

AIの著作権問題が複雑化
ASCII.jp / 2023年2月14日 9時0分

以前、画像生成AIを使ったイラストの模倣、「AIトレパク」が問題になっているという話をしましたが、画像生成AIと著作権の問題は国際的にも複雑化しています。まだ、現時点ではどうなるのかがはっきりしない混沌とした状況が進み続けています。しかし、現時点で大きなボトルネックになっているのは、計算をするGPUのチップ性能であるため、長い目で見たときには、今後必ず起きると予測できるのは、画像生成AIがリアルタイムに使われるようになり、それで生み出されるコンテンツが登場する未来です。
画像生成AIが集団訴訟を起こされる
アメリカで、1月に画像生成AIを開発し、サービスを展開しているStablity AIやMidjourneyなどを相手取って集団訴訟が提起されました(米The Vergeの記事)。著作権侵害を理由に、損害賠償と利用差し止めを求めています。プレスリリースでは「LAION-5Bデータセットに含まれる数十億の著作権で保護された画像で訓練され、アーティストからの補償や同意なしにダウンロードされ使用されています。(略)AI画像商品は、単にアーティストの権利を侵害するだけでなく、その狙いがあろうとなかろうと、アーティストという職業を消滅させることになる」と厳しい論調で述べています。LAION-5Bデータセットは、ドイツでAI向けの研究目的で作られ、主にネット上から収集された約58億枚のカラー画像のデータとタグ付けに利用できるテキスト処理が施されたデータです。
原告の立場からすれば、ドイツで研究用に作られた画像データセット(LAION-5B)をAIの学習に利用して、それを大規模に商用利用にも使うことはフェアユースの概念から大きく逸脱しているという主張です。アメリカの著作権法にはフェアユース条項があり、「批評、解説、ニュース報道、学問、研究を目的とする場合、著作権のある作品を許可なしで『限定』利用することを著作権法違反としない」とするものですが、その範囲をめぐって明確な定義がないため、裁判で争点が発生しやすいポイントです。
原告は「これらの製品が、大量の知的財産の使用を伴う他の新技術と同じルールに従うことを保証することを目的」としており、さらに「音楽のストリーミングが法律の範囲内で実現できるのであれば、AI製品も同じように実現できるはず」とも述べており、裁判を通じて、何らかの画像生成AIへのレギュレーションづくりに向かわせることも意図していることも明らかにしています。
この裁判以外にも、マイクロソフトとOpenAIに対しても集団訴訟が提起されるなど、生成系AIへの事業者を相手にした複数の集団訴訟が始まっています。まだ裁判は始まったばかりで、画像生成AIを提供する企業は全面的に争うと考えられるため、どのような結果になるのかはまったくわかりません。ただ、その結果は画像生成AIの未来に大きな影響を及ぼすと考えられているため注目されています。ちなみに日本においては、2019年の改正著作権法により、日本国内で画像生成AIが学習する場合は、どのような画像データセットを使っても合法です。
疑わしいモデルが人気になってしまった
いま画像生成AIのStable Diffusionで問題として認識されつつあるのは、簡単に追加のモデルデータを作れてしまうがゆえに起きてしまう複雑な問題の広がりです。
AUTOMATIC1111さんが作成したStable Diffusion WebUIには複数のモデルを組み合わせられる「チェックポイントマージャー」という機能がありますが、これがすごく強力なんです。
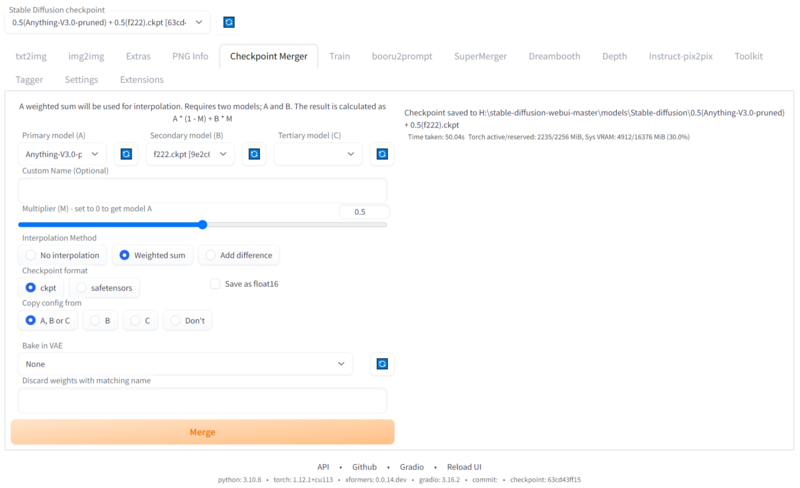
モデルデータを選択して、配分を何パーセントにするかを選ぶだけで、2分くらいで両方のモデルデータを混ぜた新しいマージモデルデータができてしまう。欧米圏では映画などのデータを追加で学習させた実写系のモデルデータも多数登場していますが、そこにアニメ系モデルを混ぜるとアニメと実写系の中間みたいなモデルデータも作成できてしまいます。これはモデルデータがベクトル情報といったパラメータの塊でしかないので、その数値をブレンドしているだからこそできることです。

そしてさらに事情をややこしくしているのは、昨年10月に違法にリークされたNovel AIのモデルデータが多くのアニメ系の派生モデルに混じった状態で使われているという問題です。
いまStable Diffusionには山のように追加学習モデルが出てきていますが、別の学習方法で作成されていると推測されるMidjourneyやNijijourney以外のほとんどのアニメ系モデルが、リーク版NovelAIからの派生であろうとみなされています。派生系で爆発的に人気が出たのが「Anything v3」ですが、これもリーク版Novel AIに中国のコミュニティで追加の画像学習をしたものと推測されています。(その経緯は「画像生成AIの激変は序の口に過ぎない」で紹介しています)
派生であるかどうかの判断としては、Novel AIとリークモデルとの比較をした「Hello Asuka」チャレンジというものがよく知られています。画像生成AIは、同じ学習データであれば、同じプロンプト(テキストによる命令)を入力すれば、同じ生成結果になるとされています。そこで、「新世紀エヴァンゲリオン」のアスカ風のキャラクターを生成することで、同じプロンプトで生成した画像の結果を比較するテストです。Novel AIとの出力結果とどれぐらい酷似しているのかを判断することで、リーク版Novel AIのデータが混じっているかどうかを一定程度推測できるとされています。
画像生成AI界隈でよく使われるモデルの系列調査 いわゆる"アスカチャレンジ"です 元々はNovelAIとリークNAIの関係調査に使われたものです それを手持ちのすべてのSD1.4系メジャーモデルに当てはめたのがこちらとなります 画質はご容赦を#AIart#waifudiffusion#anythingv3#ACertainThingpic.twitter.com/6aP8g0q4pz
— 高杉 光一🦋 with memory (@kuronagirai) January 8, 2023
様々な派生モデルで出力した結果が似るかどうかを検証した人もいますが、大半がリーク版Novel AIのデータが混じっていると考えられる結果なんですね。しかし、それも疑いまでであって、完全な証明は難しい状態です。
TikTokなどのSNSサービスが、AIアバター機能として自分の顔写真をアニメ顔に変換する機能をアプリに実装を始めており人気を集めていますが、これもリーク版NobelAIの派生ではないかという指摘もあります。しかし、何のモデルを使っているのかは一切明かされていないので、不明の状態のまま、商業利用にも広がっている可能性が出ているのが実情です。
一方で、NovelAIは、AI用のクラウドPCの環境として人気の高いGoogle Colabでリーク版Novel AIを使えないよう求めており、実際に使用できなくなっています。ただ、それ以上の法的なアクションは追加で起こしている様子はなく、また、派生モデルに対しても同様のようです。日々新しい派生モデルが登場し続けているなか、Novel AIが個々に訴えるというのも現実的とも思えません。しかし、リーク版Novel AIを利用する場合、特に商業利用をした場合、Novel AIから訴えられる法的なリスクは存在していると言えます。
作家のタッチが簡単に模倣できてしまう
さらにいまStable Diffusionで問題として認識されつつあるのが、簡単に追加学習用モデルを作れてしまうがゆえに起きてしまう、画風のコピーです。
21年7月に論文として発表されていたLoRA(Low-Rank Adaptation of Large Language Models:大規模言語モデルの低ランク適応)という手法が、昨年12月ごろにStable Diffusionで使えるようにしたプログラムが注目を集めるようになりました。この方法は学習によってターゲットする画像を30枚あまり用意して学習させると、その画像に近い雰囲気の画像を生成する学習データを生み出せる手法です。しかも必要とするVRAMの量も少なくてすみ、計算時間も10分程度で、新しい概念として学習を完了できるため、非常に簡単に特殊な学習データを追加で作れるメリットがあります。
その特性を利用して、有名なイラストレーターの画像を用意して学習させ、その学習モデルデータが公開されることが次々に起こるようになりました。
たとえば、1月に公開された「Pastel Mix」というモデルは中国人のイラストレーターMatchaさんのイラストを大量に読み込ませたものではないかとされています。本人も「(自分の絵をAIに)使わないでほしい」とTwitterで発言していますが、すでに学習済みモデルとして広く流通してしまっています。作成者もMatchaさんの画像を使ったと断言はしていませんが、ファンの人から見ると独特な色彩が似ていると感じられるというわけです。

難しいのは、作成されたデータは、Matchaさんの特徴は出しているように思われるものの、著作物としての依拠性を追求できるかがわからないところなんですよね。特徴的な配色は出力画像に出ているように見えますが、画風に著作権はないというのが一般的な解釈ではあります。やはり、根拠となる判例が作られないと、なんとも言えない状況です。
こうした形で特定のイラストレーターの画風を学習させるようなものが出てくると、アーティストにしてみれば「一所懸命に描いた絵を画像生成AIにパクられた」という気持ちになってしまいます。ただこれらのモデルは、ほぼ無料で公開されており、有料サービスとして出てきていないこともあり、的確な被害額の算定が難しく、訴えようもないという実情があります。
さらには、AI画像をSNSで積極的に発表している人の画像を、さらにLoRAで学習させて、その学習モデルデータを配布するというケースも登場しました。2月6日に公開された「Phantom Diffusion」というモデルデータでは、日本人のAI画像を発表している48人の直近の画像30枚を個別に学習し公開されています。それぞれのモデルデータが、その人の画像っぽい絵柄を生成します。このことが意味するのは、何の学習データやどのような設定で画像を生成しているのかがわからなくても、その人の作風を画像生成AIは学ぶことが可能になったという事実です。これも著作権的にどう位置づけるべきなのか、現状ははっきりとしません。

著作権問題は、世界レベルで混沌としている状況で、どのようになっていくのかは現時点では見通せないのが実情です。
著作権問題がクリアになればポストエフェクトに活用も
著作権関連の問題が複雑化していく一方、今から画像生成AIの技術がどう発達していくかについてのヒントも出てきています。中でも「今後生成系AIはこちらに動いていくのだろう」と感じさせられたのが、ポストエフェクト的な使い方でした。
ポストエフェクトというのは作成された画像に、後から色味の変更やライティングといったエフェクトをかけることで、より魅力的なものとして出力する方法です。処理が非常に重いため、CGの最終作成などに時間をかけて作成するものでした。しかし、この10年あまりの間に、コンピュータ性能の向上により、Unrel EngineやUnityといったゲームエンジンを使って、リアルタイムにポストエフェクトを使うことが当たり前になりました。今は1枚の画像生成にとても時間がかかっていますが、同じようなことが画像生成AIでも起こると予想がつくのです。
Yep, looks more stable. It's a totally different way of prompting and sometimes doesn't work at all but check out the background in this video. I want to see how much impact negative prompts make. How to use the text and image cfg etc "Make it a Van Gogh Painting" pic.twitter.com/fqILt7QOvt
— TomLikesRobots (@TomLikesRobots) January 29, 2023
画像から画像を生成する「Image-to-Image(i2i)」機能を使って、コマ撮りにした人物をゴッホ風の絵画にして、コマ撮り動画にするという例が登場してきています。今は動画でないと実現は難しいですが、ゲームや3Dに応用すれば、ローポリなモデルを用意するだけで、テクスチャやライティングなどをAIがリアルタイムで生成してくれるようになるというわけです。これまでゲームや3Dでポストエフェクトにかかっていた膨大なコストという問題が一気に解決できるようになります。
すでにリアルタイム生成ということでも面白い試みが行なわれています。生成した画像にDepth情報を追加で作成し、それをヒントにして、画像の中を矢印キーで歩き回れるようにしているものです。現在は1コマ変わるのに3~4秒くらいかかってしまうんですが、問題なのは計算能力だけなのでチップ性能が上昇化していくことで、いずれ解決するでしょう。いずれ一般的なゲーム機並の60fpsで生成するのが可能な時代も来ると予想できます。
リアルタイムなキーボード入力処理を実装したら、ついにGenerativeお散歩ゲームが形になった!!! 突然エッフェル塔が生えたりタイムリープしたり、そもそもfpsが0.3だったりで先は長いんだけど、Stable Diffusionが創る"世界"に触れさせてもらえた、というのが誠に感慨深い 夢の一つが叶った pic.twitter.com/sdOMkpAKmj
— Izumi Satoshi (@izumisatoshi05) January 21, 2023
極端な想像をするならば、現在の家庭用ゲーム機の世界では、限りなくリアルに近づいたグラフィックスを再現するための、アセットと呼ばれる3Dの素材を作成するコストが跳ね上がっています。しかし、より低コストで生成した、単純なポリゴンで構成された世界を、画像生成AIのi2iを使うことで、複雑な世界を自由に動き回れるようになる世界を作り出すことも、そう遠くない未来に実現されるであろうことが予想できます。
簡素に作った3Dデータを、様々なタッチで好きなように動かせるようになるという世界観。メタバースのような場所も、自分が求める雰囲気の世界を生成し、そこに簡単に入って歩き回れるようになるでしょう。

10年以内にGPUメーカーが「最新のチップでは、画像生成AIを使うことで過去のゲームを〇〇風の画像で60fpsで遊べる」ということを大きな売りにしてきたとしても驚くべき出来事ではないと思います。そうしたことが実現する頃までに、著作権問題について何らかの社会的な決着がついているといいのですが。
筆者紹介:新清士(しんきよし)

1970年生まれ。デジタルハリウッド大学院教授。慶應義塾大学商学部及び環境情報学部卒。ゲームジャーナリストとして活躍後、VRゲーム開発会社のよむネコ(現Thirdverse)を設立。VRマルチプレイ剣戟アクションゲーム「ソード・オブ・ガルガンチュア」の開発を主導。著書に8月に出た『メタバースビジネス覇権戦争』(NHK出版新書)がある。

この記事に関連するニュース
-
東洋経済新報社とVisual Bank 生成Al向け学習用データに関するデータパートナーシップ契約を締結
PR TIMES / 2024年11月28日 13時0分
-
Ryzen AI 300 HXシリーズで画像生成がより手軽に、「Amuse 2.2 Beta」がStable Diffusion 3.5をサポート
マイナビニュース / 2024年11月26日 18時7分
-
「デルアンバサダー“まもなく”4万人大感謝祭」の様子を見てきた。抽選を勝ち抜いたデル愛好家が大集合
マイナビニュース / 2024年11月26日 16時11分
-
AIによる画像生成は次のレベルへ!最新のAIモデル「Stable Diffusion V3.5」を「MaisonAI」に新たに搭載
PR TIMES / 2024年11月22日 16時45分
-
<特許取得済>画像生成AIを活用したホームステージング画像生成技術に関する研究発表が2024年度人工知能学会全国大会にて優秀賞を受賞
PR TIMES / 2024年11月5日 18時45分
ランキング
-
1ECナビカードプラス、2025年3月で年間利用ボーナスポイントを終了
ポイ探ニュース / 2024年11月28日 11時26分
-
2そうはならんやろ! “炎の絵”を芸術的に描いたら…… “おきて破り”の衝撃ラストが1000万再生超え「泣いちゃいそう!」
ねとらぼ / 2024年11月28日 8時0分
-
3どうする? 大学生用パソコンの選び方 「4年通しよりも2年で買い替え」がオススメな理由
ITmedia NEWS / 2024年11月28日 13時26分
-
4Dynabook、セルフ交換バッテリー機構を搭載した14型ノートPC「X74」
マイナビニュース / 2024年11月28日 11時3分
-
510000mAh前後の「大容量コンセントプラグ付きモバイルバッテリー」おすすめ4選 USBケーブル内蔵の3in1モデルも【2024年11月版】
Fav-Log by ITmedia / 2024年11月28日 6時25分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





