

性能が8倍に向上したデータセンター向けAPU「Instinct MI300」 AMD CPUロードマップ
ASCII.jp / 2023年1月9日 12時0分

CES 2023におけるAMDのLisa Su CEOの基調講演の内容そのものはレポート記事にまとめられているので繰り返さないとして、今回は最後に紹介された隠し玉であるAMD Instinct MI300の話をしたい。
Instinct MI300に関しては情報が少ないのだが、2022年6月のFinancial Analyst Dayである程度まとまった話が出てきた。この時に出てきた情報は連載672回でまとめて説明したのだが、ただ筆者としてもいろいろ読み違いしていることが今回はっきりわかったので、その訂正も含めて新しい情報をまとめてみたい。
CPUとGPUとHBM3を1つにした Instinct MI300

昨年、上の画像が出ていた時点で気が付くべきだったのだろうが、Instinct MI300は本当にCPUダイとGPUダイ、さらにHBM3メモリーまでを1つのパッケージに収めたAPUの構造になっていた。

連載672回での説明は、CPUは別パッケージになって、MI300とCXLで接続することを前提にしたものであるが、これが根底から崩れたことになる。
さて、基調講演でのSu CEOの説明では、このInstinct MI300は9つの5nmチップレットと4つの6nmチップレットを、3D積層で接続したとしている。総トランジスタは1460億個で「AMDがこれまで製造した製品の中で最も複雑」というのもよくわかる。

ちなみに同じようにマルチチップレットを3D積層を用いて製造したインテルのPonte Vecchioの場合、総トランジスタ数が1000億個以上とされている。正確な数字はわからないのでどちらが上とは言えないが、ほぼ同クラスの複雑さを持っていることがわかる。性能/消費電力比そのものは以前も示された数字だが、性能8倍は今回初公開である。
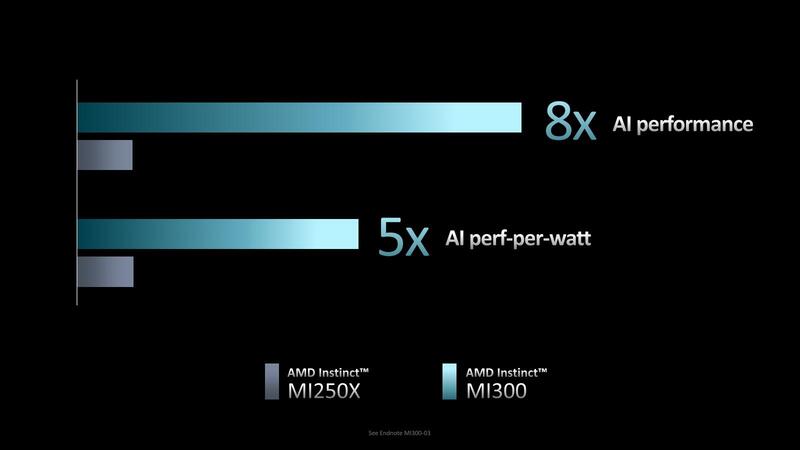
このAMD Instinct MI300は、2023年後半に投入予定とされる、というのが基調講演における説明である。

さて、ここからもう少し深く見ていきたい。まずSu CEOの説明によれば5nmチップレットが9個、6nmチップレットが4つなのだが、まずこの数が上の画像と全然合っていない。
下の画像はスライドからパッケージ部を大きく引き伸ばした上で試しにレイアウトを分類してみた構図だ。
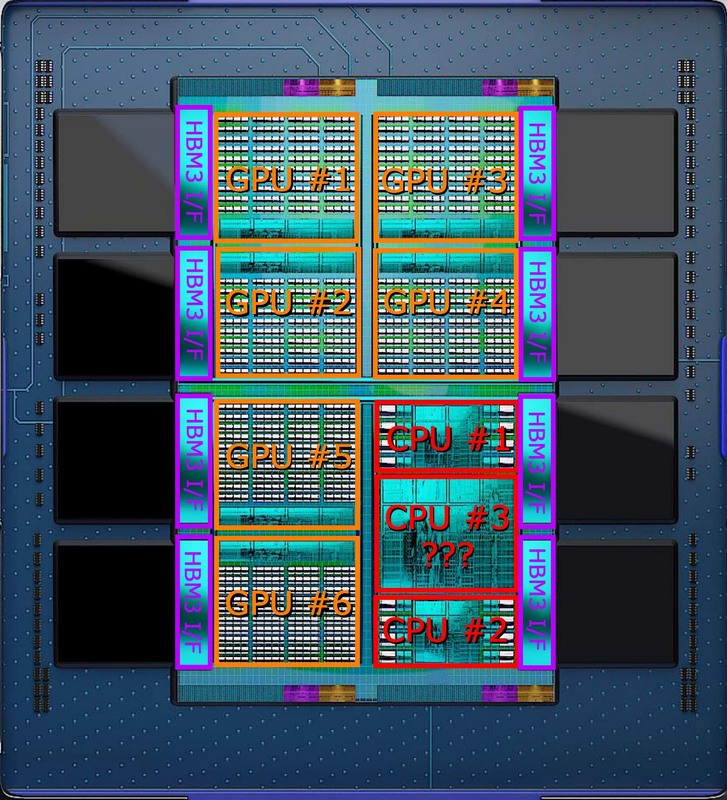
構造としては、上層にCPUチップレット×3とGPUチップレット×6があり、これはいずれも5nmで製造される。その一方で、下層には6nmで製造されたチップレット×4が配される。このチップレットはHBM3のI/F×2と、インフィニティ・ファブリックのI/F、それとおそらくは大容量の3次キャッシュを持つ形になる。この下層の6nmのチップレットの想像図が下の画像だ。
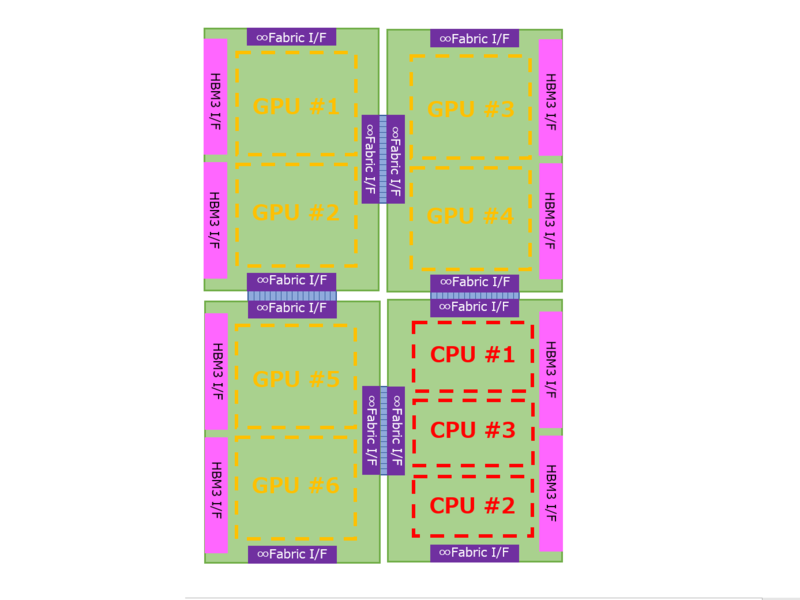
この4つのチップレットが厳密な意味で同じか? というと少し怪しい。構図で言えば、Sapphire Rapidsの4つのタイルをどう作るかという話と同じである。
上図で言えば、右下と左上、右上と左下はそれぞれ同じにできる「可能性がある」。ただ4つのタイルを完全に同じにするのは難しいだろう。それともう1つ、右下と左上のタイルは同一にできるか? というと不可能ではないが難しいだろう。
左上はCDNA 3のタイルが2つ載り、右下はZen 4のタイルが3つ載る。これを同一のタイルで実装するのはけっこう至難の業である。普通に考えたら別々にするのが妥当だろう。
そして、性能を上げるためには大容量キャッシュはどうしても必要になる。HBM3は合計の帯域は凄まじいが、GPUタイルあたり1つ、CPUに至っては3タイルで2つなので、実はCPU/GPUの演算ユニットあたりの帯域で考えるとそれほど大きいものではない。
加えて言えば、HBMはメモリーアクセスのレイテンシーが大きい。同様に大量のHBM2eを集積するPonte VecchioはRAMBOキャッシュを別タイルの形で実装しているし、Instinct MI250Xにしてもタイルあたり8MBの2次キャッシュを搭載している。
これはMI300も同じで、CUの塊とは別に大きなブロックがある。おそらく5nmのタイルの方に2次キャシュを搭載しており、それとは別に3次キャッシュを6nmのタイルの方に実装している、と筆者は考えている。
ちなみにGraphCoreのBOWや、Meteor Lakeのように、この下側のタイルがパワーデリバリー用という可能性も皆無ではないが、実際には違うと考えている。それはプロセスに起因する。
GraphCoreのBOWは公開されていない(TSMCの40nmという説もあるが、公式発表はない)が、Meteor LakeはIntel 22FFLである。連載658回でも説明したが、そもそもパワーデリバリー用であればTSMC N6である必要はまったくなく、もっと安価な28nmや40nmなどでも十分お釣りがくる。
もちろんHBMのI/Fとインフィニティ・ファブリックのI/Fが必要なので、そのあたりを勘案するとN6の方が都合が良いのはわかるが、N6のウェハーを使ってパワーデリバリーというのは、あまりにコスト的に無駄がありすぎる。
それに、もしパワーデリバリーが本当に必要なら、N5タイルとN6タイルの下に、さらにパワーデリバリー用の階層を設けることも不可能ではない。逆に言えば、N6タイルはそれ以外の用途に使うと考えた方がいいだろう。そしてN6は大容量のキャッシュの構成に都合がいい、という話はRadeon RX 7900シリーズの説明で述べたとおりだ。
さて、GPUの方はこれでいいとして、問題はCPUの方だ。MI300は24コアのZen 4コアを搭載する。ということは普通に考えれば8コアのタイル×3だ。実際下の画像を見ると、CPU #1とCPU #2は普通の8コアタイルだ。
寸法から言って、Ryzen 7000シリーズやEPYC 9004シリーズのCCDとは異なる(3次キャッシュがやや大きめ?)ように見えるが、そもそもRyzen 7000シリーズやEPYC 9004シリーズのCCDがそのまま使えるとは限らない。こちらは普通のオーガニックパッケージにC4 Bumpの形で実装される。一方Instinct MI300は3D積層なので、SoICに向けた構造が必要になる。
それはともかくとして#1と#2はまだ理解できる。理解できないのが倍近くのサイズのCPU #3である。構造的にはこれがキャッシュにしか見えないのだが、するとCPUコアの数が足りない。
そもそも上の画像のCGが本当に正確なのか? というあたりから疑わないといけなくなっているのだが、今回実物が示されたものの、CGと一緒かどうかを判断するにはやや解像度が足りない。ということで、この件はもう少し詳細がわかるまで先送りとさせていただきたい。


Instinct MI300のAI性能はMI250Xの8倍
次が性能の話である。今回Instinct MI300が「AI性能で」MI250Xの8倍になる、という説明があった。これをもう少し考察してみたい。MI250の内部構造は連載644回で説明したように、1つのダイに14×8=112XCUという計算であった。これが2ダイ構成なので合計224XCUである。ただ実際には2XCUは無効化して110XCUとして利用しているので、2ダイで220XCUである。
一方MI300は1つのタイルあたり4×10×4で160XCUとなる。これが6タイルなので無効XCUがないと仮定すると合計で960XCU。仮にXCUの性能そのものが変わらないとしても、これだけで4.37倍ほどの性能向上が実現する計算になる。
XCUは通常のベクトル演算以外に、FP16およびBF16のマトリックス演算をサポートしており、AI性能ということはおそらくこのマトリックス演算の性能と思われる。MI200の数字が下の画像であるが、通常のベクトル演算の8倍のスループットが実現できる。

さてMI300であるが、連載672回のスライドで、“New Math Formats”と言及されている。連載672回でも書いたが、これはFP16/BF16をFP8に変更した、という話である。
FP8のフォーマットは連載661回で説明しているが、仮数部は2bitないし3bitで、FP16の10bitやBF16の7bitに比べると大幅に桁数が少ない。したがって同じ演算回路規模なら2倍の性能向上が実現することになる。
先の4.37倍とこの2倍を掛け合わせると8.74倍という計算になり、8倍が簡単に実現してしまった形だ。実際には動作周波数が違う(おそらくMI200シリーズより下げないと間に合わない)だろうし、無効XCUなどもあるだろうから、もう少し性能比は縮まり、おおむね8倍程度になるのだろうと想像される。
つまりベクトル演算に限って言えば言えば4倍程度になるということだ。ちなみに計算の簡単化のために、ここにはZen 4コアの計算能力は加えていない。もしZen 4の分まで計算に入れると4倍を下回る可能性もある。ただAIで言えば、CDNA3はFP8で計算を行えるのに対し、Zen 4のAVX512に実装されているVNNIはINT8なりBF16なりでFP8には未対応である。なので恐らくZen 4の性能は加味されていないと思われる。
ところで性能が8倍になるのに消費電力効率は5倍、ということは絶対的な消費電力はMI200シリーズの1.6倍に跳ね上がることになる。MI250の場合は液冷で560W、空冷で500Wというスペックだったが、MI300ではそれぞれ896W/800Wになる計算だ。このクラスで空冷は非現実的なので、おそらくは液冷で900Wということになる。
OAM(OCP Accelerator Module)の最新スペック(v1.5)でも確認したが、P48V(48V電源ライン)の最大供給能力は700Wに限られており、「大丈夫なのか?」とやや気になる部分ではある。
とはいえ、MI300はこれ1つでFP64 Vectorが最大192TFlopsを実現する。El Capitanは1ノードにEPYC×1+Instinct MI300×4の構成である。このEPYC×1はおそらくネットワーク制御のみに使われるもので、計算処理はInstinct MI300で行なわれると思われる。
ということでノードあたりのFP64の性能は768TFlopsに達しており、2 EFlopsを実現するのに2605ノードあれば足りる計算になる。ノードあたりの消費電力は、MI300の消費電力を仮に900Wと仮定すると4KWほど。2605ノード分で10MW強に収まる計算だ。

実際にはEl Capitanの構築にはHPEも絡んでいるのでSlingshotでネットワークを構成するだろうし、計算ノード以外に管理ノードやストレージの分もあるだろうから10MWでは足りないだろうが、20MWには達しない程度で収まる計算になる。
Frontierの場合と同じく動作周波数をもう少し下げ、その分ノード数を増やして性能/消費電力比を向上させるかもしれない。ただFrontierが9248ノードと数が多く、その結果として絶対性能はともかく効率が低いという話は連載670回で触れたとおり。El Capitanはノード数が大幅に減っているので、この効率向上にも貢献しそうだ。
もともとAMDのリリースでは、El Caputanは2023年初頭に稼働という話であったが、実際にはやや後ろにズレた格好ではある。といってもすでにローレンス・リバモア国立研究所にはMilan+Instinct MI250X構成のパイロットシステムであるrzVernal/Tioga/Tenayaという3つのシステムが稼働中であり、2022年6月にはこの3つがすべてTOP500の200位以内に入っているというあたり、この程度の遅延は問題にならないのだろう。
というわけでCPUタイル周りは謎のままであるが、Instinct MI300がわりと現実的に出荷に向けて進んでいることが明らかになった発表であった。

この記事に関連するニュース
-
世界最速に躍り出たスパコンEl Capitanはどうやって性能を改善したのか? 周波数は変えずにあるものを落とす
ASCII.jp / 2024年11月25日 12時0分
-
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分
-
吉川明日論の半導体放談 第318回 データセンター市場で着々と地盤を強化するAMD
マイナビニュース / 2024年11月6日 7時15分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
-
AI性能を引き上げるInstinct MI325XとPensando Salina 400/Pollara 400がサーバーにインパクトをもたらす AMD CPUロードマップ
ASCII.jp / 2024年10月28日 13時0分
ランキング
-
1クレジットカードを少額で不正利用されていない? 巧妙な新手口を解説
ITmedia エンタープライズ / 2024年11月26日 7時15分
-
2往年の名作アクション「くにおくん」5タイトルを収録したスティック型ゲーム機、ライソンが発売
ITmedia NEWS / 2024年11月26日 22時29分
-
3「ハリー・ポッター」の“レプリカ剣”を回収 銃刀法違反の可能性か…… 運営謝罪「申し訳ございません」
ねとらぼ / 2024年11月26日 19時2分
-
4オリエンタルランド、東京ディズニーリゾート販売の“3800円のマイボトル”回収 対象個数は4240個…… 「ご迷惑とご心配」
ねとらぼ / 2024年11月26日 17時12分
-
5【最新】Wi-Fiルーターだけはいいものを買え、今ならこれでキマリだ
ASCII.jp / 2024年11月23日 17時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





