

Meteor LakeのNPU性能はGPUの7割程度だが消費電力が圧倒的に少ない インテル CPUロードマップ
ASCII.jp / 2023年10月9日 12時0分

今回はMeteor LakeのAI周りについて解説しよう。といっても、これまでも何回か紹介している。連載686回で説明したようにMeteor Lakeに搭載されるものは、2022年まではIntel VPUと称しており、Meteor Lakeに先立ちRaptor LakeにはAI M.2モジュールとして提供されてここでアプリケーションの先行開発が行なわれることになっていた。

映像処理時のCPU/GPU負荷を下げる Intel VPU
そのNPUというかVPU、元になったのはインテルが2016年に買収したMovidiusのMyriadシリーズVPUである。もともとMyriadシリーズはVision Processor Unit、つまり映像処理用プロセッサーとして発表されており、2011年には最初のMyriad 1が発表される。
2014年には後継となるMyriad 2がやはり映像処理用のプロセッサーとして発表。ところがその2年後の2016年にはMyriad 2がそのままAIプロセッサーとして再発表され、その直後にインテルに買収された格好だ。このMyriad 2の内部構造は連載566回で紹介している。
さて、インテルの買収後に第3世代製品であるMyriad Xが投入されている。変更点は以下のとおりで、SHAVEエンジンとNeural Compute Engineの組み合わせで1TOPSの推論処理性能を持つとされている。
- SHAVEコアを12基→16基に増量
- CXM Memory Fabricを2MB・400GB/秒→4MB・450GB/秒に大容量化/高速化
- 製造プロセスをTSMC 28nm HPM→TSMC 16nm FFCに微細化
- 外部メモリーI/FをLPDDR2/3→LPDDR4に
- 新たにLEON4(SPARC V8互換プロセッサー)×2を管理用に搭載
- 新たにNeural Compute Engineを搭載
このMyriad XはNeural Compute Stick 2に搭載された他、M.2モジュールの形でも提供されている(いた)。
さらにインテルはこのMyriad Xをベースに、Keem Bayと呼ばれるSoCも開発していた。2019年のIntel AI Summitで発表されたこのKeem Bayは、Myriad X単体の最大10倍の処理性能を実現する(ただし内部構造を変更というよりは、単純にVPUを10個積載する格好である)もので、またArmのCortex-A53を4コア(1.5GHz)搭載し、単体でLinuxが起動するものだった。
今回Meteor Lakeに搭載されたNPUは、Myriad Xのコアをさらに改良したうえで、デュアルで搭載した格好になる。

まずこの中のMACアレイは畳み込み処理や行列演算などを最大2048 Ops/サイクルで処理可能とされる。MAC処理の場合は2 Ops/サイクル相当になるから、演算性能は4096 OPS/サイクル。仮にこのNPUが1GHzで駆動されたとすると、それだけで8TOPSの処理性能になる勘定だ(MACアレイは2つあるため)。
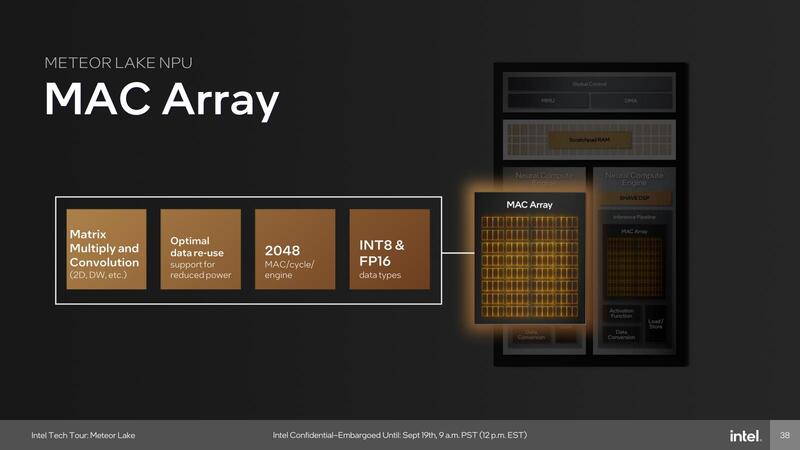
またアクティベーションに関しては、従来はSHAVEコア側で行なっていたが、Meteor Lakeでは専用のユニットが実装されたことで、より高効率化が図られている。

またData Conversion Unitが新たに追加されている。これも従来はSHAVEコアを使って行なっていた処理で、こうしたものをすべて専用ユニットにしたことで通常の畳み込みニューラルネットワークであればSHAVEコアをほぼ利用せずに処理が可能になったと見られる。
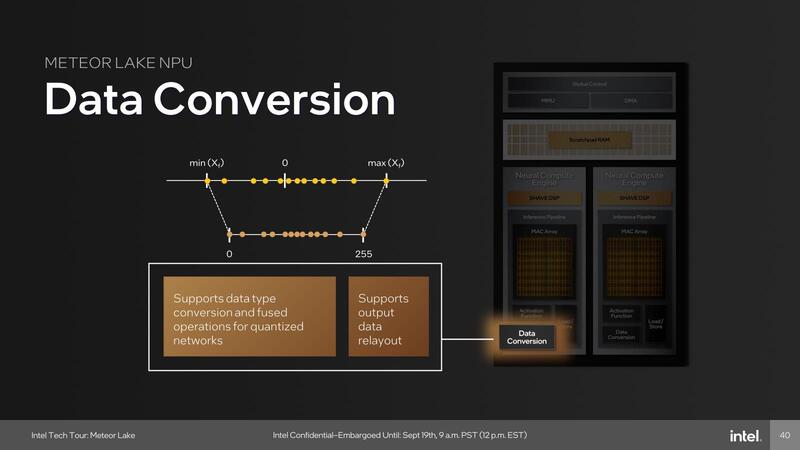
ではSHAVEは省かれたか? というとそんなことはなく、むしろ強化されている。VLIWエンジンそのものはデュアルとなり、されにINT 4などのデータ型にも対応、さらにFP32での演算機能を強化したとしている。

少し意外だったのはMACアレイそのものはINT 1/2/4やFP8/BF16などには未対応なことで、こうしたものはSHAVEコアを利用して処理する形なのは変わらない。つまりMAC アレイはすでにネットワークの構成などが決まっているものを高速に処理することに特化しており、新しく出てくるネトワークはSHAVEコア側で処理する形になる。
これそのものはごく一般的な手法であるが、INT 1/2やFP8はともかくINT 4/BF16あたりまではMACアレイ側でもサポートしていると思ったのだが、このあたりは設計開始時期にも絡んでくるのかもしれない。この第4世代、投入されるのは2023年末であるが、設計開始そのものはMyriad Xが完成した2017年あたりと想像されるためだ。
スクラッチパッドRAMとDMAエンジンが追加
そしてもう1つ、新たに2つのNeural Compute Engineで共有する形でスクラッチパッドRAMとDMAエンジンが追加された。Myriad Xまでと異なり、Meteor LakeのNPUは専用の外部メモリーを持たず、システムで共用となる。帯域そのものはむしろ増えているとは言え、他の処理でもやはりメモリーアクセスが発生するわけで、利用できる帯域は間違いなく減っているだろうし、レイテンシーそのものも大きくなっていると考えられる。おそらくはこれを補う目的でスクラッチパッドが用意されたのだろう。
おもしろいのはこれがキャッシュではなくスクラッチパッドで、しかもDMAエンジンが外部から制御されることだ。キャッシュでないのは、SHAVEコアを含むNeural Compute Engineが自発的にプログラムを処理するというよりは、外部のコントローラーから渡された通りに処理をする形になっているので、以下の方式では無駄が多い。
処理をする→オンメモリーにデータがない→リクエストを出す→キャッシュに入る
なによりキャッシュにしたところでそのデータをすぐに再利用するかどうかは怪しい。それよりは外部のコントローラが先行して必要となるデータを用意し、DMAを使ってスクラッチパッドに転送、そのデータを使ってNeural Compute Engineが処理する方が待ちが少ないためだろう。
ただ普通スクラッチパッド用のDMAは、それが利用するプロセッサー(この場合で言うならNeural Compute Engine)が制御するのが一般的なので、少しおもしろい感はある。
ちなみにその外部のコントローラーにあたるのが下の画像である。ホストとのドライバーとの制御や2つのNeural Compute Engineへの処理の振り分けや結果の転送、電源管理、セキュリティなどの処理をまとめて行う格好だ。

VPUからNPUに名前が変わったのは AIと機械学習に特化したから
ところでMyriad Xの世代まではVPUと呼ばれていたのが、なぜMeteor LakeではNPUに名前が変わったのか? であるが、連載566回でも説明したようにもともとMyriadシリーズは映像処理用のプロセッサーであり、映像処理用のフロントエンドや簡単なフィルタリングなどの機能も搭載されていた。機能的にはISPに近い。
これはMyriad Xでも同じであるのだが、Meteor Lakeの場合はそもそも独立してISPが搭載されているから、改めてもう一個ISPを搭載する必要がない。このためNeural Compute Engineは元よりその周辺から映像ハンドリング用の機能は完全に省かれ、純粋にAI/機械学習処理のみが行なえる構成になった模様だ。これに合わせて名前がVPUからNPUに変更になったものと考えられる。

OpenVINO以外のソフトウェアが使える
さてハードウェアに関してはおおむねこの程度しか情報が開示されていないが、ソフトウェアについても説明しておきたい。
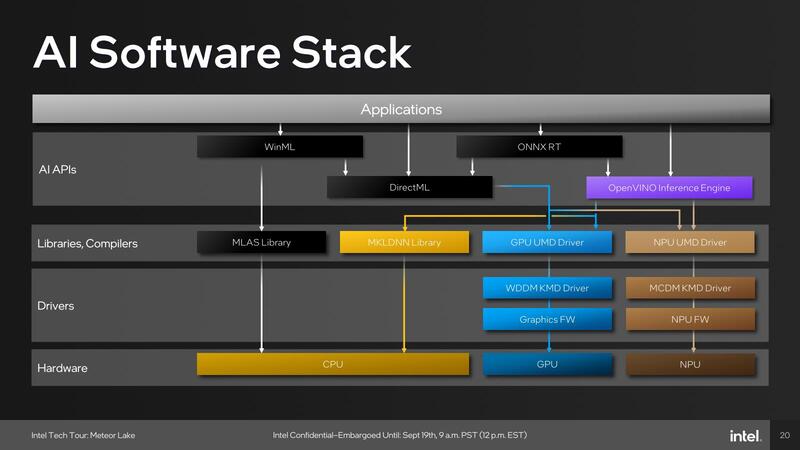
もともとMyriad 2/Xの場合、ソフトウェアフレームワークとしてはOpenVINOを使うことを強く推奨していた(事実上他に選択肢がなかった)わけだが、Meteor Lakeでは広範なアプリケーションに対応する必要があり、そこでOpenVINOだけ、という選択肢はさすがに存在しないと判断したためか、ずいぶん複雑なソフトウェアフレームワークが提供されることになった。
Meteor Lakeでは基本的に以下の4種類のAPIが提供される。
一番柔軟性が高いのがWinMLを使った場合で、CPU/GPU/NPUのどれを使うことも可能である。DirectML/ONNX RT/OpenVINOではGPUないしNPUを選択できる。おそらくONNX以外はデフォルトがDirectML→GPU、OpenVINO→NPUになっており、オプションを追加しないとこのデフォルトが使われるのだろう。
この場合、GPUがDirectMLに対応できる機能が必要になる。具体的にはDirectX 12のShader Model 6.4で提供されるDot-Products 2/4をハードウェアで実行できる必要がある。この詳細は次回説明するが、Meteor LakeのGPUはXMX(Matrix Engine)を持たない代わりに、Xe CoreにDP4Aの機能を追加してこれをカバーしている。
アプリケーション例としては、例えばMicrosoft Teamsで利用しているWindows Studio EffectsはOpenVINOをNPUのみで利用、Adobe Creative CloudはDirectMLをGPUで利用、ビデオ分析系はOpenVINOをNPUないしGPUで利用と、アプリケーションごとに使うパスが異なっている。
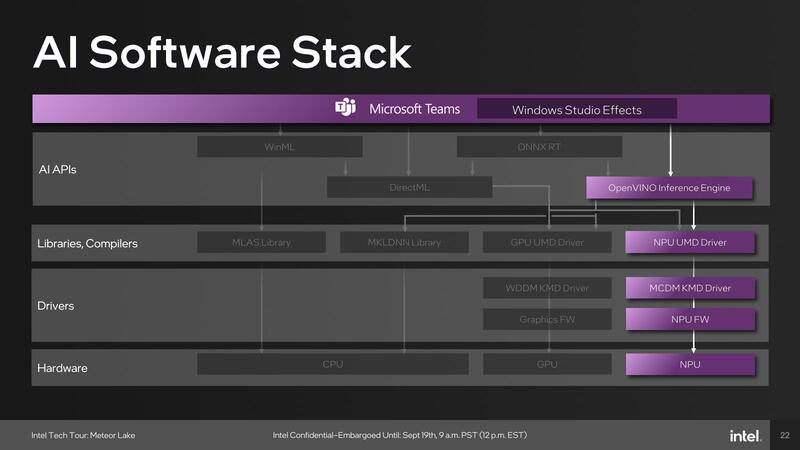
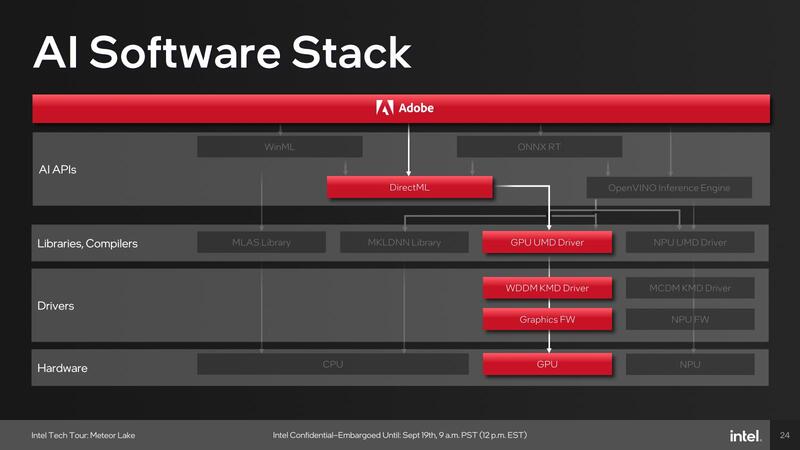
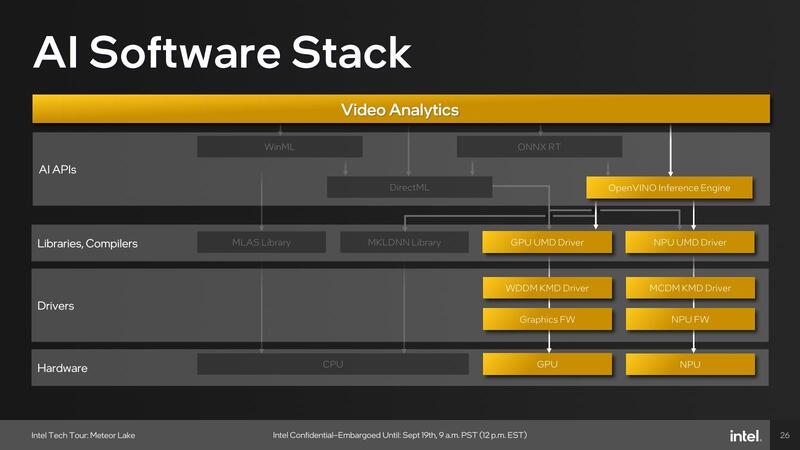
WinMLが全然ないのは、デフォルトCPUでの処理だから遅くて使い物にならないし、GPUなどを使うならDirectMLで十分、というあたりが理由であろう。
そのNPUの性能であるが、Stable Diffusion v1.5を使っての結果が示された。
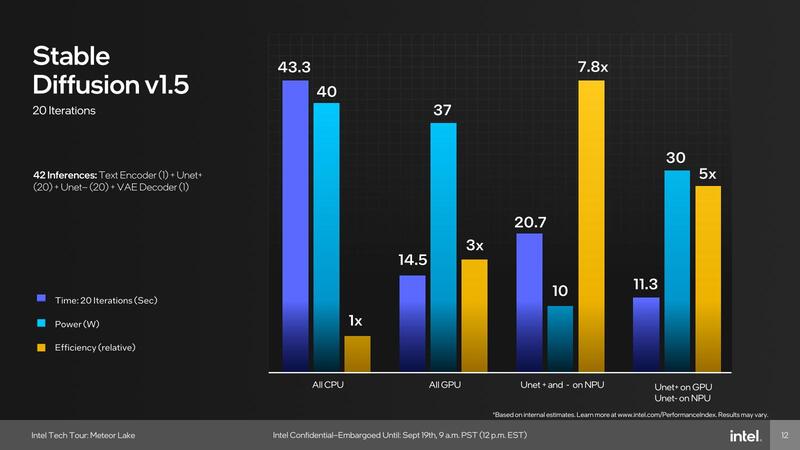
比較は以下の4パターンで、処理性能(というか所要時間)と消費電力、効率を示したものだ。
- すべてCPUで処理
- すべてGPUで処理
- Unet+とUnet-をNPUで処理(その他はCPU)
- Unet+をGPUで、Unet-をNPUで処理(その他はCPU)
おもしろいのは、絶対性能という意味ではGPUとNPUの併用が最高速で、次いでGPUのみとなり、NPUを使った場合はCPUの半分程度の所要時間でしかない。つまりピーク性能そのものはStable Diffusionの結果だけで言えば、NPUの性能はGPUの7割程度に過ぎない計算で、それほど高いものではない。
ただし消費電力はNPUのみの場合が圧倒的に少なく、GPUを使うと相応に増える。要するにNPUは性能/消費電力比を高く取るような構成になっているわけだ。この理由の1つは、NPUがSoCタイルに搭載されていることもあるだろう。
SoCタイルはなるべく省電力になるように構成されており、ピーク性能を追求するような実装にはできない。そうした構成はGPUタイル(TSMC N5)の方が得意である。なので「(ACアダプターをつないだ環境での)性能優先ならGPU、(バッテリー駆動での)性能/消費電力比優先ならNPU」といった使い分けになるものと考えられる。


この記事に関連するニュース
-
M4 Maxチップ搭載「16インチMacBook Pro」の実力をチェック 誰に勧めるべきモデルなのか?
ITmedia PC USER / 2024年12月6日 12時35分
-
Thunderboltに無線LAN、10GbE対応の最新デスクトップPC「DAIV FX-I7G7S」を試す
ITmedia PC USER / 2024年12月4日 17時0分
-
AI処理速度やカメラ機能のレベルアップに注目! M4プロセッサー搭載の最新「iMac」 を5つのポイントでチェック【2024年12月版】
Fav-Log by ITmedia / 2024年12月2日 6時10分
-
ハイエンドスマホ向け新型SoC「Snapdragon 8 Elite」にみるAI半導体の進化
ITmedia PC USER / 2024年11月28日 19時40分
-
Lenovo「Yoga Slim 7i Aura Edition Gen 9」レビュー、Core Ultra 7 258V搭載で出先での作業にも最適なノートPC
マイナビニュース / 2024年11月25日 22時22分
ランキング
-
1「これはアウトやろ」 主催フェス事故で“客5人負傷”、人気バンドの告知動画が物議…… 事務所は謝罪
ねとらぼ / 2024年12月23日 18時23分
-
2にじさんじ運営、代理人弁護士を名乗る不審なメールに注意喚起…怪しいメールアドレスを公開、名指しで警戒を呼びかけ
インサイド / 2024年12月23日 16時15分
-
3ゲームボーイ世代直撃な縦型Androidデバイス「AYANEO POCKET DMG」を試す
ITmedia PC USER / 2024年12月23日 17時50分
-
4レーザーVS稲妻、どっちが破壊力が強いか はじけ飛ぶ水晶、爆発するスイカ、前代未聞の“7番勝負”が「すごかった」
ねとらぼ / 2024年12月23日 21時0分
-
5『ドラクエ』大人になって分かる「こいつはいけねぇ」NTR展開 夜の寝室にご注意
マグミクス / 2024年12月23日 21時5分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください






