

CPUとDSPを融合させたChimeraはまさに半導体のキメラだった AIプロセッサーの昨今
ASCII.jp / 2022年12月12日 12時0分
また1ヵ月ほど間が開いてしまったが、今回のAIプロセッサーはQuadricのChimera GPNPUをご紹介したい。
暗号資産マイニング用ASICの販売からスタート
Quadricは2017年創業の比較的新しい会社。本社拠点はカリフォルニア州のバーリンゲームである。バーリンゲームといってもわかりづらいかもしれないが、位置的にはサンフランシスコ国際空港から2kmほど南東に移動したあたり。1997年頃の知識で言えば高級住宅街という位置づけで、比較的治安も良いエリアだった。
この頃で言えばバーリンゲームはもうシリコンバレーの北限を超えたさらに北(当時はOracleの旧本社があったRedwood Cityあたりが北限扱いされていたので、そこから北西に10km位の場所)にあたる。
もっとも昨今ではサンフランシスコあたりまでがシリコンバレーという扱いになっているらしいので、その意味ではバーリンゲームもシリコンバレーの一部と言ってもいいのかもしれない。
創業者はVeerbhan Kheterpal氏(CEO)、Nigel Drego氏(CTO)、およびDaniel Firu氏(CPO:Chief Product Officer)の3人だが、経歴が少しおもしろい。
もともとKheterpal氏は2005年にFabbrix, Inc.という、論理設計(RTL)を物理設計に変換する際の独特な変換ツールを手掛ける会社の創業者の一人だった。ただ同社はその後PDF SolutionsというEDA(IC設計ツール)ベンダーに買収され、そのままPDF Solutionsで働くのだが、ここでDrego氏とFiru氏に出会う。
そのまま3人は2013年にPDF Solutionsを退職、ビットコインのマイニング用ASICを製造する21.coという会社を立ち上げた。もっと正確に言えば、当初の社名は21e6で、途中から21 incに変更したらしい。
当初は自社でビットコインのマイニングを行なって収益を上げる、という目論見だったらしいが、その後方針転換(1回目)をして、マイニング用ASICの販売に舵を切る。この21.coは2015年にビットコイン向けのSBC(Single Board Computer)を発売しており、当時は米国Amazonでも購入可能だった。
ただ同社がそのビットコイン向けASICやそれを搭載したSBCを発売し始めた2015年後半というのはビットコインの価格が下落した時期でもあり、それもあって2016年頃には立ち行かなくなりつつあった。
この後の経緯がはっきりしないのだが、2017年頃には会社はBalaji S. Srinivasan氏がCEOに就任するとともに、ビットコインのマイニング用ASICの製造からビットコインを含む暗号資産全般の売買にからむサービスを提供する会社に方針を転換した(2回目)ようだ。
Srinivasan氏への当時のインタビューがYouTubeに上がっている。ただSrinivasan氏の本業は、起業して間もない企業に資金を出資するエンジェル投資家という立場であり、ある程度のところで見切りをつけて他の人に任せる決断をしたらしい。
現在も21.coという会社は存在するのだが、この会社は21Shareという会社の親会社である。21Shareは2018年にHany Rashwan氏(現CEO)とOphelia Snyder氏(現President)によってスイスで設立されており、単に名前だけが買われた可能性もある。実際21.coのOur Storyを見ると、2018年創業ということになっている。
その一方でそもそも21 incを立ち上げた3人は2016年で同社を離れ、2017年に立ち上げたのが今度はAI向けプロセッサーを開発するQuadricだった、というわけだ。
AI推論エンジンにDSPとプロセッサーを統合
さてそのQuadricが考える現在のAIプロセッサーの問題とは、純粋にAIの推論だけを考えればGraph Processorが処理に適しているわけだが、実際にはその前後にDSP(Digital Signal Processor)あるいは通常のプロセッサーが必要、という話である。
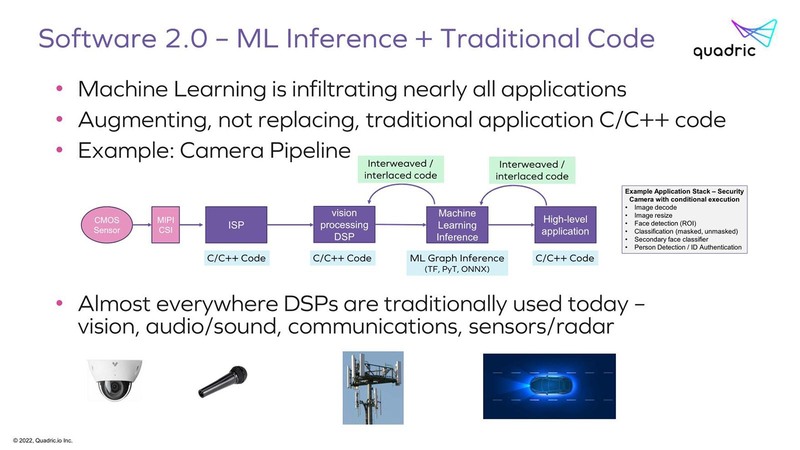
そういうこともあって、純粋なAIのアクセラレーターはともかく、特にエッジ向けのAI推論向けプロセッサーは下の画像のような構成になっていることが多い。
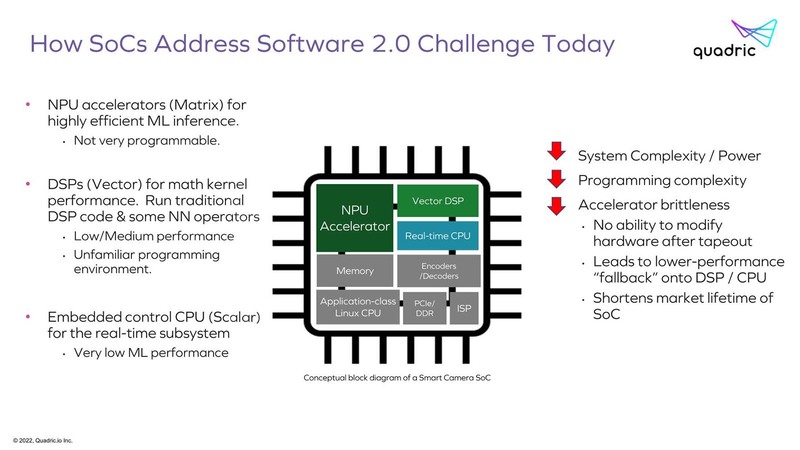
ただ当然こうした構成にすると、性能を確保しようとするとそれぞれのエリアサイズが肥大化するのでコスト上昇につながるわけで、コストを抑えるためには必然的に性能も抑える必要性がある。
「ではAI Inference EngineにDSPとRealtime Processorの機能を統合してしまえばいいのでは?」というのがGPNPU(General Purpose Neural Processor Unit)ことChimeraプロセッサーというわけだ。自分たちで“キメラ”と名付けるあたり、ある程度ゲテモノであることは理解してはいるのだろう。
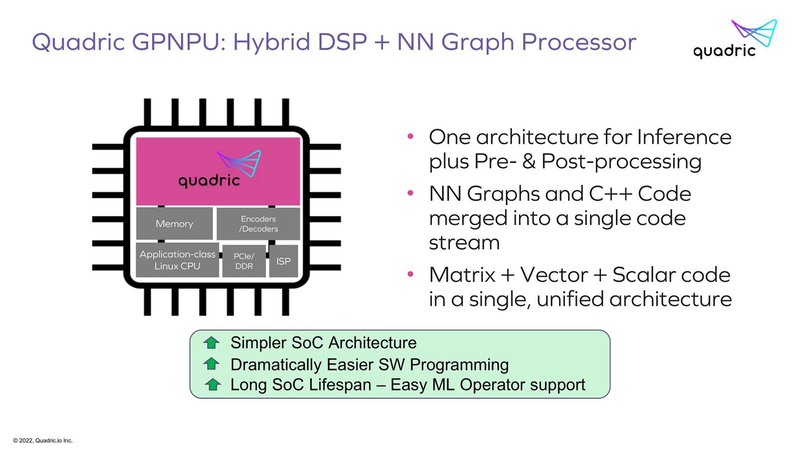
そのChimeraの中身が下の画像だ。命令長が64bitというあたりは、おそらくはVLIWのような構成になっており、通常のMPU/DSP命令(上段)とArray Processor(下段)が同時に動作する、ということに見えなくもない。
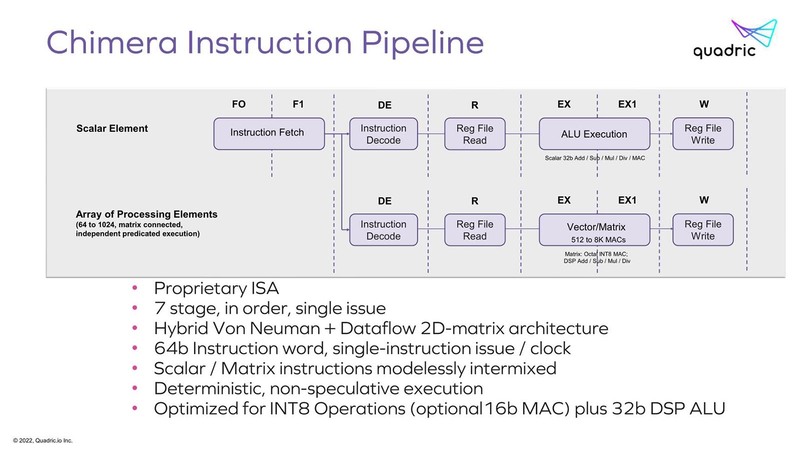
ただMatrixの方はデータフロー的に動くというあたりでもう理解ができなくなっている。データフローの場合、「普通は」すべてのProcessor Elementが独立して動くMIMD的な構成にするわけで(さもないとデータフローでなくなる)、あるいは実は64bitの命令といっても先頭にMPU/DSP命令か、Matrixかのbitが付いていて、Matrixの場合は即時実行するのではなく各MatrixのProcessor Elementに命令をロードするだけという可能性もあるのだが、パイプラインを見るとそれも違うように思える。
どう動くのかがさっぱり見えてこないあたりが困ったものだが、Chimeraの名に恥じない構成ではあると思う。下の画像がシステムの構成図であり、これだけ見ると良くある構成である。
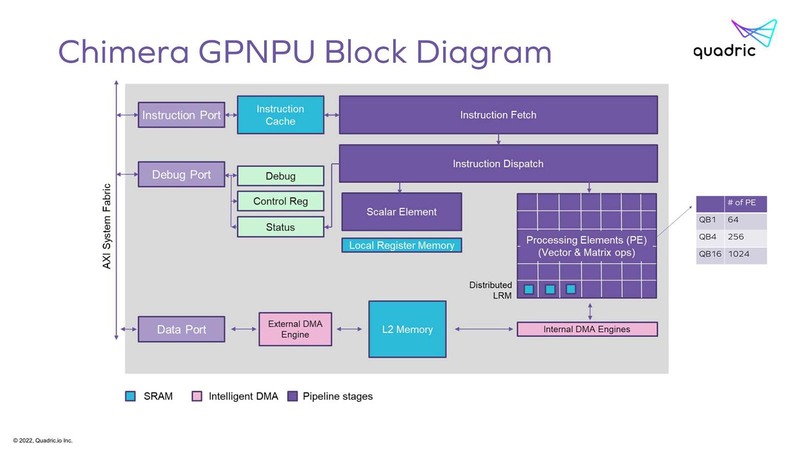
Scalar Elementからのライトバックだが、これもLocal Register Memoryから2次キャッシュへDMAエンジンが用意されており、これを利用して書き出す格好になる(このスライドでは省かれている)。
PE(Processing Elements)の方も同様に、Distributed LRM(Local Register Memory)にまずPEから書き出し、それがDMA経由で2次キャッシュにライトバックという順当な構成である。
ただそのChimeraを利用した場合の処理パスを見ると、例えばFace detectの出力はDistributed LRMから一度2次キャッシュに書き出され、NMSはもう一度2次キャッシュから今度はScalar Element側のLRMにデータを読み込んで処理をする、という少し複雑なパスを通ることになる。
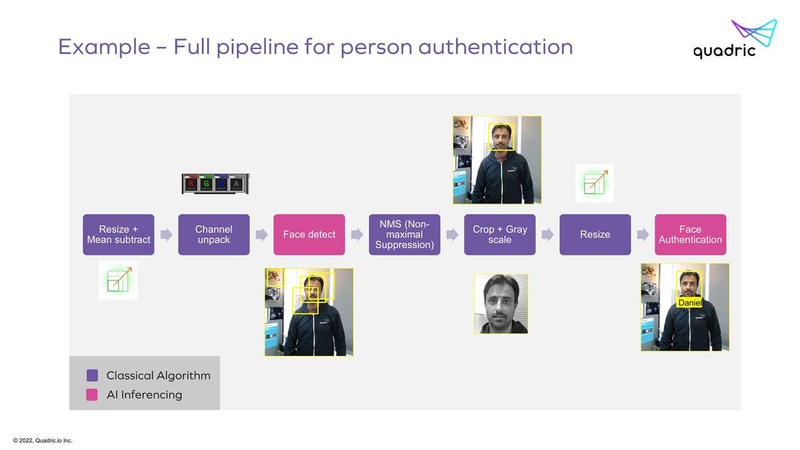
これ、素直にScalar ElementからDistributed LRMにアクセスできる(あるいはその逆)パスを用意できればもっとシンプルになりそうな気はするのだが、今度は内部構成が複雑になりすぎるのであえて諦めたのかもしれない。
PEをデータフローで動作させて高効率を実現
ちなみにそのPEがどうして効率的か? と言う説明はあった。下の画像は3×3の畳み込み演算の場合だが、まず隣接する4方向との間で演算の半分を行ない、次のサイクルで残り半分の演算ができる格好になる。
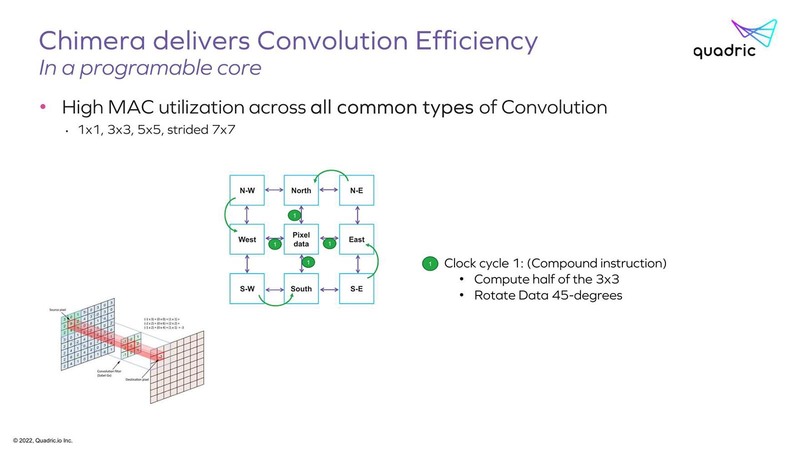
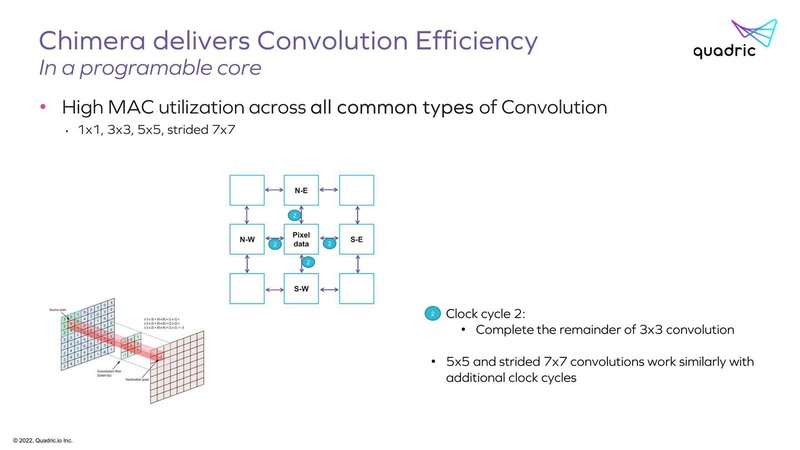
結果、3x3の畳み込みが2サイクルで実施できるわけだ。同じ仕組みで、より大きなサイズの畳み込み演算も高効率で実現可能というのが同社の説明である。

なお、メモリー回りで言えば、2次キャッシュを経由すると最大70倍の電力消費となるそうで、やはりDMAエンジンを経由してアクセスするのはそれなりにコスト増になるのは間違いない。
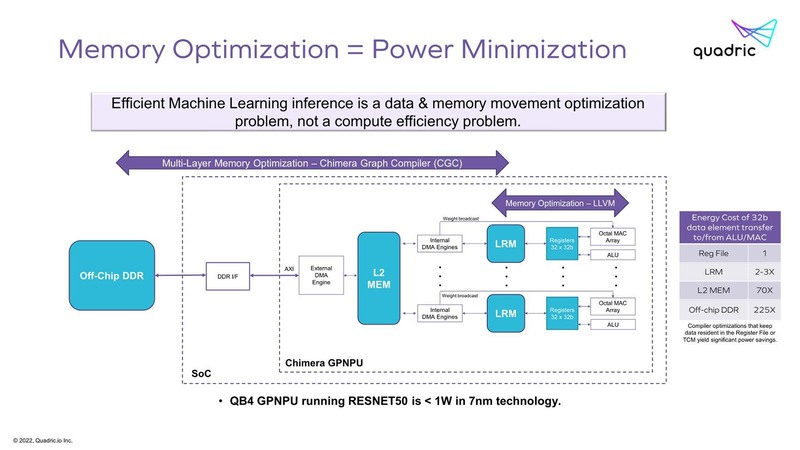
でありながらもあえてこんな構成にしたのは、例えばすべてのLRMをファブリックでつなぐような構成にすると、そのほうが複雑さが増し、回路規模が増え消費電力が増えるという判断だったのかもしれない。
後述するQB4の構成では、RESNET-50動作時の消費電力を1W未満に抑えたというあたり、性能と消費電力、複雑さに関してのバーターとしてこの構成になった、と考えるのが妥当なのかもしれない。

Chimera GPNPUはこのPEの数でQB1~QB16まで3つのラインナップが用意されている。すでにQB4構成に関しての試作チップは存在しており、ラスベガスで開催されるCES 2023に合わせて来年1月5日と1月6日にブースでデモを行なうとしている。

また同社は製品だけでなくIPライセンスの形での提供も考えているそうだ。この試作チップはM.2の2280サイズに収まっており、いわゆるエッジ向けAI推論プロセッサーと同じ感じになっている。
この製品版の方は2023年第1四半期中に準備が整うようで、仮にここから量産を始めると第2四半期あたりに最初の量産チップが出てくる格好だろうか。すでにSDKの提供はスタートしており、またLLVM C++コンパイラおよび命令セットシミュレーターも限定的にだが提供を開始しているようだ。

根本的なところで、ChimeraをChimeraたらしめている、Scalar ElementとMatrix Elementの謎のパイプライン構造の意味はわからないし、QA4構成で1GHz駆動では4TOPSというのは、性能として低くはないが高くもないという微妙なところである。
とはいえかなりおもしろいプロセッサーではあり、果たしてどこまでマーケットが取れるのか見守りたいところだ。

この記事に関連するニュース
-
安心安全なエッジAIの開発・実装に向けて組込みLinuxのオプション「EMLinux for Edge AI」を提供開始
PR TIMES / 2024年11月19日 18時15分
-
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分
-
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月11日 12時0分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
-
「Snapdragon 8 Elite」は何が進化したのか PC向けだったCPUコア「Oryon」採用のインパクト
ITmedia Mobile / 2024年10月28日 16時15分
ランキング
-
1「見た瞬間笑った」 共通テスト模試のリスニング問題 → “衝撃的なファッション”のイラストに思わず三度見 「肩ww」
ねとらぼ / 2024年11月26日 11時50分
-
2東芝マテリアルを日本特殊陶業が買収 1500億円で
ITmedia NEWS / 2024年11月26日 12時44分
-
3『ドラクエ3』大魔王ゾーマ様、配信者になる―自己紹介では「嫌いなもの:ひかりのたま」とポロリ、「“ほりい”とかいう人間も泣き叫んでた」
インサイド / 2024年11月26日 13時10分
-
4日本に1店舗のみの“完璧なマクドナルド”が778万表示の話題 地元民も「そんなすごい店やったんか…」「たまに使ってるけどそんなすげぇとこだったのね」
ねとらぼ / 2024年11月26日 7時40分
-
5Windows 11 2024 Updateの目玉機能「リコール」って何? 実際に試して分かったポイントを解説
ITmedia PC USER / 2024年11月26日 12時5分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





