

Auroraの性能は実質2EFlopsで消費電力は4500W インテル CPUロードマップ
ASCII.jp / 2023年6月12日 12時0分

2023年5月21日~25日にハンブルグでISC 23が開催され、ここでTOP500リストが更新されたが、引き続きAMD/HPEのFrontierが最高速の座を維持しており、Auroraはエントリーすらせず。

もっともこれは連載710回でも説明した通りで、本格稼働は今年7月以降になるとされているのである意味予定通りである。
説明によれば、「現在プロセッサーを交換している最中」だそうで、どうもとりあえずはXeon MaxではなくただのXeon Scalableの、それも製品版ではなくPRQ/PV版かなにかを装着した形で納入。そこで最低限の動作検証などを行ない、現在Xeon Maxに置き換えているのではないかと思われる。
ちなみにTOP500における説明会では、75%ほどの置き換えが完了していたそうで、これが完了するのに6月いっぱいはかかると思われる。
ということで、AuroraはTop500にはエントリーしていないのだが、ISC 23に合わせてインテルのJeff McVeigh氏が説明会を開き、ここでAuroraの動向や今後の製品アップデートなどをいろいろ説明した。ここからいくつかかいつまんで説明したい。
Auroraの性能は実質2 EFlops 消費電力は4500W
やっと、という感じではあるがAuroraの正式な構成が発表された。10624ノードで、1ノードあたり2 Xeon Max+6 GPU Maxなので、Xeon Maxは2万1248個、GPU Maxは6万3744個という構成になる。

以前連載710回で説明したように、Auroraでは1本のラックに64ノードが収まる格好だから、ラックの数は166本に達する。
ところでこのXeon MaxとGPU MaxがそれぞれどのSKUかは現時点では未公開であるが、仮にXeon MaxはハイエンドのXeon Max 9480、GPU Maxの方もハイエンドのGPU Max 1550だと想定した上でFP64の演算性能を計算してみよう。
Xeon Max 9480は動作周波数が1.90GHz、最大が3.50GHzであり、56コアでAVX512をフルに動かした場合は下表になる。
同様にGPU Max 1550も動作周波数が900MHz、最大1600MHzとなっており、128 Xe CoreのVector Engine(トータル1024基)をフルに動かすと下表になる。
この結果、ノードあたりの演算性能は以下のとおり。
これが10624ノードなので、システム全体での演算性能は下表になる。
データセンター向けに長期間連続稼働するという動作条件では、正直Max Boostの3.5GHzやMax Dynamicの1.6GHzでXeon MAXやGPU MAXが稼働することは考えづらい。実際にはBase Frequencyにかなり近いところで、ただそれよりも多少上かもという程度に考えておくのが無難であり、その意味では実質2 EFlopsの構成と考えるのが妥当だろう。
ただピークでは3.4 EFlopsを超えており、その意味ではFrontierはおろかEl Capitanをも上回る性能が(瞬間的には)可能かもしれない。
一方で消費電力は、Xeon Maxが350W、GPU Maxが600Wなので、1ノードあたりの消費電力は4300Wに達する。実際にはこれに加えて周辺回路(ネットワークその他)などもあるため、ラフに4500Wとしておいた方が無難だろうか。
連載710回で、Auroraのラックは1本あたりブレード80枚が装着可能で、うち64枚がAuroraブレード(というよりノード)で、残り16枚分のスペースに合計32個の電源ユニットが装着されているという話をしたが、下の写真からわかるように1つの電源ユニットあたり15KWの供給が可能である。

1つの電源ユニットから2枚のAuroraブレードに電源を供給するので、定格的には9KW出力で足りるように思えるのだが、それでは負荷変動などに耐えられないことを想定したのだろうか? 実際には定格を多少超えて運用しても大丈夫、という設計なのだろう。
ただノードあたり4500Wだとしても47.8MW。仮にこの電源の最大供給電力である15KWがフルに稼働するとすると、システム全体では80MWもの消費電力を必要とする。ちなみにこの数字にはSlingshotを使ったDragonfly Networkの分や冷却システムの消費電力、それとストレージ類などは一切考慮しておらず、これを加味すると定格でも60MWコース、フルに動かすと100MW近い消費電力になる計算である。
もちろん実際には定格稼働で47.8MWも消費しない可能性もあるので、もう少し下がるとは思いたいが、それでもノードだけで40MWを切れるかはかなり微妙に思える。システム全体での消費電力を60MWに抑えられ、しかも性能を実効で3 EFlopsまで高められればFrontierやEl Capitanに十分対抗できる計算になるのだが。
なお、最新のTop 500ではFrontierが若干性能を改善しており、1.194 EFlops/22.703MWということで、効率的にも1.052 EFlops/20MWほど。初回(1.102 EFlops/21.1MW≒1.045 EFlops/20MW)と若干改善している。次のEl Capitanは当然より高い効率を実現すると考えられるわけで、なかなかハードルは高そうだ。とりあえず実効性能でEl Capitanを上回れるのか、が次の焦点となるだろう。
AuroraはMCR-DIMMを採用 ADATAが早くもサンプルを展示
実はMcVeigh氏の説明、Auroraの構成などは最後であり、まずは同社のサーバー製品ロードマップやAI製品のロードマップなどだったのだが、その途中でさらっととんでもない話が出てきた。それが下の画像である。

この話はインテルが初めてではない。今年3月にシリコンバレーにあるCHM(Computer History Museum)で開催されたMemCon 2023において、現在複数の企業によりMR-DIMM(Multi-Rank DIMM)の仕様策定作業が行なわれており、JEDECに標準化規格として提案されていること、およびそのMR-DIMMにAMDも賛同していることがAMDのRobert Hormuth氏(CVP, Architecture and Strategy, Data Center Solutions Group)によりLinkedInに投稿されていた。
もともとAMDはHB-DIMMという名前で同種の技術を開発しており、これをJEDECに標準化案として提案するにあたり、MR-DIMMに改称したらしい。そして5月にインテルがMCR(Multiplexing Combined Rank) DIMMとしてこれをGranite Rapids世代で正式にサポートすると表明するとともに、こちらもJEDECでの標準化に向けて活動しているとしており、DDR6が出てくるまでの中継ぎとしてMR-DIMMが少なくともサーバー向けには広く利用されそうな雰囲気になってきた。
MR-DIMMの基本的なアイディアは、ランクの多重化である。もともとDIMMの内部の管理単位にランクは広く使われていた。片面実装のDIMMでは1ランク、両面なら2ランク、というケースでは、表面のDIMMと裏面のDIMMでは別々のランクが割り振られており、どちらか片方(指定された側のRank)のみがアクセスされるといった形で利用されていた。ちなみにサーバー向けの大容量のDIMMでは、4ランクや8ランクのものも存在していた。
これを利用するにあたり、例えば連続読み出しであれば通常は下図のようにまずRank #0へのアクセスを行い、次いでRank #1にアクセスを行い、再びRank #0のアクセスを、という具合に交互にアクセスすることになる。
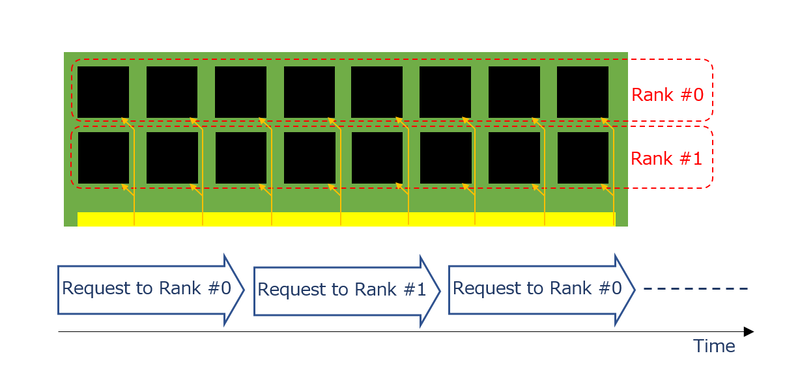
データバスそのものはRank #0とRank #1で共通であり、どのRank #をアクセスするか? という制御線でRank #0とRank #1を切り替える格好だった。
これに対してMR-DIMMでは、まずDIMMの上にバッファが乗り、ホストからのデータバスはすべて一旦このバッファで受けたあとで、Rank #0向けとRank #1向けが別々に配線される形となる。そしてデータバスには、Rank #0とRank #1へのリクエスト(とその返答)が同時に載る形になる。
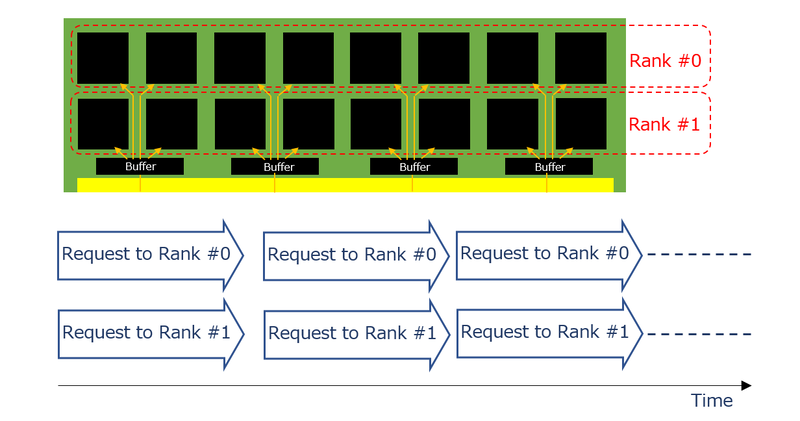
要するにホストとバッファの間は信号速度を倍速とし、バッファと個々のDRAMの間は既存のDDR5の速度とする、という方式だ。これにより以下のことが実現できる。
- 既存のプラットフォームを変更せず、また新たなDRAMチップを開発することなく帯域を倍増できる。
- DIMMあたりの容量を倍増できる。
おそらくはこのMR-DIMMをサポートするプラットフォームでは、1 DIMM/chに制限されることになるだろう。ただすでにAMDのGenoaでは、2ソケットのプラットフォームは1 DIMM/chになっている(現実問題として2 DIMM/chにすると、DIMMスロットの面積が大きくなりすぎてシャーシに収まらない)し、インテルのGranite Rapids世代でDDR5 12chになる模様なので、やはり現実問題として1 DIMM/ch構成になるだろう。それに、MR-DIMMでは容量を倍増できるから、1 DIMM/chでも容量が少なくなることはない。
なぜ倍増させる必要があるかと言えば、現状AMDのGenoaは96コアとDDR5 12chという構成であり、次世代のTurinではおそらくさらにコア数が増える。となると、コアあたりのメモリー帯域を維持するためにはメモリー帯域を引き上げる必要があり、しかもDDR6を待っていられない。
これはインテルも同じで、Granite Rapids世代は最大132コアとされており、Sapphire Rapidsから倍増しているにも関わらず、メモリー帯域はDDR5 8ch→12chで1.5倍にしかなっておらず、現状ですでに帯域不足である。これを補うために帯域をより増やしたいし、DDR6を待ってられないと思うのは当然だろう。
ちなみにこのMR-DIMM、8800MT/秒なのは第1世代で、続いて12800MT/秒の第2世代、17600MT/秒の第3世代も想定されている。この第3世代は2030年台に投入予定で、さすがにこうなるとDDR6と被らないかやや心配になるところだ。
第2世代はDDR5-6400の倍速、第3世代はDDR5-4400の4倍速(つまりRank #0~#3までの同時アクセス)になるだろう。
さてこれがとんでもないのは、今年のCOMPUTEXでADATAがこのMR-DIMMのサンプルを展示したことだ。


発表こそ今年の5月だが、水面下で開発は進んでおり、もうDIMMベンダーがサンプルを展示するほど完成度が高い、ということの裏返しである。
当然AMDも次のTurinでこのMR-DIMMのサポートを表明するものと思われる。6月13日にAMDは次世代データセンター/AIに関する発表会を開催するので、ここでなにか情報が出てくるかもしれない。
おまけ 第14世代CoreはDDR5-6400をサポート
そのADATAのブースでもう1つ展示されていたのが下の画像。なるほど、第14世代CoreはDDR5-6400をサポートするわけだ。


この記事に関連するニュース
-
リブランドした「Intel Xeon 6」はどんなCPU? Intelの解説から分かったことを改めてチェック
ITmedia PC USER / 2024年7月2日 16時5分
-
Lunar LakeではPコアのハイパースレッディングを廃止 インテル CPUロードマップ
ASCII.jp / 2024年7月1日 18時0分
-
Intel Tech Talkで見えたLunar Lakeにおける低消費電力と高性能の両立へのこだわり
マイナビニュース / 2024年6月27日 6時45分
-
Lunar Lakeはウェハー1枚からMeteor Lakeの半分しか取れない インテル CPUロードマップ
ASCII.jp / 2024年6月24日 12時0分
-
【Gaudiシリーズを解説】生成AIに対し、広がる選択肢―Fugaku-LLMも快適に動作
マイナビニュース / 2024年6月18日 11時0分
ランキング
-
1「ミスiD」ファイナリストのアイドル、交通事故に巻き込まれ活動休止 「悲しくて泣く……」ファンから心配の声殺到
ねとらぼ / 2024年7月8日 19時56分
-
2『アサシン クリード シャドウズ』無断で既存団体の旗をコンセプトアートに使用―すでに謝罪済み
Game*Spark / 2024年7月8日 20時30分
-
3スタバ、一部商品を価格より高く販売していた 約10年にわたりシステム設定に不備、返金へ
ITmedia NEWS / 2024年7月8日 17時3分
-
4東京の用水路にアマゾン川の生き物が大量発生だと……? “いてはいけないヤツ”の捕獲に衝撃「想像以上にヤバかった」「ホンマに罪深い」
ねとらぼ / 2024年7月8日 22時0分
-
5一度植えたら、自動で増殖&毎年収穫を目指せる野菜5種とは? 自然農のエキスパートが伝授する方法に反響
ねとらぼ / 2024年7月8日 9時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください






