

メモリー帯域を増やして性能を向上させたRDNA 3の内部構造 AMD GPUロードマップ
ASCII.jp / 2022年11月21日 12時0分

前回に引き続き、RDNA 3の内部解説を説明しよう。今回は内部構造の話である。下の画像がNavi 31の内部構造の全景である。比較対象のために、Navi 21の内部構造をその下に掲載する。
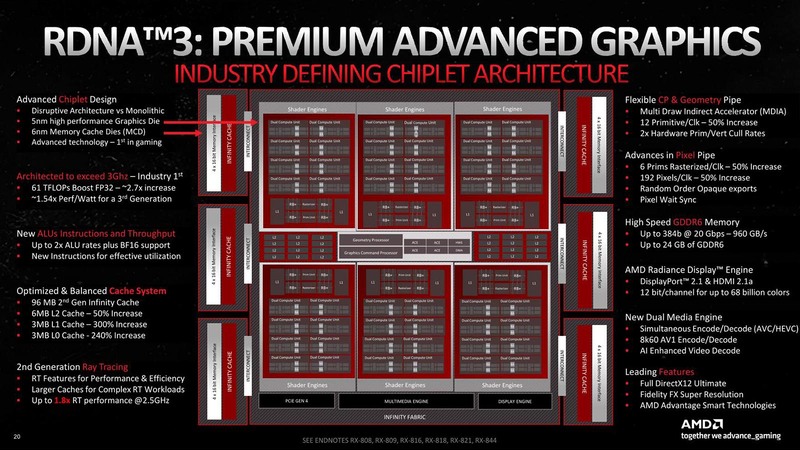

このレベルで見て判る違いは以下のとおりだ。
- Shader Engineが4→6へ強化。ただし1つのShader Engineに含まれるCUの数は10→8に減った。
- 2次キャッシュが4MB(256KB×16way)から6MB(256KB×24way)に増量
PCI Expressに関しては、Gen 5は不要と判断した(実際純粋なGPUとして使う限りにおいてはGen 4で十分である)とのこと。またCXLにも未対応だそうだが、これも別に不思議ではない。
さて、CUあたりの性能が倍になった、という話はRadeon RX 7000シリーズの発表記事でも触れられているが、その詳細が下の画像だ。
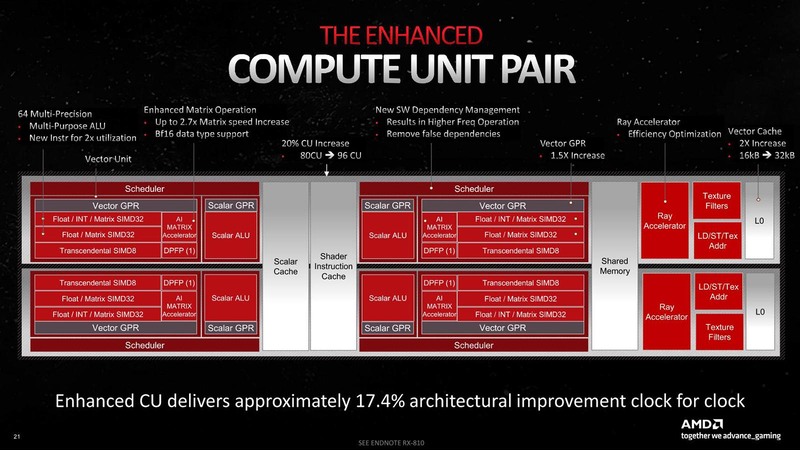
わかりづらいが、2つのCUでScalar CacheやShader Instruction Cache、Shared Memoryを共有しているという話で、ここは初代RDNAとまったく一緒である。
異なるのは演算ユニットの数である。RDNA/RDNA 2では1サイクルあたり2つの32-Wide SIMDが動作していた。そもそもGCNの世代はWave 64(64 Threadの塊)に対して、4つの16-Wide SIMDが同時に動作することで、1サイクルで1 Wave 64の処理を行なう形になっていた。
これがRDNA/RDNA 2ではWave 32(32スレッドの塊)に分割され、そのWave 32を32-wide SIMDで処理する格好になっていた。RDNA/RDNA 2ではこの32-wide SIMDがCUあたり2つ搭載されており、1サイクルあたりWave 32を2つ、つまりWave 64を1つと同じ処理性能になっていた。
RDNA 3では、このWave 32を1サイクルあたり4つ処理できるようになっている。要するにSIMDエンジンが倍増した格好だ。もっとも内部的に見ると、やや複雑な話になっている。
というのは、Wave 64が再び復活しているからだ。SIMDエンジンも64-Wide SIMDになっている。ただしこのSIMDエンジン、1サイクルあたりWave 64を1つ、もしくはWave 32を2つ処理できるようになっており、SIMDエンジンあたりのピーク性能はRDNA 2までと変わらない。したがって内部を見ると、32-Wide SIMDエンジン×2と見えないこともないが、実装としては64-Wide SIMDと考えた方が正しい。
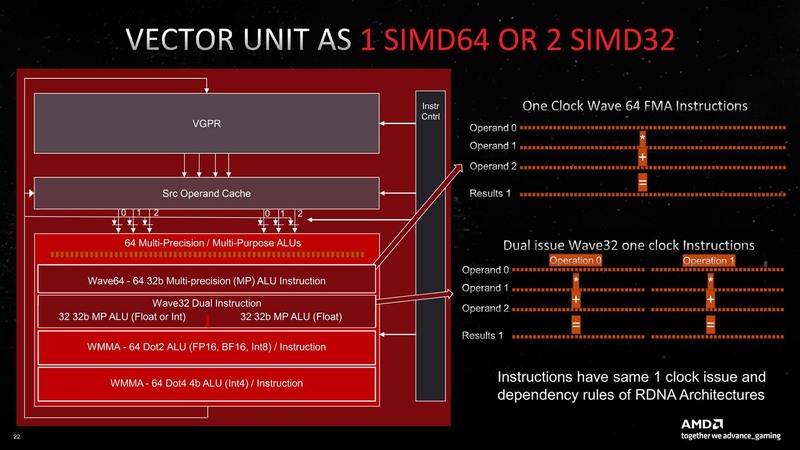
このWave 64とWave 32はさすがに混在できないようで、どちらかで動くことになる。このSIMDエンジンが、上の画像にあるように、1つのCUに2つあるわけで、この結果Wave 64なら2つ、Wave 32なら4つを1サイクルで処理できることになる。
これで性能はRDNA 2世代に比べてきっちり倍である。実際にはCU数も80から96と2割増しになっているわけで、同じ動作周波数だとしてもピーク性能はRDNA 2(というかNavi 21)の2.4倍になる計算だ。他にもあちこち手を入れることで、効率そのものも17.4%向上させたとあり、これを加味すると同一周波数での性能はNavi 21比で2.8倍あまりになる。
ちなみに素朴な疑問としてあったのは「なぜCU数を増加させず、CU内の演算能力を倍増させたか」であるが、これは何人かの人に聞いたものの明確な回答はなかった。
ただMike Mantor氏(Corporate Fellow & Chief GPU Architect)によれば「CU数を倍増させた場合も当然検討したし、他のアプローチも試してみた。その中で(今回の実装が)一番性能が出た」という返答であった。CU数をむやみに増やすとスケジューラーの側が追い付かなかった、というあたりが正直なところなのかもしれない。
なおWGPに関しては引き続き1 WGP=2 CUの関係が維持されているそうで、RDNA 2までの仕組みを大きく変えることなく性能を倍増させるにはCUあたりの性能を引き上げるのが一番楽だった、という可能性もある。
これだけでもわりと性能向上が著しいわけだが、これに加えて新しくDot積の演算エンジンが追加された。2つ前の画像で“AI Matrix Accelerator”と記述されているユニットのことだ。Dot積(Dot Products)はAIプロセッサー連載で何度も出てきているのでおなじみかと思うが、下の画像の右側にその定義が載っている。
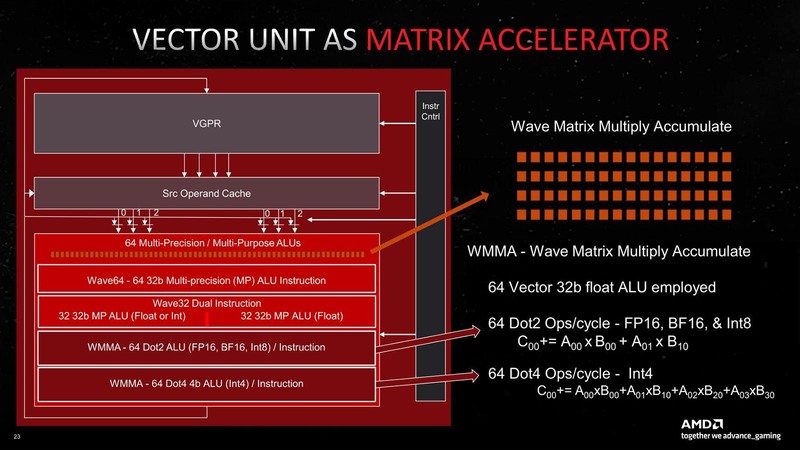
RDNA 3の場合、FP16/BF16/Int 8に対してDot 2(2項目のDot積)が、Int 4に対してはDot 4(4項目のDot積)がそれぞれ実行可能である。どちらも64-Wideになっており、Dot 2の場合は256Flops(1サイクルで乗算と加算をそれぞれ2つ実行するから)、Dot 4の場合は512Flops(同4つ実行)という計算になる。
要するにこれ、NVIDIAのTensor CoreやインテルのXMXと同じような仕組みで、畳み込み演算を高速化するアクセラレーターと考えれば良い。このWMMA(Wave Matrix Multiply Accumulate)の動作を別の図で示したのが下の画像だ。
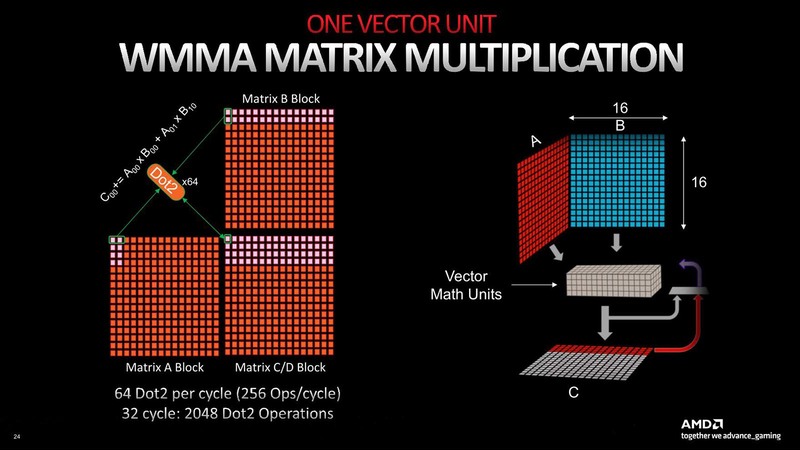
このDot 2なりDot 4の命令を毎サイクル発行するのは、プログラムの肥大化やスケジューラーの負荷増大につながるわけだが、WMMAでは32サイクルまとめての処理が可能、つまり1回命令を発行すると、32サイクルずーっとDot 2/4の演算を行なってくれるわけであり、この間にプログラムは他の処理をさせることも可能だ。これにより効率的にAI処理が可能、という話になっている。
※お詫びと訂正:RDNA/RDNA 2のWaveに関する記述に誤りがありました。記事を訂正してお詫びします。(2022年11月24日)
Shader Model 6.4に対応したAPIを提供 この中でWMMAを直接呼び出す
ところで問題はWMMAをどうやってアプリケーションから使うのか? という話になる。これもいろいろ聞いてみたのだが、将来的にはROCmでサポートする(現在は独自フレームワークを利用するが、それを提供するという話は特に出ていない)など、XDNAでのサポートも「するんじゃないかな」みたいなハッキリしない返事だった。
このあたりはテクニカルライターの西川善司氏と議論したのだが、可能性として一番高そうなのはShader Model 6.4をサポートする形で利用するというものだ。
Shader Model 6.4はDirectX 12以降でサポートされるもので、このShader Model 6も6/6.1/6.2/……とどんどん進化しているし、すでに6.5のアナウンスもあるのだが、ポイントとなるのはShader Model 6.4ではまさしくWMMAが提供するようなDot 2/Dot 4のAPIが用意されることと、マイクロソフトの提供する機械学習向けフレームワークであるDirectML(Direct Machine Learning)の要件がShader Model 6.4以降となっていることだ。
つまりAMDはドライバーの中で、Shader Model 6.4に対応したAPIを提供し、この中でWMMAを直接呼び出せるようにする。マイクロソフトはDirectMLの中で、このShader Model 6.4対応のdot2add()やdot4add_u8packed()/dot4add_i8packed()を呼び出してAIフレームワークを動かすので、アプリケーションがDirectMLを利用してAI処理を行なう場合には自動的にWMMAが利用される、というわけだ。
NVIDIAの場合は、まだそうしたフレームワークがなにもない時にTensor Coreを実装したから、CUDAの中でそうしたものを全部扱えるようにしたわけだが、AMDやインテルは「すでにAPIがあるから、それを使えば良い」という方針のように思える。
もっともShader Model 6.4をLinuxなど非Windows環境から使う場合もあり得るから、なにもしないで済むわけでもなく、それこそROCmなりXDNAなりでなんらかの対応をする必要はあると思うが、現時点では具体的にどうするかまだ決まっていないために明確な返答が出せない、というあたりに思える。
強力なキャッシュ/メモリー構成 帯域強化で1.5倍のラスタライゼーション性能を実現
さて話を戻すが、演算ユニットの性能が大幅に強化された以上、メモリーアクセス性能もこれに合わせて強化しないと無駄になる。そのあたりもわかったもので、RDNA 3ではなかなか強力なキャッシュ/メモリー構成になっている。下の画像がRDNA 3のキャッシュ/メモリー構成である。

比較対象のために、RNDA 2のものを下の画像に示すが、以下のような猛烈な帯域強化が行なわれている。
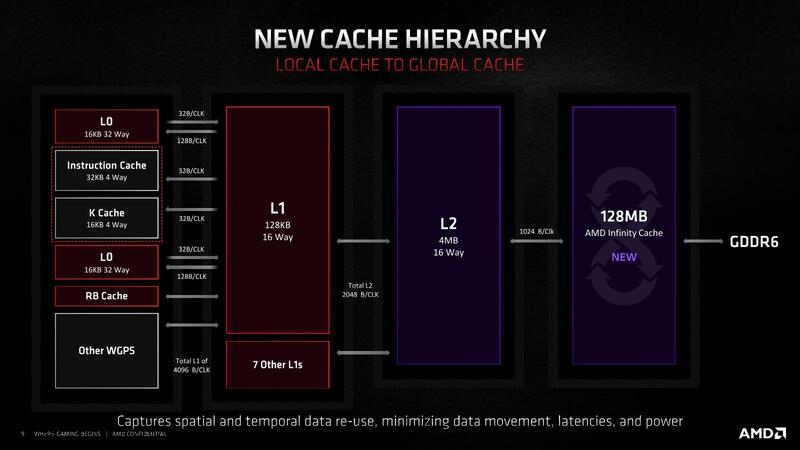
- 4 Shader Processor→6 Shader Processorになった結果として、1次キャッシュのトータル帯域は4KB/サイクルから6KB/サイクルに強化
- 1次キャッシュと2次キャッシュの間の帯域も2KB/サイクルから3KB/サイクルに強化
- 2次キャッシュとインフィニティ・キャッシュの帯域も1KB/サイクルから2.25KB/サイクルに強化
ちなみに1KB/サイクルというのは、2.5GHz駆動であれば2.5TB/秒に相当するわけで、その帯域の広さがおわかりいただけるかと思う。もちろんメモリーも、RDNA 2のRadeon RX 6950 XTが18Gbps/256bitで576GB/秒だったのに対し、RDNA 3のRadeon RX 7970 XTXは20Gbps/384bitで960GB/秒に達する。倍まではいかないまでも1.67倍に強化されているわけだ。
最終的な描画性能はこのメモリーアクセス性能とROPユニット(ラスタライザー)の性能で決まるわけだが、シェーダーエンジンあたりのラスタライザーの数は32のままのようである。ただシェーダーエンジンの数そのものが1.5倍になったことで、Navi 31はNavi 21の1.5倍のラスタライゼーション性能を実現している。

ということで、ピークの描画性能そのもので言えば、このラスタライザーの性能比の1.5倍ということになる。ただし、ただし、シェーダーエンジンあたりの演算性能そのものは1.6倍になっている計算(CU数は20→16に減っているが、演算性能が倍増)なので、ラスタライザーやメモリー帯域以前に演算処理がボトルネックになっていたようなケースでは、より性能が上がる可能性はあり得る。このあたりは最終的にベンチマークで比較してみないとわからないので、KTU氏に頑張っていただきたいところだ。
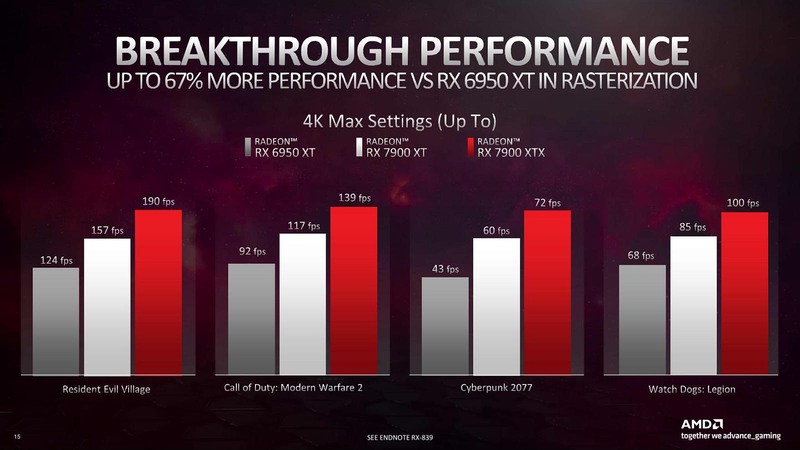
AMDが示したベンチマークの結果が下の画像だ。Radeon RX 6950 XT比で言うとRadeon RX 7900 XTXはResident Evil Villageで53.2%、Call of Duty:Modern Warfare 2で51.1%、Cyberpunk 2077で67.4%、Watch Dogs: Legionで47.1%、それぞれフレームレートが向上しているとされる。上の計算がそう間違っていないということであろう。
レイトレーシングが1.8倍高速化
最後にレイトレーシング周りについて。今回、劇的に性能が向上した的な話は残念ながらなしである。とは言え、細かく改良がなされている。まずカリング(視点から見えないポリゴンをレンダリングしない高速化技術)周りで言えば、RDNA 2のLate CullingからRDNA 3ではEarly Subtree Cullingに切り替わっている。

要するに、レイトレーシングをかける前に不要な計算を省こうという話である。他のオブジェクトの影に隠れて描画されないオブジェクトの計算をやっても仕方がないから、という話だ(厳密に言えばそうでもないのだが、これは描画品質と速度のバーターということになる)。
また複数のオブジェクトのレイの計算順序を変えられるようになった。これによって、シーンに応じて最適な(つまり高速な)処理が可能になる。

加えて、レイの計算順序の最適化やスタック管理の最適化、さらにキャッシュの増量などの効果により、トータルで1.8倍に高速化されたとしている。

もっとも、元のRDNA 2のレイトレーシング性能そのものは競合のGeForce RTX 3000シリーズに比べるとかなり見劣りするもので、それが1.8倍になってもまだ厳しいところはある。実際、ベンチマーク結果で言えば下の画像のとおり。
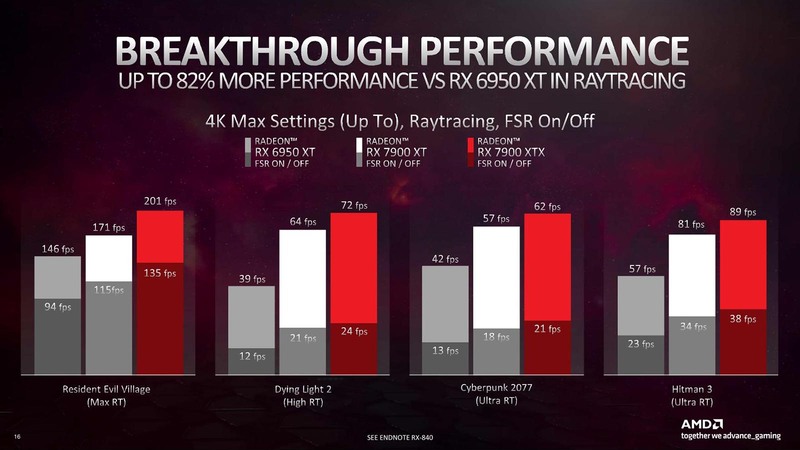
FSRを無効化した状態での性能向上率はResident Evil Villageで43.6%、Dying Light 2で100%、Cyberpunk 2077で61.5%、Hitman 3で65.2%と素晴らしいのだが、生の数字で言えばResident Evil Village以外は20~30fps台でややプレイ云々以前のレベルである。
FSRを併用すればご覧のように60fpsを超えたフレームレートが実現されているが、まだGeForce RTX 4000に追いつくのは遠いと考えた方が良さそうである。
ハードウェア周りで言えばもう1つ、動画のエンコーダー/デコーダーの話がある。こちらはあまりDeep Diveでも詳細は語られなかったので、KTU氏のレポート以上の情報はないのだが、プレイ動画の配信をH.264からAV1に変更するとどうなるか? という実例で示されたのが下の画像である。こうなってくるとエンコーダーソフトの対応が待ち遠しいところである。
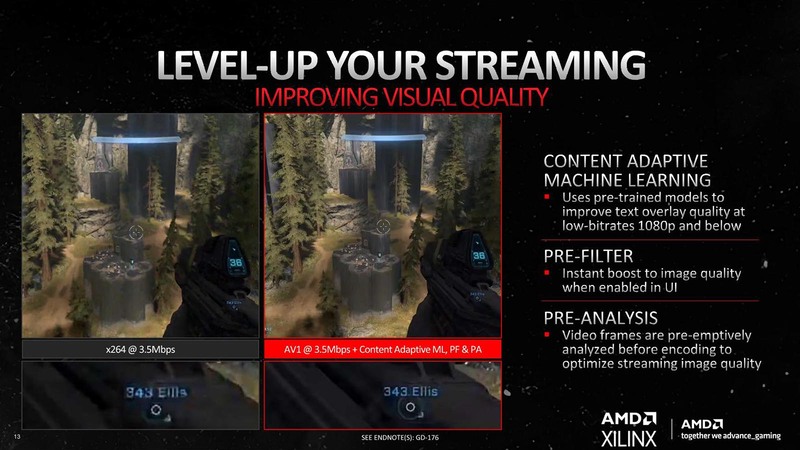
ソフトウェア周りなどに関しては今回説明を割愛するが、なにか劇的に新しいものが用意されたわけではない。FSR 3に関しても現時点ではプレビューのみで、具体的な実装方法などは不明なままである。
このあたりは製品発売日である12月13日以降に、もう少し情報が出てくるかもしれない(可能性で言えば、来年のCESで実際のゲームに組み込んだデモが行なわれ、その後でもう少し詳細が出てくるという確率の方が高そうだが)。とりあえずはRadeon RX 7900 XT/XTXのベンチマークが待ち遠しいところだ。

この記事に関連するニュース
-
【FRONTIER】 シリーズ最新作 『Call of Duty(R): Black Ops 6』動作確認済みPCの販売を開始
PR TIMES / 2024年11月25日 12時15分
-
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分
-
Ryzen 7 9800X3Dを試す - ゲーミングCPUの本命か? 第2世代3D V-Cacheの威力を徹底検証
マイナビニュース / 2024年11月6日 23時0分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
-
AI性能を引き上げるInstinct MI325XとPensando Salina 400/Pollara 400がサーバーにインパクトをもたらす AMD CPUロードマップ
ASCII.jp / 2024年10月28日 13時0分
ランキング
-
1メルカリ、不正利用へのサポート強化と補償方針を発表 ネットで意見「当たり前」「個人的には期待」「悪意のあるやつは排除して」
iza(イザ!) / 2024年11月25日 13時21分
-
2ビューカード、顧客との通話内容を録音したSDカード20枚を紛失
ASCII.jp / 2024年11月25日 17時5分
-
3AppleのSafariに関し、英CMAが「ブラウザ市場に悪影響」と調査勧告
ITmedia NEWS / 2024年11月25日 7時25分
-
4スタバ福袋当選発表に悲喜こもごも SNS「3度目の正直来た」「外れてうつになりそう」
iza(イザ!) / 2024年11月25日 12時11分
-
5大容量プランは不要だった? ギガ不足で「低速モード」になったスマホが普通に使えて驚いた
ITmedia NEWS / 2024年11月25日 12時31分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





