

Metaによる音楽生成AIを試す「Meta MusicGen」
ASCII.jp / 2023年7月6日 17時0分
音楽の世界でも広がる生成AI
生成AIが注目される流れは、画像や文章だけではなく音楽にも波及している。例えば、5月にSpotifyがAIで生成された数万曲を削除したというニュースがあった。これは著作権のほかにも、ビジネスモデル的な課題があるということを示している。
実際探してみると、AIが音楽を作成するというサービスは意外に多い。しかし先日紹介したグーグルの「MusicLM」のように長いプロンプト(指示文)を使用して曲の生成を指示できる音楽生成AIは探してみてもあまり見つからない。MusicLMはベータ版の運用を拡大しているが日本は対象外だ。
そうした中で、先日メタ(旧フェイスブック)が、MusicLMに似た音楽の生成AIプラットフォーム「Meta MusicGen」を発表した。メタも、(アップルを除く)ほかのテックジャイアント同様、AIに焦点を合わせてきている。その一環でもあるのだろう。
MusicGenの特徴
GitHubやHugging Face(AIコミュニティ)でのメタの解説によると、MusicGenは自己回帰トランスフォーマーモデルを使用しているとある。これはChatGPTと同じトランスフォーマー型AI、つまり生成AIのことであり、自己回帰型というのは生成AIにおいて出力を次のステップの入力とすることで長い出力を生成できるタイプのことを言う。ChatGPTで小説のような長い出力が可能な理由は自己回帰型だからである。MusicGenも同様に長い音楽を生成可能と思われるが、現在は12秒に制限されている。
学習に関しては、32kHz EnCodecトークナイザーを使用して訓練したとある。ChatGPTがテキストを用いて学習するのと同様に、MusicGenでは32kHzのトークン(最小単位)にエンコードされた音楽データを学習したということになる。よくAIでは「学習データがそのまま出てくる」と言われることもあるが、普通はデータ量を削減するために、元データをそのまま使うことはない。例えば画像生成AIなどでは元画像の中央の矩形領域のみを学習に使用するのが一般的だ。これは画像生成AIが4隅の生成に弱いとされる理由でもある。
MusicGenにおいても元データはおそらく44kHzか48kHzだと思われるが、データ量の関係で32kHzにエンコードしているのかもしれない。あるいはダウンサンプルするのは著作権対策のためとも考えられる。
どういうデータを用いて学習したかということが注目ポイントの一つであるが、「MusicGen」では2万時間に及ぶライセンスされた音楽を使用したとある。このライセンスされた音楽というのは、具体的にいうと「ShutterStock」や「Pond5」のようなストック音楽を提供するサービスのようだ。
テキストでの指示に加え、音楽サンプルの添付もできる
MusicGenのユニークな点は、文章でのプロンプト指示のほかに音楽自体をプロンプトとして使用できるという点だ。例えば「重厚なドラムとシンセパッドをバックにした、80年代のドライビングポップソング」を“バッハのメロディ”で作成するということができる。この場合、バッハの音楽はMP3ファイルなどをアップロードする。
MusicGenのコードなどの詳細はGitHubで公開されているが、デモとしてHugging Faceのウェブページで簡単に使用することができる。これは日本からも使用ができる。先にも書いたように現在「MusicGen」は12秒の音楽を生成することができ、出力はMP4形式となる。
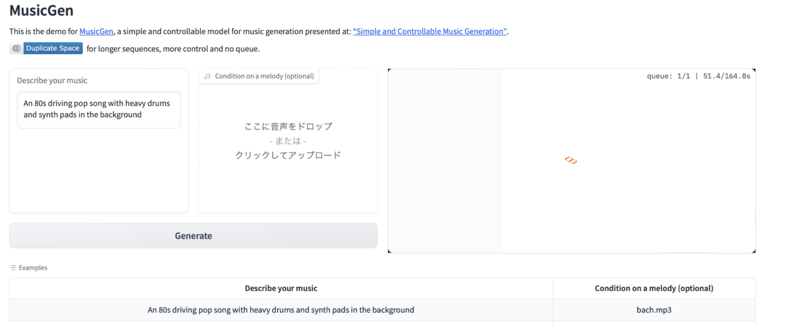
実際に試しに使ってみた。サンプルとして用意された「重厚なドラムとシンセパッドをバックにした、80年代のドライビングポップソング」とバッハのメロディを組み合わせたものと、テキストプロンプトのみの出力結果を挙げる。注記しておくとこれはMusicLMのようにあらかじめ用意されたサンプルではなく、私がMusicGenに指示を出して出力した結果だ。
参考音源付きの生成結果
テキストプロンプトのみの生成結果
ちなみに両出力結果とも同じテキストプロンプトから生成しているが、曲自体が異なるのは、MusicGenがほかの生成AIのようにランダム性を持っているからだと推測できる。ChatGPTにおいて同じ質問をしても同じ回答はしないのと同じだ。
次に独自の文章指示プロンプトを試してみるため、「静かなパートと力強いパートが交互に現れ、ドラマティックな展開となるシンフォニックプログレッシブロック」といささかマニアックな指示をしてみた。出力結果がこれだ。
プログレ風の楽曲を指示した生成結果
聞いてみるとたしかにプログレっぽいのが分かる。12秒に過ぎないが、静かなパートと力強いパートも交互に現れている。曲調はキング・クリムゾンを思わせるが、もしかすると元のストック音楽データにはクリムゾンフォロワーのようなバンドが多いのかもしれない。しかし、これは推測に過ぎない。
音楽生成AIでは著作権問題がもっとも問題になると思われるが、学習する際にライセンスに問題がない音源を使用すること、ダウンサンプリングをしているらしいこと、生成にランダム性が加わることでこの問題には一定の対策は打てているように思う。
メタはAIに注力していて、最近ではチャットGPTなどの生成AIを過去のものにするという斬新なアーキテクチャを持った「I-JEPA」というモデルを公開している。
I-JEPAはいわゆる究極のAIと呼ばれるAGIではないが、普通の生成AIよりも汎用性が高く、学習にノイズを使用しないという点が新しい。つまり細部ではなく、大まかな点に着目して学習して、推測するというモデルのようだ。
こうした成果も取り入れながらも、音楽生成AIが更なる進化を遂げる日もそう遠い将来ではないのかもしれない。

この記事に関連するニュース
-
XOP、ChatGPTの業務活用のためのプロンプト作成勉強会を11/20に開催
PR TIMES / 2024年11月9日 13時40分
-
Windowsの「ペイント」と「メモ帳」に新たな生成AIツール
ITmedia NEWS / 2024年11月8日 8時20分
-
就活を成功に導くための生成AIの活用法 – プロが勧める「使える生成AI」も紹介
マイナビニュース / 2024年11月8日 6時2分
-
AskDona RAG、ChatGPTの追加学習で社内ナレッジを最大限に活用!~新機能「システムメッセージテンプレート」提供開始~
PR TIMES / 2024年11月7日 11時45分
-
AskDona、業務効率化を促進するプロンプトテンプレート活用動画を公開!
PR TIMES / 2024年11月5日 12時45分
ランキング
-
1NHKのネット受信契約(案)が“ダークパターン”過ぎて見過ごせない件(前編) NHKの見解は?
ITmedia NEWS / 2024年11月28日 19時9分
-
2どうする? 大学生用パソコンの選び方 「4年通しよりも2年で買い替え」がオススメな理由
ITmedia NEWS / 2024年11月28日 13時26分
-
3「ミリ波対応スマホ」の値引き規制緩和で感じた疑問 スマホ購入の決め手にはならず?
ITmedia Mobile / 2024年11月28日 18時13分
-
4えっ、プレステ2のゲーム高すぎ!? ここにきて中古ソフトが高騰している納得のワケ
マグミクス / 2024年11月28日 21時45分
-
5松屋が“店内持ち込み”で公式見解→解釈めぐり賛否 「何と言うサービス精神」「バレなきゃいいのか……?」
ねとらぼ / 2024年11月28日 20時2分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





