

Ada Lovelaceのダイ3種からわかる性能の違い NVIDIA GPUロードマップ
ASCII.jp / 2022年10月31日 12時0分

半年に1回の頻度になっているNVIDIAのロードマップ。前回はHPC向けのHopperだったが、今回はやっと発表されたAda Lovelaceの話である。

もう1ヵ月も前の話になるが、9月21日に開催されたGTC 2022の基調講演で、GeForce RTX 4080およびGeForce RTX 4090が発表された。もっともこの時に発表されたGeForce RTX 4080のうち、12GB版に関しては発売を中止する(少なくともGeForce RTX 4080の名は冠さない)ことを10月14日に発表しており、いきなり味噌がついた感もなくはない。
すでに、ハイエンドであるGeForce RTX 4090は店頭販売も始まっており、KTU氏による渾身のベンチマークその1、その2、その3が掲載されており、御覧になった読者も多いだろう。これに続き11月16日(米国時間)にはGeForce RTX 4080の発売も開始されるわけで、またKTU氏が徹夜でベンチマークを回しておられるであろうことは想像に難くない。
さて、Ada Lovelaceの内部構造の速報版および詳細解説もすでにKTU氏の手で行なわれているのであまり書くこともないのだが、少しだけ補足をしておきたい。
Ada Lovelaceのホワイトペーパーはすでに公開されているが、最新バージョン(v1.03)は12GB版GeForce RTX 4080のキャンセルを受けてAD104の記述が省かれている。ただその前のバージョンではAD102/AD103/AD104という3種類のダイがあることが明確に記述されている。
下表は、そのホワイトペーパー(v1.01)のAppendixに記されたスペック一覧から、AD102/103/104を抜き出してまとめた物である。
一番特徴的と思えるのは、AD103の出現だろう。下表は、Pascal以降のコンシューマー向け製品のうち、コアの型番と製品の関係をまとめたものだ。通常102がエンスージアストもしくはワークステーションのトップエンド向けという位置づけにあり、その下に104が来て、これはxx80ないしxx70グレードの製品となる。
メインストリーム向けはその下の106グレードになり、ここがxx70ないしxx60グレードである。107/108はバリューないしOEM向けという扱いで、Pascal世代ではGP107/GP108という製品があったほか、表には入れていないがTuring世代のGeForce GTX 1600シリーズの場合はGeForce GTX 1630/1650(の一部)がTU117を使っているが、Ampere世代では106がローエンドになってしまっている。
そろそろダイを複数作るための初期コストが高騰しすぎて、106をローエンドに持って行った方が結局安価になったためと思われる。
ちなみに上表には(*)を付けた謎のGA103が湧いているが、これはTom's Hardwareが今年2月に報じたもので、ZotacがGA103ベースのGeForce RTX 3060 Tiをラインナップしたというもの。

ただ記事にもあるように、このGA103というのは本来デスクトップ用ではなく、GeForce RTX 3080 Ti Mobile用に開発したもので、これをデスクトップ用に転用した形であり、おまけに全世界で販売されているモデルではない(中国本土向け専用?)ので、例外としていいだろう。
AD103をわざわざ製造したのは 600mm2のダイに使うのはコスト的に割に合わないから
Ada Lovelaceの場合、トップエンドのGeForce RTX 4090がAD102なのは従来と同じだが、続くGeForce RTX 4080向けに新たにAD103をわざわざ製造し、これを充てているのが従来と大きく異なる部分だ。そしてキャンセルされた結果として、GeForce RTX 4070あたりにリブランドして出てくると思われるGeForce RTX 4080 12GBは、AD104を使うことになっている。
なぜこんなことに? に関する公式な表明はもちろんないので筆者による推定なのだが、Ada Lovelaceのホワイトペーパー表を見るとなんとなくわかる。AD102は、TSMCの4Nプロセス(*1)であり、基本的なジオメトリやトランジスタ密度はTSMC N5と大きく違わない(*2)と考えられる。
(*1) これはTSMC N4をベースにしたNVIDIAカスタム版プロセスとされるが、基本的にはTSMC N4と同等と考えていいだろう
(*2) N4の改良型であるN4PはN5比で6%トランジスタ密度が向上したとしているが、N4のトランジスタ密度は明確に言及がない
それでいて608.5mm2というダイサイズは、もうGPUというよりはAIのそれも学習向けプロセッサーに比肩しうる規模である。AIの学習向けプロセッサーが最低でも数十万、通常は百万円台の値段付けがされていることを考えると、いかにNVIDIAといってもこのAD102のカットダウン版などを使ってGeForce RTX 4080を作るのはコスト的に割に合わないと判断したものと思われる。
もともとAD102は12GPCの構成になっているにも関わらずGeForce RTX 4090は1GPCを無効化した11GPC構成で発売されている。
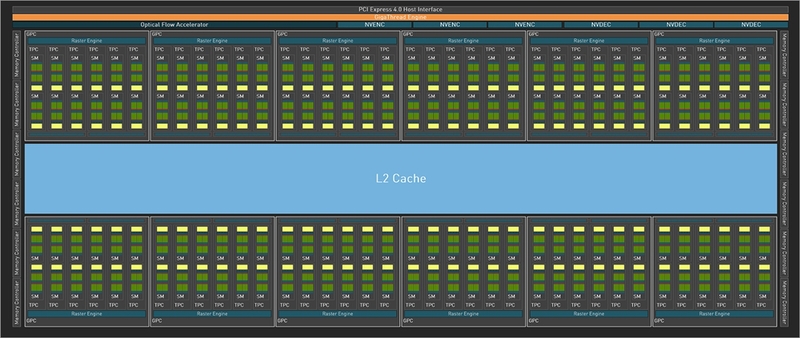
これは将来、12GPC構成となるGeForce RTX 4090 Tiなどを出荷するためのヘッドルームになるが、その一方ですでに欠陥があるダイであってもGeForce RTX 4090で救えるわけで、ここでさらにGPC構成を絞ったGeForce RTX 4080を投入したところで、その数は需要を十分に満たせるほどにはないだろう。
なにしろ600mm2のダイということは、1枚のウェハーから取れる個数は100個前後でしかない。TSMCのN5プロセスの場合、おおよそのウェハー1枚のコストは1万7000ドルほどで、つまり歩留まりが100%だとしてもダイ1つあたりの製造原価は170ドル。実際には200ドル近いと考えていい。
これにGDDR6X、基板、電源周りのパーツ、それに実装コストなどを考えると、定価1599ドルのGeForce RTX 4090はともかく、1199ドルのGeForce RTX 4080に使うと、赤字にはならないもののかなり利幅は薄いものになるだろう。将来の競合製品の投入の際の値下げの余地などを考えると、到底600mm2のダイではわりに合わないと判断したとしても無理もない。
ここまでは理解できるのだが、今ひとつ理解できないのが、AD103とAD104である。現状AD103とAD104のダイそのものの構成(製品構成ではない)は公開されていないが、普通に考えるとどちらもフル構成ではなく、歩留まり向上のために無効化しているGPCがあると考えるべきだろう。
つまりAD103は本来8GPC、AD104は6GPC構成で、ここから1GPC無効化してそれぞれ製品化する予定と考えられる。この構成の話は後述するとして、8GPCと6GPCはスペック的に近くないだろうか? ということだ。これはダイサイズにも反映されている。
AD102は12GPCで763億トランジスタ、608.5mm2。対してAD103は8GPCで459億トランジスタ、378.6mm2。AD103を基準に考えるとAD102はトランジスタ数が1.66倍、ダイサイズが1.60倍といったあたり。GPCの数が1.5倍なのを考えれば、おおむね納得できる寸法比とトランジスタ比である。
同様にAD103とAD104についても、AD104を基準に考えるとダイサイズが1.28倍、トランジスタ数が1.29倍ということで、これも8GPC vs 6GPCの比を考えれば比較的納得しやすい。ただ演算性能などの数字を見るとわかるが、そんなに大きな違いではない。
実際NVIDIAが当初はAD104をGeForce RTX 4080 12GB版として売ろうとした理由も理解できる。GeForce RTX 4070とするにはやや性能が近すぎるからだ。もちろんAda Lovelaceのホワイトペーパーにある数字は理論上のピーク性能であり、また描画性能そのものではないので、実際のゲームなどでは主にメモリー帯域の違いでもう少し性能差が出てくる可能性がある。
過去のコアのSM数(製品別ではなく、コアに本来実装されているSM数である)を比較したのが下表であるが、Ada Lovelaceの構成はTuringに近いのがわかる。
AD102はそのままTU102として、AD103をTU104、AD104をTU106に相当すると考えると、SM数の比率そのままである。そう考えると、AD103を使ったGeForce RTX 4080のコア構成は、TU104を使ったGeForce RTX 2080のSM数を倍増したような構成になると考えられるし、実際冒頭のホワイトペーパーで示したGeForce RTX 4080とGeForce RTX 2080の構成の比率はかなり近い。
(GeForce RTX 4070になるであろう)GeForce RTX 4080 12GB版の構成がわりとAD103に近いのは、グレード別に明確に差をつけるというよりはむしろ性能を隣接させることでGeForce RTX 4080 12GB版のお買い得感を高めて、こちらの売上を増やしたかったのではないか、と想像する。
GeForce RTX 4080のGPCとTPCを削ったのは性能調整のため?
ところで、不思議なのがAD103を使ったGeForce RTX 4080の構成である。基本に戻るが、Ada LovelaceではAD102は12GPCだと公言されている。おそらくAD103は8GPC、AD104は6GPC構成になっている。1つのGPCは6つのTPCと16個のROPから構成される。1つのTPCは2つのSMとPolyMorph Engineから構成される格好だ。

ということは、GeForce RTX 4080は7GPCである以上TPCは42個、SMは84個になるわけだが、実際には38TPC、76SM構成である。つまり7GPCに減らしたうえに、さらに4TPCを削った構成というわけだ。
もちろんこれまでもこうした例はNVIDIAの製品にはあったから、これが初めてというわけではないのだが、単に性能調整ないし消費電力調整のためにこうした実装にしたのか、それとも他の理由があるのかは不明である。
性能調整あるいは消費電力調整のためだとすると、妙にマッチしないのがメモリーである。再びホワイトペーパーの表に戻るが、GeForce RTX 4090やGeForce RTX 4080 12GB版の場合は21GbpsのGDDR6Xでこれは順当な構成なのだが、GeForce RTX 4080のみ、まだ出荷量も多くなく高価なGDDR6Xの22.4Gbpsを採用しているのだ。
実のところGDDR6に関して言えば、かつてはGDDR6に比べて低い消費電力で高い帯域を実現できるという売り込み文句で発表されたものの、対抗馬であるGDDR6の方はすでに24Gbps品のサンプル出荷が開始されているという状況で、速度面でのアドバンテージはほとんどない。
そしてGDDR6XはMicronのみが製造、NVIDIAのみが採用という状況に変化はなく、当然ながら相対的に価格は高止まりせざるを得ない。もし性能調整が目的でTCP/SM数を減じているのなら、もう少し性能を下げてGDDR6X 21Gbps版を採用すればコストも下げられ、入手性も相対的にマシであっただろうと思うのだが、どういう意図でこうした高価格のGDDR6Xを採用する決断に至ったのかは想像がつかない。
全体的に見て、GeForce RTX 4080のバランスの悪さが、筆者的にはどうにも気になるところである。間もなく発表されるであろうNAVI 3ベースのRadeon RX 7000シリーズと戦うのにこれで十分という判断なのだろうとは思うのだが。

この記事に関連するニュース
-
サイコム、RTX 40シリーズ搭載ゲーミングPCに『インディ・ジョーンズ/大いなる円環』をバンドル
マイナビニュース / 2024年11月22日 14時45分
-
iiyama PC、GeForce RTX 4080 / 4090 Laptop搭載17型ノートPC
マイナビニュース / 2024年11月19日 12時13分
-
iiyama PCより、GeForce RTX™ 4090 LAPTOP GPU搭載 17型BTOノートパソコンを発売
@Press / 2024年11月18日 18時10分
-
iiyama PCより、GeForce RTX™ 4080 LAPTOP GPU搭載17型BTOノートパソコンを発売
@Press / 2024年11月18日 17時0分
-
iiyama PC、Ryzen 7 9800X3D搭載ゲーミングPC発売開始
マイナビニュース / 2024年11月15日 13時9分
ランキング
-
1Twitter Japanが社名変更、「X Corp. Japan」に
ITmedia NEWS / 2024年11月24日 15時8分
-
2“熱狂”のファミコン版『ドラクエ3』発売日を、当時の新聞各社はどう報じた?後世まで語り継ぐべき名記事も発掘
インサイド / 2024年11月24日 17時0分
-
3「ドラクエ3」HD-2D版にファミコンで挫折したおっさんマンガ家も夢中! ネットで評価が割れた理由とは?
ITmedia NEWS / 2024年11月24日 12時20分
-
4Minisforumが「ブラックフライデー」を開催! 新商品も最大41%お得に買える
ITmedia PC USER / 2024年11月24日 0時0分
-
5【格安スマホまとめ】povo2.0、ローソンに行くと月1GB貰える! コラボが本格スタート
ASCII.jp / 2024年11月24日 15時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





