

ChatGPTの新機能コードインタープリターに《未来の仕事の全自動化》が見える
ASCII.jp / 2023年7月10日 17時0分
国勢調査(csv)と国土地理院(xls)とドン・キホーテ店舗数(html)を自動マージしてパワポにする
OpenAIが、ChatGPTに革命的ともいえる新機能「Code Interpreter」を追加して、試した人たちの間で大騒ぎになっている。さまざまな機能が可能になっているが、その本質は名前のとおりChatGPTの中でプログラムを実行可能になったことだ。
ChatGPT plus(20ドル/月の有料ユーザー)は、随時このCode Interpreter というプラグインが使えるようになるそうなのだが。画面左下から「Settings」を選び、「Code Interpreter」のスライドスイッチをONできれば利用可能。「New Chat」をスタートしたときに「GPT-4」を選び、「Code Interpreter」にチェックする。
とくに、データサイエンティスト的な数値の分析の世界にインパクトが大きいとされているが、実際には、机の上で仕事をする人たち全員に影響する内容である。
たとえば、複数のデータからもってきた情報を1つの表にしてまとめてプレゼン資料にするなど誰でもやる作業である。この例では、《国勢調査》による都道府県別の人口と、《国土地理院》による面積、さらに、《ドン・キホーテ》の店舗数をもってくる。
そこで、こうしたデータを手作業で切り貼りするわけだが、面倒だしヒューマンエラーも発生しがちというものだ。簡単そうに見積ってしまい残業になりがちでもある。
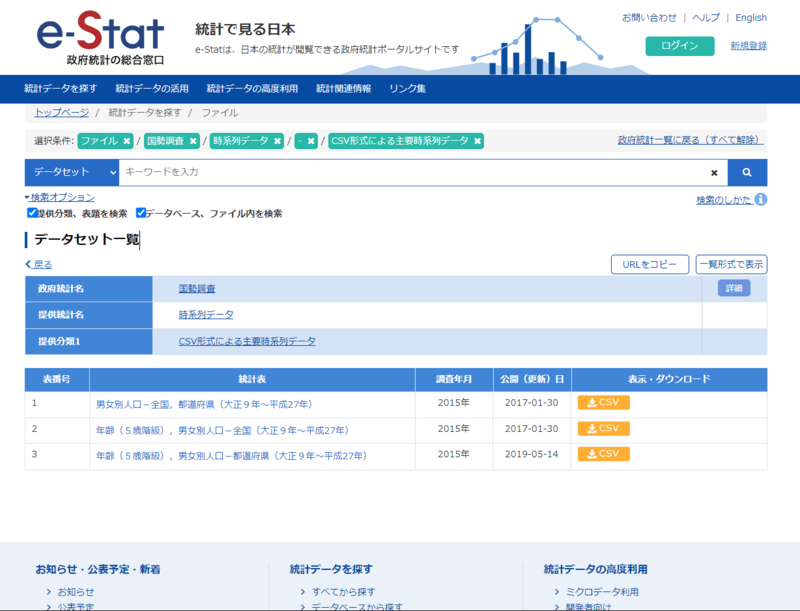
政府統計の総合窓口 e-Statは、とてもありがたいサイトだが、まずここから国勢調査のデータをダウンロードしてくる。開発者向けとしてAPIもいろいろと紹介されているのだが、今回は、それがない場合の例としてCSV形式のダウンロードデータを使わせてもらうので念のため。
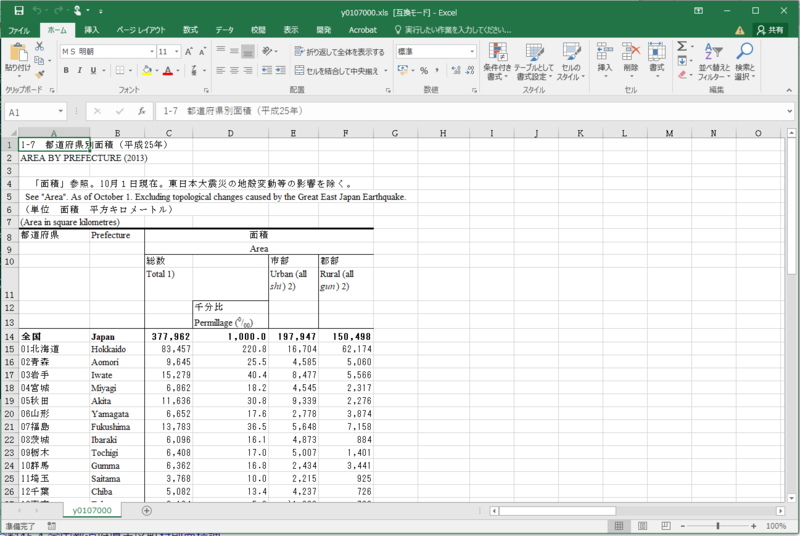
次に、国土交通省 国土地理院の令和5年に公開された「全国都道府県市区町村別面積調」(「面積調」という言葉があるのですね)をもとにした、総理府統計局が公開している「都道府県別面積」のエクセル形式のデータである。
最後が、ドン・キホーテの公式ページにある店舗一覧である。これは、CSVでも、エクセルでも、APIでも、XMLでもなく、人間が目で見るためのウェブページである。このページを構成しているhtml形式ファイルをダウンロードして使わせてもらうことにする。
これを、ChatGPTの新機能 Code Interpreter でどんなふうにマージして1つのエクセルファイルにして出力、さらには、その結果をパワーポイントにしたか? 次のビデオでご覧いただきたい(大幅に省いてあるのでやりとりの雰囲気を見ていただきたい)。
Code Interpreter を使う設定にすると、ChatGPTのメッセージ窓の左側に「+」マークが表示されるようになる。これは、ファイルのアップロードボタンだ。そこで、国勢調査の人口データ、国土地理院の面積データ、ドン・キホーテの店舗一覧画面データを、1つずつアップロードしては、エクセルにマージしていく。
ちなみに、Code Interpreterの意味は「Pythonのコードを作って実行できる」ということから来ているのだろう。アップロードしたデータの加工を、ChatGPTが自動生成したコードを実行することで行うわけだ。私も、エクセル形式のデータを大量に操作するときには、Pythonでエクセルが操作できる「Openpyxl」というライブラリを使ったりするが、同じ発想である。
今回の場合は、私は、元データを都合よい形に編集したり、Pythonのコードを書いたりすることも一切していない。ひたすら、ChatGPTが、全自動で作業をすすめるようすを眺めながら、必要なファイルを与え、ときどき「こうしてほしい」とか入力しているだけである。
説明しながら動くので《人間の作業者》以上に信頼できる?
動画をよく見てほしいのだが、バラバラのデータ形式の整合性をとったり、都道府県の表記のブレ、さらには数値データなのに文字形式だったりするなど、こまかな対応を次々にやってくれている。その都度、そうした対応の内容を実況中継し、うまく処理できなかったと自身が評価したときは、「申し訳ありません」とお詫びした上で新たな試行錯誤をしてくれる。ケナゲとしか言いようがない。

途中、私が介在をしたのは、ドン・キホーテの店舗一覧ページの処理をやっていたときだけだ。htmlファイルから店舗の住所を特定できない言ってきたので、住所らしい表記は店舗住所しかないので、それを集計すればよいのでは? とアドバイスした。

「郵便番号と住所がきちんと書かれている文字列を見つけて集計する」といったことは、人間ならとっくにやっていることだろう。ひょっとしたら、今回、私がこんなヒントを与えたことで、今後は、ChatGPTは、こうした店舗一覧ページをなんなく処理するようになるかもしれない。
などと書くと、「妄想でしょう」と言われそうだが、あながちそうでもないかもしれない(他にやる人が増えればか?)。私は、2023年11月にChatGPTがリリースされてすぐ、「モノを擬人化したラブストーリー」を書いてとお願いした。すると「このようなリクエストを受けたのは初めてですがやってみます」と答えてストーリーを書いてきたのだ。現在では「擬人化してストーリーを書いて」という要求に、黙って答えてくる。
結果的に、国勢調査と国土地理院とドン・キホーテのデータをまとめたエクセルファイルがまずはできあがり、さらには、パワポファイルを書きだしてもらった。パワーポイントについても、Pythonには、「python-pptx」というライブラリがあるので、Code Interpreter は、それを実行して出力してきたわけだ。
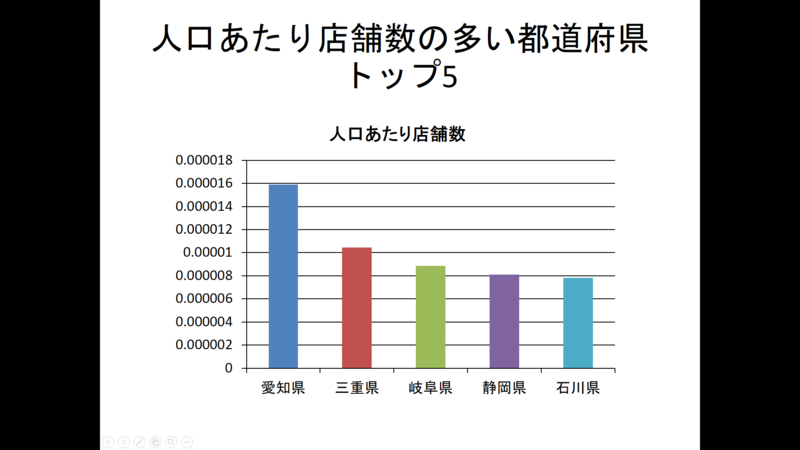
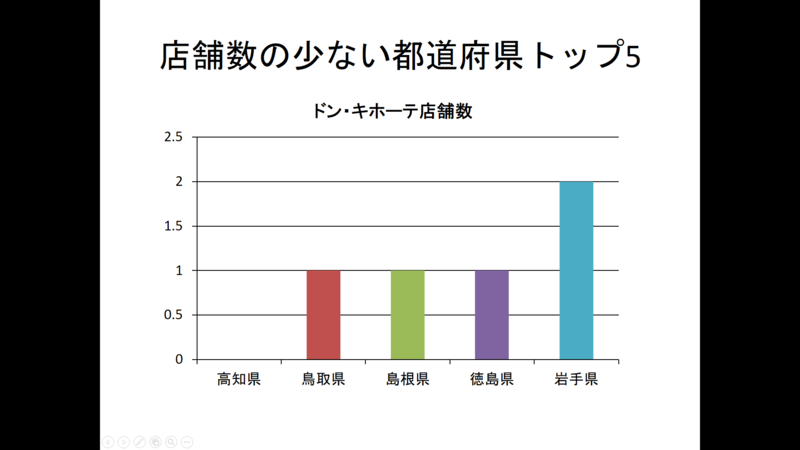
実際に生成したパワポでは、店舗数の多い/少ないのトップ5、「人口あたり」の多い/少ないのトップ5、「面積あたり」の多い/少ないのトップ5をあわせた6枚のスライドを出力。上記は、その例だが縦軸に人口あたりの小数点以下の桁数の多さや店舗数に「0.5」があるのは、いまのところご愛敬。こうしたことも対応していく可能性がある。
また、これに関する所見として次のような「まとめ」を書きだしてきた。
このデータ分析により、ドン・キホーテの店舗数が都道府県ごとにどのように分布しているかが明らかになりました。店舗数が多い都道府県は主に大都市圏に位置しており、特に愛知県が最も多くの店舗を擁しています。一方で、店舗数が少ない都道府県は主に地方の県で、特に四国や中国地方の県が目立ちます。これは都市部と地方部との間で人口や経済規模に大きな差があることを反映している可能性があります。
また、人口あたりの店舗数や面積あたりの店舗数を見ると、店舗数の多い都道府県とは異なる傾向が見られます。これらの指標では、人口が比較的少ない県や面積が狭い県が上位にランクインしています。これは、ドン・キホーテが地方都市でも一定の市場を獲得していることを示しているかもしれません。
この分析からは、ドン・キホーテの店舗展開戦略に地域間で一定の差があることが読み取れます。また、西日本の県では店舗数が全体的に少ない傾向があり、これは西日本に新たな店舗を開設する機会があることを示しているかもしれません。
分かり切った分析といわれそうだが、知らない事柄については、このくらいシンプルなところからでいないと相手に伝わらない。
おそらく、都道府県の人口と面積、ドン・キホーテの店舗数をまとめて表にするだけなら、ちょっと慣れた人なら1時間くらいでまとめてしまうのだと思う。今回、これだけのことをやるのに延々と時間がかかったのは、あまり効率的でないようにも見える。しかし、もっと分かりにくい大量の項目を名寄せしたい場合には、ChatGPTのCode Interpreterは、威力を発揮するはずである。
なお、ChatGPTは、実行時のほんのちょっとした条件の違いで結果が変わるので、私と同じ結果にはならない可能性がある。今回は与えたデータの整合性に関しては難易度がやや高かったとも思える。
こうしたオフィスワークのためのAIによる自動化や効率化は、マイクロソフトも提案しているし(Microsoft 365 Copilot)、ChatGPTの周辺ツールとしてエージェントと呼ばれる分野(AutoGPTやAgentGPT、BabyGPT)が成立している。明日、我々の仕事がすべて変わりはじめるわけではないが、未来の仕事のようすが少し見えはじめている。
「AIは人の仕事を奪う」ではなく「AIはプログラムの存在をあやうくする」
ところで、このようにして得られた結果というのは正しいのだろうか? 実は、間違っている可能性がおおいにある。今回の例くらいシンプルな問題なら、「全件」元データにあたって検証してみることができる(目的によってはサンプルでもよいだろう)。
それが可能なくらい複雑にならないよう作業を分解して、ChatGPTにタスクを与えるべきである。今回も、1つファイルを追加するごとにエクセルファイルの中身を確認して、表全体ができてはじめて「こんなパワポを作ってほしい」とお願いした。「全自動化」とは書いたが、実際に全自動化できるとは思うが段階的にやるのが賢明というわけだ。
大切なデータであれば、バリデーションという作業を行うのが当たり前である。たとえば、1つのデータを入力するときに二度にわたって別の人間が入力して、突き合せをする。ChatGPTは、人間みたいなものだから同じ作業を異なるアプローチでやってもらって比較するのもありだろう(あるいは別の人工知能と比べるか)。
また、ChatGPTがコードを書いてそれを実行しているのがCode Interpreterなのだから、コードを書きだして保存・検証する方法もあるだろう。その際、彼は丁寧な解説をコメント付きのコードとともに書き出してくる。
ChatGPTは「人間に理解を促す」ように作られていることは、もう少し理解されるべきだと思う。
ところで、ChatGPTの中身ともいえる大規模言語モデルGPT-4は、もともとマルチモーダルで画像を認識することもできる(一般ユーザーに開放されていないだけなのだ)。それが、今回、Code Interpreter では、ファイルのアップロードによって本当に部分的ではあるが可能になった(従来も裏技的なアプローチはあった)。また、GIFファイルの出力もできるあたりは、人に理解をうながすアニメを吐き出すのも時間の問題かもしれない。
プログラマーが、鉛筆で描いたメモを見てChatGPTが仕事をする時代がくる。すでにそうしたGPT-4のデモ映像が知られている。データ構造、それをあつかうための基本的なアイデアや概念図など、「ことば」とともにさまざまな手段で、人工知能とのインタラクションができるようになりそうだ。
しかし、そうした時代にプログラムというものをまだ人間は目にしているのだろうか? AIが、SFで描かれた世界のように世の中に直接関与することの是非は議論されている。「AIが人の仕事を奪う」という議論がされてきたが、「AIがプログラムの存在をあやうくする」ことになるかも知れない。将来的にプログラミング言語はAIと人間の合意のための言語になると思っているのではあるが。
遠藤諭(えんどうさとし)

株式会社角川アスキー総合研究所 主席研究員。MITテクノロジーレビュー日本版 アドバイザー。プログラマを経て1985年に株式会社アスキー入社。月刊アスキー編集長、株式会社アスキー取締役などを経て、2013年より現職。人工知能は、アスキー入社前の1980年代中盤、COBOLのバグを見つけるエキスパートシステム開発に関わりそうになったが、Prologの研修を終えたところで別プロジェクトに異動。「AMSCLS」(LHAで全面的に使われている)や「親指ぴゅん」(親指シフトキーボードエミュレーター)などフリーソフトウェアの作者でもある。趣味は、カレーと錯視と文具作り。2018、2019年に日本基礎心理学会の「錯視・錯聴コンテスト」で2年連続入賞。その錯視を利用したアニメーションフローティングペンを作っている。著書に、『計算機屋かく戦えり』(アスキー)、『頭のいい人が変えた10の世界 NHK ITホワイトボックス』(共著、講談社)など。
Twitter:@hortense667
この記事に関連するニュース
-
北海道と西日本を同じ大きさの円で囲ってみた→16府県がすっぽり「北海道はでっかいどう」な結果が話題
よろず~ニュース / 2024年11月17日 7時50分
-
一人暮らしの高齢世帯 2050年に32道府県で20%超え 人口問題研究所が推計を発表 自治体が中高年の婚活支援も
RKB毎日放送 / 2024年11月14日 10時47分
-
単身世帯、2050年に40%超 27都道府県で、未婚や少子化
共同通信 / 2024年11月12日 19時1分
-
「子育てしやすい」自治体ランキング2024最新版 東京圏、名古屋圏、近畿圏、の上位はどこか
東洋経済オンライン / 2024年11月9日 7時30分
-
法人向けChatGPT「ChatSense」、ファイル・画像入力の上限を5枚に引き上げ
PR TIMES / 2024年10月31日 10時21分
ランキング
-
1ITジャーナリスト三上洋氏が解説!急増している迷惑電話、犯罪の手法と対策
ITライフハック / 2024年11月29日 9時0分
-
2クラファン始動から約12年、“いまだ未完成”なのに…約1,125億円超えの資金をユーザーから集めたゲーム
Game*Spark / 2024年11月29日 11時5分
-
3NHKのネット受信契約(案)が“ダークパターン”過ぎて見過ごせない件(前編) NHKの見解は?
ITmedia NEWS / 2024年11月28日 19時9分
-
4バージョンアップで対処を!ファイル圧縮・解凍ソフト「7-Zip」24.06以前に攻撃者が任意のコードを実行できる脆弱性
Game*Spark / 2024年11月29日 11時15分
-
5巨大エンタメ企業に潜んでいた“死角”――ソニーのKADOKAWA買収は外資牽制の一手になるか
ITmedia NEWS / 2024年11月29日 12時19分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





