

Rialto BridgeとLancaster Soundが開発中止へ インテル CPUロードマップ
ASCII.jp / 2023年3月13日 12時0分

今回はインテルの製品ロードマップから小ネタをいくつかご紹介したい。
Rialto BridgeとLancaster Soundが開発中止へ
3月3日、インテルのJeff McVeigh氏(CVP&暫定GM、AXG)が“Accelerating Customer Results with Accelerated Computing”なるプレスリリースを出しており、製品ロードマップの変更があったことを明らかにした。
ところで「あれ?」と思った方はおられないだろうか? AXGのGM(General Manager)はRaja Koduri氏だったはずだからだ。実は2022年12月にKoduri氏はAXGのGMから降格されている。現在の肩書はChief Architectである。もっとも、2022年12月まではSVP(Senior Vice President:上席副社長)だったのが現在はEVP(Executive Vice President:上級副社長)で、これだけ見るとポジションそのものはむしろ上がっている(SVPよりEVPが上)。
ちなみに今年1月27日に出た年次報告書によれば、現在インテルのEVPはMichelle Johnston Holthaus氏(GM, CCG)、April Miller Boise氏(Chief Legal Officer)、Sandra L. Rivera氏(GM, DCAI)、Christoph Schell氏(Chief Commercial Officer, Sales, Marketing, and Communications)、David Zinsner氏(CFO)の5人になっており、Koduri氏の名前がないあたりは、AXGのアーキテクトとして引き続き活躍してほしいものの、経営そのものからは外れるポジションに置くことでバランスを取りたかったのではないかという気がする。
ちなみにKoduri氏、2022年末に長いメンションを投稿しており、椎間板の膨張に起因する背中の痛みを解消するために入院して手術を行なっており、このあと3~4週間は動けなくなるとしていた。このあたりも、このポジション変更に関係していた可能性がある。
A long personal thread..hopefully useful for some you. The past 16 days I have learned more about discs than I ever planned to learn, but may be should have done sooner..Not computer discs, but the ones in my spine. But let me start at the beginning for some context.
— Raja Koduri (Bali Makaradhwaja) (@RajaXg) December 20, 2022
余談ながら2月のISSCCの会場には元気に姿を見せており、治療の予後は良かったようだ。
一方Jeff McVeigh氏はVP&GM, Super Computing Groupという立場で、AXGの中でIntel GPU Max(要するにPonte Vecchio)に携わってきていた方で、とりあえずKoduri氏の降格にともない、暫定的にAXG全体の面倒を見ている格好だ。
ということで本題。今回の話はそのMcVeigh氏の管轄下のデータセンターGPUの話である。McVeigh氏曰く「顧客の投資対効果を最大化することを目的として」データセンターGPUは2年周期で投入することにした、としている。
この結果として、Ponte Vecchioの後継に位置付けられ、よりコア数を増やしたRialto Bridgeに関しては開発を中断。Ponte Vecchioの後継は2025年投入のFalcon Shoresになることが発表された。
Rialto Bridgeは昨年5月のISCにおける基調講演で発表された製品で、Ponte Vecchioと同じプロセスノードで製造されているが、Xeコアの数を25%増加させたものあったが、1年経たずに消えることになった。


2025年投入予定のFalcon Shores
Rialto Bridgeに代わるFalcon Shoresであるが、こちらはx86コアとXeコアを1つのパッケージに載せた構成で、AMDのInstinct MI300や(アーキテクチャーはx86ではないが)NVIDIAのGrace Hopperなどと同じようなAPU(インテル用語ではXPU)である。

こちらも2022年5月のISCにおける基調講演ではもう少し詳細な説明が出てきている。基本的にはSapphire RapidsやPonte Vecchioと同じくマルチタイル構成であるのは間違いないが、ただわかるのはそこまでである。

ちなみに上の画像ではx86タイルとXeタイルが2つづつ、合計4タイル構成で示されているが、2月のInvestor Meetingの際には3タイル構成の図が示されている。おそらくどちらも適当に作った図、という感じがしなくもない。最終的にCPUとXeのタイルがどういう数になるかはまだまだわからない。
そのFalcon Shoresの概念図が下の画像であるが、普通に考えればこの内蔵メモリーとCPU/GPUの間はCache Coherencyがありそうに思えるのだが、実際どうなのだろう?
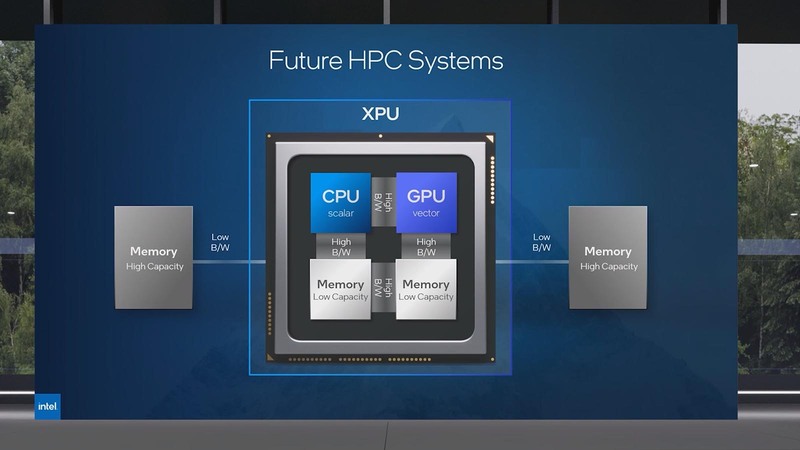
さらに言えば、タイル方式なのでCPU/GPUコア以外にカスタムタイルも構成可能としている。

それよりも問題は、2024年投入予定だったFalcon Shoresが、今回のプレスリリースではしれっと2025年投入に後退していることだろうか。そもそもPonte Vecchio(とSapphire Rapids)の投入が遅れたから、そのあおりを喰らって後ろにずれたのだろう。
同様に、次の製品投入が2年後になったのがFlexシリーズの製品。要するにデータセンターGPUとして投入されている製品だ。最初のFlexシリーズは2022年のIntel Visionで発表になっており、8月にFlex 140/170として製品発表された。
これが初代のArctic Soundベースの製品であったが、これに続く製品として2023年以降にLancaster Soundという製品が予定されていることが以前アナウンスされていた。もっともアナウンスされたのはコード名だけで具体的な構造などは不明なままであったが、先に出たRialto Bridge同様に製造プロセスは変えずにXeコアの数やエンコーダーの数を増やした程度だったと思われる。
ただこちらもキャンセルになり、これに続くMelville Soundに注力すると発表された。このMelville Soundはプレスリリースによれば「性能、機能、ワークロードの面で現世代から大きく飛躍する」ものになるそうで、プロセスの微細化によりコアの数やエンコーダーの数を大幅に増やした製品になるものと思われる。
Auroraは順調に遅延中
ところでこのプレスリリースの中には“Early Customer Adoption”という説があり、この中でAuroraが2万個のXeon MAXと6万個のGPU MAXを導入する予定だとした上で、しれっと「アルゴンヌ国立研究所は初期の利用者が2023年第3四半期にはシステム(=Aurora)にアクセスできるようになると予定している」と記している。
昨年11月のプレスリリースによれば、2022年中に128ノードから構成されるSunSpotと呼ばれる小規模システムを早期アクセス用にリリース、2023年1月からアルゴンヌ国立研究所を含む顧客にXeon MAX/GPU MAXを搭載したブレードの出荷を開始するとしていたが、実際にこれを採用したAuroraがいつ立ち上がるのかは明示されていなかった。
今回のリリースで、その立ち上げ時期が2023年7月以降になることがはっきりしたわけだ。ということは次のISC23(ハンブルグで今年5月21日より開催)には、まだフル構成のAuroraのデータはTOP500に入らない公算が高い。フル構成の数字がTOP500に入るのは、11月12日からデンバーで開催されるSC23になるのだろう。
ただ2023年11月と言うのは、ローレンス・リバモア国立研究所に導入されるEl Capitanもフル稼働している時期である。El Capitanの話は連載701回で説明したとおりで、当初の2023年初頭の導入からはやや後送りになっているが、おそらく今年11月のTOP500までには稼働を開始しているだろう。
ということで、2023年11月のTop500は、ハイエンドの座をAuroraとEl Capitanが競うことになるわけだが、筆者の予想としてはAuroraはかなり苦しそうに思える。理由は単純でノードの数である。インテルが明言しているようにAuroraは1万を超えるノードから構成される。一方でEl Capitanは連載701回でも説明したように3000ノードを下回ると予測される。
ピーク性能が同じだとすれば、ノード数が少ないほど実効性能が上がるわけで、この点でAuroraはかなり不利になる。消費電力での比較もさることながら、実効性能でAuroraがEl Capitanを上回るのはかなり厳しそうだ。
ところでそのAuroraの構成だが、先日もう少しだけ詳細を聞けたのでご紹介したい。まずラックであるが、Auroraブレードを格納した6本のラックごとに、熱交換器を収めたラックが2本入る。要するにAuroraブレードのラック3本毎に熱交換器のラックが一つ入る格好だ。

さて、下の画像はAuroraブレードのラックのアップだが、実は連載695回で書いた説明は間違い(CGが嘘)であって、実はラックは20×4段構成でAuroraのブレードを格納する。

うち16本がAuroraのブレードで、1ラックあたり64枚のAuroraのブレードが入る格好だ。では残りはなにか? という話だが、これは実は電源ユニットとのこと。こちらはAuroraのブレードの半分の高さで、16枚のAuroraブレードに対して8個の電源ユニットが搭載される。Auroraブレード2枚あたり1個という計算だ。電源ユニットも当然液冷だそうで、それもあってよく見ると電源ユニットにも冷却用のホースが来ているのがわかる。
なぜこれがわかったか? というと、今年2月のプレスリリースで、インテルはオレゴンのラボの中にBorealisと呼ばれるAuroraのテスト用システム(128ノードで、これはアルゴンヌ国立研究所のSunspotと同じ構成である)を稼働させていることを明らかにしたが、実は昨年このBorealisの見学ツアーに行けたからである。といっても写真撮影は厳禁だったため、情報としてお届けできることは少ないのだが。
ちなみにこのプレスリリースの中の動画を見ていると、レポーターのRob Kelton氏がイヤーマフを付けている(動画で2分13秒あたりから)のがわかるが、実際Borealisは壮絶にうるさかった。

この記事に関連するニュース
-
世界最速に躍り出たスパコンEl Capitanはどうやって性能を改善したのか? 周波数は変えずにあるものを落とす
ASCII.jp / 2024年11月25日 12時0分
-
スーパーマイクロ、スーパーコンピューティング2024にてHPCに最適化されたマルチノードシステムの最大規模のポートフォリオを発表
共同通信PRワイヤー / 2024年11月22日 9時44分
-
デル・テクノロジーズ、「Dell AI Factory」の拡張による先進的なポートフォリオで、エンタープライズ企業のAI導入を促進
PR TIMES / 2024年11月19日 16時15分
-
エクセルソフト、インテル・ソフト開発ツールの最新バージョン2025の販売を開始
週刊BCN+ / 2024年11月6日 15時19分
-
エクセルソフトは、HPC/AI アプリケーションの最適化および高速化、マルチアーキテクチャー・プログラミングを支援するインテル・ソフトウェア開発ツールの最新バージョン 2025 を販売開始
PR TIMES / 2024年11月6日 11時45分
ランキング
-
1クラファン始動から約12年、“いまだ未完成”なのに…約1,125億円超えの資金をユーザーから集めたゲーム
Game*Spark / 2024年11月29日 11時5分
-
2NHKのネット受信契約(案)が“ダークパターン”過ぎて見過ごせない件(前編) NHKの見解は?
ITmedia NEWS / 2024年11月28日 19時9分
-
3ITジャーナリスト三上洋氏が解説!急増している迷惑電話、犯罪の手法と対策
ITライフハック / 2024年11月29日 9時0分
-
4巨大エンタメ企業に潜んでいた“死角”――ソニーのKADOKAWA買収は外資牽制の一手になるか
ITmedia NEWS / 2024年11月29日 12時19分
-
5dカード PLATINUM、予想を上回る申し込みがありweb申し込みを一時停止
ポイ探ニュース / 2024年11月29日 15時53分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





