

なぜかRISC-Vに傾倒するTenstorrent AIプロセッサーの昨今
ASCII.jp / 2023年2月13日 12時0分

Tenstorrentは2021年1月、連載599回で解説した。ここから2年ほど経過し、順調に進んでいる部分もあるのだが、謎な方向への展開も見えてきた部分もあるので、今回はTenstorrentのアップデートをお送りしたい。
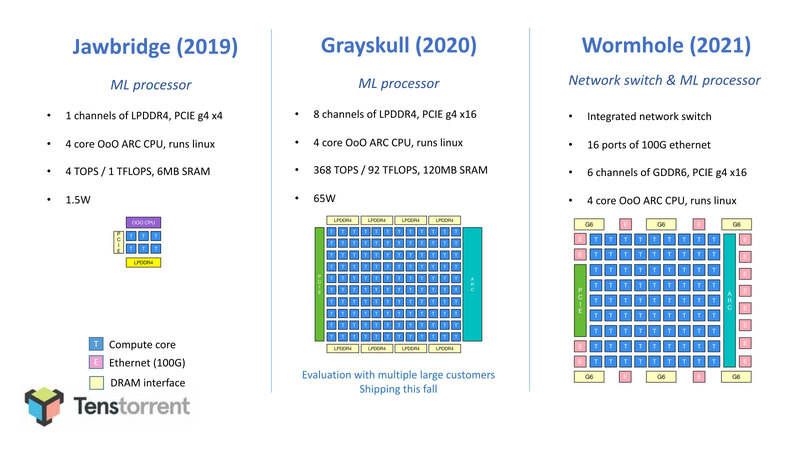
推論向けのJawbridgeとGrayskull 学習向けのWormholeとBlackhole
連載599回ではGrayskullについて説明したが、こちらはすでに量産に入っており広範に出荷されている。ボードにしても、ハーフサイズのe75と、長さ4分3のe150、e150と同じサイズのカードにGrayskullを2つ搭載したe300の3製品がラインナップされている。



もともとGlayskullが1.3GHzで368TOPSといった数字だったことを考えると、e75が900MHz動作、e150が1.3GHz動作、e300が1.1GHz動作×2といったあたりになっているのであろうと想像される。
さて、これに続く話であるがGrayskull(とこれに先立つJawbridge)はAI推論向けであるが、その次のWormholeと、さらにその後に投入予定のBlackholeはAI学習向けとなっている。そのWormholeの詳細をまずは説明する。
WormholeもGrayskull同様、TenstorrentのTensixコアをベースとした構成になっている。異なるのは全体の構成で、Grayskullは120個(12×10)のTensixコアに8chのLPDDR4 I/Fを組み合わせた構成だったのに対し、Whormholeは80個のTensixコアに6chのGDDR6を組み合わせ、さらに100GbE×16を搭載という、かなりI/O性能を高めた構成になっていることだ。
つまりチップ単体で言えば、WormholeはGrayskullよりも演算性能が低いことになる。これはどういうことか? というと、Wormholeは1チップでソリューションを構成するつもりが最初からない。
マルチチップ構成でAI学習に必要な演算性能を実現することを前提に、メモリーやインターコネクトのバランスを考えた結果が、Tensixコアの数をむしろ抑えるという結論である。

詳しい諸元はまだ公開されていないが、2021年当時だからGDDR6は16Gbpsあたりと想定すると、x32構成でチップ1個あたり64GB/秒ほど。6chで384GB/秒となり、Tensixコア1個あたり4.8GB/秒となる。Grayskullは120コアに対して100GB/秒だから、コアあたり1GB/秒未満の帯域でしかない。このあたりが、AI推論向けと学習向けの性格の違いを物語っている。
さて上の画像は2021年のLinley Spring Processor Conferenceのものだが、もう少し詳細な情報が2022年のISSCCで出てきている。以降の話はこれをベースに説明したい。
Tensixコア数を減らしても性能が向上したWormhole
WormholeはTensixコアそのものにも手が入り、よりスループットが向上した。この結果、Tensixコアの数は減ったにも関わらず性能そのものはむしろ向上している。そして上下には100GbEのMAC×16が搭載されている。


この16ポートのイーサネットは、もちろん外部に接続することも可能だが、基本はWormhole同士の接続に利用する。先にも書いたが、Wormholeはチップ1つでAI学習を実施するのではなく、大量のWormholeチップで協調動作を行なってAI学習を行なう方向性であり、その際のチップ間インターコネクトに100Gイーサネットを使うわけだ。
これに加えて、DRAMも上で書いたようにGDDR6 16Gbps 16Gbit品を使うことを前提に構成されており、1つのWormholeあたり384GB/秒の帯域と12GBの容量を利用可能となっている。
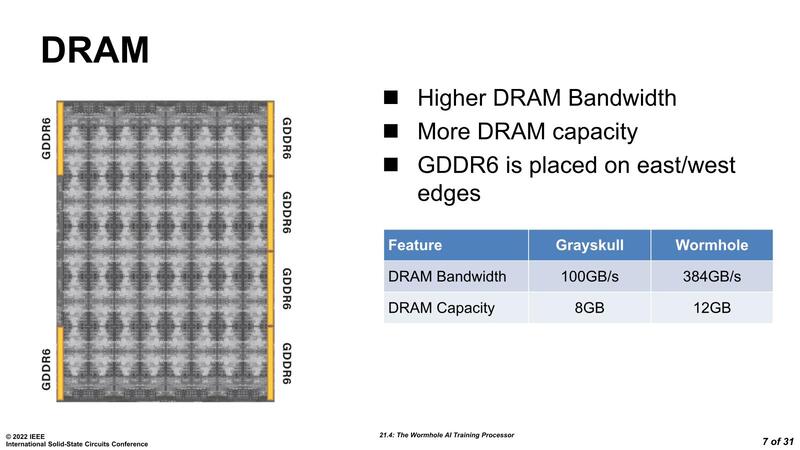
また外部I/FとしてPCIe Gen 4 x16を持つほか、4コアプロセッサーが制御用に搭載されている。


この制御プロセッサーはなにをしているのか? という話だが、ここにもあるように個々のTensixコアの動作制御やDVFS(Dynamic Voltage Frequency Scaling:要するにインテルのSpeedStepと同じ技術だ)などを行なう。
Wormholeの場合、ダイに6ヵ所の温度センサーと19ヵ所のプロセスセンサーが配されており、これでダイの温度や電流/動作周波数などを常に監視しており、これとワークロードをベースにDVFSを制御する。

このDVFSの制御も機械学習になっているそうで、この制御はARCベースのクワッドコアCPU+専用回路で実装されている。こうなると、ARCコアでLinuxが動く必要があるのかやや疑問であり、ひょっとすると当初はLinuxベースを想定していたはずだが、実装は異なるかもしれない。
Tensixコアは縦横4方向のリンクを持つ しかもNOCはマルチチップ構成で非常に有用
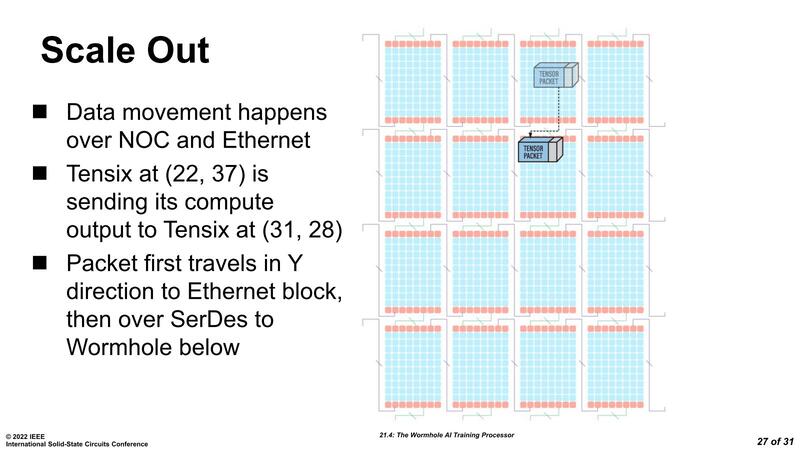
さて、GrayskullでもTensixコア同士はNoCで接続されているという話があったが、これはWormholeも同じである。下の画像がWormholeのネットワーク構成だが、すべてのTensixコアには2つのルーターが置かれ、それぞれのルーターは縦方向と横方向の2対のリンクを保持しており、結果としてTensixコアは縦横4方向のリンクを持つ構造になる。

このメッシュの上でNOCを構築するのはGrayskullと同じである。ただGrayskullではこれをNOCにする意味が今ひとつ不明だったのだが、続くスライドでその意味が完全に理解できた。
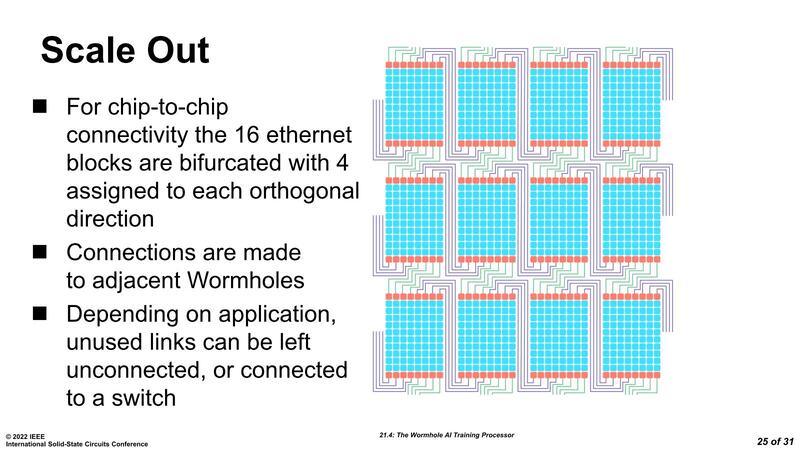
先にも書いたように、Wormholeは100GbEを16本搭載し、これを利用してチップ間接続が可能になっている。上の画像はこのWormholeを12個集約した例であるが、16本のGbEを4本づつに分けたうえで、それぞれ上下左右のWormholeと接続する格好である。
この際にリンクはGbEを経由して外部に引っ張り出される形になる。
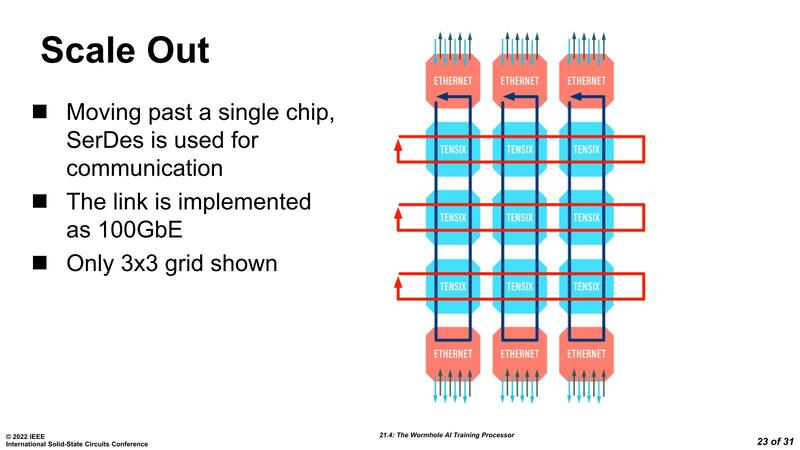
この構成で言えば、80×12=960個のTensixコアが特にパーティションもなにもない、均一な形で接続されているようにプログラマーからは見える。こうなってくると、NOCを利用するメリットは明確である。
Wormholeが1チップで動作しているのであれば、NOCのメリットはあまり感じられないが、物理的にどうつながっているかケースバイケースのマルチチップ構成でプログラミングをすることを考えると、NOCは非常に有用である。
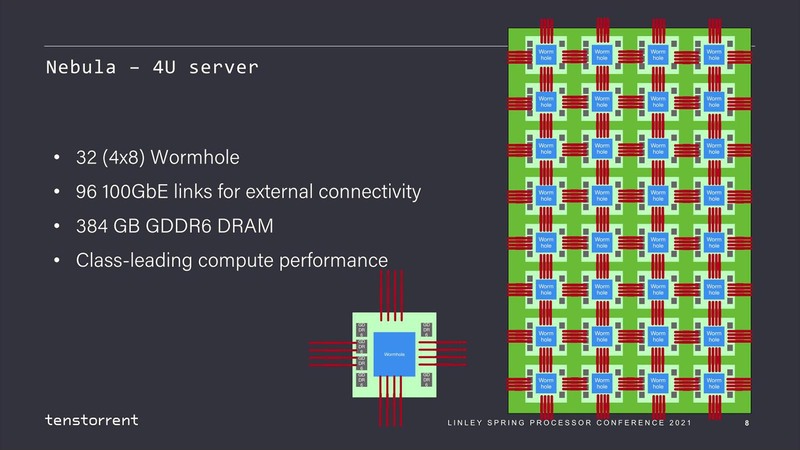
ちなみに2021年の計画では、このWormholeを32個つないだNebulaが4Uサーバーとして提供され、このNebulaを8つ搭載した48UのラックがGalaxyとされていた。
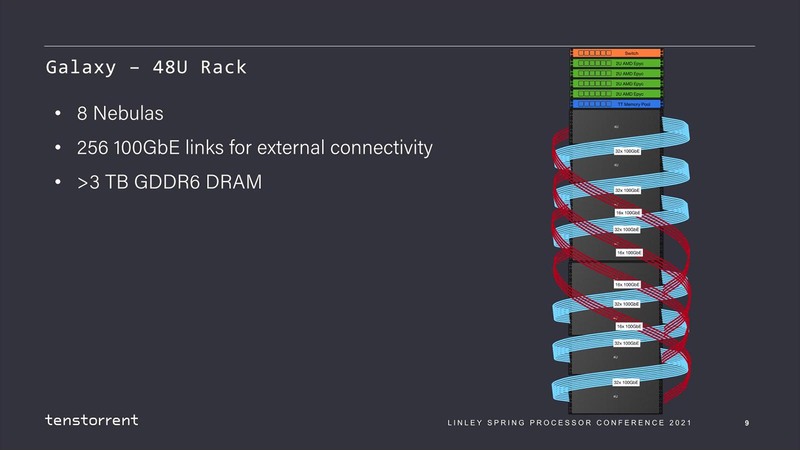
そのGalaxyの内部結線を分解したのが下の画像だ。
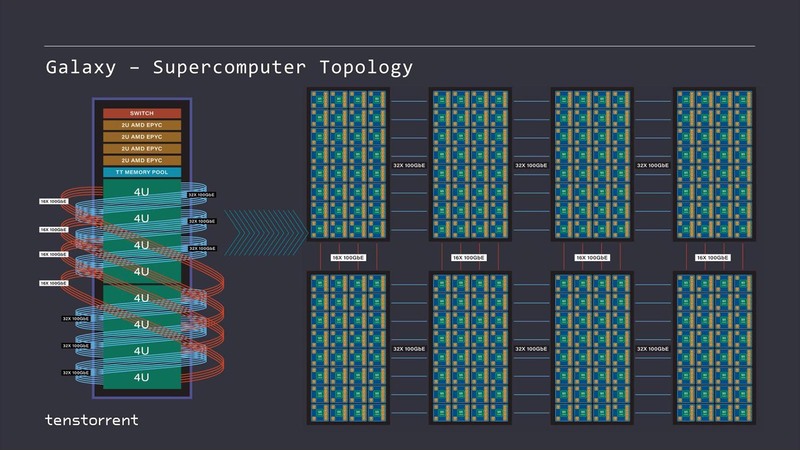
このGalaxyでは256個のWormholeが搭載され、Tensixコアはトータル2万480個、演算性能はFP16で110PFに達する。そして必要なら複数ラックをつないでさらに大規模な構成を構築することも可能だ。
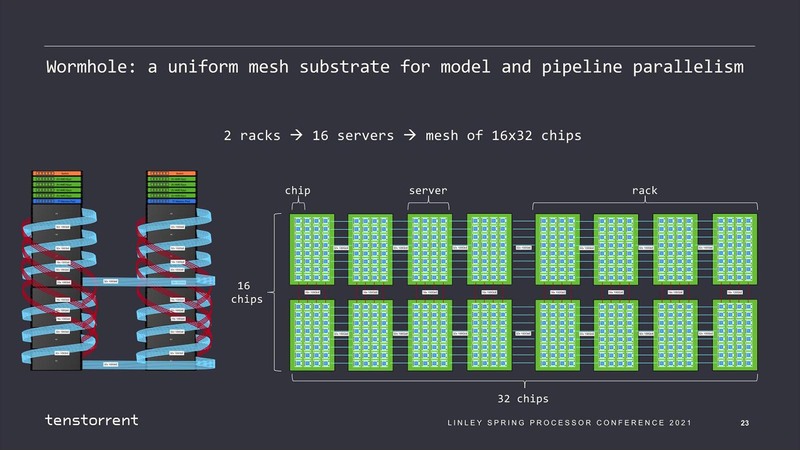
そして内部は、レイヤーの複雑さに応じてTensixコアの塊を任意のパーティションに区切ってそれぞれ処理させることで効率を上げられるとする。
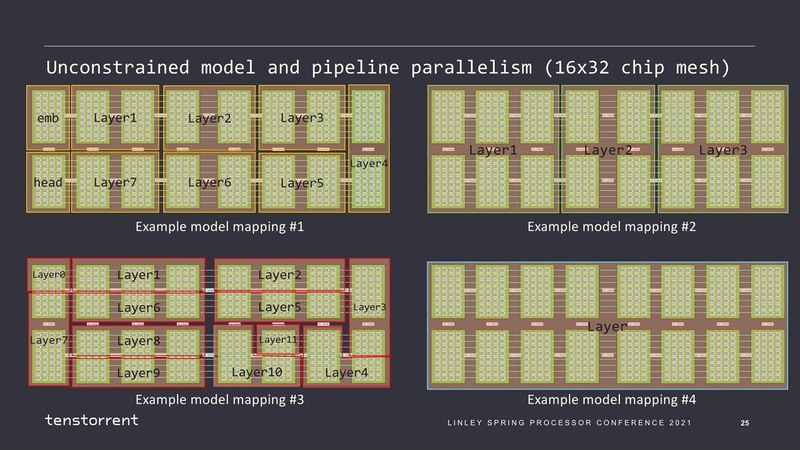
昨年2月の時点ですでに最初のサンプルはできあがっていたようで、予定では2022年第4四半期に出荷という話であったが、今のところまだ発表がないあたりはやや遅れているようだ。

次世代のBlackholeではRISC-Vを搭載 Tenstorrentの方向性が変わっていく
次はこれに続くBlackholeの話である。連載599回の冒頭でJim Keller氏がTenstorrentに加わった話をしたが、Keller氏はこのBlackholeから本格的に作業に加わったようだ。
2022年に入って、Tenstorrentは猛烈な勢いで人材を集めている。まず2022年2月9日にはArmのMachine Learning Research LabでSenior Director兼Distinguished EngineerだったMatthew Mattina氏をVP of Machine Learningとして引き抜き、6月22日にはLenovo NECの社長だったDavid Bennett氏をChief Customer Officerに据えている。
今年1月23日にはGoogleでStrategic AlliancesのDirector職だったKeith Witek氏をCOOとして迎え入れた。これに先立つ1月20日、同社は創業者兼CEOだったLjubisa Bajic氏とCTOだったJim Keller氏が役割を交代。Bajic氏がCTOとなり、Keller氏がCEOになるという、あまり類を見ないCEO交代劇が演じられている。
実を言えばBajic氏は2003~2013年と2014~2016年にAMDに在籍しており、Keller氏がAMDにいた2012~2015年にはわりと近い位置(2012~2013年はSr. Manager/Architect, IC Design、2014~2016年はDirector, IC Design/Architect)で仕事をしており、ある意味よく知った仲間であったからこそ実現できたことかもしれない。
こうした人材の拡充と一緒に、Tenstorrentの方向性もまた少し変わってきた。2022年1月に開催されたTSMCのOpen Innovation Summitにおける基調講演にKeller氏がTenstorrentのCTOとして講演したのだが、次世代の製品であるBlackholeはTSMCのN6で製造され、しかもTensixコアに加えてRISC-Vのコアと、さらにはSiFiveのX280ベクトルコアを搭載することを明らかにしている。
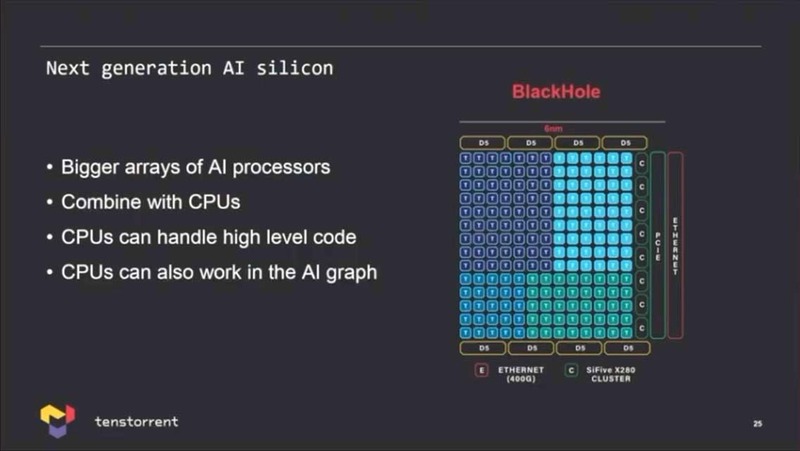
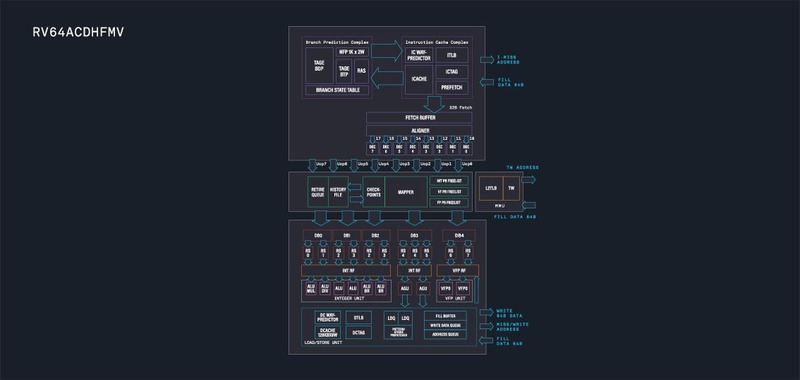
実は昨年からTenstorrentのProductsページにRISC-Vが加わっており、無償で提供されている4命令のアウト・オブ・オーダーコアのOcelotというコア以外に商用で2/3/4/6/8命令デコードのアウト・オブ・オーダーのAscalonというRISC-Vコアを開発しているとしている。D5というのはこのうち6命令デコードのコアの模様だ。
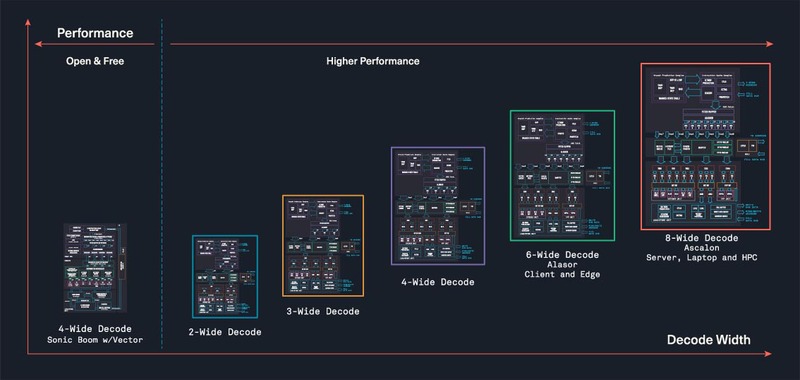
ちなみにTenstorrentはRISC-Vのみでもビジネスする気が出てきたのか、最大8命令同時デコード、11命令同時発行のコアや、そうしたコアを集約するCoherent Clusterを用意し、これとTensixコアを組み合わせた構成やAscalonだけを128コア組み合わせた構成なども示されているが、これはあくまでも可能性を示したレベルであって、これで現実に製品を提供するというつもりはなさそうである。
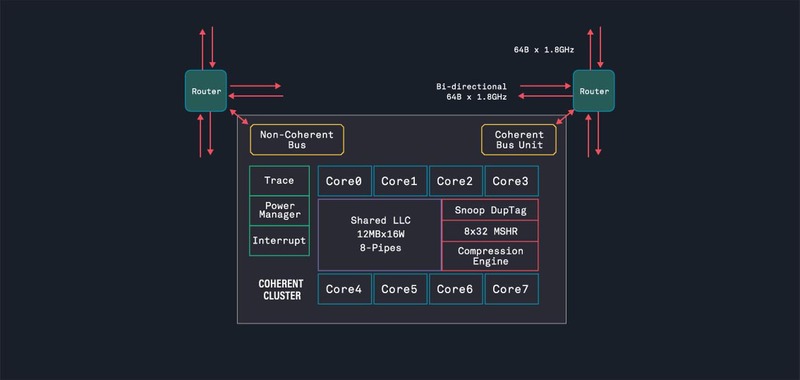
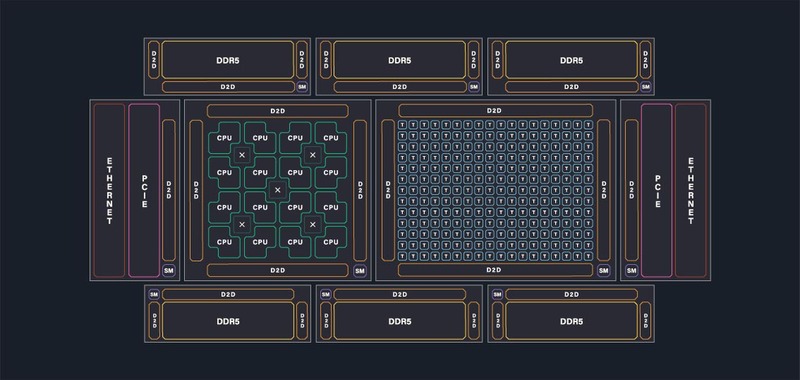
ただこれまではTensixコアで高効率にAIワークロードを処理する方向だったのが、Tensix+汎用(RISC-V)コアで、高効率に処理する方向に変わってきており、またKeller氏の基調講演の内容は、複数のネットワークモデルを同時に(Blackholeに)載せて、最適なものを利用するといった方法だったあたり、同社の方向性そのものが以前から少し変わってきた気がする。
サーバー向けのRISC-VコアやチップレットベースCPUなどもラインナップしているあたりは、もう単にAIのスタートアップというよりは、もっと幅広い市場に食い込むことを考えているのかもしれない。

この記事に関連するニュース
-
「Lunar Lake」Deep Diveレポート - 【Part 2】Memory、GPU、NPUについて
マイナビニュース / 2024年7月4日 14時23分
-
Lunar LakeではPコアのハイパースレッディングを廃止 インテル CPUロードマップ
ASCII.jp / 2024年7月1日 18時0分
-
Intel Tech Talkで見えたLunar Lakeにおける低消費電力と高性能の両立へのこだわり
マイナビニュース / 2024年6月27日 6時45分
-
【Gaudiシリーズを解説】生成AIに対し、広がる選択肢―Fugaku-LLMも快適に動作
マイナビニュース / 2024年6月18日 11時0分
-
COMPUTEXで判明したZen 5以降のプロセッサー戦略 AMD CPU/GPUロードマップ
ASCII.jp / 2024年6月17日 12時0分
ランキング
-
1楽天ペイと楽天ポイントのキャンペーンまとめ【7月4日最新版】 楽天ペイアプリでポイント最大10倍もらえる
ITmedia Mobile / 2024年7月4日 10時5分
-
2ドコモ、au、ソフトバンク、楽天モバイルの端末セールまとめ【7月5日最新版】 新スマホ「AQUOS R9」「Xperia 1 VI」をお得に入手しよう
ITmedia Mobile / 2024年7月5日 10時5分
-
37月10日は「納豆の日」 LINEヤフーが納豆にまつわる検索データ公開 ユーザーの関心明らかに
iza(イザ!) / 2024年7月5日 11時19分
-
4Google検索も不要に? 検索AI「Perplexity」がスゴすぎてちょっと怖い
ITmedia NEWS / 2024年7月5日 19時16分
-
5「ドコモ光 1ギガ」旧プランを2025年6月に提供終了、解約金の安い新プランへ自動移行
マイナビニュース / 2024年7月4日 19時15分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください







