

GeForce RTX 4090基本ベンチ&解説編!Fire Strike UltraはRTX 3090から93%アップ!?
ASCII.jp / 2022年10月11日 22時0分


NVIDIAの新アーキテクチャー“Ada Lovelace”を使用した新GeForceの時代が、10月12日22時より始まろうとしている。今回発売される「GeForce RTX 4090」(以下、RTX 4090)は、Ada Lovelace世代のフラッグシップであり、ゲーマーとクリエイターの双方をターゲットにしたエンスージアスト向けモデルだ。
本邦での予価はNVIDIA公式から29万8000円“より”と発表済みだが、本稿執筆時点(10月10日)では具体的な価格情報は入ってきていない。高額な製品にも関わらず秋葉原では深夜販売も予定されており、超ハイパワーGPUへの関心の高さが窺える。
GeForce RTX 40シリーズ(以下、RTX 40シリーズ)は、TSMCの5nm(NVIDIA的には4N)プロセスで製造されているほか、設計的にはCUDAコアよりもRTコアやTensorコアの強化がポイントになる。11日22時のAICパートナー製カードの日本発売に先立ち、「GeForce RTX 4090 Founders Edition」(以下、RTX 4090 FE)のパフォーマンスレビューが解禁されたが、本稿ではまず、RTX 40シリーズの技術的な見どころと、基本的パフォーマンスまでを紹介したい。
GeForce RTX 3090 Ti(以下、RTX 3090 Ti)をも超えるCUDAコアを備えたRTX 4090は、GPUパワーに飢えているエンスージアストに内なる平穏を与えてくれるのだろうか?


SM/RT/Tensorの3要素の強化がポイント
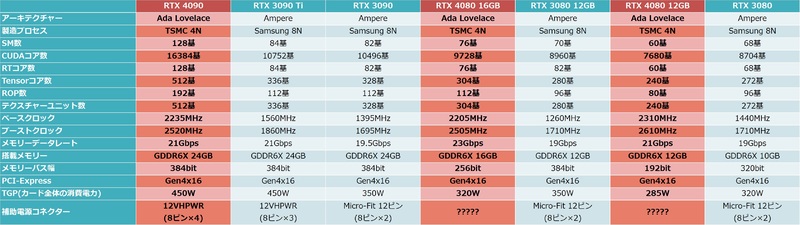
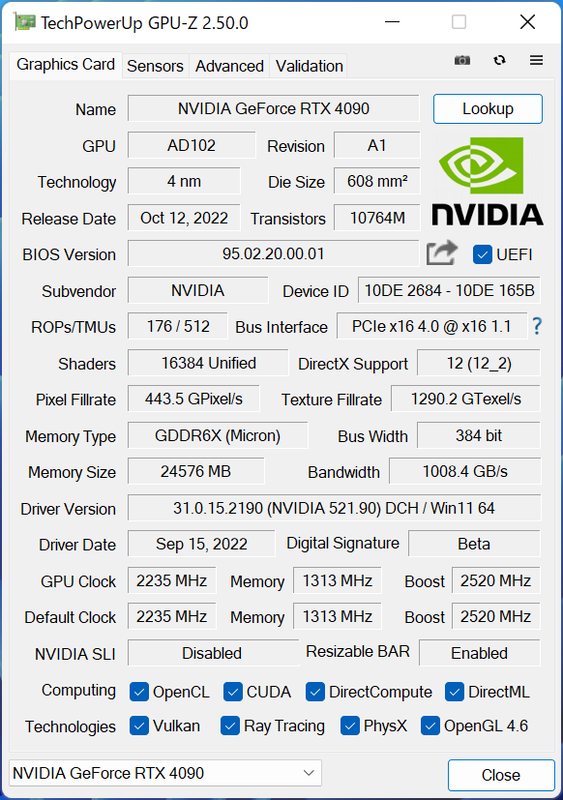
まずはRTX 4090のスペックを確認しておこう。AD102ベースのコアを使用しているが、フルスペックのAD102よりもGPC(Graphics Processing Cluster)1+1/3基ぶんのSM(Streaming Multiprocessor)が無効化されている。それでもCUDAコアはRTX 3090 Tiよりも1.52倍多い16384基を搭載。一方、メモリーの24GBのGDDR6X、384bitバスといった部分はRTX 3090 Tiと変わっていない。
また、動作クロックについてはTSMCの4Nノード(=5nm)採用によりブーストクロックは2520MHzまで引き上げられているが、その代償としてTGPは450Wに設定されている。
ただ、PCI Express Gen 5対応が見送られ、Gen 4 x16でリンクするというのはやや残念だ。RTX 40シリーズの発表が遅れたのは、仮想通貨マイニング熱の終焉に伴う既存GeForceの在庫調整という噂もあるが、PCI Express Gen 5でいくか、互換性重視でGen 4のままとするかの調整も遅れの一因ではないかと筆者は邪推している。
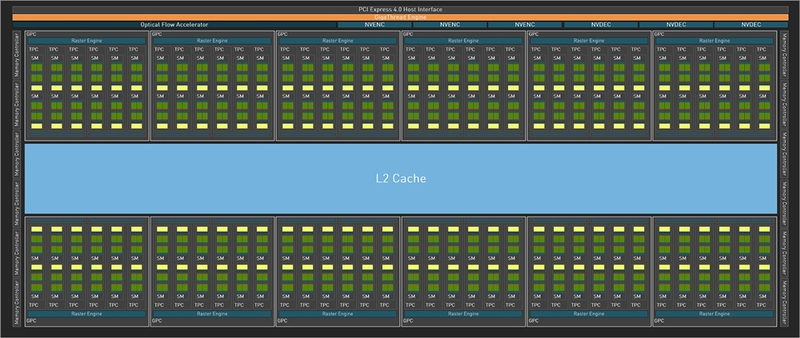
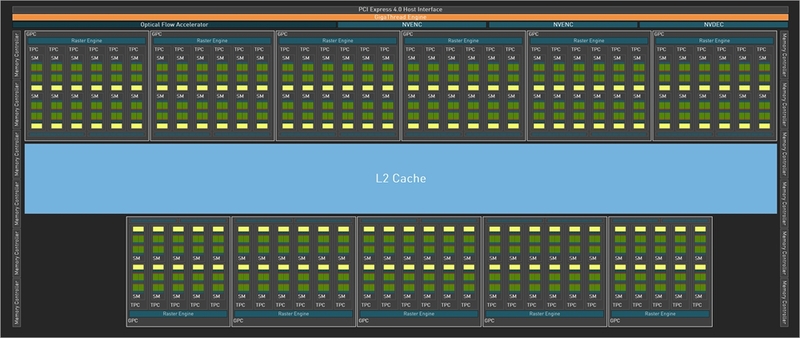
すでにお気づきかもしれないが、AD102およびRTX 4090のブロック図にはNVLinkの記載がない。NVIDIAはNVLinkの回路にトランジスタを割くなら、CUDAコア等の増量に使った方が良いと判断したようだ。NVLinkでマルチGPU環境を構築したかった人には残念だが、マルチGPUは今のゲームに求められるレスポンス向上(低レイテンシー)が得られない以上、非対応となったのは無理もない話だ。
補助電源ケーブル構成によりOC限界が変わる
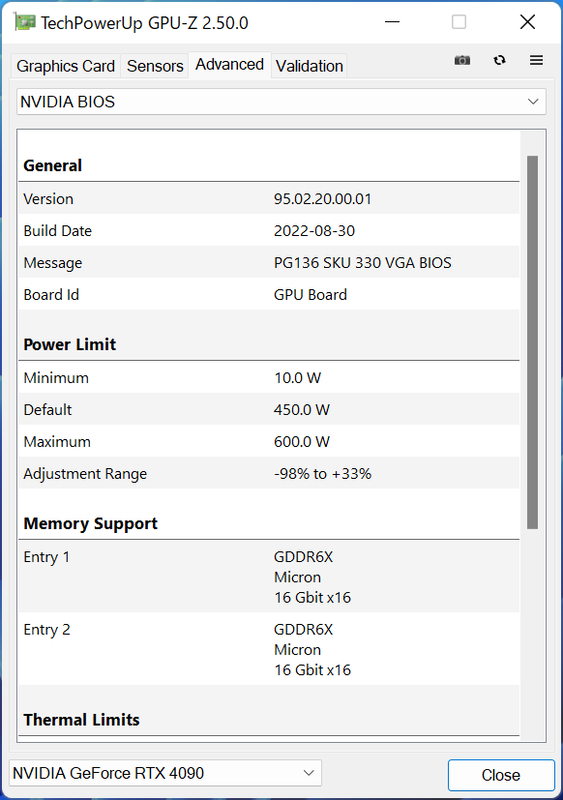
RTX 4090 FEの補助電源コネクターにはRTX 3090 Tiで初採用された16ピンの“12VHPWR”が採用されている。これはRTX 4090 FEのTGPが450Wと高く設定されているためだが、RTX 4090 FEに同梱される変換ケーブルはなぜか8ピン×4を12VHPWERに変換する。8ピン補助電源1本で150Wだから、この変換ケーブルで600Wの電力供給に対応できる。これはどういう理由によるものなのだろうか?
その答えはシンプルで、RTX 4090 FEの場合、8ピンケーブルを3本しか接続しなくても普通に動作する。だが4本接続した場合に限り、「MSI Afterburner」などのOCユーティリティー上でPower Limitを定格の33%増、即ち600Wまで引き上げることができる。ただ、この仕様はビデオカードメーカーの味付け次第でもっと低い値、例えば500W程度に絞られている場合もある点に注意したい。RTX 4090 FEならではの欲張り仕様といえるかもしれない。
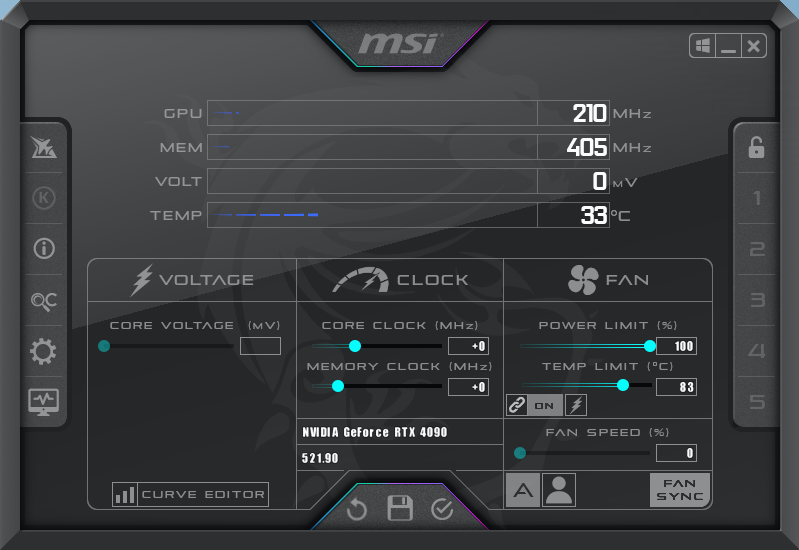
この挙動は同梱の12VHPWRケーブルの設計にある。現在流通している12VHPWR対応電源や変換ケーブルの中には、4本の制御用ピンのうちSense0と1をGNDに接続することで、決め打ちで600W供給を可能にしている製品があるが、RTX 4090 FE同梱の12VHPWRケーブルはもう少し賢い。このケーブルには補助電源ケーブルが何本接続されているか判定する回路が組み込まれており、これに応じて制御用4ピンをGNDに接続する/しないを決定している。RTX 4090 FEはこれを読み取って、Power Limitの設定レンジを決定する。
何度も繰り返すようだが、ここで解説した内容はあくまでRTX 4090 FEの場合であり、国内で流通するAICパートナー製RTX 4090カードでは異なる可能性がある点に注意されたい。筆者はファクトリーOCモデルにもこのケーブルが供給されるのではないかと考えているが、TGPを450Wより上に設定して出荷されるファクトリーOCモデルでは8ピンケーブル4本接続が必須になる可能性も十分に考えられる。

RTコアの進化とSERでレイトレーシングをより快適に
Ada LovelaceではCUDAコアそのものに手をいれず、RTコアとTensorコアの強化が主眼になっている。この辺はGTCでの発表を解説した記事で述べているが、本稿はその内容を補完するとともに、RTX 40シリーズの新要素をもう少し深く解説しておきたい。

①SER(Shader Execution Reordering)
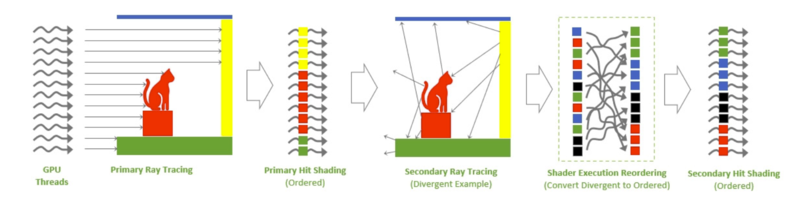
GeForceではCUDAコアのクラスターであるSMが基本単位となり、ここに搭載されている命令ユニットがCUDAコアに命令を発行する。RTX 40シリーズのSMでは、この部分に命令の事項順序を動的に並び替え、処理効率を向上させることが可能となった。それがSERだ。
レイトレーシングでピクセルの色を決定する処理において、光線(レイ)があちこちに飛べば、飛んだ先ごとに異なったシェーディング処理が走ることになる。飛び先が多いほど異なる処理が走るため、処理の切り替えやメモリー管理などの負荷が増大する。SERで似た処理を連続するように並び替えることにより、処理効率を向上させることが可能になる。
「Cyberpunk 2077」に搭載予定の「Overdrive」モードでは、レイトレーシングの中でも特に負荷の重いパストレーシングが実装される予定だ。しかしこうした処理ではSERの存在が必要不可欠となる。NVIDIAによれば、Cyberpunk 2077のオーバードライブモードにおいて最大44%の性能向上が観測されたという。

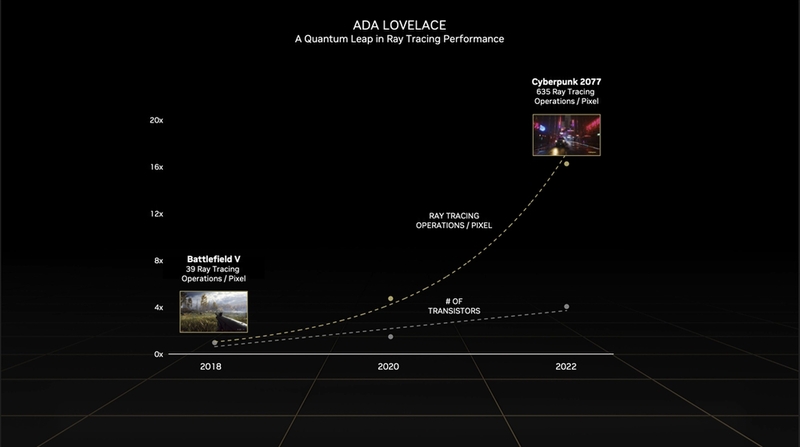
②RTコアに新機能を追加
レイトレーシング処理の命といえるRTコアは、第3世代に進化。前世代に比較してレイ-トライアングルの衝突判定速度が2倍になったほか、「Opacity Micromap Engine」と「Displaced Micro-Mesh Engine」が新たに追加された。
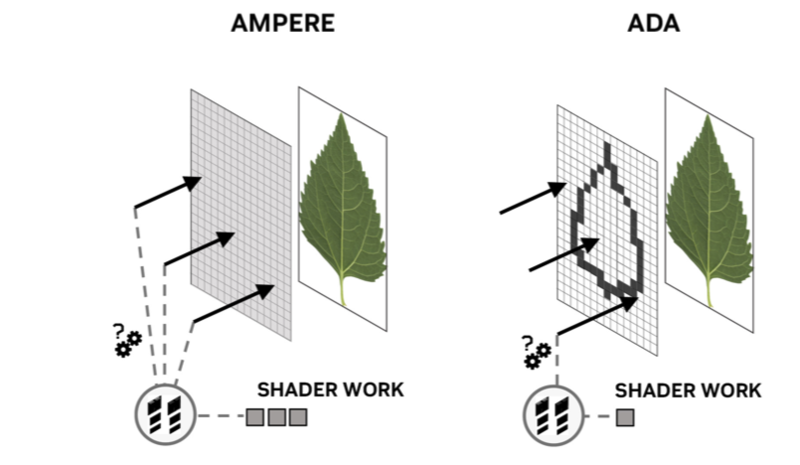
Opacity Micromapは部分的に透明度を持つオブジェクト(植物の葉や炎、煙など)の処理を効率化する機能だ。下図のように葉のテクスチャーを持つオブジェクトにレイが衝突した場合を考えてみよう。葉のテクスチャーの外周は透明になっており、こうした表現は実ゲームでもよく使われる。このオブジェクトにレイが衝突した際、衝突地点が透明(外側)ならレイはヒットしていないと判定されるが、葉の内側や境界ならヒットしたと見なして別の処理に続く。
従来のRTコアでは、オブジェクトにヒットした判定はできるが、そこが透明な部分か、そうでないかの判定に複数の処理(下図ではShader Work)が使われる。画面上に葉が1枚や2枚で済む訳はないので、この判定処理がボトルネックを生む。
そこで予め透明度のマップ、即ちOpacity Micromapを保持しておき、それを参照して葉の外か中か、あるいは境界かを判断できる。透明度を持ったオブジェクトを多数配置して表現するシーンでは、Opacity Micromapでシェーダーの負荷を劇的に下げられるわけだ。
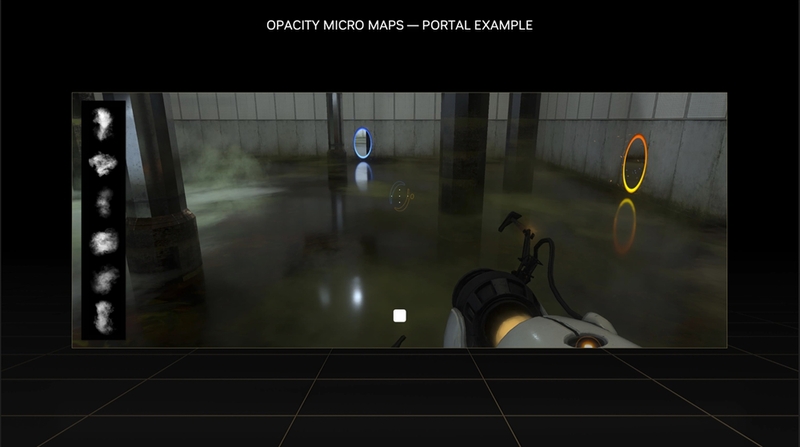
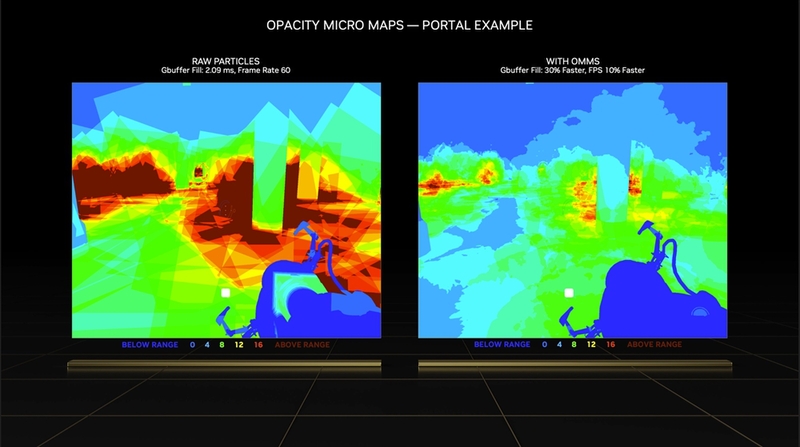
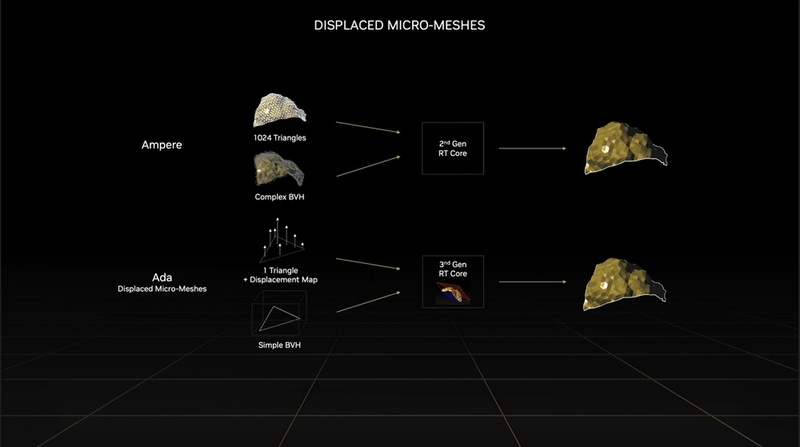
もう1つの追加要素であるDisplaced Micro-Mesh Engineは、レイとポリゴンの衝突判定を行うために必要不可欠なBVH(Bounding Volume Hierarchy)構築の速度とBVHのデータ量を劇的に小さくできる機能だ。オブジェクトのジオメトリーが100倍複雑になっても、レイをトレースする処理はそれほど増えないが、ジオメトリーが100倍になればBVHの構築時間も100倍になるし、メモリー消費量も増える。これも大きなボトルネックになり得る。
RTX 40シリーズの第3世代RTコアでは、BVHを適度に粗い三角形の集合レベルで構築し、その三角形ごとに本来の形状を再現する情報(Displacement Map)を組み合わせることが可能になる。こうすれば複雑なジオメトリーを少ないデータ量で表現できるのだ。

AIがフレームを自動補間する新世代のDLSS
③“CPUボトルネック”を緩和しフレームを生成する「DLSS Frame Generation」
RTX 40シリーズにおける最大のみどころはDLSS 3で追加されるDLSS Frame Generation、日本語で言えば「DLSSフレーム生成」への対応だ。これに伴い従来のDLSSはDLSS Super Resolutionと呼ばれることになった。DLSS Super Resolutionは引き続きRTX 20〜30シリーズでも利用可能だが、DLSS Frame GenerationはRTX 40シリーズ専用となる。「DLSS 3」とは、DLSS Frame Generationを含むDLSS実装を示す呼び名だ。

DLSS Frame Generationの前にDLSS Super Resolutionについて解説しておくと、低解像度のレンダリングから高解像度かつ高画質の出力画像を得る超解像処理を行う機能だ。Tensorコアを利用したAI処理により実現する。DLSS Super ResolutionでGPUの負荷が劇的に下がるため、ゲームのフレームレート向上に大きな効果が得られるが、CPUがGPUに描画を指示しなければ効果が得られない。もしCPUの処理がモタついて、GPUに描画指示を出すのが遅れれば、フレームレートは上がらない。いわゆる「CPUバウンド」の状態になる。
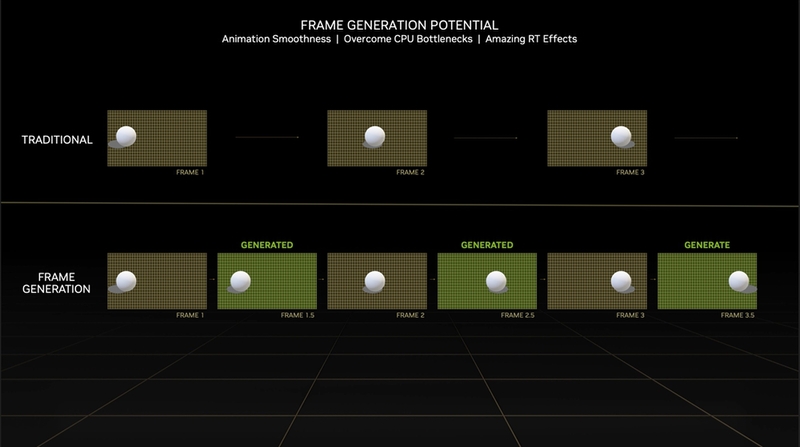
この状況を打破するのがDLSS Frame Generationとなる。DLSS Frame Generationでは前フレームと今フレームの情報から、今フレームと次フレームの中間フレームをGPUだけで推測して出力する。仮にCPUがフレーム0、1、2、3、4……と描画指示を出した場合、フレーム0と1から0.5を、1と2から1.5を生成する。
DLSS Frame Generationは特にCPUバウンド(=CPUが律速)の状態で効果を発揮するが、これは即ちCPUのパフォーマンスが低いほどDLSS Frame Generationの効果も期待できることを意味する。レイトレーシングのように重い処理で効果を発揮するが、DLSS Frame Generationの動作にレイトレーシングは必須ではない。
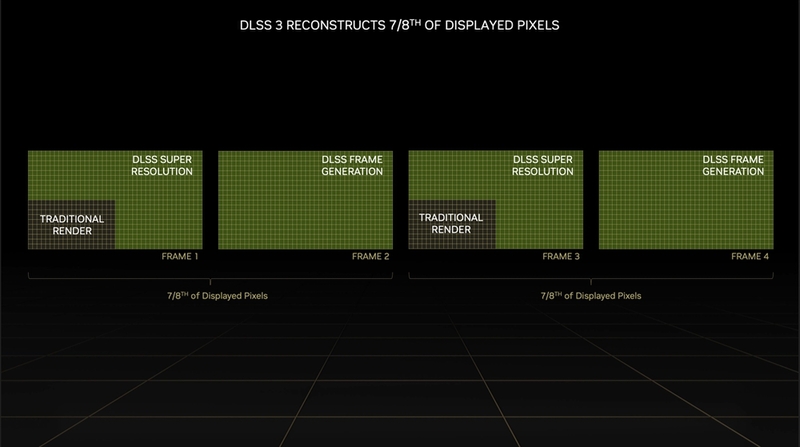
DLSS Frame Generationを使うことで、同じフレームレートでもGPUのシェーダー負荷を減らせる点も大きなメリットだ。例えばDLSS Super ResolutionのPerformanceモードでは、出力解像度の縦横半分の解像度(面積にして1/4)でレンダリングされるが、これにDLSS Frame Generationを適用すると、最初の1フレームとFrame Generationで挿入される次のフレームのすべてがAIによって描画されることになる。理論上、1のシェーダー負荷で8の仕事ができる計算になる(実際はそう上手くは行かないだろうが)。
このDLSS Frame Generationの推論処理において必要なのが、あるフレームにおいて動いていないピクセルの判定だ。これを処理するのがRTX 40シリーズに搭載されたオプティカルフローアクセラレーターだ。
オプティカルフローについてざっと解説しておくと、時間的に連続した2枚の画像を比較し、各ピクセルの光学的な動きから動きのベクトルを算出するというもので、「Adobe Premiere Pro」をはじめ、動画編集系ソフトではお馴染みのフレーム補間技法となる。DLSS Super Resolutionで言うところのモーションベクターはゲーム内世界でのオブジェクトの動き、オプティカルフローは画面に投影された映像の動きと言い換えられる。
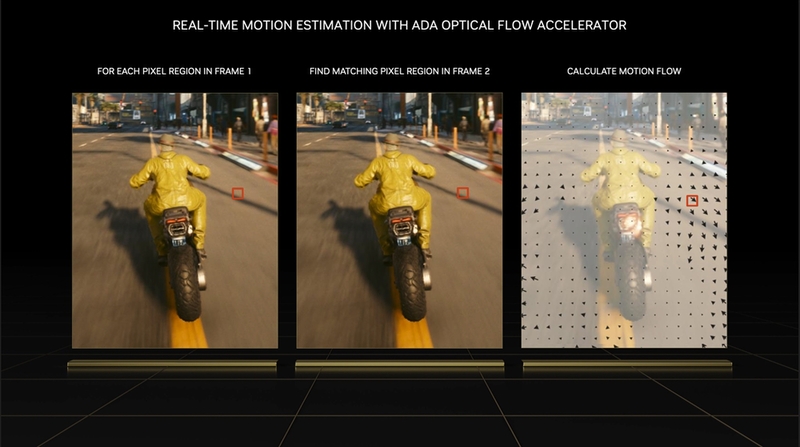






このオプティカルフローアクセラレーターの存在が、DLSS Frame GenerationがRTX 40シリーズ以降でしか使えない理由になる。オプティカルフローで画面を光学的に分析して初めて、破綻の少ないフレーム生成が可能になるのだ。もちろん推測による生成であるため、激しく動く物体がある場合は形状が乱れるなどの制約はあるが、ゲームにおけるCPUボトルネックを打破する手段としては非常に有用といえる。
ただ、常に場面の正確な動きを認識する必要があるeスポーツ性の高いゲーム(VALORANTやApex Legends等)では、推論によって描画するDLSS Frame Generationとは相性が良くないのではと感じる人もいるはずだ。
しかし、そういったゲームではそもそも描画が軽いものが多く、DLSS Frame Generationが必須になるとは考えにくい。もしDLSS Frame Generationが実装されていても、使わなければ済む話だ。
④NVEncはAV1に対応。さらに2つ並列で動作可能
RTX 40シリーズではGPUに搭載されたハードウェアエンコーダー「NVEnc」がAV1に対応した。先鞭を付けたのは先日登場した「インテル Arc A380 グラフィックス」だが、今回はレビュー用に「DaVinci Resolve Studio 18」やDiscordのβビルドも提供されたため、実践的なパフォーマンスの検証もできた。DaVinci Resolve Studio 18に関しては別稿で検証結果をお目にかけたい。
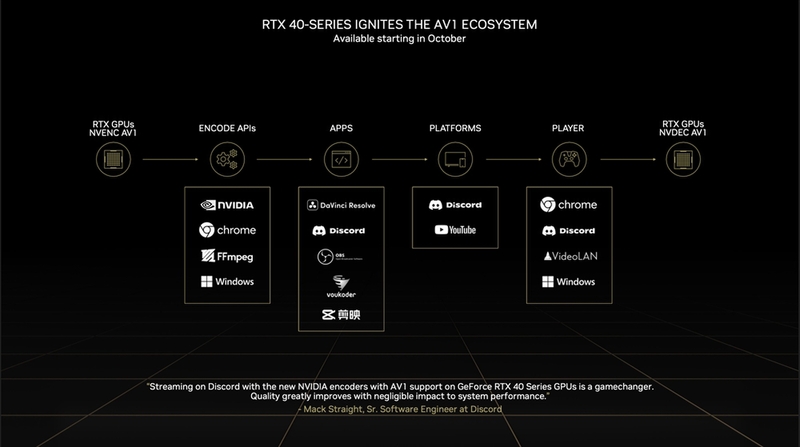
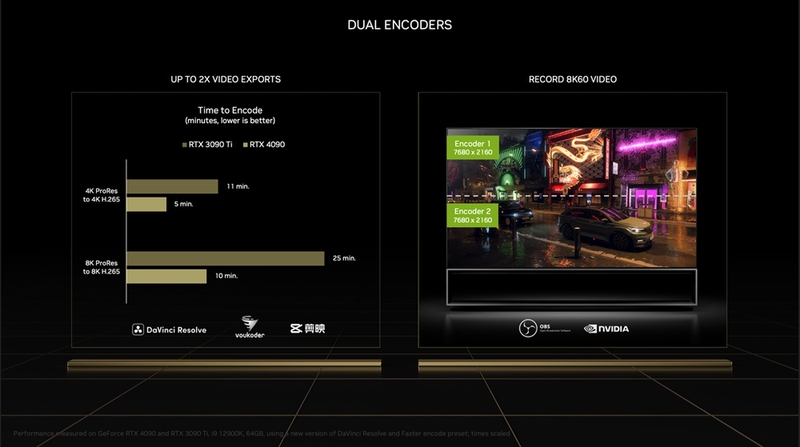
さらに、NVEncは2基搭載され、2基のNVEncを並列で動かせるようになった。Pascal〜Volta世代(GeForce GTX 1070〜Titan V)ではすでに複数のNVEncを備えたモデルが存在するが、並列で動かせるのはAda Lovelace以降とのことだ。「OBS Studio」の最新ビルドではデュアルNVEncに対応しており、エンコーダーにNVEncを指定するだけで自動的に並列処理となる。ただ、今回試した限りではNVEncの片方だけを使用するような指定はできなかったので、2基同時利用が前提と考えられる。
新旧GeForce&Radeonのフラッグシップ対決
座学はこの辺にして検証に入ろう。RTX 4090 FEと比較するために「GeForce RTX 3090 Founders Edition」(以下、RTX 3090 FE)を準備。さらにファクトリーOCモデルだがRTX 3090 Tiと「Radeon RX 6950 XT」(以下、RX 6950 XT)搭載カードも準備した。RTX 3090 Ti搭載カードは水冷ユニットと合体した超ハイエンドモデルであり、TGPは480W設定のモンスターカードである点を考慮したい。
CPUはCore i9-12900Kをベースに以下のものを準備した。OSは確実性を重視し、Windows 11 21H2で実施。またReSizable BARやSecure Boot、コア分離(VBS)やHDRといった要素はすべて有効化している。
高負荷ほど輝きが増すRTX 4090
ではいつも通り、「3DMark」のスコアー比較から始めよう。RTX 3090→4090の差分を考えると、4Kで描画するFire Strike UltraやTime Spy Extremeで差をつけると予想できる。
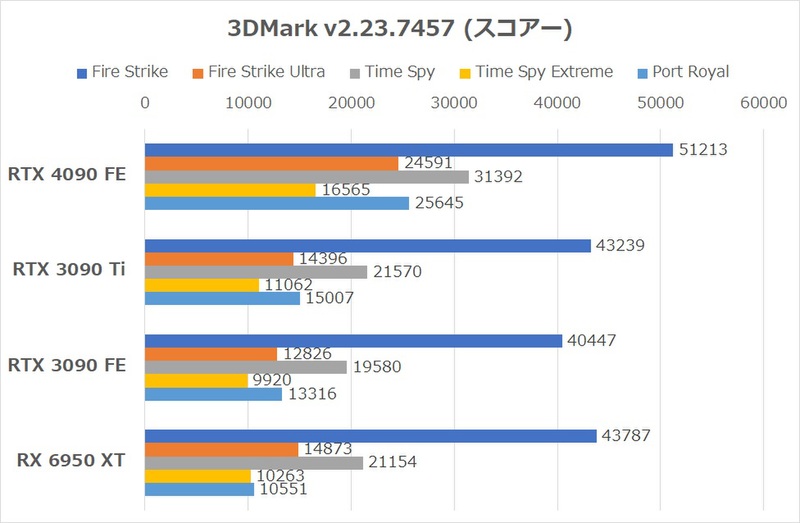
見事、すべてのテストにおいてRTX 4090 FEはRTX 3090 TiやライバルのRX 6950 XTを置き去りにする高スコアーを叩きした。Fire Strikeでは従来のGPUに比して17〜27%程度しかスコアーが伸びていないが、Fire Strike Ultraでは約65〜92%、Time Spy Extremeでは約50〜67%と、負荷の高いテストほどRTX 4090 FEの伸びが目立つ。Port Royalでは、約71〜143%増という非常に大きいゲインが観測できたが、これはRDNA 2世代のRadeonのレイトレーシング性能がGeForceに比べ低いことも原因といえる。
消費電力はTGPに連動して増加
次は消費電力を見てみよう。ラトックシステム「RS-WFWATTCH1」を利用してシステム全体の消費電力を計測した。システム起動10分後の安定値を“アイドル時”、3DMarkのTime Spy Graphic Test 2実行時のピーク値を“高負荷時”、Cyberpunk 2077プレイ中(4K、最高画質、DLSSオフ)のピーク値を“CP2077プレイ時”とした。
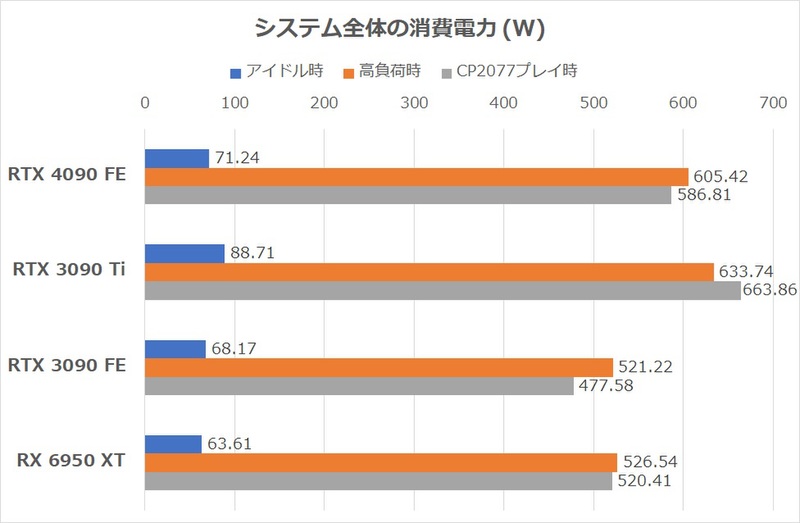
TGPが450Wになったぶんだけ、RTX 3090 FEから消費電力は増えている。RTX 3090 FEのTGPが350W、RTX 4090 FEが450Wなので差は100W。実測値もほぼこれに近い。今回準備したRTX 3090 Tiカードの消費電力はRTX 4090 FEを上回ったが、これはこのカードのTGPが480W設定であるためだ。まだパフォーマンス開示が許可されていないRTX 4090のファクトリーOCモデルでは、今回のRTX 3090 Ti以上の消費電力になる事はほぼ間違いないだろう。
ちなみに、この検証におけるRTX 4090 FEは補助電源ケーブルを4本接続し、最大600Wまでブーストできる状態だが、消費電力の実測値はほぼTGP通りだった。では、補助電源ケーブルを4本接続してTGP600Wに設定した場合と、TGP450Wに設定した場合、そしてケーブル3本で接続した場合で、性能や消費電力はどう変化するのだろうか。それぞれの3DMarkのスコアーと、消費電力をチェックしてみた。
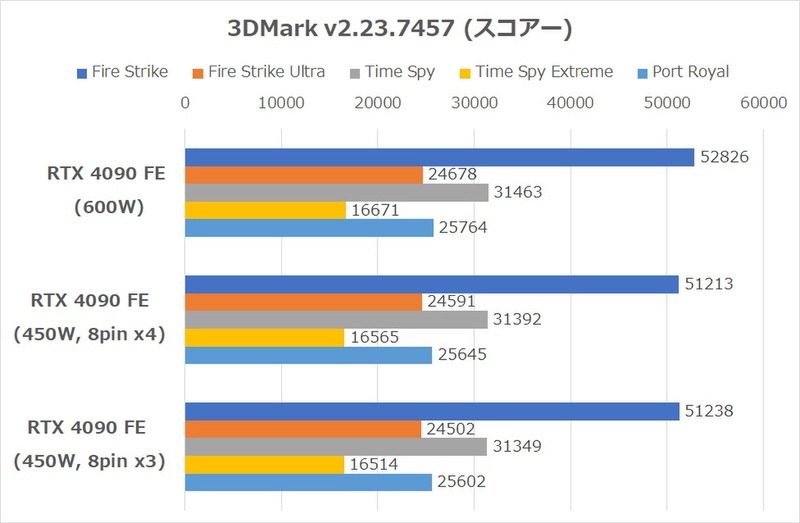
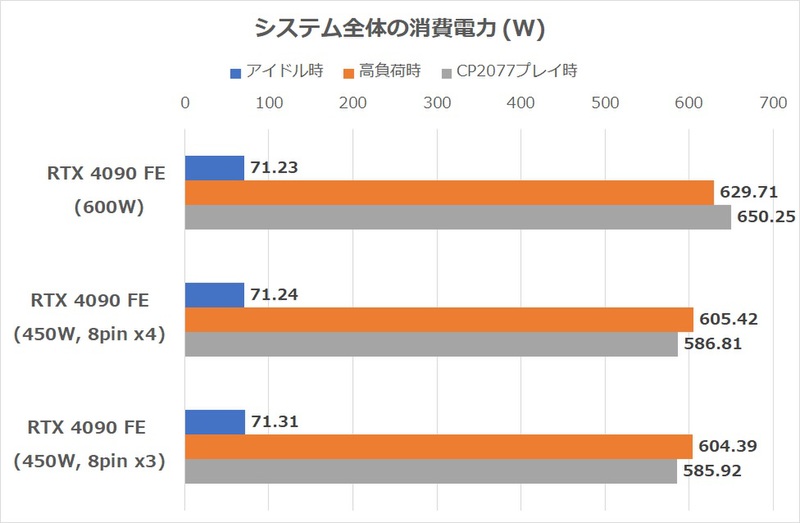
まず、補助電源ケーブルは8ピン3本でも4本でも性能や消費電力に差といえそうな差は観測されなかった。微妙に3本構成の方が3DMarkのスコアーが低い印象があるが、この程度では差といえない。TGPはどちらも450Wなのだから、450Wぶんの仕事をしていると言うべきだろう。まあ、変換ケーブルのうち1本接続せずにプラプラさせておく理由もないので、4本全部接続した方が良いことは間違いない。
一方、4本接続してTGPを600Wに設定すると、4本接続してTGP 450Wに設定した時よりも明らかにスコアーが上昇するが、消費電力も激増する。特にCyberpunk 2077プレイ時の消費電力は60W以上増えているが、TGPの伸び幅(150W差)を考えるとかなりマイルドである。この検証ではRTX 4090 FEのクロック設定を弄らずTGPだけ増やした設定なのでこうなったと考えられる。
貴重な借り物をOCして検証する時間の余裕がなかったためこれ以上は踏み込まなかったが、ファクトリーOC版RTX 4090を使うのであれば、大出力(1000W〜)電源の準備は必要だ。ただ、電源メーカーのPCI Express Gen 5(12VHPWR)対応は遅いため、当面は既存の電源ユニットを変換ケーブルで使い続けるのが無難だろう。
ゲーム検証編に続く!
今回は検証前の解説がメインになってしまったが、本稿はひとまずここまでにしたい。次回は、本命となるゲームパフォーマンスの検証データをお目にかけたい。Ada Lovelaceの真の実力やいかに?

この記事に関連するニュース
-
Nvidia次世代GPU「RTX5090」前モデル比で約36%クリエイティブ性能向上―「Blender」ベンチマークにて確認
Game*Spark / 2025年1月20日 23時1分
-
219ドルのIntel「Arc B570」実力検証! Arc B580/A750、RTX 4060、RX 7600と真っ向勝負させてみた
マイナビニュース / 2025年1月16日 23時0分
-
GeForce RTX 50だけではない! 社会がAIを基礎にしたものに置き換わる? 「CES 2025」で聴衆を圧倒したNVIDIAの最新構想
ITmedia PC USER / 2025年1月10日 17時40分
-
1599ドルのRTX 4090と549ドルのRTX 5070の性能が同じ? 熱狂と興奮のNVIDIA基調講演レポート
ASCII.jp / 2025年1月7日 21時15分
-
NVIDIAが新型GPU「GeForce RTX 50シリーズ」を発表 新アーキテクチャ「Blackwell」でパフォーマンスを約2倍向上 モバイル向けも
ITmedia PC USER / 2025年1月7日 18時50分
ランキング
-
1デジ庁、「e-Gov電子申請アプリ」アップデート 更新前に旧バージョンのアンインストール必須
ASCII.jp / 2025年1月20日 16時15分
-
2ソフトバンクが10年ぶりにGalaxyを扱う3つの理由、「月額3円」なぜ実現? 発表会場でキーパーソンを直撃
ITmedia Mobile / 2025年1月23日 11時51分
-
3リアルタイムで文字起こし&翻訳、しかも利用料ゼロ 異色のAIタブレットの実力
マイナビニュース / 2025年1月23日 11時0分
-
4「許さない」 しまむら、“新作ディズニーアイテム”が完売多数で転売 2万5000円での出品も…… 「本当やめて」と怒りの声
ねとらぼ / 2025年1月23日 13時43分
-
5DIYで室温が約10℃変わった「トイレの寒さ対策」が310万再生 コスパ最強のアイデアへ「天才!」「これすごくいい」
ねとらぼ / 2025年1月23日 8時30分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





