場でも展示された。



ところでHabana Labsの製品の場合、ソフトウェアはインテルのOneAPIやOpenVINOではなく、独自のSynapseAIを利用する。
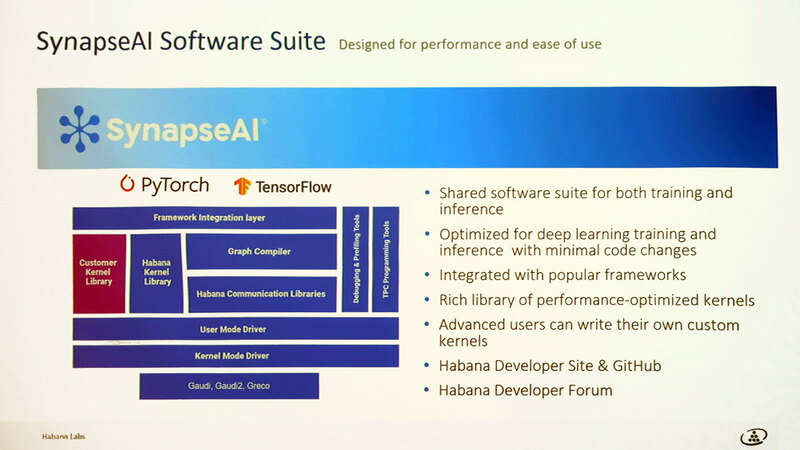
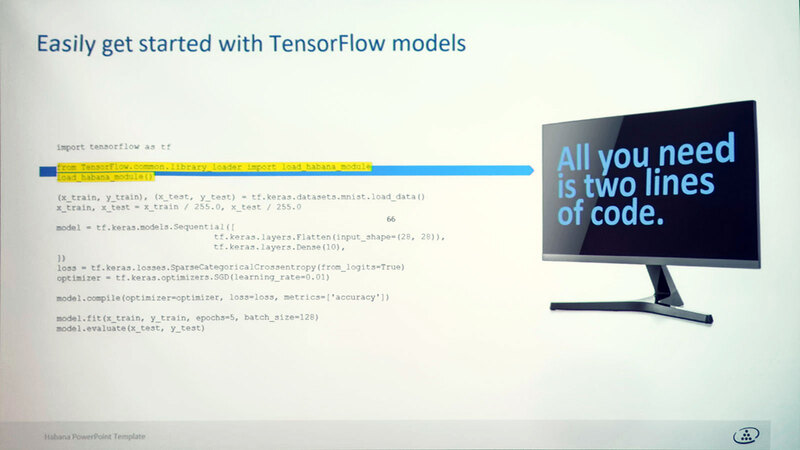
このSynapseAIを使う場合、例えばTensorFlowのモデルだったら冒頭に2行追加するだけでSynapseAIを利用してGAUDI 2を活用できるようになるという話であった。
第2世代GOYAはGRECOに名称変更
トレーニング/推論向けのGAUDIがGAUDI 2になったので、推論専用のGOYAはGOYA 2になったか? と思ったら、なぜかGRECOになった。

GRECOもGAUDI 2同様に7nmプロセスに移行、オンチップメモリーの増量やLPDDR5の搭載、INT 4のサポートなど、さまざまな機能強化が施されているが、最大の特徴は200W→75Wに減った消費電力である。
この結果として、2スロット/フルレングスだったGOYAのPCIeカードは、GRECOでは1スロット/ハーフレングスに小型化されている。

実際GOYAのカードの実物はかなりごっつく、強制空冷が必要な構成だったのに対し、GRECOはかなりシンプルな構造になっている。ちなみにGRECOは今年後半に発売予定となっている。


というわけで、2023年以降のインテルは、Intel ArcやCPU/VPUと、Habana LabsのGAUDI 2/GRECOの組み合わせでAIソリューションを提供していく、という方針が明確に示された説明会であった。

この記事に関連するニュース
-
Core Ultra 200H/U/Sをあえて組み込み向けに投入するのはあの強敵に対抗するため インテル CPUロードマップ
ASCII.jp / 2025年1月20日 12時0分
-
Supermicro(スーパーマイクロ)、AI、HPC、仮想化、エッジのワークロードに最大性能を提供する、最新プロセッサー搭載の最高性能サーバーの量産を開始
共同通信PRワイヤー / 2025年1月14日 9時33分
-
インテルCES 2025でAI PCとエッジ・コンピューティングにおけるリーダーシップを拡大
PR TIMES / 2025年1月7日 18時45分
-
インテルがCore Ultra 200HX/H/Uシリーズを発表、285HXの性能は前世代から最大41%向上
ASCII.jp / 2025年1月6日 23時0分
-
PCテクノロジートレンド 2025 - CPU編「Intel」と「AMD」
マイナビニュース / 2025年1月3日 10時0分
ランキング
-
1ローソンが238円で具なしカップラーメン発売へ 「高くない?」「カップヌードルとほぼ同額」異論も
iza(イザ!) / 2025年1月22日 17時7分
-
2快活CLUBに不正アクセス、個人情報が一部漏えいか
ASCII.jp / 2025年1月22日 13時15分
-
3“映り込み”を防いでスマホ撮影するには……? 100均アイテムを使った目からウロコのライフハックに「これはスゴい」
ねとらぼ / 2025年1月22日 7時50分
-
4父「若いころはモテた」→娘は半信半疑だったが…… 当時の“まぶしすぎる姿”に40万いいね「俳優さんみたい!」「衝撃的」【海外】
ねとらぼ / 2025年1月22日 17時20分
-
5サンリオに不正アクセス ピューロランドのチケット購入などが不可能に 情報漏えいについては調査中
ITmedia NEWS / 2025年1月22日 17時12分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





