

性能ではなく効率を上げる方向に舵を切ったTensilica AI Platform AIプロセッサーの昨今
ASCII.jp / 2023年5月29日 12時0分

連載717回でSynopsysを取り上げたので、片割れであるCadenceを取り上げないのは片手落ちだろう。ということで今回はCadenceが提供するTensilica AI Platformを紹介したい。

命令セットを自由に組み替えられる 自由度の高いプロセッサー「Xtensa」
Tensilicaは1997年にサンノゼで創業された。創業者はChris Rowen博士であるが、Rowen博士はMIPS Computer Systemsの創業者の1人でもあり、SGIによる同社の買収後はしばらくSGIに在籍するものの、その後Synopsysに転職。そして1年で辞めて立ち上げたのがTensilicaである。
そもそもRowen博士はMIPS Computerを立ち上げたくらいなので32bit汎用RISCプロセッサーの特徴や長所短所はよく理解している。そしてSynopsysでIPというビジネスを学んだことで、独特のアーキテクチャーを持つプロセッサーをIP売りする、というビジネスを思いつき、これを実現するために立ち上げたのがTensilicaというわけだ。
そのTensilicaの最初のプロセッサーであるXtensaの特徴はASIP(Application-Specific Instruction set Processors)である。要するにアプリケーションの要件に合わせて命令セットを自由に組み替えられるというものだ。
Xtensaは「強いて言えば」VLIW+Vectorの構造になる(厳密にはRISC的な要素もあるのだが、無理に分類すればVLIW+Vectorにならざるをえない)が、その命令セットどころか命令長まで自由であり、同じXtensaでも、それこそASICごとに命令セットにはまったく互換性がない。
ちなみにXtensaはCPUだけでなくDSP(Digital Signal Processor)も利用可能で、どちらか(あるいは両方)を使うか否かも自由に選択できる。それもあってデザイン手法も独特だ。
一番無難な方法は、Xtensa Processor Generatorと呼ばれているツールを使って命令セットや構成を設計し、ここからプロセッサーのIPを生成するとともに、そのプロセッサーIPをサポートするソフトウェアを自動作成するというものだ。
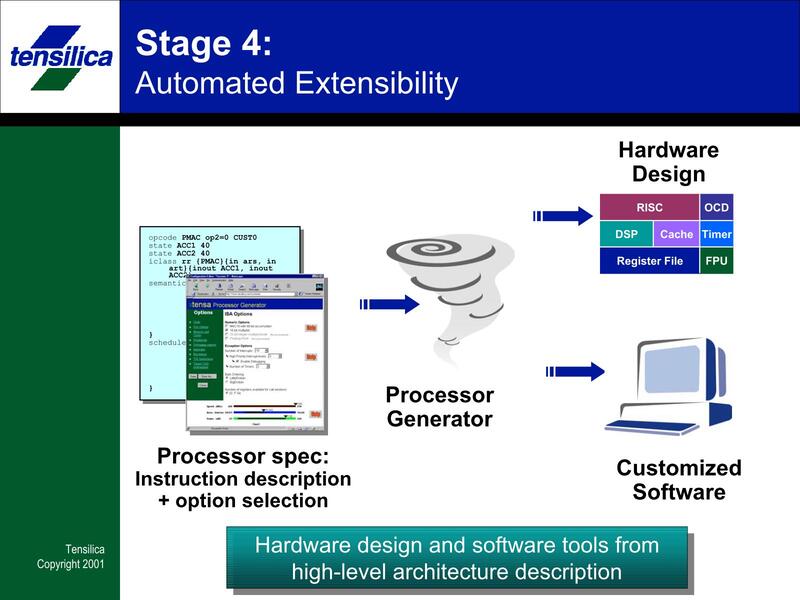
なぜいきなりStage 4か? というと、Stage 1はありもののCPUを使う、Stage 2はARMなどのIPのライセンスを受けてそのまま使う、Stage 3はセミカスタムのIPを使うというものがあり、その次に来るものだからという話である。ちなみにStage 3で例に挙げられていたのがARC InternationalのARCtangentであるあたり、お互いを強く意識し合っていたのがわかる。
Tensilicaはさらにそこから一歩進んで、アプリケーションプログラムからそれに合わせたアーキテクチャーを生成するというオプションまで提供していた。
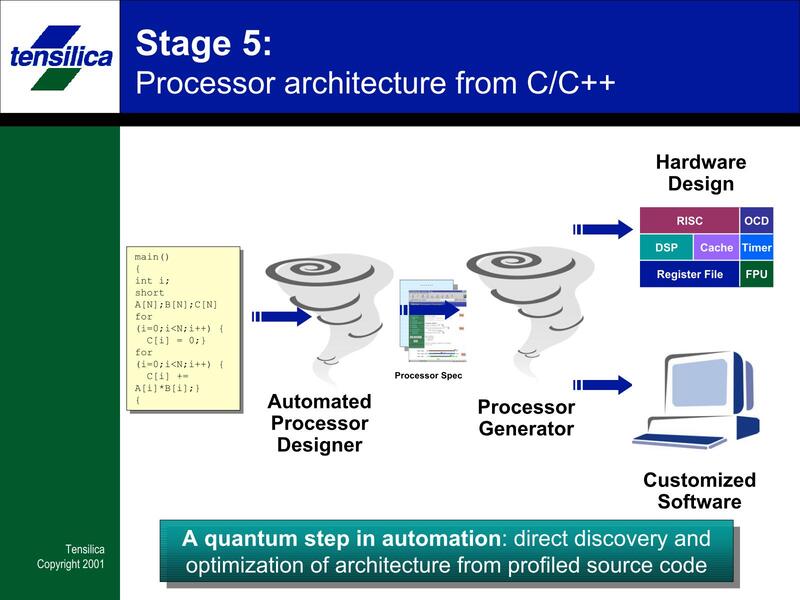
下の画像は2000年頃にあったTensilicaの日本語カタログ(当時は横浜に日本オフィスも構えていた)からの抜粋だが、かなり好きなように内部構成を変更できる仕組みなのがわかる。
ちなみに上の画像の構成をサポートして実際に稼働させられるXT-1000というボードも当時発売されていた。これは主に評価用で、まだ当時のことなのでXilinx/Alteraともに大容量のFPGAはラインナップしておらず、それもあってXT-1000はAlteraのCPLDを2つ搭載し、ここにXtensaを載せて稼働させる形だった。
意外なところで使われている Xtensa LXシリーズ
この後Tensilicaは次々に新製品というか新IP(?)を発表していく。2000年にはXtensa III、2001年にXtensa IV、2002年にXtensa V、2004年には第6世代のXtensa LXを発表している。
このXtensa LXの延長で、現在でもXtensa LX7が発売されているし、そのXtensa LXシリーズをより高性能の方に振ったXtensa NXシリーズもある。
少し話が横道に逸れるが、このXtensa LXシリーズは意外なところで使われていたりする。例えばローレンス・バークレー国立研究所のNERSC(National Energy Research Scientific Computing Center)といえばPerlmutterを導入したサイトで、連載510回、連載608回、連載617回でその名前を紹介しているが、そのNERSCが2008年頃から行なっていたものにGreen Flash Projectという取り組みがある。
これはHPCシステムをいかに効率的に実装・運用するかを研究するもので、2009年3月には最初のプロトタイプが稼働したが、このシステムはVILW CPUを32コア集積したチップにDRAMを組み合わせ、これを32個集積したボードをラック当たり32枚実装、100ラック程度で10PFlopsの演算性能を実現するというものだ。
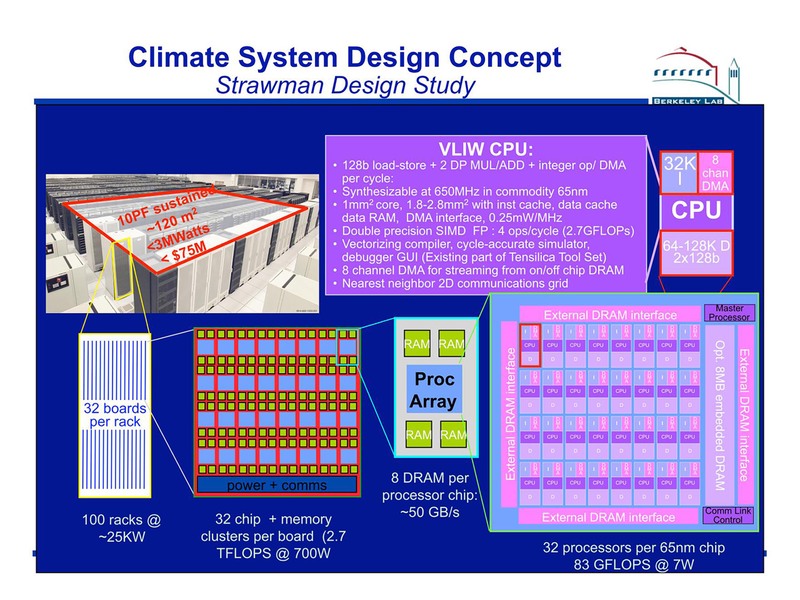
このVLIW CPUというのがまさにXtensaであって、チップ1個で83GFlopsを消費電力7Wで達成している。2009年と言えば、NVIDIAならまだ40nmプロセスで製造されるFermi世代に相当し、単体性能が一番高かったM2090が40nmプロセスで666GFlops/250Wで、効率は2.67GFlops/W程度。7Wで83GFlops(=11.86GFlops/W)を65nmプロセスで実現してしまったXtensaの効率がいかに高かったかがわかる。
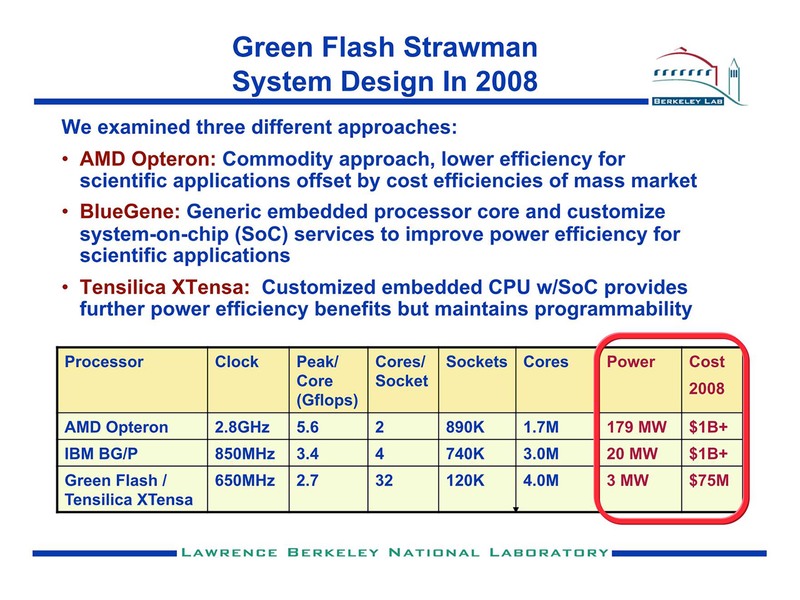
ちなみにNERSCにおける分析が下の画像だ。BlueGene/P(と比較してもはるかに効率が良いシステムを、しかもさらにお安く実装できることをこのプロジェクトでは実証して見せた格好だ。そしてその核がXtensaだったというわけだ。
話を元に戻そう。XtensaはCPUであり、複雑な分岐を含む処理を高速に行なえることを特徴とするが、信号処理などの分野に関して言えば別にそこまで複雑な分岐などは発生しないし、繰り返し処理がメインになるため、CPUコアの性能はそう必要なく、むしろDSP(Digital Signal Processor)コアを強化することが好ましい。こうした用途に向けてDSPソリューションも提供し始める。
といっても、実際はXtensa LXコアにDSPという構成は変わらないのだが、DSPユニットを強化した構成である。2009年頃の製品ポートフォリオで言えば、オーディオ向けにHiFi Audio Engine(Dual 24bit MACを搭載したDSPとXtensa LX2を組み合わせたもの)や388VDOというビデオエンコード/デコードプロセッサー、超高速汎用DSPであるDiamond 545CK(3-issue VLIW DSPに8-way SIMDを組み合わせた物)などがラインナップされるようになった。
もちろんもう少し下のグレードの製品も多数用意されている。ちなみにDiamondシリーズというのはCPUというよりMCUを志向した、省電力コントローラー向けIPである。

そんなTensilicaであるが、2013年にCadenceに買収される。このあたりの経緯はSynopsysに買収されたARC Internationalと大して変わらない。違いがあるとすれば、ARC InternationalはVirage Logicに買収され、それがさらにSynopsysに買収された形だが、TensilicaはCadenceに直接買収されたということくらいだろうか。
Cadence傘下になった後も、引き続きTensilicaブランドでCPU/DSP IPの提供はされており、いろいろなところで利用されている。有名なところでは、AMDのRadeon R9/R7シリーズから搭載されたTrueAudioという技術があるが、これはTensilicaのHiFi 2 EPというDSPをベースに構築されたものである。
AI向けに最適化したDNA Scalable Processor
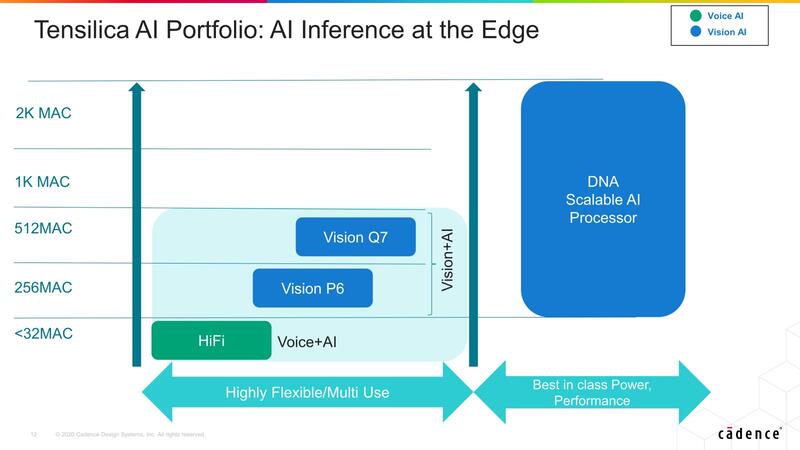
ということで話をAIプロセッサーに移す。AI市場の盛り上がりに合わせて、当然TensilicaもAI向けの対応を始める。といっても当初畳み込みニューラルネットワークが映像処理(セグメンテーションやクラシフィケーションなど)で立ち上がったこともあり、まずは同社のVision Q6という映像処理向けのDSP上でニューラルネットワークを稼働させるためのフレームワークを提供するに留まっている。

2019年にはTensilica DNA 100 Processor(数百個のDSPコアをSoC内に搭載できるというコンセプトのもの)を発表しているが、DSPコアそのものは従来のままで、まだAIに最適化されたというものではなかった。このあたりのソリューションが用意できたのは2020年である。
DNA Scalable Processorと呼ばれる新IPは、DSPをベースとしつつもAI向けに最適化した構造を取るものである。
中核になるのはXNNE(Xtensa Neural Network Engine)で、MACユニットそのものはVision DSPなどと似ている(完全に同じではなく、AI向けのデータ型のサポートなどが追加されている)が、これにSparsityへの対応を行ったScalable Sparse Compute Engineや、量子化専用ユニットの追加(DSPでも同じことはできるが、それだけ演算性能を食うことになるので、専用ユニットにすることで効率を上げている)などを実装したものだ。
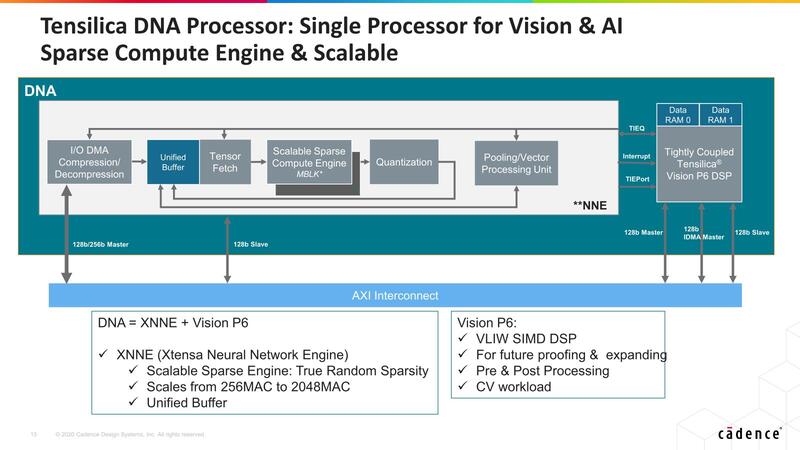
基本はDSPをブン回して性能を上げるという方向での実装であり、データフローの実装やIn-Memory Computing的な実装は同社の得意とするところではない。
ただScalable Sparse Compute Engineでデータが疎の部分の演算は自動的にパスできるからデータフローに近い効率を実現できるし、Unified BufferをMACユニットに近いところに置くことで、外部のメモリーアクセスの頻度を減らすことで本当のIn-Memory Computingに比べればまだ帯域的には低いであろうものの、かなり効率的に演算を実施できるように配慮したことがうかがえる。
性能としては、この時点でもNVIDIAのXavierと比較して2.4倍の効率を達成したとしており、手始めとしては悪くない数字である。
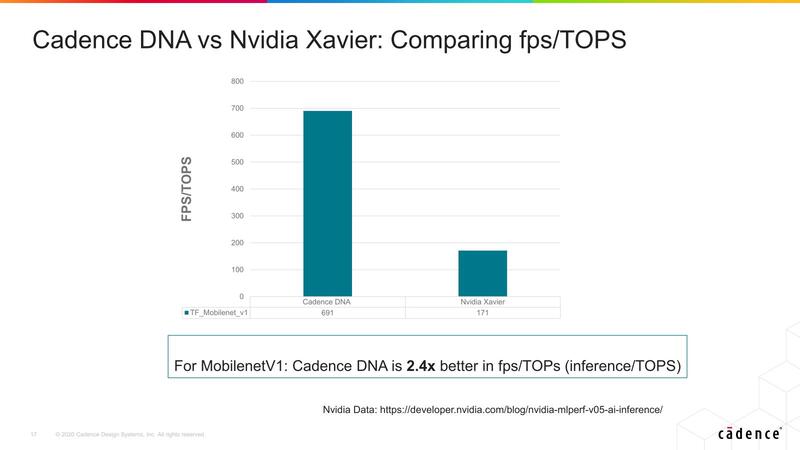
もっとも、「既に販売しているプロセッサー」に比べて、IPで提供されるプロセッサーの効率が数倍では商売にならない。そのIPを購入して新しいチップを自分で作るとなると数年の期間が必要であり、その間により性能を上げたプロセッサーが市販されるであろうことは明白だからだ。
ただTensilicaはここで性能を上げる方向ではなく、効率を上げる方向に舵を切った。2021年に発表されたのが、現在も提供されるNNA110である。
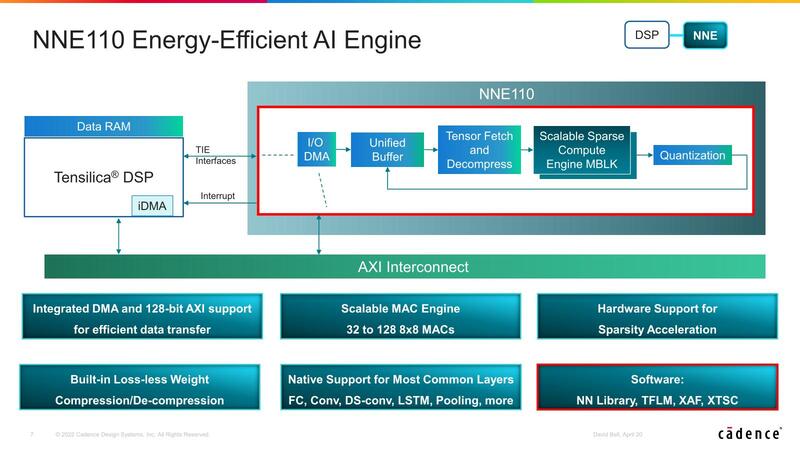
構成そのものはNNEそのものであるが、MAC数は32~128と、3つ前の画像で示した256~2048から大幅減となっており、またPooling/Vector Processing Unitが省かれているのがわかる。PoolingはおそらくTensilica DSPの側で処理であり、またVector Processing Unitはその必要がないと判断されたためだろう。
どうしてか? というと、TensilicaはAIの用途を“Always On Processing”向けに割り切ったためだ。

同社はすでにVision DSPやAudio DSPを幅広く展開して供給しており、それこそ画面付きのスマートスピーカーなどに広範に採用されている。こうしたすでにあるアプリケーションに、今回のNNA110を追加するだけで、性能を向上させつつ大幅に消費電力を減らせる)というわけだ。
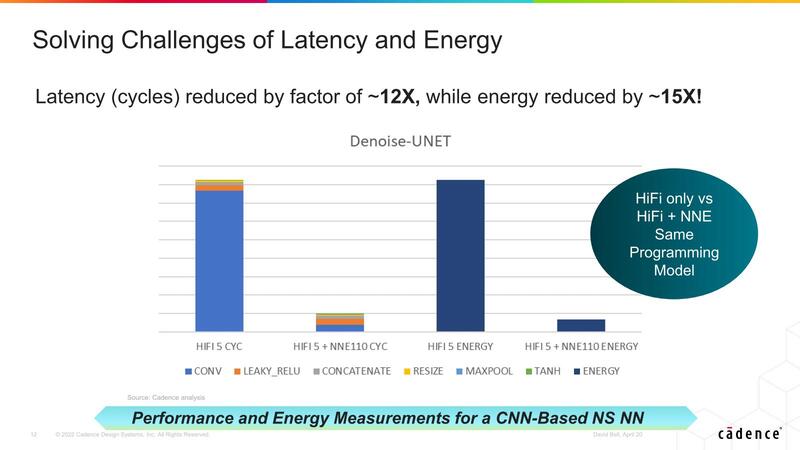
ユーザーとしても、すでにTensilicaのIPを使ってアプリケーションを構築しているのであれば、そこにNNA110を追加するのはそう難しくない。いわば抱き合わせ商法を狙って展開されているのがNNA110というわけだ。Tensilicaのユーザーは多いので、そうしたユーザーを狙っての商売だけに、確実に市場が狙えそうではある。なかなか賢いビジネスだと思う。

この記事に関連するニュース
-
世界最速に躍り出たスパコンEl Capitanはどうやって性能を改善したのか? 周波数は変えずにあるものを落とす
ASCII.jp / 2024年11月25日 12時0分
-
MIPSが業界初となる高性能のAI対応RISC-V車載用CPUのP8700を発表し、ADASおよび自動運転車向けに提供
Digital PR Platform / 2024年11月22日 17時27分
-
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
-
「Snapdragon 8 Elite」は何が進化したのか PC向けだったCPUコア「Oryon」採用のインパクト
ITmedia Mobile / 2024年10月28日 16時15分
ランキング
-
1「見た瞬間笑った」 共通テスト模試のリスニング問題 → “衝撃的なファッション”のイラストに思わず三度見 「肩ww」
ねとらぼ / 2024年11月26日 11時50分
-
2日本に1店舗のみの“完璧なマクドナルド”が778万表示の話題 地元民も「そんなすごい店やったんか…」「たまに使ってるけどそんなすげぇとこだったのね」
ねとらぼ / 2024年11月26日 7時40分
-
3スマホ料金「最激戦区の30GBプラン」を比較 ahamoショックにUQ mobileやY!mobileも追随でどこがお得に?
ITmedia Mobile / 2024年11月26日 6時5分
-
4Windows 11 2024 Updateの目玉機能「リコール」って何? 実際に試して分かったポイントを解説
ITmedia PC USER / 2024年11月26日 12時5分
-
5おばあちゃんに今日のコーデをLINEで送ったら…… 思わず涙する“返信”に「もうだめだった……こんなん泣くやん」「尊すぎる」200万表示
ねとらぼ / 2024年11月26日 10時30分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





