

第4世代EPYCのGenoaとBergamoの違いはL3の容量 AMD CPUロードマップ
ASCII.jp / 2022年12月5日 12時0分

前回はSapphire Rapidsの現状をお届けしたが、その対抗馬であるGen 4 EPYCことGenoaの話に触れていなかったので、こちらをお届けしよう。ただその前に1つ、こぼれ話をお伝えしたい。
PCI-SIGがPWR12VHPWに関して注意を喚起
連載662回で12VHPWRコネクターについて説明した。現時点でこれを積極的に採用しているのはNVIDIA一社で、GeForce RTX 3000世代ではまだOEMベンダーの中には従来式の8ピンコネクターを使う所も目立ったが、GeForce RTX 4000世代ではこの12VHPWRコネクターを使うケースが圧倒的に多くなっている。
問題はそのハイエンドであるGeForce RTX 4090で、12VHPWRコネクターの融解現象が報告されていることだ。(レビューの記事の写真5枚目のキャプションでKTU氏も言及されている)この融解現象に関し、ついに米国では集団訴訟が提起されることになった。

こうした現象を受けて、12VHPWRコネクターの規格を策定したPCI-SIGはメンバー企業に対して以下の注意喚起を行なった。要するにポジショントークである。
「以前、あるメーカーが12VHPWRコネクターの利用に関し、安全上の問題がある可能性をPCI-SIGに報告したことをお知らせしたが、これに加えて最新の訴訟についてもお知らせする。」
「この訴訟で原告は、12VHPWRケーブルおよびプラグが『溶融し、深刻な電気的および火災の危険をもたらす』と主張している。PCI-SIGは、12VHPWRコネクターを含むPCI-SIGで策定された技術をもとに製造、マーケティングまたは販売するすべてのメンバー企業に対し、上記訴訟で報告された問題事例のテストを含め、エンドユーザーの安全を確保するために適切かつ慎重なすべての手段を講じる必要性を強く訴えたい。」
「PCI-SIGの仕様は相互運用性のために必要な技術情報を提供するものであり、適切な設計や製造方法、材料、安全試験、安全公差などに対応するものではないことに留意されたい。PCI-SIGの仕様に基づき実装を行なう際、メンバー企業がその製品の設計、製造、および安全性試験を含む試験に責任を負うことになる。」
ちなみにNVIDIAは11月18日に「コネクタをきちんと根本まで差し込むこと」を対策として公開している。
個人的に言えばあの小さなコネクターで50Aを流せるという方が信じられなかったりする。その意味では、8ピンコネクター×3や×4などにしてくれた方がよほど安心できるのだが、それはともかくとして、この注意喚起の声明に関してPCI-SIGに「ECN(Engineering Change Notice)あるいは仕様変更を発行する可能性は?」と確認したところ、「現在ワークグループが現象について調査中である」という返事が返ってきた。
PCI-SIGとしては、別に12VHPWRコネクターはNVIDIAのGPU専用のものではなく、今後登場するであろうアクセラレーターカードなどで広く利用されることを期待しているわけで、今後も類似の現象が発生するのは避けたい以上、ここで問題の洗い出しと対策を徹底したいのだろうということは容易に想像がつく。
ちなみに挿したことがある方ならおわかりだろうが、12VHPWRコネクターはきちんと装着されたかどうか、一見してわかり難い。前述のNVIDIAの対策ページでも「われわれは、GPUカードの電源を入れる前に、確実にコネクターが挿入されていることを確認できる方法について現在調査中である」という文章が入っているほどだ。
なお、上述の訴訟はまだ提起されたばかりで、今後どうなるかは不明であるし、PCI-SIGがなんらかのECNを発行するかも不明である。とはいえ、なにかしらの対策が取られる気はするのだが。
Genoaこと第4世代EPYCが発表
11月10日、AMDは第4世代EPYCプロセッサーを発表した。これまでGenoaとして呼ばれてきた製品である。この発表会の模様はYouTubeでも視聴可能であるが、こちらをベースに解説しておきたい。
まずは製品ラインナップについて。今回EPYCは従来の7000番台から9000番台に番号が切り替わった。この理由については性能のバランスを考えて、という話であったが個人的にはBergamoとの関係を考えてGenoaを9000番台に持ってきたのではないか?という気がしている。
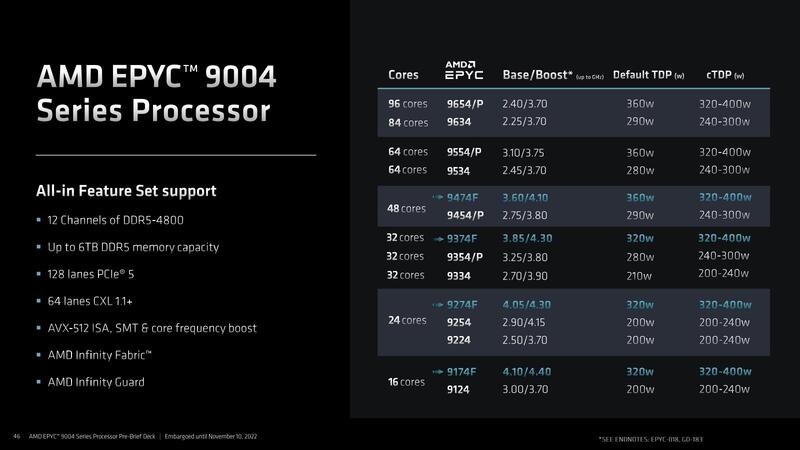
このBergamoは後述するとして、まずは製品ラインナップであるが、16コアから96コアまで全部で18製品となっている。ちなみに価格はここには掲載されていないが、プレスリリースの方には記されており下は1083ドル(EPYC 9124)から上は1万1805ドル(EPYC 9654)とかなりバラついている。
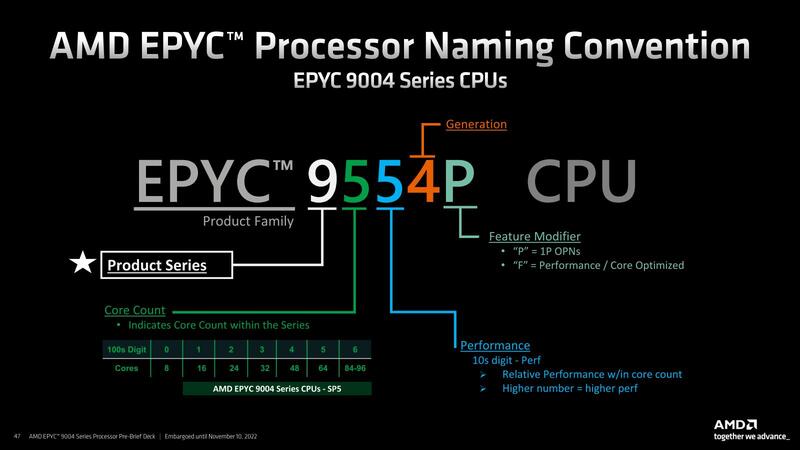
ちなみに型番の定義が下の画像だ。おそらくだが、来年Bergamoが出るときには2桁目(100の位)に、128コアまでを示す7が追加されるような気がする。
Genoaには3種類の製品がある
さてBergamoはともかくとしてGenoaであるが、大別して3種類の製品からなる。具体的には、4CCD/8CCD/12CCDのラインナップがある。今回の例で言えば、16/24/32コアの製品が4CCD構成、48/64コアの製品が8CCD構成、84/96コアの製品が12CCDの構成になる格好だ。
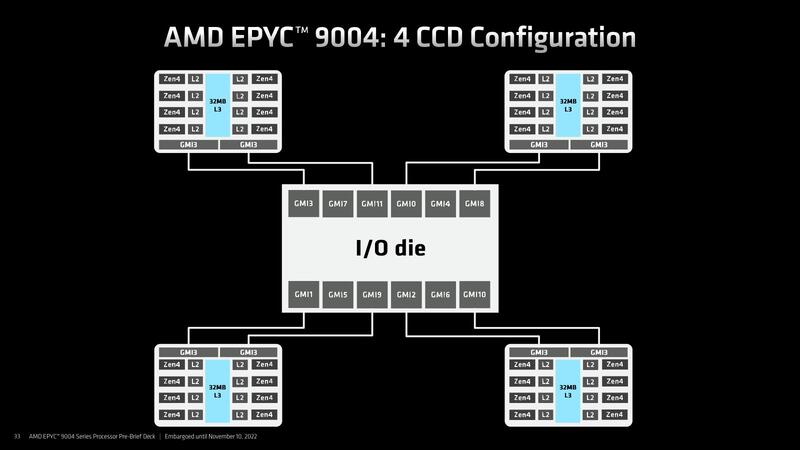
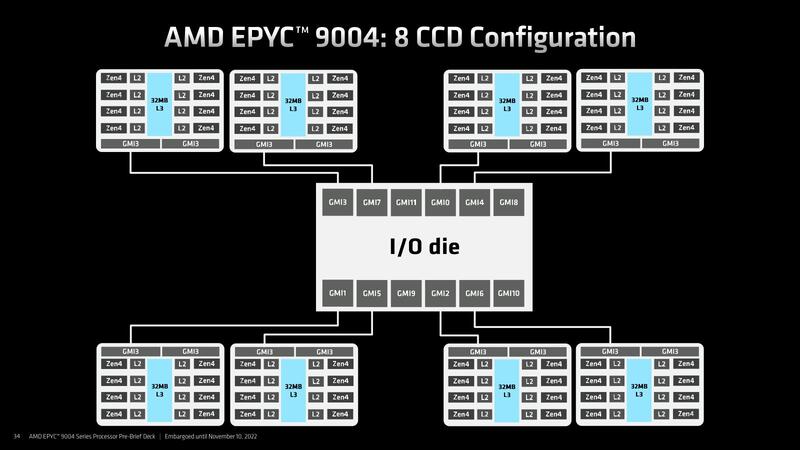
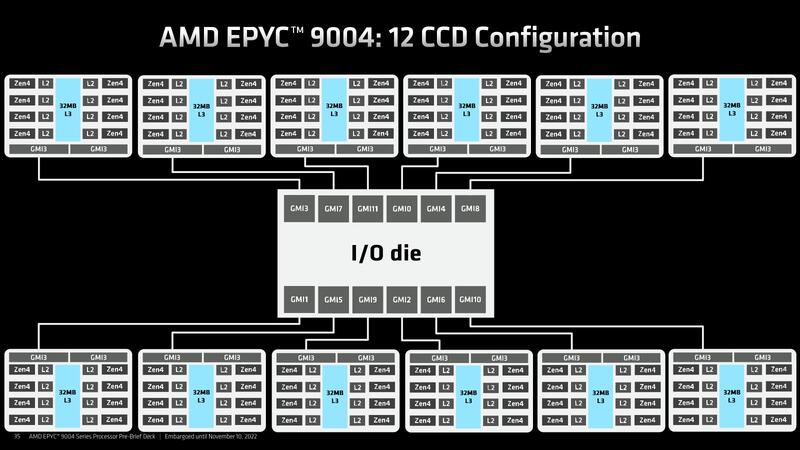
各々のCCDそのものは、Ryzen 7000シリーズに搭載されているものとまったく一緒である。したがって、コアあたりの性能そのもので言えばRyzen 7000シリーズと変わらない。ただしRyzen 7000シリーズはコンシューマー向けということで、いろいろ機能が無効化されている。具体的にはL3 Cache Range ReservationやStorage Class Memory向けのQoS機能、Security/Virtualization機能などだ。


またデバッグ/プロファイリング機能の充実はおそらくRyzen 7000シリーズでも可能だと思うが、これまでは説明がなかった気がする。

最高速を2倍に引き上げながら 消費電力は据え置き
ではEPYCをEPYCたらしめている部分は? というと、IODを含めたSoC全体、ということになる。IODは上の画像で示すように12chのCCD接続用インフィニティー・ファブリックのI/FとメモリーコントローラーとPCIe/CXLなどのI/O I/Fを統合したチップである。
まずメモリーコントローラーであるが、DDR5を12ch搭載、最大で6TBものメモリーを利用可能となっている。

もっとも、6TBの構成にする場合、12chのDIMMスロットにそれぞれ2枚づつのDIMM(それも2×8Rank 3DS-RDIMMで、16Gbit×4構成)を装着する必要がある。そもそもDDR5では、1chのメモリーバスに2枚のDIMMを挿す場合には速度やRankの制約が非常に多い。それもあって、EPYC 9004シリーズの場合は、1ソケットサーバーは24本のDIMMスロットを持つが、2ソケットサーバーはそれぞれ12本のDIMMスロットを持つ構成がデフォルトとされている。
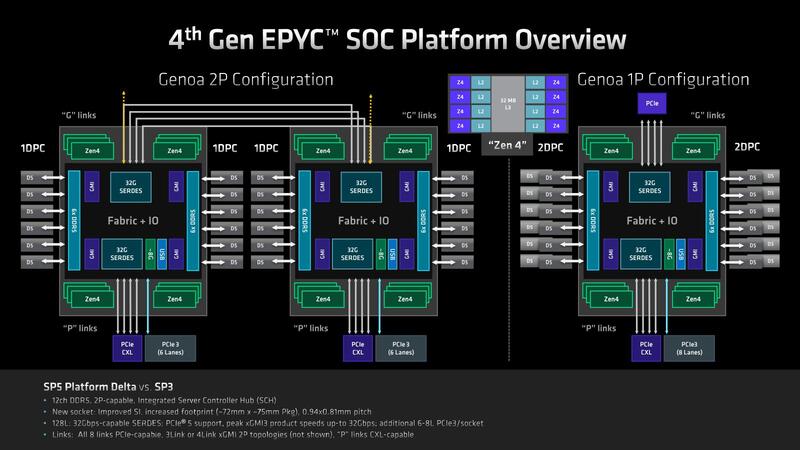
実際AMDのEPYC 9004シリーズ向けのリファレンスボードであるTitaniteの場合、DIMMスロットはソケットあたり12本になっている。
ちなみに速度はDDR5-4800どまりである。コンシューマー向けはともかくサーバー向けのRDIMMや3DS RDIMMは今のところDDR5-4800どまりであり、少なくともGenoa世代ではこれで問題ないと思われる。ちなみにこのメモリーコントローラー、NUMAの分割に合わせて4つまで分割してそれぞれ独立にアクセスすることも可能である。

少しおもしろいのがこのメモリーコントローラーの性能に関する部分だ。DDR4のMilanとDDR5のGenoaなので当然帯域は倍以上異なるわけだが、それよりも特徴的なのはSingle Rank Efficiencyの部分である。
当然ながらサーバーである以上、Multi-Rank Interleaveは前提になっており、2 Rankのメモリーと1 Rankのメモリーでは性能が大きく異なる。実際Milanでは25~30%もの性能低下があるのだが、これをGenoaでは10%未満(実際には5~6%)で抑えたというのは、特にメモリーのコストを抑えたシステム(同容量では2 Rankのメモリーの方が高い)での性能低下を最小限に抑えられるという点で効果的である。

また、DDR4→DDR5では帯域こそ増えるもののレイテンシーも増えることそのものは避けられないのだが、Genoaではこのあたりをずいぶん工夫しており、速度が上がりつつもDRAMアクセスのレイテンシーそのものは13nsしか増えない(このうち10nsはDDR4→DDR5に起因する)あたりは、Zen 4コアが内部の2次キャッシュの大容量化などでよりメモリーアクセス頻度が減ったことと相まって、実質的にさほどGenoaと変わらないレイテンシーで帯域だけ2倍以上になったことになる。
次が2ソケット用のインフィニティ・ファブリック・レーンの話である。Genoaに搭載されたIODでは、このソケット間の接続にx3ないしx4のインフィニティ・ファブリックを利用できる。このファブリックのPHYはPCI Expressと共用というのはGenoaまでと同じである。
x3とx4のどちらを使うのかはアプリケーション次第であって、例えばアクセラレーターを大量に利用するような構成ではソケット間接続はx3にして、余った32レーンでアクセラレーターを2枚余分に接続できるし、Computationなどの用途であればx4接続することでプロセッサー同士の接続がより広帯域になるわけだ。
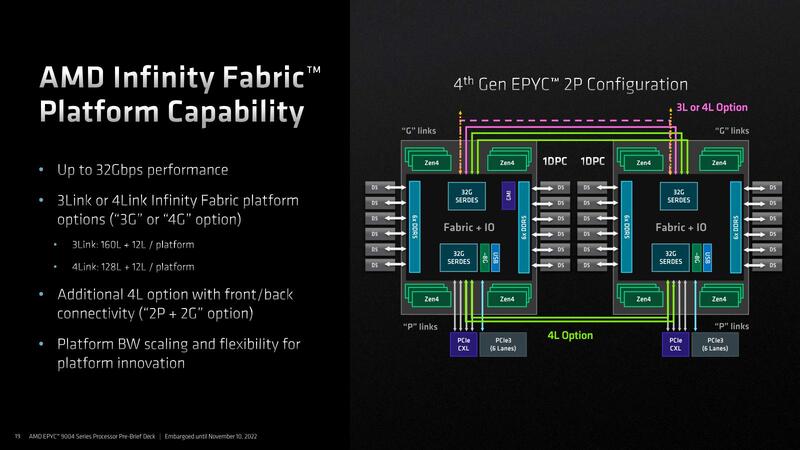
なおこのインフィニティ・ファブリックの最高速は36Gbpsである。SerDesをPCI Express/CXLと共用する関係で、PCI Express/CXLとしての動作時には32Gbpsになるが、インフィニティ・ファブリックとしての利用時は36Gbpsになり、それでいながら転送時の消費電力は2pJ/bitを下回るとしている。
この2pJ/bitというのは、Genoaまでのインフィニティ・ファブリックと同じ数字であり、つまり最高速を2倍に引き上げながら消費電力そのものは据え置きにできたとされている。ちなみにSerDesはPCI Express/CXL以外にSATA、さらにイーサネットとしても利用できるという構成は以前のままである。

性能に関してはいくつかスライドが出ているが、これはAMDのウェブサイトで示されているものと大差ないし、なんなら動画でデモが公開されているので今回は割愛する。
前回の記事の最後でも書いたが、Genoaの本当の敵は第3世代Xeon Scalableではなく、間もなく登場するはず(出ると良いなぁ)のSapphire Rapidsベースとなる第4世代Xeon Scalableである。
現時点ではまだその第4世代Xeon Scalableの評価ができない以上、これがそろってからが評価の本番だと思うからだ。というわけで、Genoaについてはこのあたりで終わるが、最後にBergamoについて語ろう。
3次キャッシュを削減してコアの密度を上げた Bergamo
EPYC 9004シリーズの発表会では一切言及されなかったのだが、事前説明会の折に「GenoaとBergamoの相違点はここだけ」として示されたのが下の画像だ。
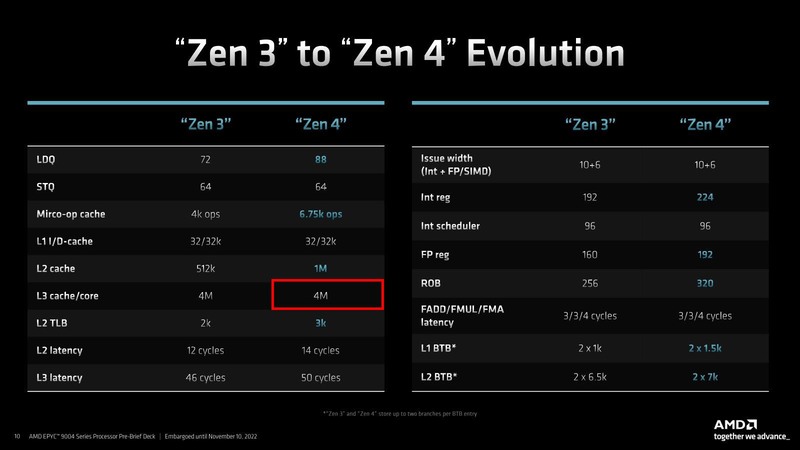
そもそもBergamoはより高密度なサーバー向けであり、プラットフォームは既存のGenoaと共通で、コア数が最大128になる、というのが事前に説明された情報のすべてであるわけで、それもあって筆者は連載643回ではArmのbig.LITTLEに似た効果を、ただしより少ない労力で実装する形になると予測。物理設計時のライブラリーを変更するかもしれないと判断したわけだが、もう少し簡単に3次キャッシュを削減する形でコアの密度を上げる形にしたようだ。
実際、これでかなり高密度化ができる。下の画像は今回発表されたEPYC 9004のパッケージ写真だ。

ここから3つのCCDを抜き出したのが下の画像である。このCCD1つあたりの3次キャッシュが占める面積は35%ほど。CPUコアよりはやや小さい程度であるが、インフィニティ・ファブリックのI/Fがある分これ以下にはできない感じだ。

さて、ここで仮に3次キャッシュのサイズを半分にすると、ダイサイズはZen 4の82.4%ほど、1MBまで減らすと73.7%ほどまでダイサイズが減る計算になる。試しに3次キャッシュを1MB/コアまで減らし、その代わり2 CCXを1つのダイに収めた場合のシミュレーション画像が下の画像だ。

ダイサイズは34.9%ほど増える計算になるが、これが8ダイでも12ダイのEPYC 9654よりは小さい(Zen 4の10.8ダイ相当になる)。パッケージの再設計は免れないが、Genoaと同じサイズにできるだろう。実のところ、なぜ2つのCCXを1つのダイに入れる案を出したかと言えば、理由は2つある。
まず、IODは最大12個のCCDを接続できる。ということは、128コアのBergamoでIODを再利用したければ、CCDあたり13個という変な数になってしまう。むしろ16コアのCCDを8つ接続する方が考えやすい。Bergamo用のIODを別に用意する案もあるだろうが、検証の手間が大幅に増えることを考えるとあまり賢明な案ではない。またCCXそのものを16コアに拡張するのは、AMDの設計のポリシーから外れる。
次に、Radeon RX 7000シリーズのところでも出た話だが、PHYのサイズは減らない。インフィニティ・ファブリックのPHYはCPUコア+3次キャッシュ32MBの高さにちょうど合う感じであり、仮に3次キャッシュを4MB(1MB/コア)まで減らしてもPHYの高さは減らないので、無駄なダイエリアができてしまうことになる。であれば、3次キャッシュ4MBのCCXを2つ縦に並べた方が効率が良いことになる。
もちろんこれは筆者の推定で、この通りになる保証はまったくない(そしてご存じの通り筆者の推定はけっこう間違う)わけではあるが、激しくは外していないと思う。
おそらくBergamoは動作周波数も2GHzかその程度に抑えられるだろう。この程度まで抑えられれば、3次キャッシュの少なさもメモリー帯域の高さでカバーできる。
コアあたりの性能は当然落ちるが、そもそもBergamoはクラウドなどに向けた高密度サーバー向けだから、個々のコアの性能そのものはそこまで重要ではない。そしてAMDの利用するTSMCのN5プロセスは、2GHz付近での性能/消費電力比は非常に良い。重要なのは性能/消費電力比であることを考えると、Bergamoは結構良いバランスの製品に仕上がる可能性が高い。
最初のところで書いた型番は、例えばBergamoがEPYC 7004やEPYC 6004などになる可能性がある。おそらく現行の9はGenoa(とこの後出てくるGenoa-X)のみで、Bergamoは別の番号になるだろう。そのあたりまで含めて今回7から9に上げた、というふうに筆者は考えている。

この記事に関連するニュース
-
【FRONTIER】 シリーズ最新作 『Call of Duty(R): Black Ops 6』動作確認済みPCの販売を開始
PR TIMES / 2024年11月25日 12時15分
-
世界最速に躍り出たスパコンEl Capitanはどうやって性能を改善したのか? 周波数は変えずにあるものを落とす
ASCII.jp / 2024年11月25日 12時0分
-
最新ゲーミング最速CPU「Ryzen 7 9800X3D」搭載!TSUKUMOのミニタワー型PC新モデル発売
Game*Spark / 2024年11月21日 13時50分
-
ゲーミングに最適化したキャッシュ爆盛りデスクトップCPU「Ryzen 7 9800X3D」正式発表 米国では479ドル
ITmedia PC USER / 2024年10月31日 23時40分
-
AI性能を引き上げるInstinct MI325XとPensando Salina 400/Pollara 400がサーバーにインパクトをもたらす AMD CPUロードマップ
ASCII.jp / 2024年10月28日 13時0分
ランキング
-
1電気のプロが“本格的な暖房を使う前に警告”するのは…… コンセントのまさかの現象理由と対策に「そうだったのか……」「全く知らなかった!」
ねとらぼ / 2024年11月25日 19時30分
-
2スマホ料金「最激戦区の30GBプラン」を比較 ahamoショックにUQ mobileやY!mobileも追随でどこがお得に?
ITmedia Mobile / 2024年11月26日 6時5分
-
3HD-2D版『ドラクエ3』勇者「俺だけバラモス倒せなかった…」←なんで? 嘆きの声続出の理由
マグミクス / 2024年11月25日 17時25分
-
4富山の「段ボールの製造会社」の社員たちを変えたのは掃除だった – 指示待ち社員が変わった経緯を社長が明かす
マイナビニュース / 2024年11月25日 9時18分
-
5Amazonブラックフライデー、絶対誰も教えてくれないお得に買える“裏技”
ASCII.jp / 2024年11月26日 7時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





