

Tenstorrentが日本支社を設立、自動運転の市場開拓が狙い AIプロセッサーの昨今
ASCII.jp / 2023年4月3日 12時0分

Tenstorrentは連載706回で取り上げたばかりなのだが、先日日本支社設立の記者説明会が開催され、その際にいくつか新しい情報が公開されたので、連載706回のアップデートという形で説明したい。
TensixコアはいずれもRISC-Vと判明
まずはAIプロセッサー周りに関して。連載599回で同社のTensixコアの説明を行ったが、この際のスライドでは、Compute Engineに加えて5つのRISCコアが搭載されているという話だった。この話そのものは別に変わらないのだが、今回明らかにされたのはこのRISCコアはいずれもRISC-Vとのこと。
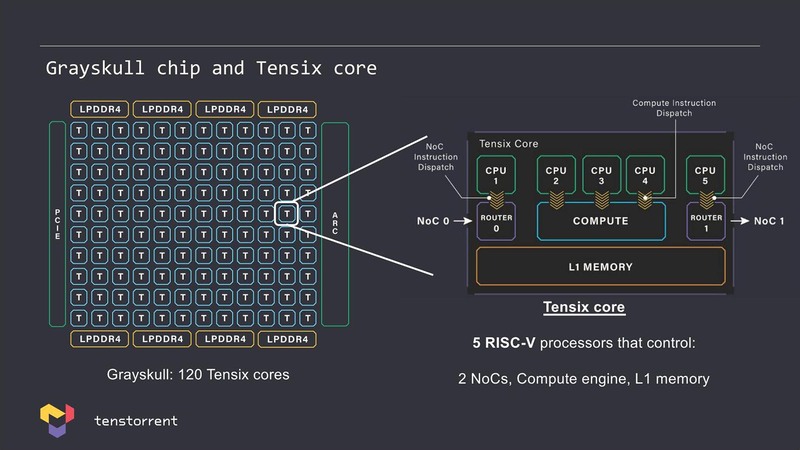
ただしこれはJim Keller氏が携わって湧いてきたAscalonコアとはまったく異なるものであるのは間違いない。というのはTensixコアそのものは2017~2018年にはもう設計が終わった段階であり、まだKeller氏が同社に参画する以前の話だからだ。
またAscalonコアはいずれもスーパースカラー/アウトオブオーダー構成(D2などは少し怪しいが)をベースにしているのに対し、上のスライドにあるようにTensixコアに内蔵されているのはシングルイシューでおそらくインオーダーなコアなのでまったく異なる。
RISC-Vを選んだ理由は比較的簡単に推定できる。まったく独自の命令セットでは、社内でのみの利用、つまりTensixコアの内部のプログラムはTenstorrentのみが扱えるように限定したとしても、それなりに開発ツールの移植などが必要である(後述のように、この前提も怪しい)。
RISC-Vコアならこのあたりがすでに存在するので、最低限の環境はすぐそろうことになる。またインオーダーのRISC-Vコアはすでに大量に存在し、しかも無償提供されているものも多く、少なくともAIプロセッサーを自前で開発しようとしている会社にとっては、スクラッチから作るのもそう難しくはない。逆にあえて他のアーキテクチャーを選ぶ方が変だろう。
次にロードマップ。一番最初のJawbridgeは試作品であって、製品としては推論向けのGrayskullと学習向けのWormholeがすでに完成、次いでWormholeの後継であるBlackholeが現在設計中という話は連載706回で説明したが、これに続いて2024年中に投入を予定している推論向けのQuasarと学習向けのGrendelという2つの製品を開発中であることが明らかにされた。

細かいスペックは上の画像に記載されているとおりで、ラフにまとめると下表になる。
Black HoleはWormhole比で3倍近い処理性能であるが、メモリー帯域は1.5倍程度でしかないので、Wormhole上で稼働していたネットワークをそのまま乗せ換えても性能がきちんと出ない可能性がある。
もっともWormholeは連載706回で説明したように、多数のチップを接続してシステムを構成するのが前提の製品であり(したがって上の画像にも“Networked ML Processor”とある)、一方Black Holeは単体動作(“Standalone ML Computer”)が前提なので、Wormholeで稼働するネットワークをそのまま乗せ換えることは考慮していないのだろう。
Quasarは推論向けではあるが、D2D(Die-to-Die)I/Fを装備しているというのは後述するチップレットビジネス向けのコンポーネントとして提供する気があるのは間違いない。ただスタンドアローンでGDDR6のI/FやPCIe I/Fも装備しており、これ1つ、あるいは2~4個のチップを乗せてPCIeカードとして出すことも考慮しているようだ。
そしてGrendelであるが、もうこちらは完全にチップレット構成であり、CPUチップレットとAIチップレット、それにメモリーI/Fや3次キャッシュのチップレットを組み合わせることが前提である。
実はこのGrendelという名称は、このチップレットを組み合わせた全体の名称ではなく、AIチップレットの名称なのかもしれない(これも後述する)。
ところでAIプロセッサーを扱うためのライブラリーだが、同社は上位のフレームワークだけでなく、一番下のTensixコアをそのまま触るためのベアメタルなライブラリーも提供する、としているのが特徴である。
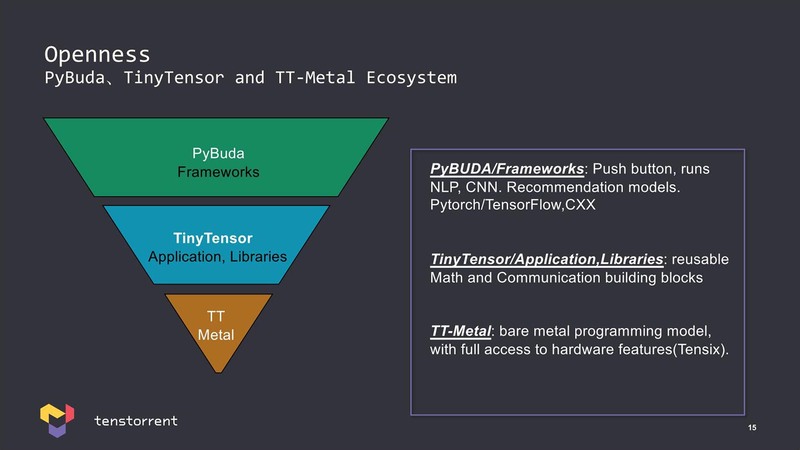
先にTensix内部のRISC-Vコアの話をしたが、実際にはTT-Metal経由でこのRISC-Vコアを触ることも可能なようで、そうなると自社開発のCompute Engineは仕方ないとしてもRISC-Vコアに関しては開発ツールがすでに存在するのは間違いなくメリットだろう。
PyBUDA/TinyTensorに関してはその上位のフレームワーク/APIとして提供されるとしている。それはともかく、TT-Metalを提供するということであれば当然Compute Engineの詳細も公開されないと使いようがないのだが、そうした情報がいまだに出てこないで、このあたりはNDA契約の元で開示されるのかもしれない。
SRAMベースのチップは 今後容量の点で厳しくなる
さてAIプロセッサーに関しての情報をもういくつか紹介しよう。Tenstorrentによる昨今のトレンドが下の画像だ。
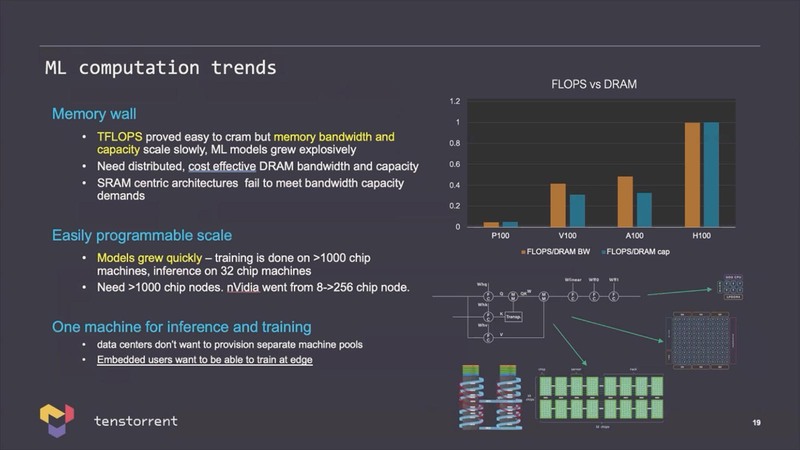
もちろん演算性能は重要だが、それを活かすには十分なメモリー帯域とメモリー容量が必要であるとし、SRAMベースのチップは今後メモリー容量の点で厳しくなるとしている。また今後はネットワークを動かすためには十分な規模が必要とある。
要するにCelebrasのようなプロセッサーはいずれ行き詰まるし、NVIDIAのソリューションもスケーラビリティに欠けるとするわけだ。このあたり、2016~2018年にTeslaに在籍したということは、Keller氏はFSDの開発だけでなく、NVIDIAのA100ベースのスーパーコンピューターの構築にも関わっていたわけで、その経験から出てきたメッセージな気はする。
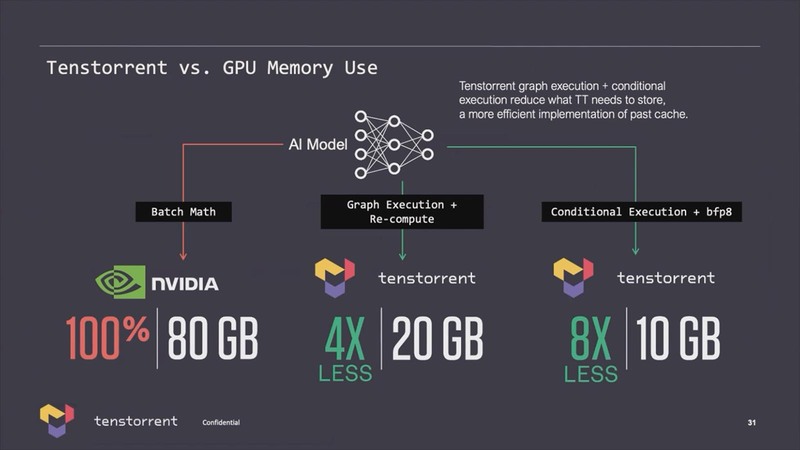
このうちメモリー容量に関するTenstorrentの説明が下の画像だ。同じモデルならNVIDIAの4分の1、さらにBFP8を併用すると8分の1までメモリー必要量を減らせるとしている。メモリー帯域はともかく、メモリー容量の問題に関してはこれでNVIDIAに比べるとだいぶ問題が緩和される、という説明であった。
ところでもう少し足元の話をすると、Wormholeを32個集積したNebulaという4Uサーバーが発表されていたが、今回この詳細が公開された。もっともこれはデータセンター向けではなく組み込み向けの一例であって、要はエッジで学習をしたいというニーズ向けと思われる。

日本支社設立の目的は 米国以外の新規市場開拓
さてここからはRISC-Vプロセッサー絡みの話である。まず日本支社設立の目的が下の画像だ。海外のRISC-Vプロセッサー企業の上陸は、筆者が知る限りCodasip、SiFiveに続きこれで3社目である。

加えて言えば、すでに国内にもRISC-VプロセッサーIPを手掛けている会社(NSITEXE、ArchiTekなど)もあるため、日本の状況を考えるとそろそろ多くなりすぎた感もある。ただそうした状況はTenstorrentもよく理解しているようで、いわゆるMCU向けのコアは「すでに競争相手が多いので」ということで手を出さず、代わりにAIプロセッサーと高性能のRISC-V IPを提供するというアプローチをとる。
日本法人のマネジメントチームは下の画像の3人である。といっても、Jim Keller氏は本社のCEOであり、David Bennett氏もCCO(Chief Customer Officer)ということで別に日本にかかりきりというわけでもなさそうで、実質的には中野守氏がトップということになる。

中野氏の前職はGraphcoreの日本のカントリーマネージャーで、昨年12月にTenstorrentに入社とのこと。ちなみにその前はクレイ・ジャパンの社長であった。Bennette氏は、今後増えるであろう海外支社を統括する立場になるのではないかと思われる。
会社設立のリリースは3月13日に出されているが、実はこの数日前にそのBennette氏が都内にいることをAMDの元兄貴がつぶやいていた。
近所散歩してたら、David に似た声だなと思ったら、本人だった(^^) 日本に居たのも知らなかったよ!@DavidBennett__pic.twitter.com/sE5d1QrpPK
— 土居憲太郎 (@Ken_Doi) March 5, 2023
てっきり会社設立にともなう作業のために来日したかと思ったのだが、説明会によれば会社そのものの設立は今年1月で、いろいろあって発表が2ヵ月遅れたとのことだったので、どこまで今回の説明会と関係あるのかは不明である。
Jim Keller氏お得意のRISC-Vで CPUだけでなくチップレットの提供を目論む
ここからはRISC-Vコアの話に移りたい。先に説明したようにTenstorrent自身はRISC-Vコアを当初から扱っていたが、少なくともそのRISC-Vコアそのものでビジネスするつもりはなかったようだ。
これが変わったのはやはりKeller氏の参加からだろう。まず最初にAscalonと呼ばれる8命令デコード/11命令発行のスーパースカラー/アウトオブオーダーのRISC-Vコアを設計をしている。
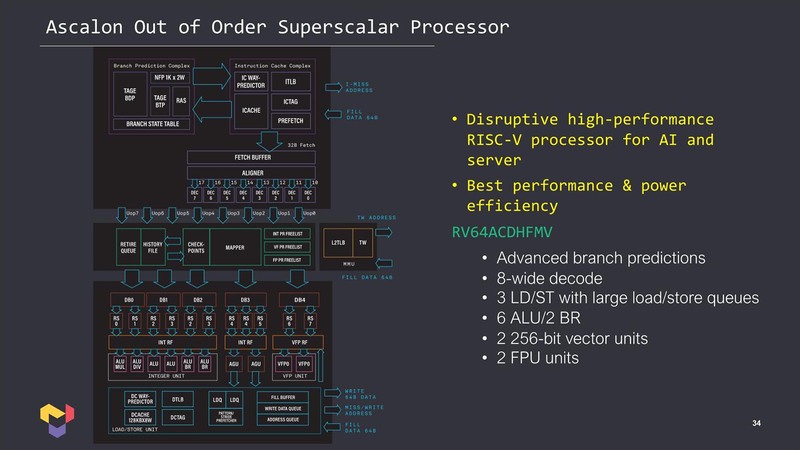
予想外だったのは、Tenstorrent(というよりKeller氏)はまずこのハイエンドコア(D6)を完成させ、次にこれのサブセットとして2/3/4/6命令デコードの派生型(D2~D5)を作ったという話だ。
普通は逆なのだろうが、すでにAMDやインテル、Teslaなどでこうした大規模なスーパースカラー/アウトオブオーダーのコアを作り慣れていたからこその技である。
このAscalongコアをまとめたクラスターや、それを組み合わせたチップレットという話はすでに報じたとおりだが、Tenstorrentは単にCPU IPを提供するのみならずチップレットの提供というビジネスも目論んでいる。
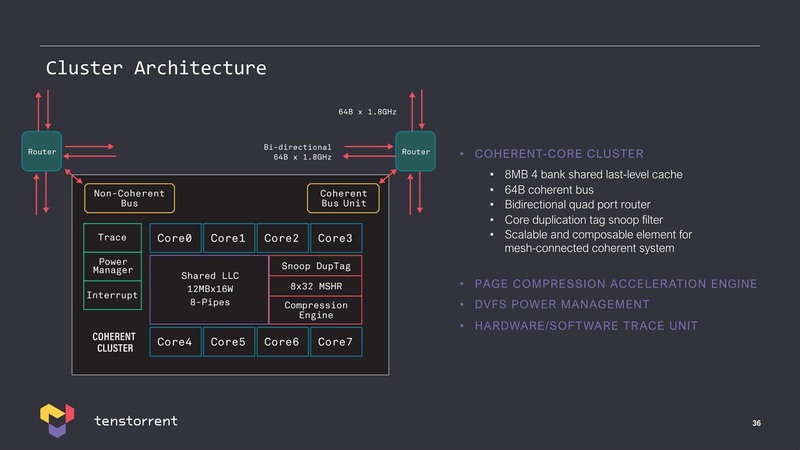
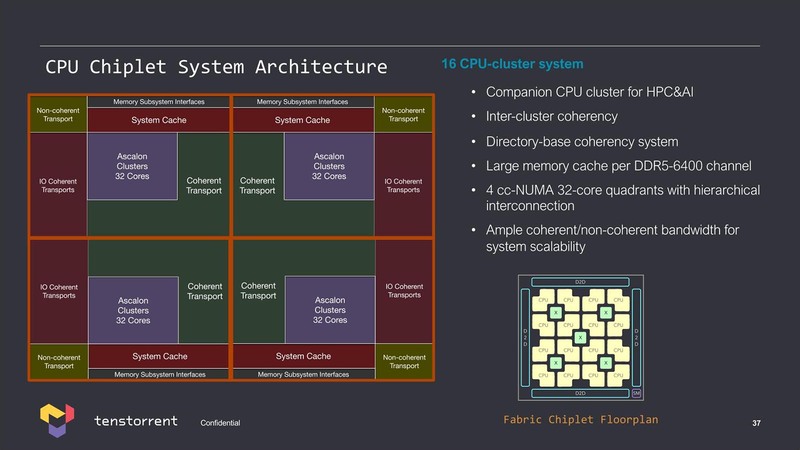

要するにビジネスとしては以下のことを考えているわけだ。
- CPU(RISC-V/AI) IPの提供
- CPU IPを使ったASICの設計支援
- CPU チップレットの提供
- チップレットを利用した独自チップの設計支援
実際、こうしたリソースを利用した商談は水面下で進んでいるが、特に後述する自動車向けではIPだけがほしいというところからチップレットの設計支援をしてほしいというところまで、さまざまなニーズが寄せられているそうだ。
Tenstorrent自身、こうしたチップレットを今後は積極的に採用していくつもりらしい。Aegisと名付けられたHPC向けの設計では128コアのAscalonにAI アクセラレーターと周辺チップからなる5つのチップレット構成であるが、さらに大規模なTunderbolt-XMというチップのアイディアも披露された。
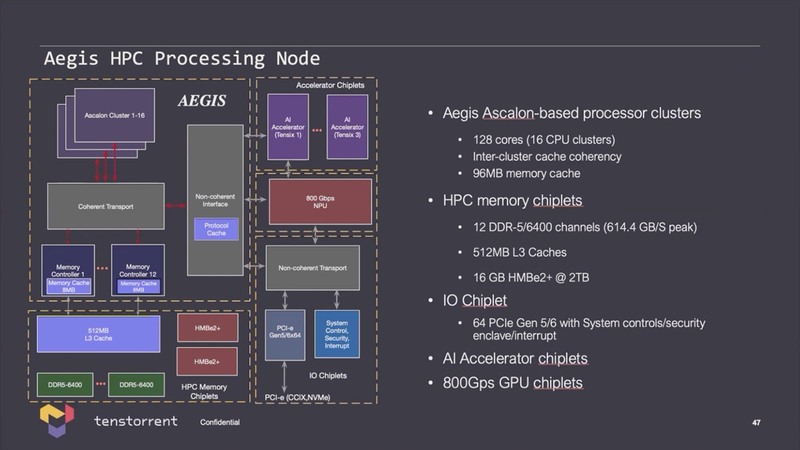
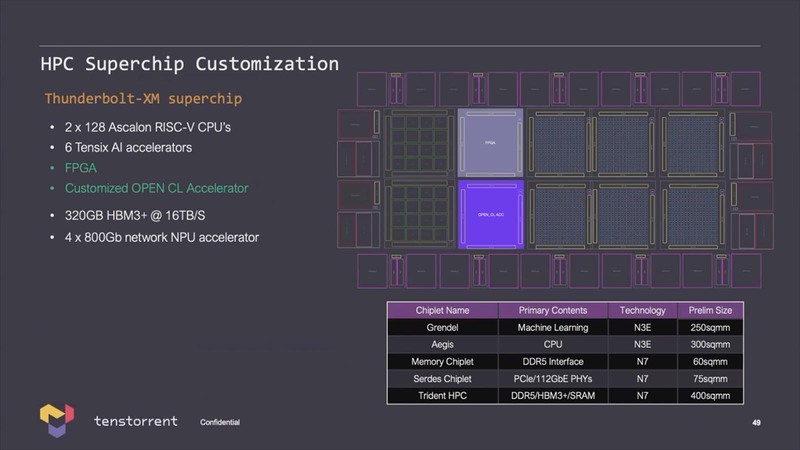
上の画像では各チップレットの詳細も示されており、Aegis(128コアのAscalonのチップレット)はTSMC N3Eで300mm2、Grendelは同じくN3Eで250mm2とされる。その一方PHYやSRAMは全部N7での製造になっており、特にDDR5とHBM3 I/Fに加えてL3 SRAMまで搭載したTrident HPCは400mm2とかなりの寸法である。
図で見ると、このTrident HPCを10個搭載することになってるが、さすがにこれはいろいろ無茶ではないか? という気がする。実現可能性はともかくとして、技術的にはこうしたものまで提案できるというのがTenstorrentのRISC-V/チップレットビジネスというわけだ。
自動運転のアルゴリズム構築に使うスパコンを 日本の自動車会社に売り込むのが真の狙い
最後に自動車向けについて。日本支社が設立された目的は、当然日系の自動車会社を取り込みたいというニーズがあるからだろう。ただそのアプローチは、他社と明確に異なっている。
下の画像で示すTenstorrentの自動車市場を見ると、中央と右はよく見るが、左はかなり目新しい。
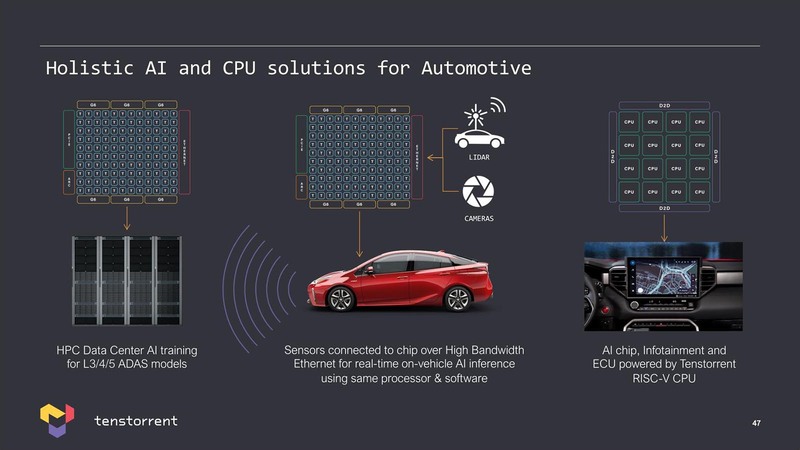
特にレベル3以上の自動運転を狙う場合、今後はコネクテッドカーの形でないと難しくなっていくと考えるのも無理はない。
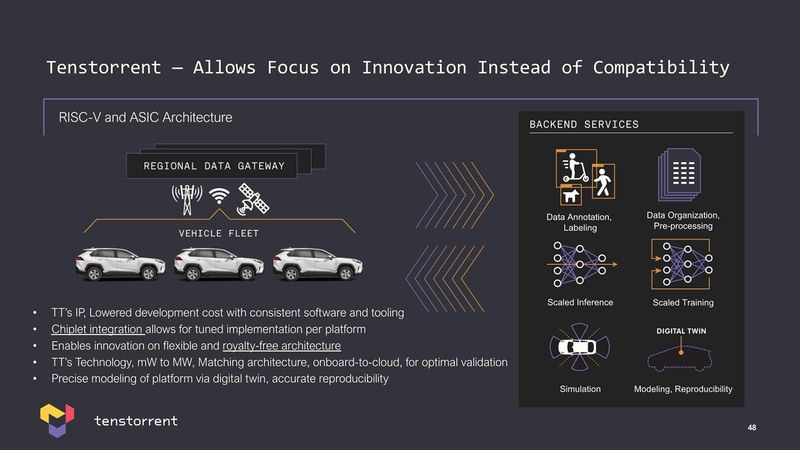
連載709回でも説明したが、Teslaは自動運転のアルゴリズム構築のためにDojoスーパーコンピューターを自社で開発した。ただこれはTeslaだからできる技であって、普通の自動車メーカーは自社でAIスーパーコンピューターを構築できるような技術力はない。
ならそうしたニーズはないのか? というとそんなわけもなく、遠からず自車の運行データをネットワーク経由で吸い上げ、そのデータを元にアルゴリズムを迅速に改良していくというTeslaと同じような仕組みが求められるのは間違いない。
そうしたニーズが必要になる顧客、つまり自動車会社やティア1(自動車会社に直接部品などを納入する請負業者)に対して、Teslaでそうしたシステムを構築した責任者が(Dojoに負けないような)代替解決案を提供できます、というのはビジネス的に非常に説得力があるし、市場も期待できる。なるほど、真っ先に日本に海外支社を立ち上げたわけである。
ちなみにすでにこうした目的に向けたPoC用の開発ボードが存在するそうだ。説明によれば、現時点ではホストとしてTiger Lakeが搭載されているが、これはPoC向けだからという話で、仮に製品化が進行するとしたらRISC-V CPUとNebulaを一体化したチップになるだろうとのことだった。


この記事に関連するニュース
-
Intel Tech Talkで見えたLunar Lakeにおける低消費電力と高性能の両立へのこだわり
マイナビニュース / 2024年6月27日 6時45分
-
インテルが「Lunar Lake」のチップ実物を披露 実は現行「Core Ultra」の直接後継ではない その理由は?
ITmedia PC USER / 2024年6月26日 20時55分
-
TOPPAN、単体での電気検査が可能なコアレス有機インターポーザを開発
マイナビニュース / 2024年6月18日 16時36分
-
【Gaudiシリーズを解説】生成AIに対し、広がる選択肢―Fugaku-LLMも快適に動作
マイナビニュース / 2024年6月18日 11時0分
-
TSMCの3nm生産能力の大半を主要顧客が確保、2026年まで受注継続 台湾メディア報道
マイナビニュース / 2024年6月13日 9時49分
ランキング
-
1清春、27年前にブチギレた“因縁の大物芸人”と対峙 トガっていた時期に頭たたかれ“殺しのリスト”入りへ「テレビナメるな」「パーンって」
ねとらぼ / 2024年7月5日 16時5分
-
2ランサムウェア被害、報告続出 イセトーサイバー攻撃で今わかっていること(7月5日時点)
ASCII.jp / 2024年7月5日 15時45分
-
3「コレのせいやったんか」 最近スマホが重い → “とんでもない理由”が判明……!? 「自分もやってた」「4年以上経ちました」と猛者たち集結
ねとらぼ / 2024年7月5日 16時0分
-
4「Pixel 6」シリーズに不具合、最新アプデ→初期化でトラブル発生 Googleが回避策を案内
ITmedia NEWS / 2024年7月5日 8時20分
-
5VTuber・犬山たまき所属事務所、誹謗中傷した人物との間で和解成立―当初「示談金の支払などは行わない」と回答するも訴訟提起で一転
インサイド / 2024年7月5日 16時55分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください







