

グーグル、高クオリティかつ高速なテキスト画像生成モデル「Muse」を発表
ASCII.jp / 2023年1月5日 15時0分

グーグルは1月2日、従来のモデルよりも大幅に効率的でありながら、最先端の画像生成性能をもつテキスト画像AI生成モデル「Muse」を発表した。

競合モデルと同クオリティかつ超高速化
近年「Stable Diffusion」やOpenAIの「DALL-E 2」など、テキストから画像を生成するAIは驚くべき進化を見せている。グーグルもすでに「Imagen」と「Parti」という画像生成AIを発表しているが、「Muse」はそのどれとも異なる新しいモデルだ。

実際、1画像(512×512)あたりの生成時間はMuseが1.3秒となり、Stable Diffusion 1.4の3.7秒を明らかに上回っている。
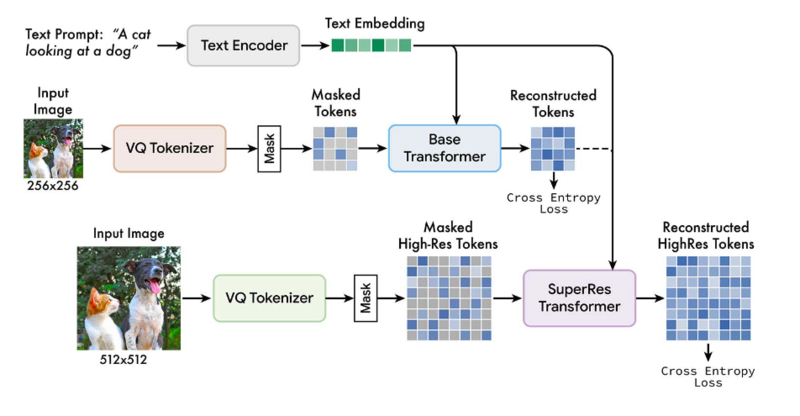
高速化の理由としては、ImagenやDALL-E 2などの拡散(diffusion)モデルと違い、量子化された画像トークン(学習用画像のセット)を使用することでサンプリングの反復回数を減らしていることと、Partiなどの自己回帰(autoregressive)モデルにはない並列デコードで効率を高めているためとしている。
テキストだけで複数の物体をコントロール

また、1から画像を生成するのではなく、あらかじめ用意した画像を編集することもできる。上記作例では「皿に置かれたケーキとカップに入ったカフェオレ」の写真を元画像として用意し、そこに「花のラテアートが描かれたカフェラテの隣にあるクロワッサン(A croissant next to a latte with a flower latte art.)」というテキストを入力することで、皿やカップはそのままにクロワッサンと花のラテアートの部分だけが編集されている。
マスクを使えば修正も書き足しも自由自在
さらに画像中の一部の要素だけを指定する「マスク」機能を使えば、マスク内だけを修正(Inpainting)したり、逆にマスク内はそのままに外側だけを書き足す(Outpainting)ことができる。

修正の例。上記の画像ではマットで指定された部分のお城がカットされ、代わりにテキストで指定された熱気球(Hot air balloons)が現れた。

書き足しの例。上記の画像ではマットで指定された建物はそのままに、周囲の背景がテキスト(Beautiful fall foliage)の指定通りに変更された。
今年は画像AIの実装が続くか?
現状グーグルはAIのデータセットにバイアスがかかる危険があるとして、一部(Imagenのみ米国限定でベータ版が利用可能)をのぞいて画像生成AIを公開していない。
一方、OpenAIに10億ドル出資しているマイクロソフトは、昨年10月に検索エンジン「Bing」に画像生成AI、DALL−E2を「Image Creator」としてすでに実装(日本では利用不可)しており、一部報道では「ChatGPT」を使った検索の強化も予定されているという。
もちろんAppleやAmazonといったライバル達もAI関連技術への莫大な投資を続けている。去年大きな注目を浴びた画像生成AI技術だが、このぶんだと今年はさらなる革命的な進化と実際のサービスへの実装例を多く見ることができそうだ。

この記事に関連するニュース
-
Ryzen AI 300 HXシリーズで画像生成がより手軽に、「Amuse 2.2 Beta」がStable Diffusion 3.5をサポート
マイナビニュース / 2024年11月26日 18時7分
-
NTTドコモ、生成AI「Stella AI」が1年間無料で使える「Stella AIセット割」
マイナビニュース / 2024年11月22日 17時57分
-
AIによる画像生成は次のレベルへ!最新のAIモデル「Stable Diffusion V3.5」を「MaisonAI」に新たに搭載
PR TIMES / 2024年11月22日 16時45分
-
株式会社SUPERNOVA、生成AIのニュースタンダード「Stella AI」を提供開始
PR TIMES / 2024年11月22日 15時15分
-
グーグル、iOS版「Gemini」アプリを公開 日本語で自然な会話ができるGemini Liveにも対応
ASCII.jp / 2024年11月15日 11時40分
ランキング
-
1クレジットカードを少額で不正利用されていない? 巧妙な新手口を解説
ITmedia エンタープライズ / 2024年11月26日 7時15分
-
2リンク付き投稿は拡散力減?イーロン氏明かすXルール 「告知投稿めっちゃ影響」不満も続々
J-CASTニュース / 2024年11月26日 17時11分
-
3『ドラクエ3』大魔王ゾーマ様、配信者になる―自己紹介では「嫌いなもの:ひかりのたま」とポロリ、「“ほりい”とかいう人間も泣き叫んでた」
インサイド / 2024年11月26日 13時10分
-
4オリエンタルランド、東京ディズニーリゾート販売の“3800円のマイボトル”回収 対象個数は4240個…… 「ご迷惑とご心配」
ねとらぼ / 2024年11月26日 17時12分
-
5アップル「iOS 19」SiriがChatGPTみたいになる?
ASCII.jp / 2024年11月26日 20時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





