

電気自動車のTeslaが手掛ける自動運転用システムDojo AIプロセッサーの昨今
ASCII.jp / 2023年3月6日 12時0分

今回取り上げるのはTeslaのDojoである。そもそもTeslaの車と言えば電動車であることと、他社に先駆けて自動運転の仕組みを取り入れていることが特徴なのはご存じのとおり。ついでに言えばその自動運転のシステムを自社で構築していることも特徴的である。
下の画像は2019年に開催されたPytorch DevCon 2019でTeslaのAndrej Karpathy博士(Sr Director of AI:現在はTeslaから離職した模様)が示した、Teslaの自動運転に関わるスタックの様子であるが、ハードウェアとしてTeslaの車に搭載されるのは、上から2つ目の“Inference @ FSD Computer”である。

FSDは“Full Self Drive”の略で、このチップ自身もなかなか壮絶な代物で、当然Teslaの内製である。このFSDの詳細は別の機会に紹介するとして、右下に謎の“Dojo Cluster”というコンポーネントがあるのがわるだろうか?
Teslaの自動運転車の場合、走行時にその走行の様子を記録したデータ(含ビデオデータ)を、常にTesla社に送信している。Teslaはそのデータを基に、より良い自動運転のアルゴリズムを常に改良し続けている。この改良を担うのがDojoだ。
要するにFSDは自動運転のアルゴリズムを使って推論を行ない、それを基に運転操作をする。一方でその際に得られた運転データを利用して学習し、より良い自動運転アルゴリズムを開発する。この学習を行なうためのシステムがDojoである。
このDojoの詳細が公開されたのは昨年8月に開催されたHotChips 34である。実はこの時点でもまだDojoはフル稼働していない。ではDojoが完成するまでの間はどうしていたか? というと、NVIDIAのA100ベースのスーパーコンピューターを構築し、ここで学習していた。
下の画像はこのスーパーコンピューターのプレスリリースでの写真だが、A100を5760枚集積したクラスターでこの学習処理をしていた。

ただこのクラスターを利用しても、一部のアルゴリズムでは学習に1か月近くを要するものがあったらしい。Dojoの目的は、これを1日に短縮することである。つまり現在のA100ベースのクラスターよりも30倍高速なシステムを構築するというのがDojoのターゲットとなる。
さてそのDojoであるが、基本となるタイル(Compute Die+I/O Die)の構成はCelebrasのWSEを連想させる、巨大なウェハーサイズの構造である。

これだけでも大概であるのだが、このウェハーサイズのタイルは、それぞれ個別にパワーデリバリーと冷却をワンパッケージにした形で構成される。

こんな構造になるから、当然液冷になるのだろう。ちなみにTeslaによれば、1個のタイルあたりで9PFlops(BF16/CFP8)の演算性能を実現、オンタイルメモリーは11GBのECC付きSRAMで、帯域はオンタイルメモリーのみで10TB/秒、オフタイル(つまりタイル間でのメモリー転送)を含めると平均36TB/秒とされている。
ただこのコンピュートタイルは純粋に計算をするだけの処理なので、外部とのI/Fがない。これを担うのが、Dojo Interface Processorである。
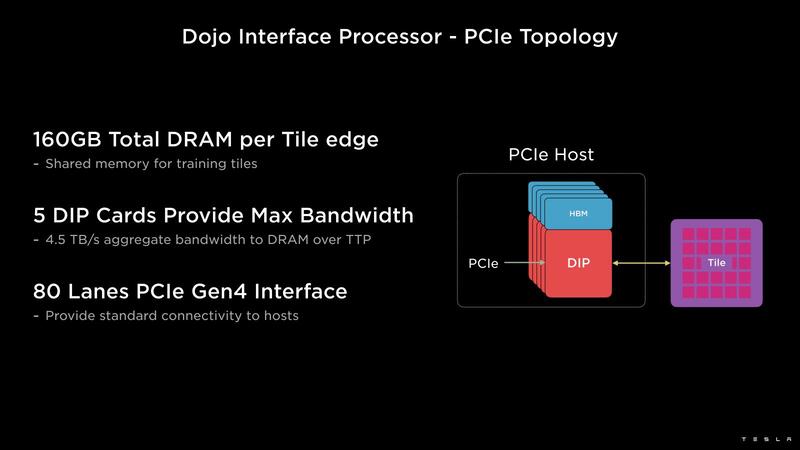
こちらは外部の共有メモリーと、ネットワーク/ホストとのI/Fを担う格好である。1つのDIPカードにはDIPが2つ搭載され、それぞれのDIPにはHBM2が2つづつ接続されている。
このDIPの中身は明確にはなっていないが、下の写真を見る限りはArmベースのSoCでイーサネットを内蔵したチップのようだ。

外部I/FはPCIe Gen4 x16で、これがボード上のPCIe Switch経由につながり、最終的にホストに接続される構成らしい。ちなみにコンピュートタイル自身も相互接続可能になっており、それぞれ9TB/秒で接続される。
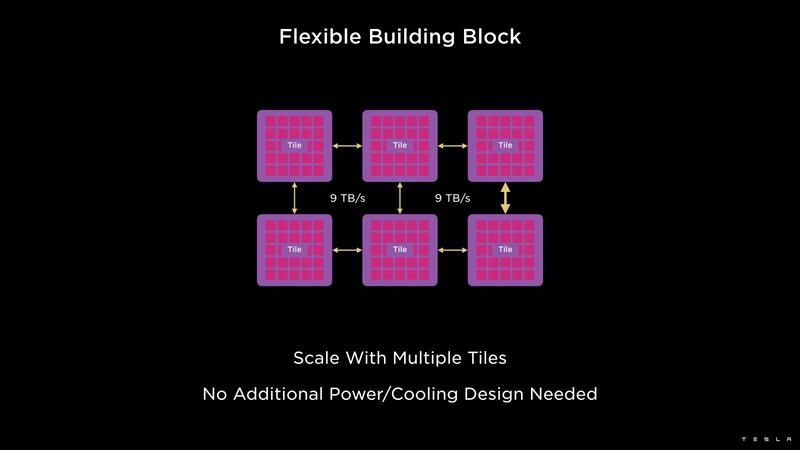
ここで少しおもしろいのが、コンピュートタイル同士の接続とDIP経由の接続の使い分けである。コンピュートタイル同士はけっこうな数の接続が可能であるが、規模が大きいと当然その際の通信の遅延が大きくなる。
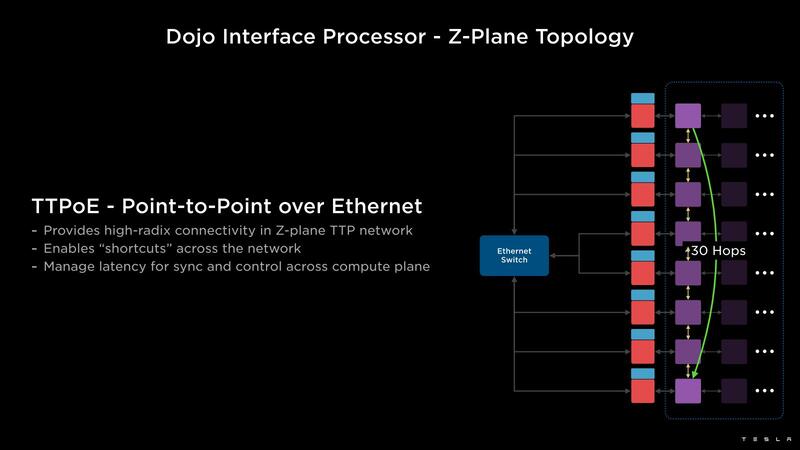
その場合、DIP経由で直接Point-to-Pointで通信を行なうことで、Hop数を大幅に減らせることになる。TeslaはこれをZ-Plane Topologyと呼んでいるが、要するに相手との距離次第でコンピュートタイル同士の接続とDIP経由の接続を使いわけすることで、遅延を大幅に減らせるというわけだ。
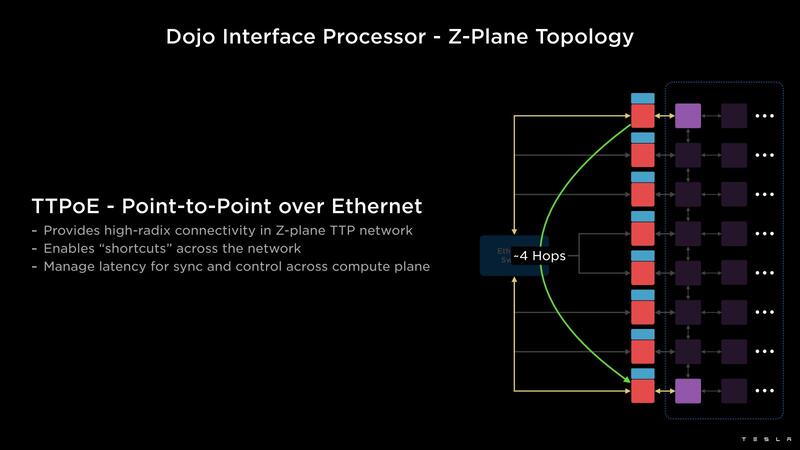
実際のDojoのシステム全体は下の画像のとおりである。複数のコンピュートタイル同士を相互接続し、その外側にDIPが並ぶ構造だ。これを組み合わせて、1EFlopsの演算性能とオンタイルで1.3TBのSRAM、それに13TBのHBMメモリーが用意される格好になる。
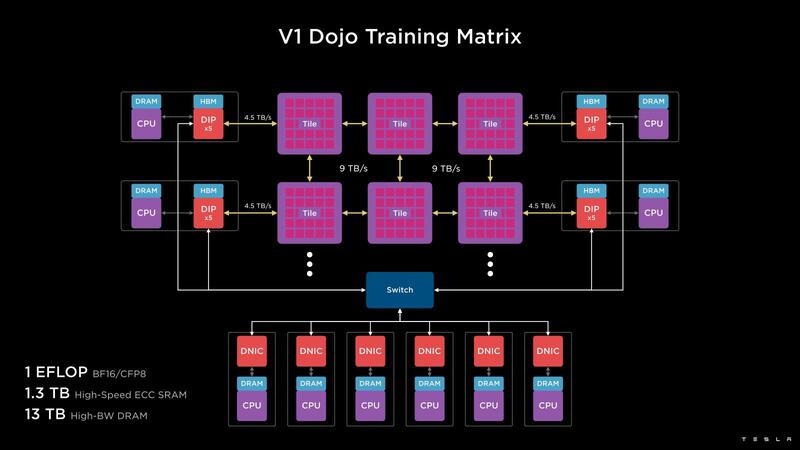
Dojo Nodeを縦横に354個集積したD1ダイ ダイサイズは645mm2とかなりの大きさ
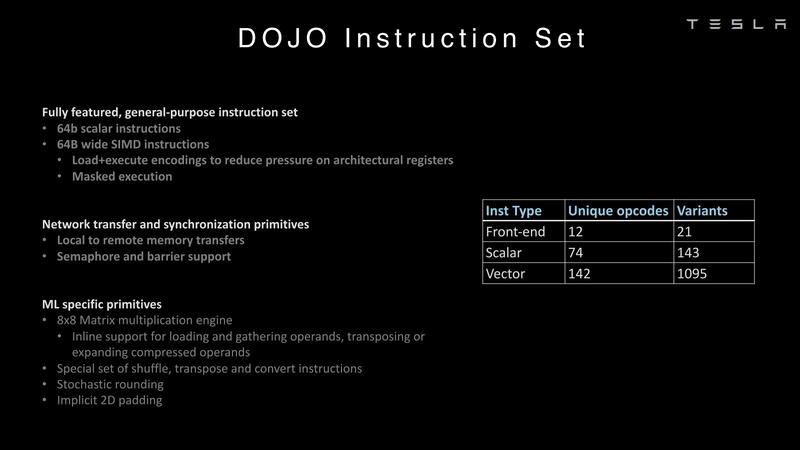
ここからはコンピュートタイルの中身をもう少し説明したい。コンピュートタイルの根幹をなすのは、4-wayのスーパースカラーなコアである。独自命令セットであり、RISC-Vをカスタマイズとかそういうわけでもない。
DojoはTeslaのみが使うシステムなので、別にRISC-Vでなくても良いということだろう。このコアの特徴であるが、以下のような独特な構成である。
- フェッチは32Bytes/サイクルで、最大8命令のフェッチが可能。
- デコードは8-wideで、2スレッド/サイクルの処理が可能(つまり4-way SMTではあるが、1サイクルあたり2スレッド分しか命令は供給されない)
- ALU×2/AGU×2の4-way SMT構成。ただしフェッチバッファやALUのレジスターファイルなどはスレッドの数だけ用意される。
- FPUは搭載しない(というか、そもそもデータ型がBF16/CFP8という時点で、ALUがなくFPUのみというべきなのだろうか?)が、ベクトルというかSIMDエンジンは搭載される。こちらは2-wideで、64Bytes幅である。ここで最大8×8×4の行列乗算が可能。
- 仮想記憶はなし。メモリー保護機能も最小限。スレッド間でのリソース共有(共有メモリーなど)はソフトウェアで制御する。
- 通常アプリケーションスレッドが1~2個と、コミュニケーションスレッドが1~2個走る。
このパイプラインに、1.25MBのSRAMが割り当てられる。こちらは図からもわかるように命令とデータの両方を格納する形であるが、キャッシュというよりはスクラッチパッドという方が正確だろう。
このSRAMはロード400Gbps、ストア270Gbpsの帯域を持っており、またベクトルレジスターにデータを格納するにあたって、並び替えを行なうGather Engineを実装している。
これは例えば行列乗算では行と列を入れ替えるような操作が必要になるこが多く、これをソフトウェアでなくハードウェアで行なうことで効率化を図るためと考えられる。
逆にキャッシュにあたるものは存在しない。むしろキャッシュを使わなくても、4-wayスレッドで命令やデータのロード時間を遮蔽できるから、無理にキャッシュを入れて制御を複雑にする必要はない、という判断かと思われる。
このCPUパイプライン+1.25MB SRAMをDojo Nodeと呼ぶが、実際には複数のノードが2次元構造でつながっている。この接続を担うのがNOCルーターで、東西南北にそれぞれ128Bytes/サイクル(実際は送受信各64Bytes/サイクルと思われる)で接続可能であり、またNOCルーターとSRAMの間もそれぞれ64Bytes/サイクルで接続される。
このNOCルーターは東西南北にある別のNOCルーターとの間で8パケット/サイクルの転送が可能であり、また各々のルーターはSRAMに対して直接DMAで転送を行なえるので、CPUパイプラインの側に負荷をかけずに転送可能となっている。
ちなみにCPUパイプラインの命令セットはこんな感じ。確かにあまり一般的な感じはしないし、RISC-Vにするメリットも少なそうだ。
さてこのDojo Nodeを縦横に354個集積したのがD1ダイとなる。TSMCのN7ながら動作周波数は2GHzとやや低めで、Low Power Cell Libraryで構築されている可能性もある。
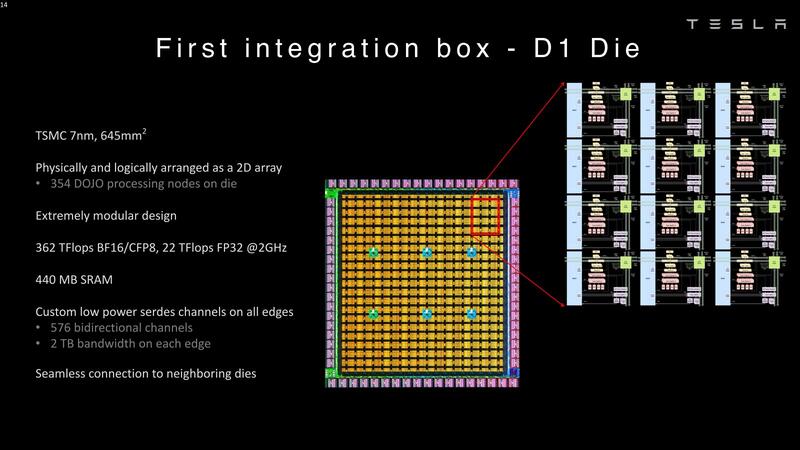
性能はBF16/CFP8では362TFlopsと、ノードの数のわりに少し高めだが、これはベクトルユニットを利用した場合の数字と思われる。ベクトルを使えないFP32では22TFlopsとやや低めに推移している。
このD1ダイ1つで440MB(正確には442.5MB)のSRAMを実装しているが、それもあってダイサイズは645mm2とかなりの大きさ。これを25個集積し、さらにその外側にI/O用のダイを40個(つまり一辺あたり10個:1つのD1ダイあたり2個接続される計算である)配したのがDojoタイルである。つまり1つのタイルには8850個のノードが含まれ、11GBのSRAMが内蔵される形だ。
ExaPodが今年第1四半期に稼働予定
ここからは昨年9月末に開催されたTesla AI Dayのスライドからご紹介したい。ちなみに全体では3時間半にもおよんでおり、1時間57分からDojo Introduction、2時間23分あたりからDojo Hardwareの説明が行なわれている。
まずトレーニングタイルだが、システムにはこれが6つ相互接続する形で1つのトレイに収まる。これがシステムトレイである。

一方DIPは、そのトレイの下に並ぶ。その20枚のDIPカードがちょうどささるように、ホストCPUのシャーシが用意される。こちらは構成は明らかになっていないが、PCIeスロットの数とかコアの数を考えると、Milanベースの1ソケットEPYCサーバーが4台入っているように思える。



技術的に言えば、同じくMilanベースの2ソケットEPYCサーバー(これだと最大でPCIe Gen4レーンを162本出せる)を2台という可能性もあるが、そこで2ソケットにする意味があまり見当たらない。
トータルメモリーは8TBというあたり、EPYCサーバーあたり2TBという計算だ。このDojo Host Interfaceを2つ積み重ねたのがDojo Cabinetであり、そのDojo Cabinetを複数並べたのがExaPODである。


Dojoの、AI Dayにおける説明では以下の数字が示されている。
- 24 GPU(A100) vs 25 D1では、バッチ処理のレイテンシーが150μs vs 5μsで30倍高速
- 自動ラベリングやOccupancy network(境界面を使ったネットワーク分類)などの処理でA100と比較して最大3.2~4.4倍高速
- 1つのコンピュートタイルでGPU BOXが6つ分以上の性能。そしてコンピュートタイルの価格は1つのGPU BOX未満
- 4つのDojoキャビネットで、既存の72ラックのGPUサーバーを代替できる。といった数字が示されている。
最初のExaPodは今年第1四半期(つまり今月だ)中に稼働予定であり、Teslaは将来的にパロアルト(Tesla本社所在地)に7つのExaPodを稼働予定としている。
なんというか、数は力とでもいうべきソリューションである。とはいえ自動運転のアルゴリズムを改良していくのには、このくらいのパワーが必要なのかもしれない。

この記事に関連するニュース
-
世界最速に躍り出たスパコンEl Capitanはどうやって性能を改善したのか? 周波数は変えずにあるものを落とす
ASCII.jp / 2024年11月25日 12時0分
-
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分
-
Core Ultra 7 265K&RTX 4070 Ti SUPER搭載ゲーミングPC、空冷クーラーでも本当に大丈夫?
ASCII.jp / 2024年11月16日 10時0分
-
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月11日 12時0分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
ランキング
-
1ITジャーナリスト三上洋氏が解説!急増している迷惑電話、犯罪の手法と対策
ITライフハック / 2024年11月29日 9時0分
-
2NHKのネット受信契約(案)が“ダークパターン”過ぎて見過ごせない件(前編) NHKの見解は?
ITmedia NEWS / 2024年11月28日 19時9分
-
3「ミリ波対応スマホ」の値引き規制緩和で感じた疑問 スマホ購入の決め手にはならず?
ITmedia Mobile / 2024年11月28日 18時13分
-
4どうする? 大学生用パソコンの選び方 「4年通しよりも2年で買い替え」がオススメな理由
ITmedia NEWS / 2024年11月28日 13時26分
-
5えっ、プレステ2のゲーム高すぎ!? ここにきて中古ソフトが高騰している納得のワケ
マグミクス / 2024年11月28日 21時45分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





