

Foveros Directを2023年後半に出荷 インテル CPUロードマップ
ASCII.jp / 2022年12月26日 12時0分

12月4日~8日にかけて、サンフランシスコでIEDM 2022(正式名称は2022 IEEE International Electron Devices Meeting)が開催された。サンフランシスコで、と書くことからわかるようにこちらはリアルイベントであるが、オンラインの形でも12月12日から内容が公開されている。
このIEDM、ISSCC(International Solid-State Circuits Conference)やVLSI Symposiumなどと並んで、主に半導体のデバイスそのものに関する重要な学会となっている。
当然ここでは多くの半導体関係企業や研究所、大学などからの発表が行なわれているわけだが、インテルも例に漏れずここで多数の発表をしている。なにしろ合計で11本の講演を行なっており、うち3つは招待講演である。今回はこのIEDMにおけるインテルの発表内容を解説したい。
ちなみに5日間ものイベントではあるが、初日はチュートリアルセッションで、合計6本のチュートリアルが開催される。チュートリアル、といってもまったくの素人ではなく、半導体にはそれなりに知識があるが、その分野には明るくないという人のためのセッションなので、初心者向けでは全然なかったりする。
翌日はShort Courseと呼ばれる、8時間半にもおよぶ「全然Shortではない」特定分野向け集中講座が2本実施される。今年で言えばShort Course 1が“High-Performance Technologies for Datacenter and Graphics to enable Zetta Scale Computing”、Course 2が“Next-Generation High-Speed Memory for AI and High Performance Compute”となっている。
3日目からがいよいよ本番で、まずPlenary講演が3本(それぞれ45分)行なわれたあと、5日目まで最大で同時8セッションが並行開催される形で実施される。そんなわけでリアルイベントに参加しても、実は全セッションに参加するのは物理的に不可能である。それもあってオフラインの形で後から全セッションの内容を確認できるのは便利である。
Foveros Directを2023年後半に出荷
それはともかくとして、そのPlenary講演の最初に行なわれたのが、Ann Kelleher博士(EVP&GM, Technology Development)による“Celebrating 75 Years of the Transistor”という講演である。
内容はこれまでのトランジスタの発展を振り返りながら、今後もますますトランジスタの高密度化が進んでいくこと、その際の設計技法として従来のDTCO(Design-Technology Co-Optimization)からSTCO(System-Technology Co-Optimization)に切り替わりつつあること、また単にトランジスタの構造だけでなくインターコネクトや素材、メモリー素子などでも進化が必要であり、このためには新素材とか新しい露光技術、システム分割の方式、信頼性確保、製造/パッケージングやソフトウェアなど多岐に渡る分野での革新が必要で、このためには人材がさらに必要となる、と述べている。
Kelleher博士の講演はわりと高いレベルの話で、あまり技術的に細かい話は出てこなかったのだが、3つほどご紹介したいスライドがある。先にSTCOという言葉が出てきたが、その実例として出てきたのがPonte Vecchioだった。

単に機能分割するだけだと、プロセス的に必ずしも合理的に分割できるとは限らない。ましてやPonte Vecchioの場合、異なるプロセスで製造したタイルを組み合わせることになるので、その設計は通常のモノリシックな製品に比べると猛烈に難しくなる。それであってもモノリシックな構成ではPonte Vecchioは構築不可能であり、これを実現できたのはSTCOのお蔭というわけだ。
また同社のプロセスについても言及があった。一番アレなのは、すでにIntel 4がManufacturing Readyとされたことだろう。ただしHVM(High Volume Manufacturing)扱いにはなっていないあたりは、まだサンプル出荷のレベルに留まっていると判断すべきだろう。

これに続き、2023年後半にはIntel 3の量産準備が、2024年前半にはIntel 20A、後半にはIntel 18Aの量産準備が整うとされている。
しかしこうなると、インテルのデータセンター向け製品の詰まり具合がヤバいことになる。下の画像は今年の2月に行われたInvestor Meetingのものだが、なにしろ現時点でもまだSapphire Rapidsが出荷開始されていないわけで、つまり2023年にSapphire Rapidsが出てそこから半年かそこらで今度はEmerald Rapidsが出る、という予定に切り替わるわけだ。

そして2つ前の画像のロードマップがそのまま行くのであれば、そのEmerald Rapidsの出荷と同じころにGranite RapidsとSierra Forestの生産(製品の量産は難しいだろう。おそらく検証用のシリコンの量産がスタートといったあたりだろう)し、ここで問題がなければ2024年に両製品の本格量産が始まる、というのが現時点での見通しに基づく現実的(?)なスケジュールかと思う。
しかし実績があるはずのIntel 7を使ったSapphire Rapidsがこれだけ遅れている現状、新プロセスとなるGranite Rapidsがどこまで順調に進むのか不安しか感じないのが正直なところである。
話をKelleher博士の講演に戻すと、Foveros Directを2023年後半に利用可能にすることと、2025年までの範囲でPluggable Opticsのソリューションを提供する予定であることが公開されたのが今回新しく発表された事柄となる。

配線密度をさらに3倍に上げたFoveros
さて本題はここから。今回のIEDMでインテルは8本の講演を行なった。そのうちの1つがPaper #27.3の“Enabling Next Generation 3D Heterogeneous Integration Architectures on Intel Process”という論文である。要するにFoverosの話である。
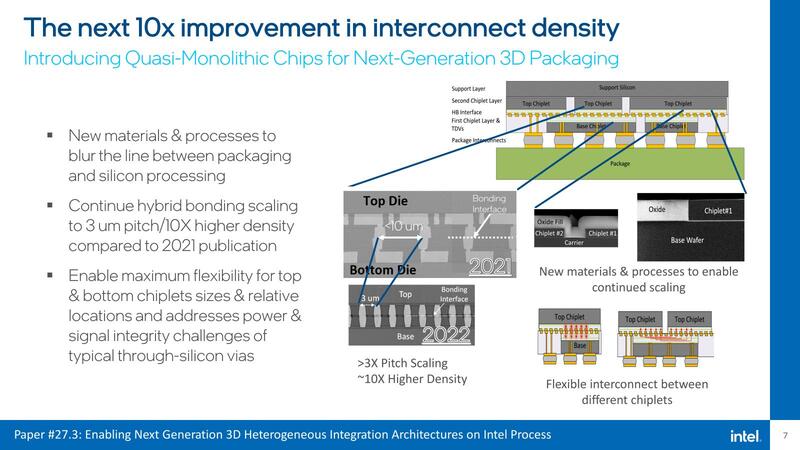
Foverosの話は今年のHotChipsでも触れられており、この内容を連載682回でも説明しているが、いろいろ不明な部分が明らかにされた格好だ。
Ponte VecchioやMeteor Lakeなどがその良い例だと思うが、Chiplet(インテル用語ならタイル)を組み合わせることで、一見するとモノシリックなチップ(QMC:疑似モノシリックチップ)を作ることがすでに可能になっている。
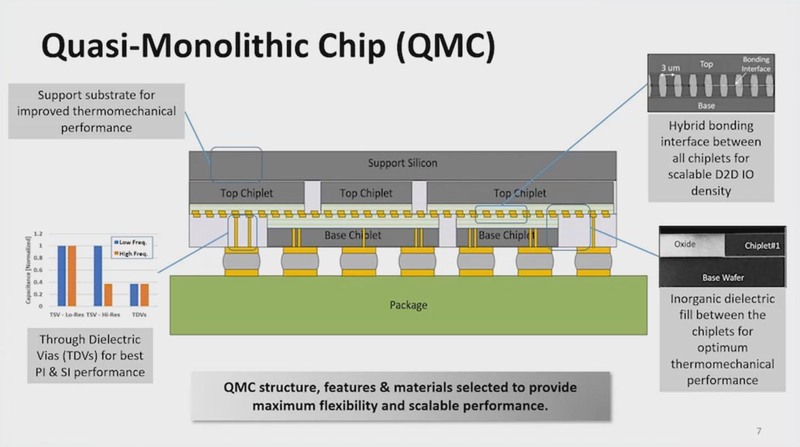
上の画像は概念というか現実には存在しないチップであるが、Top ChipletとBase Chiplet同士は直接Hybrid Bondingで接続される。Base Chipletの中で外部に信号を出したい、あるいはTop Chipletから直接外部に信号を出したい(が、真下にBase Chipletがある)場合は、TDV(Through Dielectric Vias)を使って下に信号を引っ張ればいい。
またTop Chipletの真下にBase Chipletが存在しないケースでは、単にTDVを挟んでパッケージと接続する形になる。基本的にこの構成はFoveros Omniで実現できるという話は以前説明されたとおりだ。今回の話はこの続きとなる。
Foveros OmniはBump Pitchが25μm、つまり1mm2のサイズに40×40で1600本の配線を通せる構成になっていたが、より配線密度を引き上げる必要がある、とする。
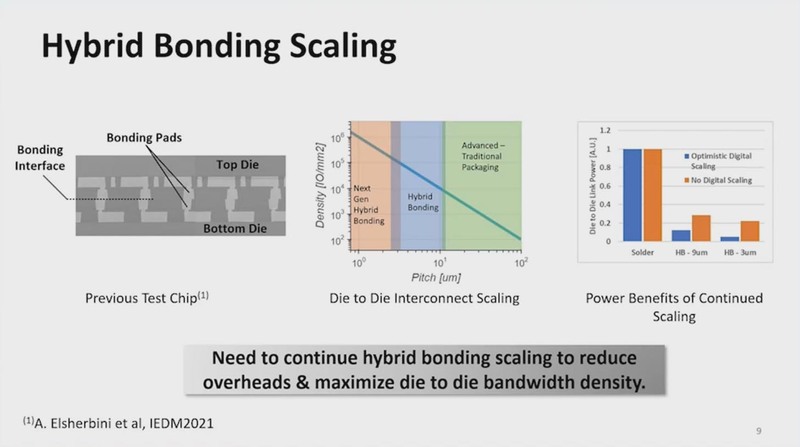
連載682回で説明したように、Foveros Omniの次にあたるFoveros Directでは、Top ChipletとBase Chipletの間にBumpを挟まず、おそらく分子間力を利用して直接銅配線同士を接続する仕組みが使われるとしていたが、これがおそらく9μmピッチと想定されていた(正確な数字は未公表)。
これで配線密度は2.78倍、1mm2あたり1万2000本強の配線を通せる格好になるが、今後QMCがさらに広く使われるようになると、これでは足りないという話になる。今回発表されたのは、なんとピッチを3μmまで縮めたものである。
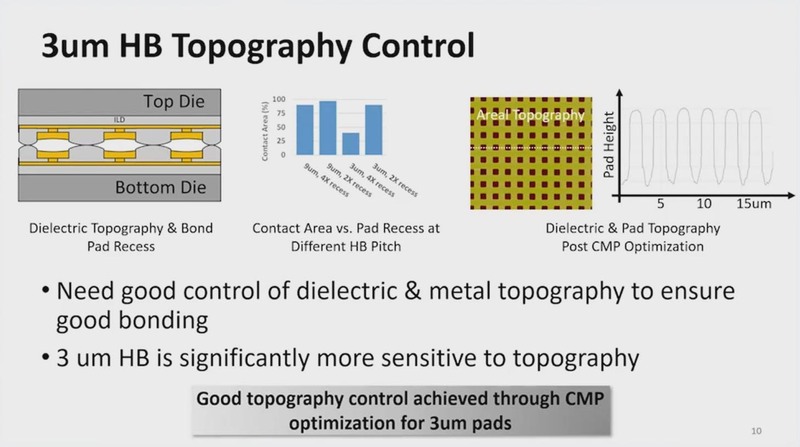
真ん中のグラフにあるように、今年のHot Chipsで公表されたものは9μmのものだったが、これの密度をさらに3倍に上げた、ということになる。
当然これでHB(Hybrid Bonding)を実現しようとすると、構造に対してより敏感になるとしているが、なにしろ接触部の面積が9分の1になるからこれは当然である。なのでCMP(Chemical-Mechanical Polish:半導体製造で、エッチングした後に不要部を取り去る際に、化学薬品などを使って削り取る工程。イメージ的にはコンパウンドを使って磨く感じになる)をうまく利用して平滑さを上げることが重要としている。
実際一番右にあるパッド(接触部)の高さの測定結果を見ると、側面がほぼ垂直に立ち上がるようになっているのがわかる。これが斜めになったりしていると接触面積が減ってしまうわけで、このあたりをうまく作り込むことが重要とする。
Hybrid Bondingは土台の反りをいかに抑えるかがポイント
下の画像が今回試作されたHBの断面写真となる。一見する限りはかなり綺麗に接続できており、またテストの結果も良好とのこと。

下の画像がこのHBを構築するための製造プロセスである。
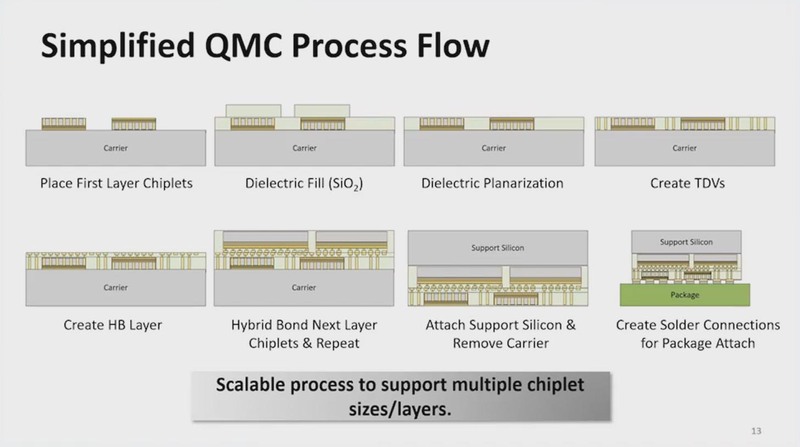
左上から横方向に順に、下のようなけっこう面倒な処理になっている。
- 1:土台(Carrier)にChipletを置く
- 2:その上に誘電材を構成する
- 3:CMPを使ってこれを平坦化する
- 4:必要な個所にTDVを構築する
- 5:全体の上にHB層を構築する
- 6:1~5をもう一度繰り返し、製造されたTop Chipletをひっくり返して載せる
- 7:土台を外す
- 8:全体をパッケージに載せる
この2番目、つまりChiplet全体を覆うように誘電材を構築するという処理が意外に大変で、土台の反りをいかに抑えるかがポイントとの話であった。

またこの角にあたる部分は強度的にストレスがかかりやすいので、欠けないようにするのが大変だったという話も紹介された。
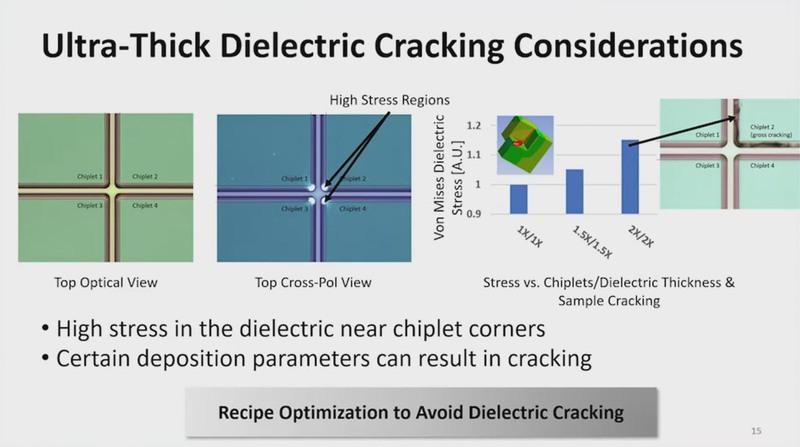
さらに言えばこの誘電材の構築後の平滑化(先の3)にあたっては、20μmほど削り込む必要があるとされる。これは通常のCMOSプロセスの10倍だそうで、通常のCMOSプロセスと同じスラリー(研磨剤)を使っていたら時間がかかりすぎてしまう。
そこでおそらくはもう少し荒い研磨剤を用意するとともに、削り方を工夫することで実現した、とされる。
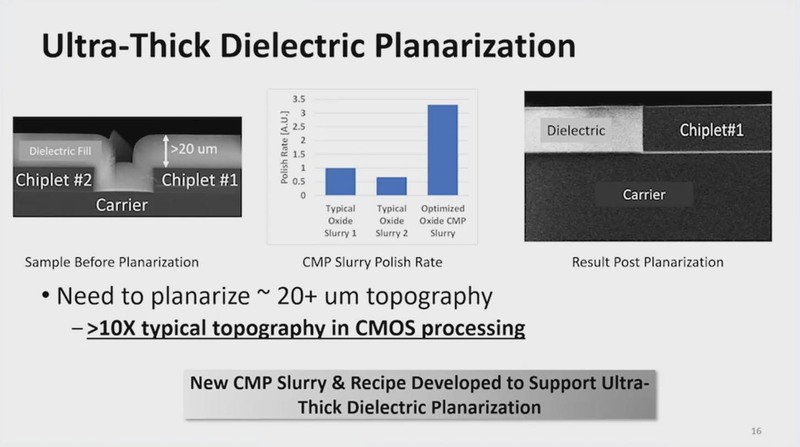
その分荒れ具合は少し大きくなっているようで、通常のCMOSプロセスで使うスラリーだと0.75~1Å程度を削れるのに対し、今回使ったスラリーでは3.2~3.3Å程度を一気に削れるようになったそうだ。
もちろんこのままでは荒すぎる気がするので、あるいはまずこの荒いスラリーで大雑把に削った後、最後により目の細かい(?)スラリーでより厳密に削ったのかもしれないが(どの程度まで削れば分子間力での接続に十分なのか、に関して筆者は情報を持っていない)。
ところで先にTDVについて少しだけ触れた。一般にはこれはTSV(Through Silicon Vias:シリコン貫通電極)を使うが、インテルはこれをTSVではなくTDVを使うのが効果的としている。両者の違いは材質で、要するに銅配線を使うか、誘電材を使うかである。
CMOSプロセスではここにタングステンを使ったりするが、TSVでは通常銅である。ではTSVをTDVにするとなにが良いか? というのが下の画像だ。
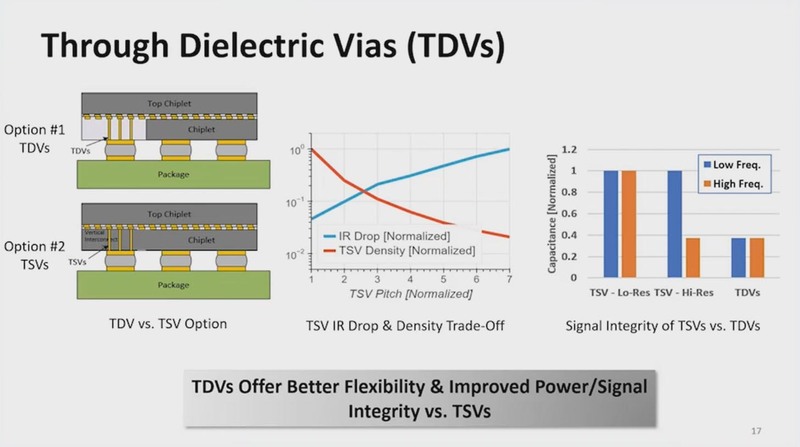
TSVは配線密度を上げると配線抵抗も急速に増えることでIR Drop(要するに電圧降下だ)も大きくなる。一番右のグラフがわかりやすいが、TSVでは配線に起因する寄生容量が比較的大きく、また信号周波数の影響を受けやすい。TDVだとこの影響が少ないため、Power/Signal Integrity(電源供給や信号送受信の収束性)が向上する、とのことだった。
今回の発表は、「次世代の」Foveros Directを目指したものであり、3μmまで配線ピッチを縮めることが現実的に可能、というものとなっている。こうなると1mm2あたり11万1千本以上の配線密度を実現可能で、しかもTSVを利用した場合より良い伝達特性が実現できる、というものであった。
少なくとも2023年後半登場の第1世代Foveros Directには利用されないので、今すぐどうこうという話ではないが、まだまだ3Dパッケージング技術は発展の余地がある、ということを知らしめる発表となった。


この記事に関連するニュース
-
アプライド マテリアルズ エネルギー効率に優れたコンピューティングのサミットで先進パッケージング新コラボレーションモデルを発表
PR TIMES / 2024年11月22日 12時45分
-
【新刊案内】世界のチップレット・先端パッケージ 最新業界レポート 発行:(株)シーエムシー・リサーチ
PR TIMES / 2024年11月19日 10時45分
-
エクセルソフト、インテル・ソフト開発ツールの最新バージョン2025の販売を開始
週刊BCN+ / 2024年11月6日 15時19分
-
エクセルソフトは、HPC/AI アプリケーションの最適化および高速化、マルチアーキテクチャー・プログラミングを支援するインテル・ソフトウェア開発ツールの最新バージョン 2025 を販売開始
PR TIMES / 2024年11月6日 11時45分
-
12月11日(水) AndTech「先端半導体デバイスにおけるCu/Low-k多層配線技術、および 2.5D/3Dデバイス集積化技術の基礎から最新動向と今後の課題」Zoomセミナー講座を開講予定
PR TIMES / 2024年10月29日 10時15分
ランキング
-
1クレジットカードを少額で不正利用されていない? 巧妙な新手口を解説
ITmedia エンタープライズ / 2024年11月26日 7時15分
-
2リンク付き投稿は拡散力減?イーロン氏明かすXルール 「告知投稿めっちゃ影響」不満も続々
J-CASTニュース / 2024年11月26日 17時11分
-
3『ドラクエ3』大魔王ゾーマ様、配信者になる―自己紹介では「嫌いなもの:ひかりのたま」とポロリ、「“ほりい”とかいう人間も泣き叫んでた」
インサイド / 2024年11月26日 13時10分
-
4オリエンタルランド、東京ディズニーリゾート販売の“3800円のマイボトル”回収 対象個数は4240個…… 「ご迷惑とご心配」
ねとらぼ / 2024年11月26日 17時12分
-
5アップル「iOS 19」SiriがChatGPTみたいになる?
ASCII.jp / 2024年11月26日 20時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





