

Meteor LakeのGPU性能はRaptor Lakeの2倍 インテル CPUロードマップ
ASCII.jp / 2023年10月16日 12時0分

今回でMeteor Lakeの話はいったん終了である。残るのはGPUとSoCまわりとなる。まずはGPUから説明しよう。
Xe-LPGはXe LPの強化版? Xe LPと比較して2倍の性能と言うけれど……
Meteor Lakeに搭載されるGPUはXe-LPGとなる。Raptor LakeまでのGPUはXe LPベースであり、その意味では新アーキテクチャーの搭載になる。
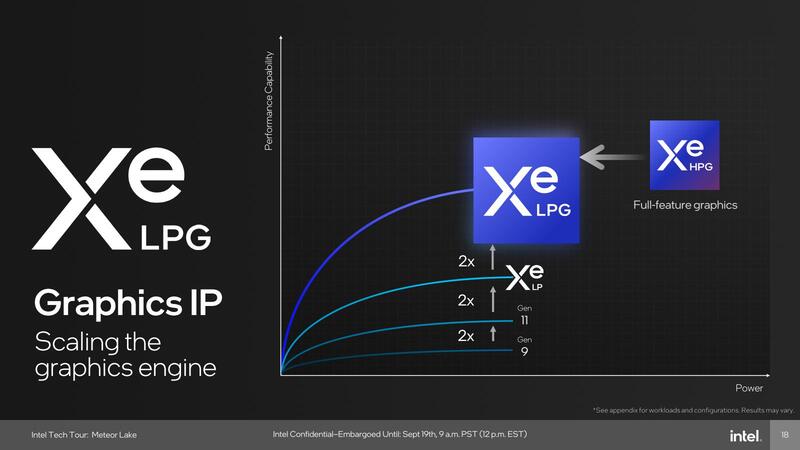
Xe LPGは連載579回のロードマップには存在しない。構造的にはXe LPの強化版というよりはXe HPGの低消費電力向けという扱いになるかと思われるのだが、インテル的にはXe LPの強化版という説明の仕方をしている。
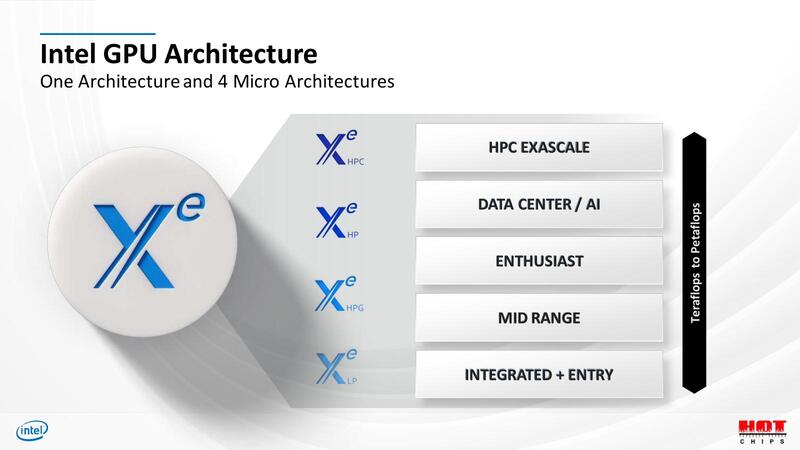
Xe LPとXe LPGの違いは、以下の3つが挙げられている。
- より高い動作周波数での駆動
- より規模の大きな構成が可能
- アーキテクチャー的な効率向上
まず動作周波数が下の画像で、同じ動作周波数ならより低い電圧で動作するし、同じ電圧ならはるかに高い動作周波数まで稼働するとしている。
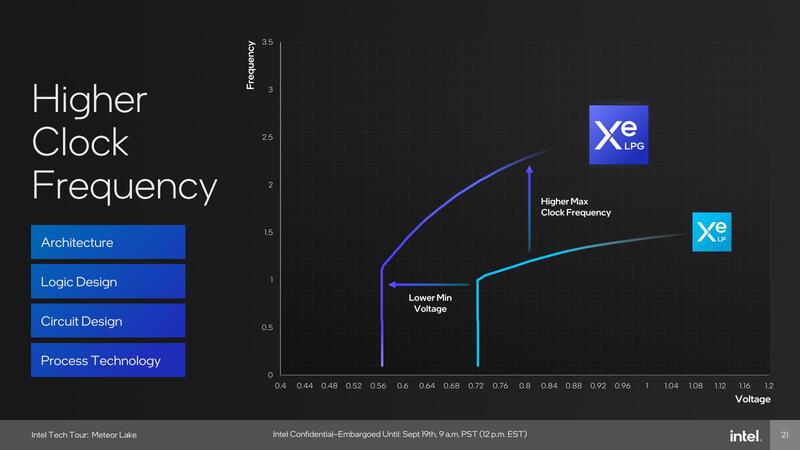
リファレンスになるのはRaptor Lakeあたりだろうから、例えば「Core i9-13900HK」を例に取ると、GPUは最大1.5GHz駆動である。ここから考えると、Xe LPGでは最大2GHz位まで動作周波数を引き上げ可能(実際に2GHzまで行くかどうかは不明)だし、ベースとなる1GHzであれば電圧を0.78倍に落とせるので、それだけ省電力になる可能性が高い。ちなみにこれはアーキテクチャー云々というよりも、Intel 7を使うXe LPとTSMC N5を使うXe LPGの違いだと思われる。
次が構成そのものの大型化である。従来のXe LPは最大でも96EU構成であったが、Xe LPGでは128EU構成(Xe LPGの用語なら128XVE)まで拡大できるとしている。EUの中身はこの後説明するとして、EU数で1.33倍、ジオメトリー・パイプラインが2倍、サンプリング/ピクセル バックエンドがそれぞれ1.33倍、そして従来は未サポートだったレイトレーシング・ユニットを搭載している。

レンダースライスの数で言えば3分の2になる計算だが、個々のレンダースライスの性能が大きく上がっている。大規模なGPUであれば、複数のタスクを並行して動かす場合の粒度が下がるので不効率という可能性もあるが、このクラスのGPUであればこれによるデメリットはないと考えていいだろう。
最後がアーキテクチャーそのものである。Xeコアの構造は下の画像のとおり。1つのXeコアに16個のXVE(Vector Engine)とロード/ストアー・ユニット、それとキャッシュが搭載される。

Xe LPの場合と比較すると、サンプラー/メディアサンプラーがXe Coreの外に追いやられている。ではそのXe LPGのXVEは? というのが下の画像だ。

Xe LPのEUの構成は連載579回で示したとおり以下の構成だった。
- INT/FP共用となる8-wideのVector SIMDが搭載
- INT8でDP4Aにも対応
それに対し、XVEでは以下のようになっている。
- INT/FPそれぞれ別に8-wideのVector SIMDが搭載
- FP64のEngineも搭載
- EM(Extended Math)の数は変わらず
このINTとFPのVector SIMDは同時に実行が可能であり、絶対的な演算性能で言えばXe LPGのXVEはXe LPのEU比で2倍の処理性能を誇ることになる。記事冒頭の画像に出てきた2倍というのはこのことで、確かに嘘ではない。
嘘ではないのだが、INTとFPを同時に動かすという状況がどの程度あるのかという疑問は当然出てくる。常時こうした処理があれば、確かに実効性能は2倍になるだろうが、INTのみやFPのみであれば実効性能は変わらないからだ。
また新たにFP64の演算器が搭載されたのも目新しいが、これはHPC用途向けならともかく、Xe LPGにわざわざ搭載した理由が思いつかない。科学技術計算をやらせる(Meteor Lakeをモバイル・ワークステーション的な用途で使う)ケースはあるだろうから無意味ではないが。
XVE数は128なのでFP64では128Flops(MAC演算が可能なら256Flops)。1GHzなら256GFlops、2GHzで512GFlopsになるので、CPU側でAVX256(FP64で最大16Flops/サイクル、Pコアが最大5GHzで動いたとしても80GFlops)を使うよりはるかに高速ではあるのだが、ローパワー向けのGPUにしてはやや無駄な気もしなくはない。
INTユニットにDP4Aの演算エンジンを搭載 回路規模を小さくでき省電力化にも貢献
ところでMeteor Lakeの技術解説記事でKTU氏も触れていた話だが、Xe LPGではINTユニットにDP4Aの演算エンジンが搭載されている。このあたり少し経緯が複雑なのだが、もともとXeの基本的なコアは、Xe LPG同様にIntとFPが別々に設けられ、さらにFP64やXMXなどがオプションで追加可能な構成になっている。
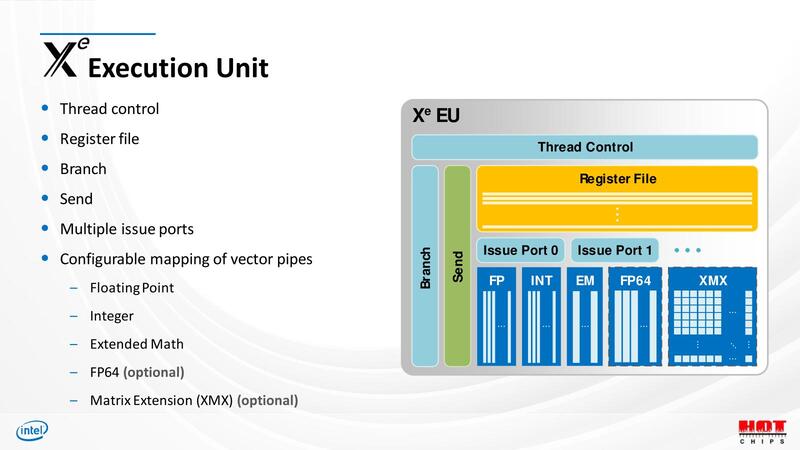
DP4Aのエンジンは本来はXMX(Matrix Extension)に含まれるもので、実際Xe HPGを搭載するIntel ArcではXMXでDP4Aの処理をしている。ただXe LPやXe LPGではXMXが搭載されない。そこでXe LPではIntのVector SIMDエンジンにDP4Aの処理機能を搭載している。これをXe LPGも継承した格好だ。

この方式は、Xe HPGを搭載するIntel Arcに比べると回路規模をはるかに小さくでき、省電力化にも適している。その一方で例えばXeSSを使う場合には、XeSSと描画の両方でXVEのInt側のVector SIMDを取り合うことになる。つまりXeSSを利用すると本来よりも描画性能が落ちることになってしまうわけで、XeSSの品質と描画性能のバランスをどのあたりで取るか、考えどころである。
そうは言っても所詮は内蔵GPUなので、ディスクリートGPUほどの描画性能はそもそも発揮できないし、フルHD程度の画面でプレイする限りにおいてはそこまでクリティカルに描画性能が効いてくることもない(XeSSを前提にすれば、描画サイズはSDないし1600×900ピクセル程度で、これをXeSSでフルHDに拡大するといったあたりだろうか?)ことを考えれば、これで十分という判断かもしれない。
そしてゲーム以外でDP4Aを使うケース(例えば画像加工)もあるから、この場合はGPUをフルにDP4Aの処理に回せるわけで、このあたりがバランスとしては落としどころになるのだろう。
ちなみに他の機能としては新たにアウト・オブ・オーダー・サンプリングが追加されたとあるが、こちらの詳細は不明である。

Meteor Lakeの演算性能は Raptor Lakeの約1.78倍
また性能は、まだIntel Core Ultraの詳細なSKUが不明なのでなんとも言い難いのだが、1つ目安としてRaptor Lakeと比較した数字がある。それが下の画像だ。
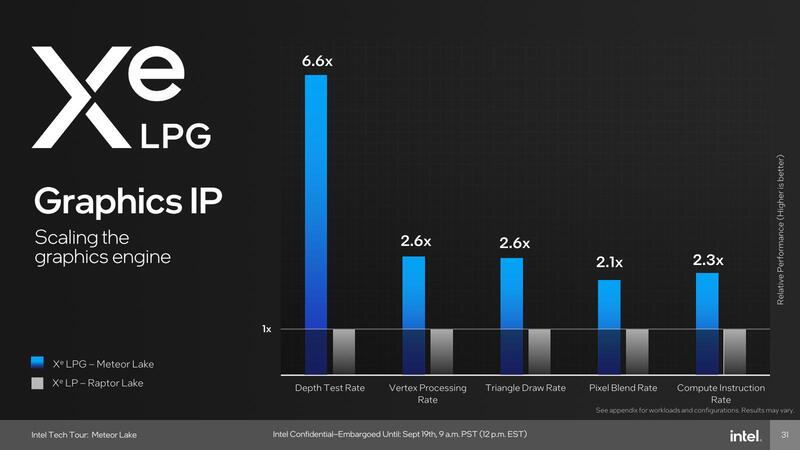
単純に考えると、動作周波数が1.5GHz→2GHzに上がり、96EU→128XVEなので、演算性能そのものは1.78倍ほどになる。これがそのままゲームのフレームレートに直結するわけではないにせよ、相応に性能は強化されたと考えて間違いではないだろう。
ただ所詮は内蔵GPUであり、メモリーはCPUと共用の形になるため、ここがボトルネックになるわけで、ディスクリートGPUとは比較にならない。とはいえ、Intel Arcで言えばA380が比較的構成としては近いので、これにどの程度肉薄できるかは実際に比較してみたいところだ。
ちなみにその他の構成はIntel Arcにほぼ等しい。メディアエンジンはAV1のエンコード/デコードをサポートしているし、ディスプレーは最大4ポート(うち2ポートは内蔵LCD向けの省電力機能を搭載)構成となっている。

動画の再生はSoCコアだけで可能
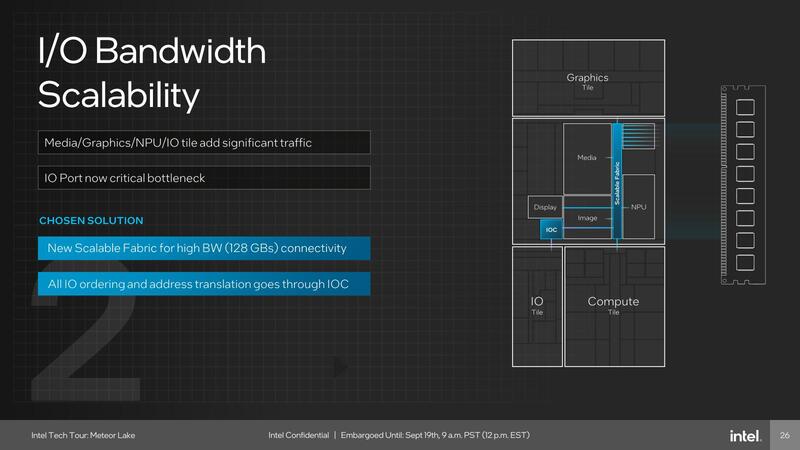
一方でSoCコアであるが、内部は少しおもしろい。インターコネクトは2種類あり、NOC(Network On Chip)はキャッシュ・コヒーレントなファブリックで、これはCPUコアとGPUコア、およびSoC内のLP Eコアやメディアエンジン、ISPなどを相互接続している。
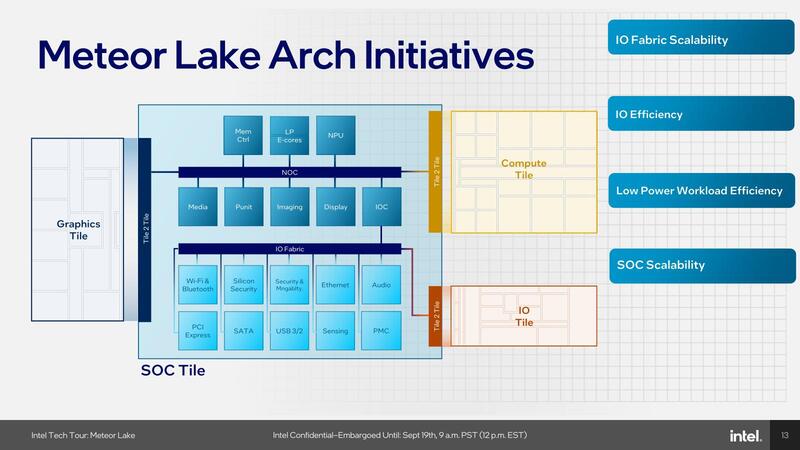
このNOCの右端にあるIOC(IOコントローラー)を介して2つ目のIOファブリックが接続されている。こちらはキャッシュ・コヒーレントではなく、かつPCI Expressのプロトコル(論理層のみ:物理層は独自)を介して周辺機器やIOタイルと接続される格好になっている。
この結果、例えば動画の再生は本当にSoCコアだけでまかなえることになり、コンピュートやグラフィックス、IOの3つのタイルは(極端に言えば)電源を落とすことも可能である。
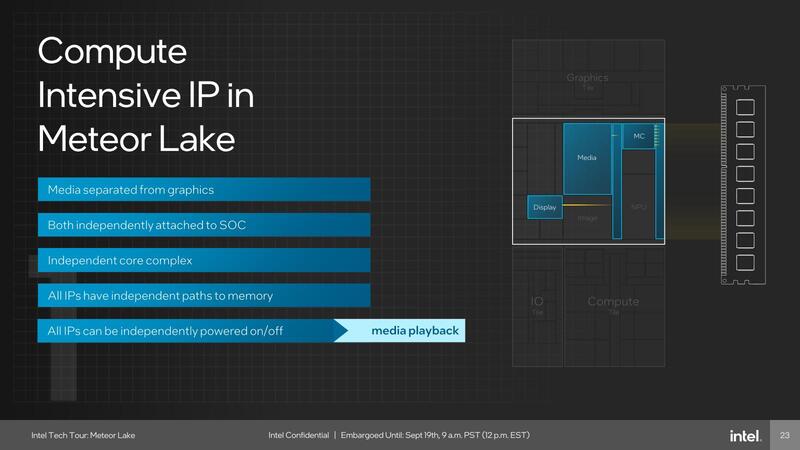
ちなみにNOCは128GB/秒もの広帯域であり、消費電力的にイマイチと思わなくもないのだが、仮にLPDDR5X-6400をサポートしたとすると帯域は1chあたり51.2GB/秒。2chで100GB/秒に達するわけで、確かにこのくらいの帯域がないと持たないのかもしれない。
また電力管理は、SoCタイルのPUNIT(Power Unit)が全体の管理を行ない、それぞれのタイルに用意されたPMIC(Power Management IC)に制御を送る形で実装されている。
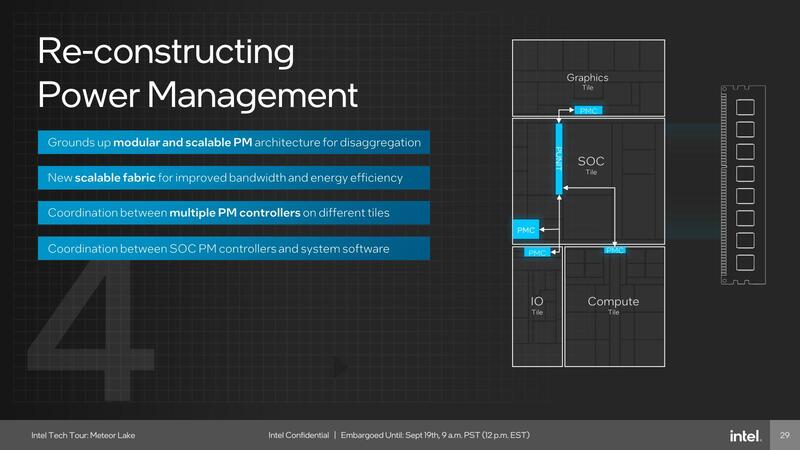
1つ不明なのは、VRMはどうしたのか? である。インテルはかつてFIVR(Fully Integrated Voltage Regulator)をHaswell世代で導入しつつ、Skylake世代で諦めた。理由は省電力動作時に効率が上がらないからで、ところがIce Lake世代ではMIA(Magnetic Inductor Arrays)を利用する形で再びパッケージ上にVRMを実装している。
VRMにはインダクター(コイル)が必須で、ところがHaswell~Skylake世代ではチップ上にインダクターを構成しても容量が非常に小さく、VRM内のスイッチング速度を高くできない結果、低負荷時の効率が悪いというのがSkylake世代の問題であり、MIAはインダクターの中に磁石を仕込むことで容量を大きくして、スイッチング効率を引き上げたという仕組みである。
ただこれは従来型のパッケージでは基板の裏にMIAを配することで対応できたが、Meteor Lakeの場合はCPU/GPU/IO/SoCの各タイルの下にはベースタイルが配される格好になる。

そのベースタイルの下にMIAを仕込むつもりなのか(写真を撮りそこなったが、確かMeteor Lakeのパッケージの裏側は全面ボールだった気がする)、それともベースタルの中に仕込むのか(これは難易度が高そう:厚みがMIA並みになる)、それともFIVRはMeteor Lakeの世代では諦めるのか、このあたりは現状不明なままである。後は製品が出るまでこれ以上細かい情報は出てこなそうである。
デスクトップ向けMeteor Lakeは LGAのソケットではなくNUCなどの組み込み向け
ちなみにPCWorldのインタビューの中で、Michelle Johnston Holthaus氏(EVP&GM, CCG)が「デスクトップ向けのMeteor Lakeが2024年に出る」(6分33秒付近)と喋ったことでやや騒ぎになったが、これはデスクトップといってもNUCの類の超小型デスクトップの話で、いわゆるLGAのソケット装着タイプの話ではない。
こちらの方は以前KTU氏も触れていたがRaptor Lake-Sのリフレッシュになる予定であり、自作PCユーザーにMeteor Lakeは(Ice LakeやTiger Lake同様)やや縁遠いものになりそうだ。

この記事に関連するニュース
-
Lunar LakeではEコアの「Skymont」でもAI処理を実行するようになった インテル CPUロードマップ
ASCII.jp / 2024年7月8日 12時0分
-
「Lunar Lake」Deep Diveレポート - 【Part 2】Memory、GPU、NPUについて
マイナビニュース / 2024年7月4日 14時23分
-
「Lunar Lake」Deep Diveレポート - 【Part 1】P-Core&E-CoreとPackageについて
マイナビニュース / 2024年6月29日 12時31分
-
Intel Tech Talkで見えたLunar Lakeにおける低消費電力と高性能の両立へのこだわり
マイナビニュース / 2024年6月27日 6時45分
-
Lunar Lakeはウェハー1枚からMeteor Lakeの半分しか取れない インテル CPUロードマップ
ASCII.jp / 2024年6月24日 12時0分
ランキング
-
1「赤ちゃんのお世話がしたいニャ!」ベビーサークル越しに愛を訴える猫ちゃん
おたくま経済新聞 / 2024年7月8日 7時0分
-
2一度植えたら、自動で増殖&毎年収穫を目指せる野菜5種とは? 自然農のエキスパートが伝授する方法に反響
ねとらぼ / 2024年7月8日 9時0分
-
3「どう見てもセガのアレ」 コンビニうどんの容器トレーが「圧倒的既視感」「コントローラーの抜け殻」と話題
ねとらぼ / 2024年7月7日 17時0分
-
4モトローラが日本市場で急成長している理由 1年で出荷台数2倍以上、「edge」「razr」の販路拡大がカギに
ITmedia Mobile / 2024年7月6日 11時45分
-
5「わろてる」 人気VTuberが部屋で“でかめのやらかし”をした様子を公開し話題に 「どうなってんのこれw」「想像以上」
ねとらぼ / 2024年7月7日 18時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください






