

メモリーに演算ユニットを内蔵した新興企業のEnCharge AI AIプロセッサーの昨今
ASCII.jp / 2023年2月6日 12時0分

今回取り上げるEnCharge AIは、創業したのが昨年2月なので、やっと1年経ったばかりというできたてホヤホヤなスタートアップ企業である。一応プロトタイプのシリコンは存在するようだが、外部に評価用チップを出荷できるような状況ではない。
さらに言えば同社がステルスモードを抜けたのは今年1月のこと。今年1月に同社は総額2170万ドルの投資を複数のベンチャーキャピタルやファンドから受けており、これに合わせてステルスモードから抜けた格好だ。なのだが、実は同社の技術は過去6年に渡って蓄積されてきたものである。

創業者はNaveen Verma教授(CEO)とKailash Gopalakrishnan博士(Chief Product Officer)、Echere Iroaga博士(COO)の3人である。Verma教授はプリンストン大のECE(Electrical and Computer Engineering)学部の教授職を現在も継続しながらEnCharge AIを立ち上げた格好だが、CPOのGopalakrishnan博士は2022年3月まではIBMのフェロー職にあり、COOのIroaga博士はIkanos CommunicationsからApplied Micro経由で、EnCharge AIに合流直前まではMACOMでVP&GM, Connectivity Business Unitというポジションにおられた。
ちなみにApplied Microは2017年にMACOMに買収された(連載446回参照)ので、これにともなってApplied MicroからMACOMに移籍された格好だ。
長年研究してきた演算ユニット内蔵メモリーを商品化
そんなEnCharge AIであるが、核となる技術はアナログベースのCIM(Compute-In-Memory)である。実はこれはVerma教授の研究テーマでもあり、プリンストン大でVerma教授はこの技術をずっと研究してきていた。冒頭に書いた過去6年の技術と言うのは、プリンストン大の中で行なわれてきた研究をさしている。
実際この技術は2021年のISSCCで“A Programmable Neural-Network Inference Accelerator Based on Scalable In-Memory Computing”として発表されている。発表したのはHongyang Jia博士以下7名であるが、これはVerma教授の研究室のメンバーであり、それもあって最後に指導教官であるVerma教授も名前を連ねている。ここで研究してきた技術をベースに実製品を構築する目的で創業されたのがEnCharge AIというわけだ。
さてそのEnCharge AIのコアであるが、先に書いたようにアナログベースのCIMである。CIMはこれまでも何度か説明してきたように、メモリーアクセスのコスト(主に消費電力)が圧倒的に低下することもあり、性能/消費電力比を引き上げるのには非常に効果的な仕組みとなっている。
デジタルベースで言えばSamsungのPIMやSK HynixのGDDR6-AiMがそうだし、Compute-Near-Memoryで言えばCerebrasのWSEやGraphCoreのTSPやインテルの試作AIプロセッサーなど多数ある。
ただデジタルベースでは、現実的には膨大なSRAMを搭載してここに演算ユニットを埋め込む形になるので、とにかくダイサイズが巨大化するという欠点があった(CerebrasのWSEなどその極北に位置する製品である)。
別のアプローチが、SRAM以外のメモリーを利用する方式である。TetraMemのmemristorやNORフラッシュを使うMythicのAMPやSyntiantのNDPなどがその例で、メモリー素子を利用してそのままアナログ的に畳み込み演算をすることで高効率化を図るというアプローチだ。EnCharge AIのアプローチも、このアナログ演算に近いのだが、最大の違いはメモリスタでもNORフラッシュでもないことである。
1152個のMAC演算を一発で行なうSIMD方式
まず基本的な構造を説明したい。ここから説明する構造は、2021年のISSCCの論文をベースとしたものなので、実際にEnCharge AIが開発しているチップとはディテールが多少異なるかもしれないが、基本的な仕組みは変わらないと考えられる。
下の画像がチップ全体の構造である。2021年にも試作チップが紹介されているが、これはCIMA(Compute-In-Memory Array)が16個の構成である。
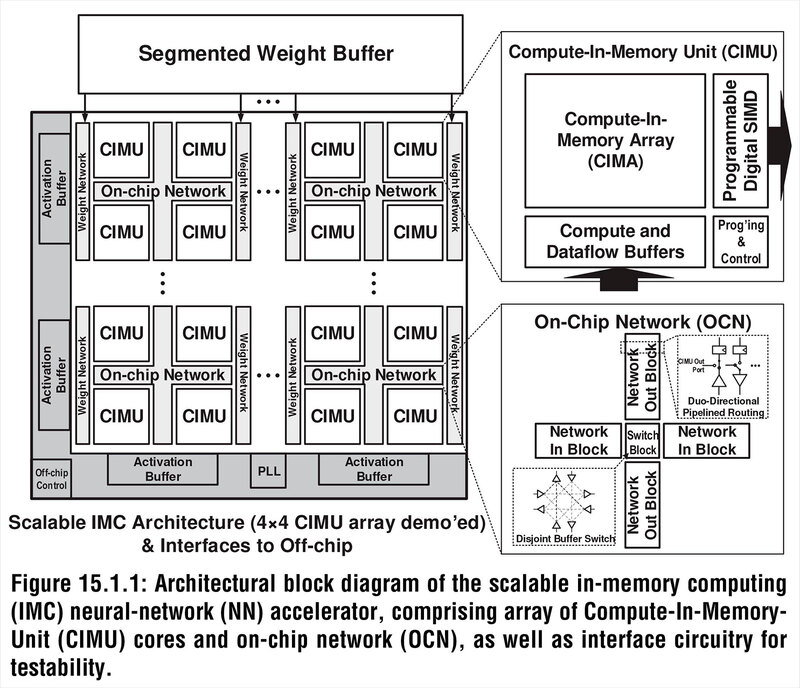
この16個が4つづつの組になっており、それぞれに重みデータロード用のネットワークI/Fが搭載される。また4つのCIMUは、オンチップ・ネットワークで接続される形になっている。
おのおののCIMUの中核はアナログベースのCIMUであるが、データを格納するためのバッファ、それと畳み込み演算の後のアクティベーションなどを行なうためのSIMDエンジンが組み合わされた格好になっている。アナログベースで計算しても、どこかでデジタルに変換する必要はあるわけで、それも含めてProgrammable Digital SIMDを搭載した格好だろう。
また、おもしろいのは重みに関してはローカルにバッファーを持たず、CIMUアレイの外にSRAMを用意。個々のCIMUにはその重みにアクセスするためのネットワークだけを搭載していることだ。
さてその核となるCIMAであるが、実に1152行×256列もの膨大な数の演算コアである。それぞれの演算コアは記憶を担うCL(要するにコンデンサー)と、これをアクセスするためのロジック(W/WB)から構成される。1152行ということは最大で1152個のMAC演算が一発で行なえるわけだ。
余談だが試作プロセッサーは5mm角で、そこにCIMUが16個収まっている。大雑把に言えばこのCIMUは1個あたり1mm角程度であり、そこに29万4912個のMAC演算ユニットとメモリーが収まる計算になる。つまりメモリー&演算ユニット1つあたり、3.4μm2程度に収まる計算である。
ちなみに製造プロセスはTSMCの16nmであり、TSMCの発表では16FFのSRAMセルサイズは0.07μm2と以前に発表があった。この0.07μm2は1bit分のサイズなので、8bit分だではそれだけで0.56μm2。ここにMAC演算ユニットを追加したら、3μm2前後になるわけで、現状はSRAMベースのCIMと同程度の効率でしかないが、これは研究用ということも考えれば十分だろう。
さてここからが肝心な部分だ。MythicやSyntiantは、記憶素子にNORフラッシュを利用した。要するにFloating Gate Flashであるがフラッシュメモリーは基本的にシリコンの上に酸化膜で挟み込む形でフローティングゲートと呼ばれる電荷を保持する領域を構築している(詳細は連載259回参照)。
ただこれはトランジスタなどと同じ仕組みなので、原理的にそれほど電荷の容量を大きくできない(トランジスタ層だから、高さを稼ぐのが難しい)という欠点がどうしても存在する。
その容量が大きくできないところにいろいろ工夫をして無理やり電荷を詰め込むわけだから、当然無理が出てくる。そもそもフラッシュの場合動作温度の変動などに敏感であり、常時監視をしてパラメーターを調整したり、場合によっては再キャリブレーションをする必要がある。
この技術そのものフラッシュメモリーでは一般的なのだが、この監視や調整/再キャリブレーションといった処理は当然デジタル的に行なうわけで、結果アナログ→デジタル→アナログの制御ループを積み重ねることになるので、無駄が多い。
もちろんフラッシュメモリーのように大容量の記憶セルを扱うのであれば、こうした監視/制御のためのロジックは相対的に小さくなるから無視できる範囲なのだが、CIMに使うにはバカにできない。
EnCharge AIではフラッシュの代わりに、配線層を利用してコンデンサーを構築し、ここに電荷を貯めるという形で問題を解決した。要は配線層は背も高いし面積も広くとれるので、大容量のコンデンサーを構築しやすい。これの極端な例が、インテルが10nm SuperFinで導入したSuper MIMである。SuperMIMは連載576回で説明したが、配線層の比較的上層に大容量コンデンサーを構築し、これをパスコンとして使うというものである。
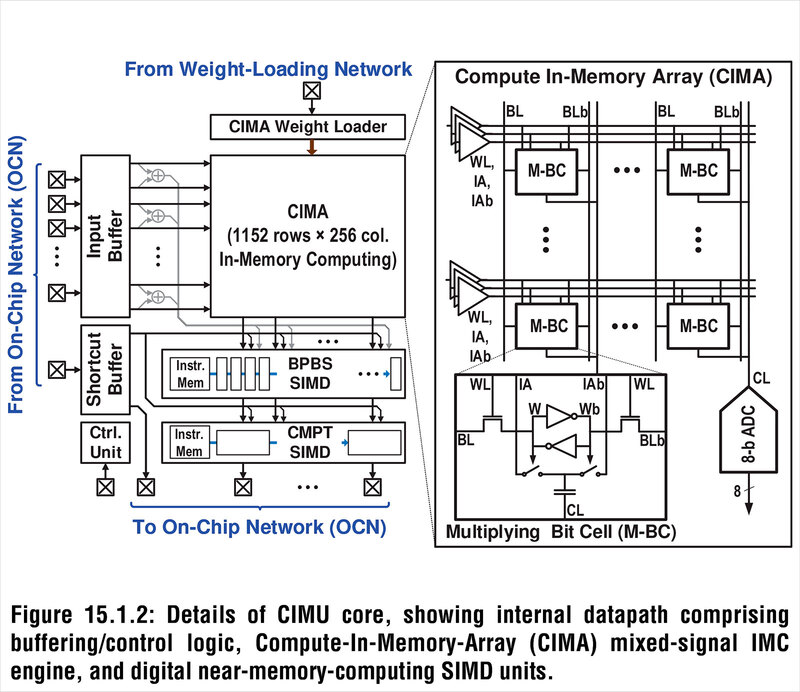
EnCharge AIはもう少し配線層の下層にコンデンサーを構築するもので、容量もSuperMIMに比べればずっと小さいが、それでもフローティングゲートに比べれば非常に大きな容量を稼げる。
そして容量が大きいということはSN比(信号/ノイズ比)を大きくできるということで、精度を上げる(≒データを多値化する)ことも難しくないし、補正やキャリブレーションの頻度も大幅に減らせる(=こうした回路の規模を小さくできる)ことになる。
フラッシュメモリーを使わず CMOSプロセスだけで実現できる
小型化については実験の結果からも示されている。下の画像はテストチップおよびシミュレーションの結果である。
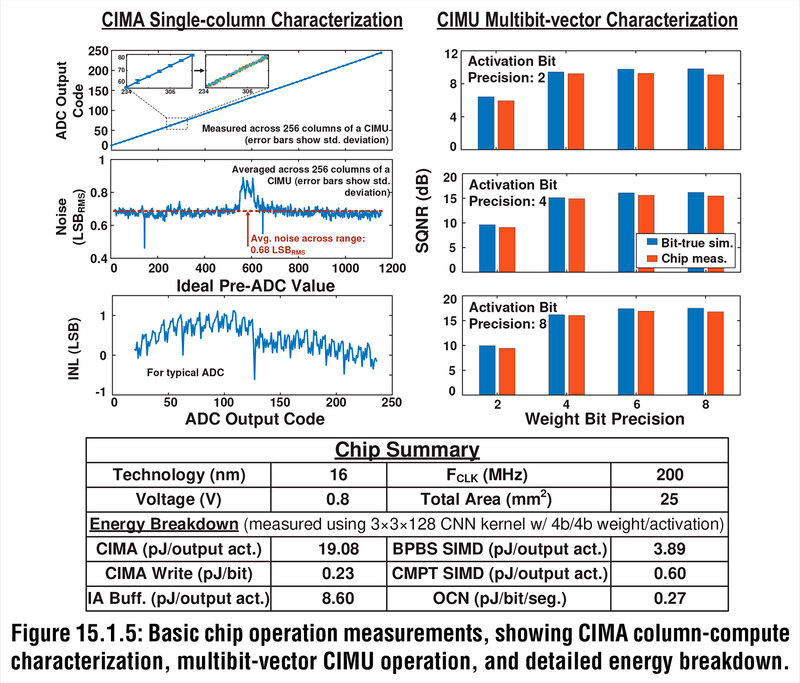
左上は、1つのコンデンサーに入力した電荷とその出力であり、きれいに直線的な関係にあることが示されている。その下の2つはADC(Analog/Digital Conversion)にかける前とかけた後の信号とノイズの関係で、非常にノイズが少ない(=入力した値をそれほど補正をかけずに出力として使える)ことを示している。
右はActivation BitとWeight Bit(アクティベーションと重み、それぞれの精度)とSQNR(Signal-to-Quantization-Noise Ratio:量子化を行なった後の信号とノイズの比率)である。
EnCharge AIの方法では、重みを8bit(つまり256段階)で取った場合でも、SN比が15dB(つまり信号とノイズの比が32倍弱)という、非常に大きなマージンが取れることになる。これはフラッシュベースのCIMではなかなか実現できない数値である。
上の画像の下部の表にもあるように、TSMCの16nmで試作したチップは5mm角とそれほど大きいものではないが、重要なのはこれが組み込みフラッシュを利用しない普通のCMOSプロセスだけで実現できることである。したがって、今回はTSMCの16nmでの試作だが、この先10nm/7nm/5nmと微細化することになんの問題もない。
強いていうならばコンデンサーの構築に配線層を使う関係で、7nmあたりまでは微細化の効果は大きそうだが、その先は配線層の微細化が止まりかけている関係もあってそれほど効果はなさそうだが、この試作チップでは121TOPS/Wという驚異的な数字を叩き出しており、他の方式と比べても遜色ない構成であることがわかる。
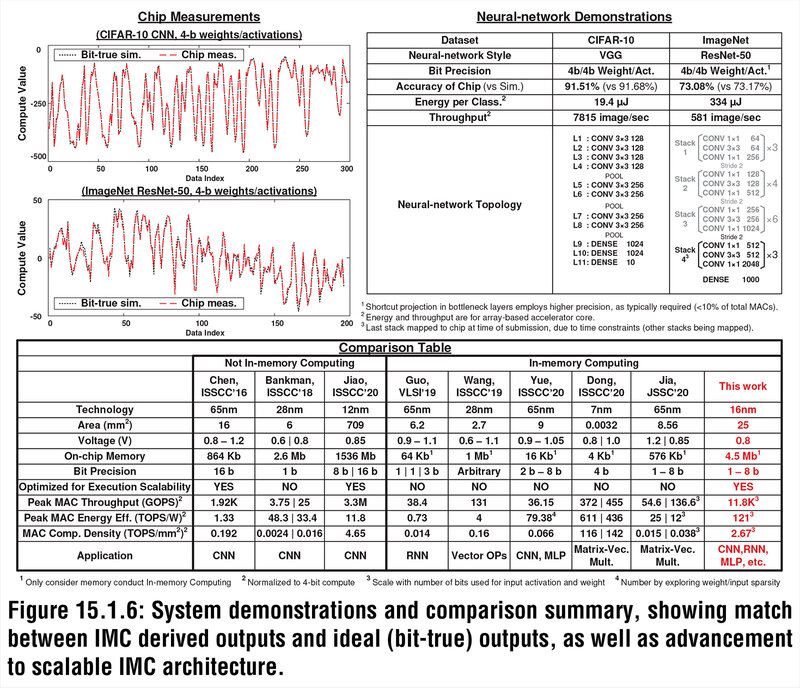
ここまでの発表はあくまでも研究の枠を出ないものであったが、すでにEnCharge AIは製品化に向けての最初の試作チップを完成させており、製品化に向けて着々と進んでいる。

この試作チップ、ずいぶん大きなものに見えるのだが、EnCharge AIのサイトに掲載された写真がこの試作チップのものだとすれば、これはPGAパッケージを使っているので極端に大きいのであって、チップそのものは相当小さいように見える。

ちなみにこのチップは150TOP/Wを超える効率を発揮する予定、とされている。無事に製品化にこぎつけるまでにはまだいろいろ障害はあるだろうが、乗り越えてがんばってほしいところだ。

この記事に関連するニュース
-
TSMC、中国向け「先端AI半導体」の製造受託停止へ アメリカ政府の対中輸出規制強化の前触れか
東洋経済オンライン / 2024年11月26日 15時0分
-
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分
-
半導体バブルに異変「AIかそれ以外」明暗くっきり "異次元の生産"に沸くアドバン、赤字のローム
東洋経済オンライン / 2024年11月15日 7時30分
-
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月11日 12時0分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
ランキング
-
1携帯ショップで働きたい人が減っている――現役店員が語る“理由”とは?
ITmedia Mobile / 2024年11月27日 17時5分
-
210000mAh前後の「大容量コンセントプラグ付きモバイルバッテリー」おすすめ4選 USBケーブル内蔵の3in1モデルも【2024年11月版】
Fav-Log by ITmedia / 2024年11月28日 6時25分
-
3そうはならんやろ! “炎の絵”を芸術的に描いたら…… “おきて破り”の衝撃ラストが1000万再生超え「泣いちゃいそう!」
ねとらぼ / 2024年11月28日 8時0分
-
4「Windows 11 2024 Update(バージョン24H2)」の既知の不具合まとめ【2024年11月27日現在】
ITmedia PC USER / 2024年11月27日 17時50分
-
5「声出して笑ったwww」 お母さんからLINE → 思わず目が覚める“衝撃のメッセージ”が590万表示 「戦況報告すぎる」
ねとらぼ / 2024年11月28日 7時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





