

電気を利用せずにスイッチングできるGoogle TPU v4 AIプロセッサーの昨今
ASCII.jp / 2023年7月24日 12時0分

またしばらく間が空いてしまったがAIプロセッサーの話をしよう。今回はGoogle TPU v4である。Google TPUそのものはこのAIプロセッサシリーズの最初の回で説明した。この時にはGoogle TPU v1~v3までに触れたが、2021年のGoogle I/O 2021で後継となるGoogle TPU v4が発表された。この発表の概略は動画の2分11秒あたりから一瞬だけ紹介されている。
そのGoogle TPU v4は2021年後半から一般にも供用が開始されている。供用、というのはGoogle Cloud TPUサービスという形での提供と言う意味で、チップ自身の販売はなされていない。
そのGoogle TPU v4、発表時にも概略の説明はあったのだが、今年の4月にGoogle自身がそのGoogle TPU v4の詳細を公開した。こちらは論文も出ており、今年6月に開催されたISCA 2023で発表されている。というわけで、この詳細の説明や論文をベースにGoogle TPU v4(以下、TPU v4)について解説したい。
演算性能がTPU v3からほぼ3倍にアップしたTPU v4
TPU v4そのものはTPU v3の延長上にある。下の画像が論文に示されたTPU v3とTPU v4の比較であるが、製造プロセスがTSMCの16FF+からN7に変わり、動作周波数も微妙に向上(940MHz→1050MHz)、トランジスタ数も倍増している。
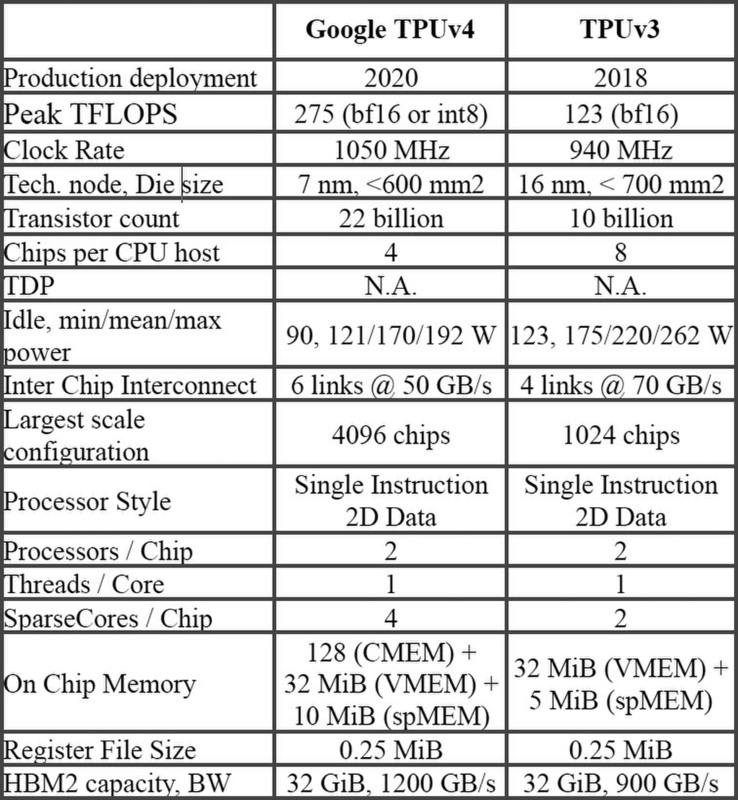
基本的なアーキテクチャーはTPU v1から変わっていないが、MXU(Matrix Multiply Unit)のサイズがTPU v1では256×256の64K/サイクルだったのに対し、TPU v2~v4では128×128の16K/サイクルに縮小され、ただしTPU v2とv3ではこれが2つ、TPU v4では4つ搭載される。
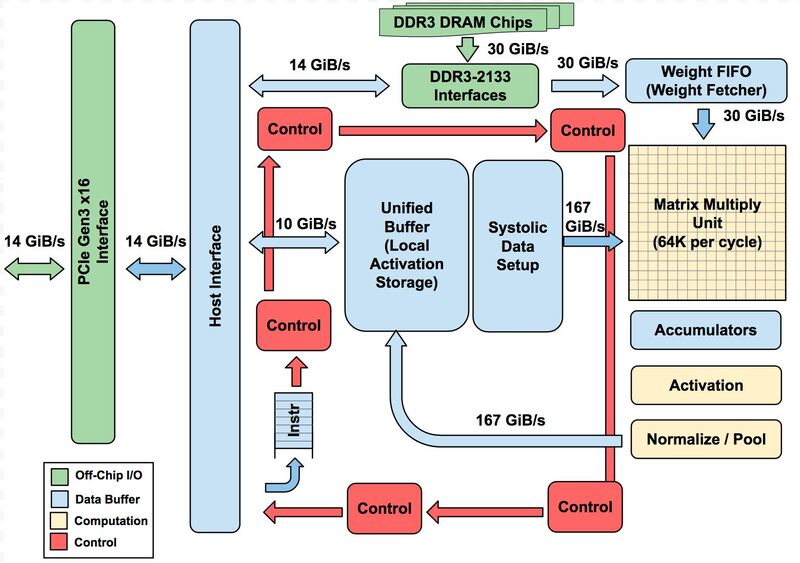
ただし、v2以降ではTensor Core(つまりTPU v1の図全体)が1チップに2つずつ搭載されるので、MXU全体の規模としてはTPU v1~v3までは64K/サイクル、TPU v4では128K/サイクルになっている計算だ。
結果として演算性能はTPU v3のほぼ倍になる275TFlopsに引きあがっている。ちなみにTPU v3まではBF16のみのサポートだったが、TPU v4ではINT 8もサポートされている。もっともどの程度INT 8を使うのか? というのは微妙なところで、メインはBF16になりそうである。
なぜか? という話も論文に出ている。すでに2021年後半からTPU v4によるサービスがスタートしているわけだが、そのサービスでの学習ワークロードの90%以上がTPU上で行なわれている。2022年10月の時点で、そのワークロードの58%はTransformerモデルだった。このうち26%がBert、31%はLLM(Large Language Modelだった。
またTPU上で行なわれた学習の24%はレコメンデーションモデルだったとなっている。要するにTPU(v4だけでなくv3などもだろうが)の主要な用途は学習向けであって、推論処理よりは多少精度が必要になる。
特に学習の場合INTでは桁が足りないので、指数を利用できるFP16なりBF16でないとまずい(FP32の方がより良いだろうが、このあたりは精度と学習速度のバーターになるだろう)という話だ。今だとここにFP8を使ってどこまで精度を落とさずに済むかの検証をしているところだが、設計年度が2020年なのでまだFP8のサポートがないのは致し方ない。
チップの消費電力は最大でも200W程度
話を戻すと、もう1つ大きな違いはチップの集積数だ。TPU v3の場合は4本のリンクで合計280GB/秒だが、TPU v4ではこれが6本になり帯域も300GB/秒になっている。6本、ということは3次元メッシュが構成できるという話で、4本で2次元メッシュしか構成できないTPU v3よりも多くのチップを同等のレイテンシーで接続可能であり、実際接続できる数も最大1024チップから4096チップに増えている。
例えばTPU v3とv4でどちらも最大構成を正方形なり立方体の構成で接続するとすると、TPU v3なら32×32構成になるので、正方形の端から端まで通信するのに31×2で62hop必要になる。
一方TPU v3では16×16×16構成になるので、立方体の端から端までの通信は15×3で45hopで済む計算になる。TPU v3よりも4倍も多い数のプロセッサー間通信が、v3よりも少ないhop数で通信できる、というのがここでのメリットというわけだ。ちなみにメッシュといっても実際はHyperCube型に両端が接続されている構造だ(論文では3Dトーラス構造としている)。
ちなみにTPU v4のパッケージが下の画像だ。チップの消費電力は最大でも200W程度(HBMの分も含む)とそれほど大きくないのだが、空冷にするとどうしても体積を喰う(さすがに1Uサーバーに収めるには冷却能力的に厳しいだろう)ということで液冷となっている。


この液冷のモジュールは1本のラックに128枚(つまりTPU v4が512個)収められ、このラックを8つ並べたのがTPU v4 Podと称されている。

なぜここまで高密度にするかと言えば、TPU v4同士のネットワーク接続の距離を最小に収めたいためである。2Uあるいは3Uサイズにすると、明らかにラックの数が増え、それだけネットワークケーブルの長さを伸ばす必要がある。
おそらく、液冷にする方が高密度化によりネットワークのレイテンシーも削減できるし、到達距離が短い分ネットワークの消費電力も減り、性能も向上する。液冷システムを追加する分消費電力は増えるが、これは性能と消費電力のバーターという話であろう(ついでに言えば、空冷よりも効率的に冷却できる分、トータルでの消費電力はむしろ減っているかもしれない)。
ネットワーク周りではもう1つ、スイッチも独特である。論文によれば、2つ上の画像にある基板には4つのPCI Expressコネクターと16個のOSFPコネクターが搭載されているとされる。
PCI Expressの方が基板の表面に見えているもので、これはホストとの接続用と思われる(OCuLinkコネクターだろう)。ちょうどそのPCIeの裏側にOSFPコネクターが4つづつ、合計16個並んでいる格好だ。このOSFPコネクターはTPU v4同士を接続するためのものと思われる。
OSFPというのはイーサネットのトランシーバー用モジュールの規格の1つで、下の画像のようなのモジュールを装着する格好だが、2020年という時期から考えるとまだ400Gbpsの対応は難しく、おそらく100Gbpsのモジュールを装着しているものと思われる。

ちなみにイーサネットを使っているからといって別にTCP/IPを通しているわけではなく、独自のネットワークプロトコルを通しているものと思われる(CelebrasやTenstorrentと同じやり方だ)。
電気を利用せずに光信号のままイーサネットをスイッチングできる
さて、先程4096個のTPU v4を3Dトーラス構造で接続すると説明したが、これは厳密には正しくない。実際のTPU v4 Podは、64個のTPU v4を4×4×4の3Dトーラスで構成し(これをCubeと呼ぶ)、このCube同士をさらに4×4×4の3Dトーラス構成としてつなぐ、という構成である。
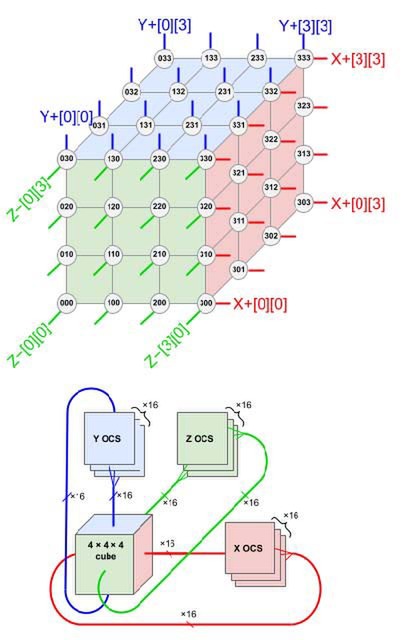
このCube同士の接続にはイーサネットのスイッチを介することになるのだが、このスイッチであるPalomar OCS(Optical circuit switches)は、なんと電気を利用せずに光信号のままMEMSミラーを利用する構成になっている。
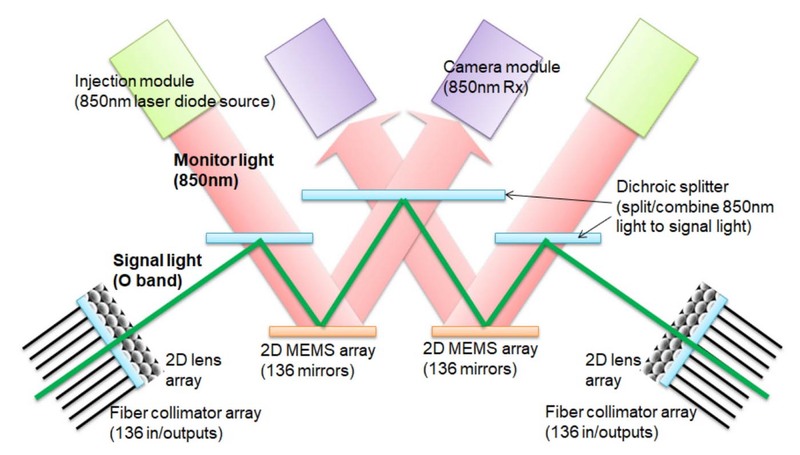
通常、イーサネットのスイッチというのは光信号入力→光/電気変換→電気信号ベースでスイッチ→電気/光変換→光信号出力という形で実装されている。これに対しPalomar OCSは2つのMEMSミラーを利用してスイッチを行なう、つまり光/電気変換や電気/光変換をせずにスイッチングを行なう仕組みである。
GoogleによればこのPalomar OCSの価格はTPU v4 Pod全体の5%未満、消費電力は3%未満とされ、InfiniBandに比べてはるかに安く、低消費電力を実現できている。実際高速なスイッチの場合、スイッチチップそのものの消費電力だけでなく光/電気の双方向変換に結構な消費電力を費やしているから、MEMSミラーの駆動だけで済むPalomar OCSは非常に優秀と言える。
もっともその分、2つのMEMSミラーと3つのハーフミラー(このハーフミラーは、MEMSミラーの制御や確認のために利用する850nm帯のレーザーを通し、それ以外は反射する)を通るから、それなりに信号が減衰する。短距離用のxBASE-SRではなく、中長距離用(つまりもともとの光信号の強度が高い)のxBASE-FRもしくはxBASE-LRを前提にしているのは、Palomar OCSの損失が少なくない可能性が高い(*1)。
ところでこのPalomar OCS、パケットの中身を見て切り替える機能はない(そもそも入力パケットの中身を判断する機能がない)。Palomar OCSは事前プログラミング方式で、稼働させるニューラルネットワークに合わせてトポロジーを変更する用途であり、一応ミリ秒単位で構成の変更は可能であるが、動的に切り替えるという用途には適さない。
ただ、特に大規模のニューラルネットワークで動的に構成を切り替えるという使い方はあまりない(同時に複数のネットワークを稼働させる、などではまた別だが)ことを考えれば、レイテンシーと消費電力・コストを抑える良い仕組みと言える。
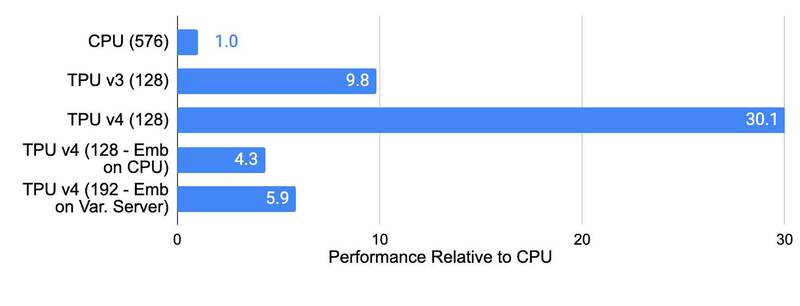
このTPU v4の性能、Googleによれば例えばレコメンデーションではTPU v3の3倍、CPUの10倍の性能であるとしており、MLPerf Training 2.0での結果ではNVIDIAのA100ベースのシステムと比較して最大1.87倍高速で、消費電力は最大1.93倍少ないと主張している。
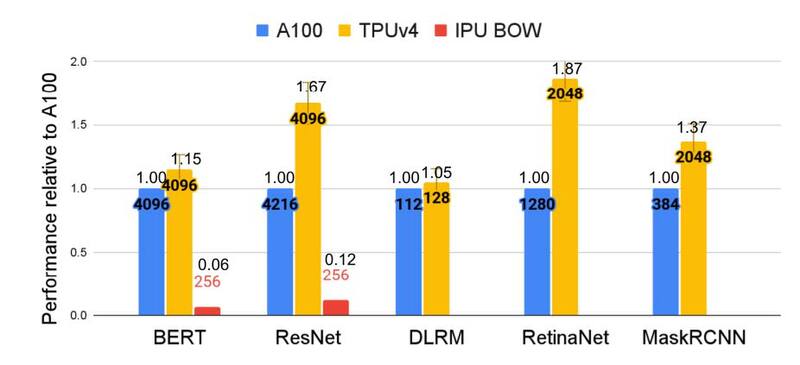

ちなみにもはやA100は最新製品ではなく、現行はH100だったりGH200だったりするわけだが、これに関してのGoogleの主張は、同じ7nmプロセスで製造した製品同士の比較であり、H100との比較はTPU v4の後継製品で行なうべき、というものである。
今年のGoogle I/OではTPU v5の話は特になかったことを考えると、登場するのは来年あたりだろうか? TPU v1が2015年、v2が2017年、v3が2018年、v4が2020年だったことを考えると、そろそろ出てきてもおかしくない時期である。さてH100をどの程度上回る性能になるだろうか?
(*1) 制御用に850nm帯のレーザーを使う関係で、ハーフミラーで分離しやすい1310nmを利用した、という可能性もなくはないが、だとすれば制御用を1310nmにして信号は850nmという選択肢もあったわけで、そちらではないということはやはり減衰がバカにならない可能性の方が高い。

この記事に関連するニュース
-
STマイクロエレクトロニクス、ヘルスケアおよびフィットネス向け次世代ウェアラブル機器を実現する革新的なバイオセンサ技術を発表
PR TIMES / 2024年11月14日 17時0分
-
エンドツーエンド光接続時の波長を有効活用する長距離光伝送技術を確立 ~光と電気アナログ信号による波長変換技術を活用した光ノードシステムを開発~
Digital PR Platform / 2024年11月12日 15時7分
-
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月11日 12時0分
-
6Gにおけるサブテラヘルツ帯の超高速無線を実現する小型無線デバイス ~InP集積IC技術により300GHz帯において世界最高の160Gbpsデータ伝送に成功~
Digital PR Platform / 2024年10月28日 15時7分
-
AI性能を引き上げるInstinct MI325XとPensando Salina 400/Pollara 400がサーバーにインパクトをもたらす AMD CPUロードマップ
ASCII.jp / 2024年10月28日 13時0分
ランキング
-
1歴史的名作『Half-Life 2』20周年!期間限定無料配布、拡張パック同梱するアプデ、資金不足やハッキング被害にも触れるドキュメンタリー映像などでお祝い
Game*Spark / 2024年11月16日 13時52分
-
2Amazonブラックフライデーで出品されたら即ポチ必至「PC&スマホ・タブレット」5選【ネット通販傑作遊びモノ】
&GP / 2024年11月16日 20時0分
-
3あれ、意外とイイかも? 電車派必見なiPhone「マップ」アプリの便利機能3選
&GP / 2024年11月16日 7時0分
-
4極薄な折りたたみスマホ「Galaxy Z Fold Special Edition」が登場 日本投入はある?
ITmedia Mobile / 2024年11月16日 10時5分
-
5不具合続いた『Wizardry Variants Daphne』実装予定機能を時期未定に―開発・運用体制の大幅増強を宣言
Game*Spark / 2024年11月16日 14時57分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





