

TOP500の1位に惨敗したスパコンAuroraの真の性能 インテル CPUロードマップ
ASCII.jp / 2023年11月20日 12時0分

先週の続きで今週もRISC-Vの話をするつもりだったのだが、SC23がコロラド州デンバーで開催され、これにあわせてTOP500のリストも更新された。ということで長らく懸案になっていたAuroraがついにランクインしたため、急遽予定を変更してこちらを解説する。

AuroraはTop500のランキング2位 トップを維持したFrontierの半分の性能
Auroraは今年5月に行なわれたISC 23のタイミングでは、スパコン性能ランキングとなるTOP500にまだエントリーしなかったという話は連載723回で説明したとおりである。今回はきちんとエントリーされたので、分析の前にまずは結果から伝えよう。
そのAuroraであるが、ランキング2位である。下の画像はTop 4までの抜粋であるが、ラフに言ってトップを維持したFrontierの半分の性能しかない。それでもやはり今回新規にランクインしたマイクロソフトのEagleを上回る数字だし、富嶽の性能は抜いているので、それなりに面目は立ったと言えなくもないが、いろいろな意味で問題がありすぎる。
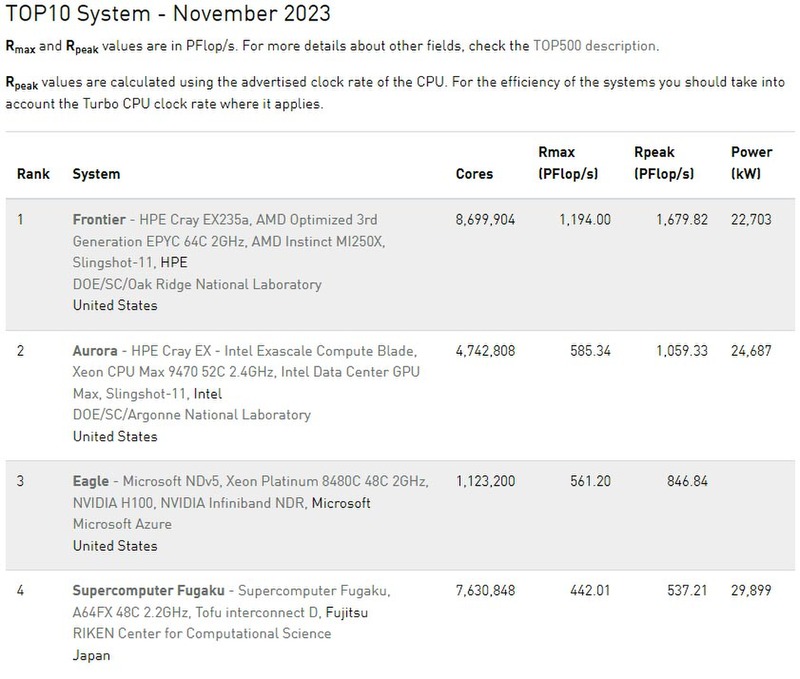
ちなみにこの585.34PFlopsという数字、Ian Cutress博士によれば「システムの半分を稼働させている」のだそうだ。後で数字を検討するが、コア数やRpeak(理論性能)が明らかに所定のものと異なっている。したがって、フルシステムではもう少し性能があがり、1170PFlops程度になるものと思われる。それでもFrontierには届かないのだが。
Aurora isn't #1. The PF for power isn't good. This int a full system run, I think he said half with little optimization. Still expecting 2EF when full #Top500#SC23#iamhpcpic.twitter.com/BOW4sXwylc
— 𝐷𝑟. 𝐼𝑎𝑛 𝐶𝑢𝑡𝑟𝑒𝑠𝑠 (@IanCutress) November 13, 2023
さて、インテルはプレスリリースで第2位になったことをアピールしているが、控えめに言っても結果は大惨事である。具体的に言えば以下のとおり、もうなにから手を付けて良いのか、という感じではある。
(1) 7月の時点で75%の機材が最終構成に合わせて更新されたにもかかわらず、いまだにフルシステムでの稼働ができていない。 (2) 半分のシステムにもかかわらず、この時点で消費電力は24.6MWに達している。 (3) 半分のシステムで理論性能は1059.33PFlopsなのに、実効性能はたったの585.34PFlopsに過ぎない。
システムの稼働率は51.2%ほど 稼働率100%での性能は2069.11PFlops
もう少し細かく見ていきたい。まず(1)の「いまだにフルシステムでの稼働ができていない」である。Auroraの場合は1つのノードにXeon Max×2とData Center GPU Max×6が搭載される。以前の推定では、Xeon Max 9480とData Center GPU Max 1550が搭載されているのではないかとしたのだが、実際の詳細を見ると、CPUは52コアのXeon Max 9470が搭載され、動作周波数は2.4GHzになっていた(これは一覧のページには掲載されていないが、TOP500の結果をcsvファイルでダウンロードすると明記されている)。
一方のGPUの方はData Center GPU Maxとだけ記載されている。Data Center MaxはIntel Arkに掲載された128コアの1550以外に、112コアのData Center Max 1350が存在することがわかっている。ノード数を計算すると以下のとおりだ。
これを見る限りはData Center GPU Max 1550を採用していると考えるのが普通だろう。総ノード数1万624に対して5439ノードなので、51.2%ほどのノードが稼働している計算になる。これは「ざっくり半分」としてしまって問題ないだろう。1350を使った場合は約6111.9ノードというのは58%ほどに相当するため、半分よりはやや多く「6割程度」と表現すべきなのがこの傍証である。
さて、では5439ノードが稼働しているという前提のもとに理論性能を計算してみる。Xeon Max 9470は2.4GHz駆動であると示されているので、こちらはXeon Max 1個あたり1996.8GFlops。不明なのがData Center Max 1550の動作周波数で、連載723回で試算したようにBase 900MHz/Max Dynamic 1.6GHzで演算性能はそれぞれ29491.2GFlops/52428.8GFlopsという数字になる。
AuroraはRpeakが105万9325.75TFlopsとされているので、ノードあたりで言えば194.76TFlopsほど。ここから計算すると、1GHzにやや満たない970MHzで194.70TFlopsほどになる。おおむねこのあたりが動作周波数として設定されていると考えて良さそうだ。
意外に低めという見方もあるが、動作周波数を上げると簡単に消費電力が増えてしまい、さらに発熱も増えるので長時間の連続稼働が厳しくなる。なるべく低めに抑えて長時間動作を可能にするのが狙いだろう。これはFrontierも同じ、という話は連載670回で説明した。
ちなみにここまでの推定が正しいとすると、フルノードで稼働した際のAuroraの理論ピーク性能は2069.11PFlopsになり、一応2EFlops超えを果たす。連載723回では「実質2EFlops」と書いたが、実際にはもっと低めに抑えられていたわけだ。インテルの公約は「今年サービス開始されるAuroraは、『ピークの』倍精度浮動小数点演算性能が2EFlopsを超える」だったので、嘘はついていないことになる。
それにしても、なぜまだ半分しかシステムが稼働できないのか? に関する説明はインテルからもその他の筋からも今のところ流れて来ていない。あるいはハードウェアではなくソフトウェア側の問題なのかもしれない。
フルシステムの消費電力は 39.5MW~42.0MW程度か
次が(2)の「半分のシステムで消費電力が24.6MWに達する」問題。冒頭に引用したCutress博士のPostにもあるが、このシステムではコンピュート・ノードこそ半分しか稼働していないものの、その他(ストレージや管理システム、ネットワーク、水冷システムや空調)などはフル稼働している状態での数字だそうである。それでも24.7MWというのはかなり大きいのだが、だからといってフルシステムで倍になるわけではない、という話である。
連載635回でThomas Sterling教授が示したスライドでは1EFlops以上を60MW以下、という数字だったからこれよりはマシではある。マシではあるのだが、Top 10での性能消費電力比を示したのが下表である。
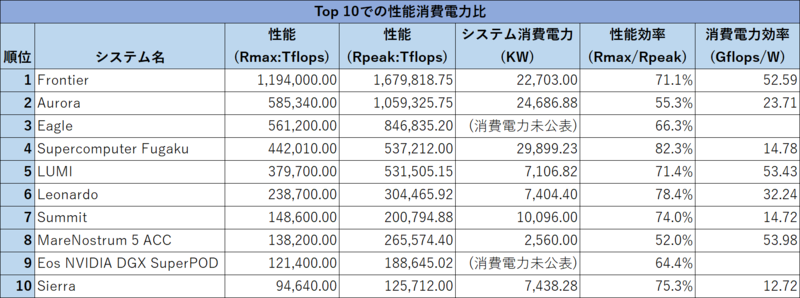
2018年に初登録されたSummitやSierra、あるいは完全なCPUのみの構成なので性能/消費電力比が低めの富嶽には勝っているものの、昨年11月に稼働したイタリアのLeonardo(今回6位:ちなみにXeon Platinum+NVIDIA A100の構成)にも負けているのは少しいただけない。Frontierと比較すると半分以下でしかない。
加えて言えば、このTop 10で最高効率なのは8位のMareNostrum 5 ACCだが、Xeon Platinum 8460YにNVIDIA H100を組み合わせている構成であり、別にSapphire Rapidsに問題があると考えるのは早計だろう。
ではAuroraがフル稼働するとどの程度の消費電力になるかを考えていこう。Cutress博士はもう少し細かい考察をすでに掲載しており、コンピュート・ノード以外の消費電力が2~4MWだとするとフルシステムでは36MW/EFlops程度とかなり数字が悪いが、これが8~10MWクラスだとすると効率は22MW/EFlopsになり、Frontier(19.0MW/EFlops)に近づくとしている。
ただこの計算、Frontierの方もインフラとコンピュート・ノードの数字を分けて計算する必要があるわけで、同じ算出方法だと仮にインフラを8MWとすれば17.3MW/EFlops程度になることを考えると、まだ差は大きいように思う。
話を戻すと、フルシステムの消費電力を推定するには、そうしたインフラの分をある程度考慮する必要がある。筆者はフルシステムでは2倍よりずっと低い、1.6倍~1.7倍程度と想定している。つまり39.5MW~42.0MW程度だ。性能はノード数に直線的に比例すると仮定すると1143TFlopsほど。効率は27.2~29.0GFlops/W程度に収まると想定している。60MWよりだいぶ低いだけでもマシではないかと思う。
性能効率が低いのはノード数の多さが原因 最適化もできていない
それより問題が(3)の「実効性能はたったの585.34PFlopsに過ぎない」である。この性能効率の低さが実はシステム的に最大の問題かもしれない。表の性能効率を見ていただくとわかるが、Auroraより低いのはMareNostrum 5 ACCのみである。もちろん例えばSummitも、現在は74%と結構高い効率を実現しているが、2018年6月に初エントリーした時にはRpeak 187.66PFlops/Rmax 122.30PFlopsで効率は65.2%だったので、この5年間で10%以上効率を改善したわけで、まだ性能の伸びしろがあるという見方もできる。
ただこのAuroraの55.3%という数字、理論性能が3TFlopsなのに実効性能が1608GFlopsで効率53.6%だったASCI Blue Mountainを思わず彷彿してしまう。TOP500の上位100システム内で見ても85位という低い効率だ。
ではなにが悪いのか? Xeon Maxか、Data Center Maxか、ネトワークか、という話で言えばまずネットワークはFrontierと同じHPEのSlingshot-11なのでこれは無罪。Xeon Maxというより広義のSapphire Rapidsという意味ではTop 50の中に2/3/8/9/15/19/24/34/41位の9システムがランクインしており、例えば19位のMARENOSTRUM 5 GPPはXeon Platinum 8680+のみの構成だが性能効率はなんと86.48%(Rpeak 46.37PFlops/Rmax 40.10PFlops)なのでSapphire Rapids自身も無罪。
ではHBMを実装したXeon Maxは? というとこちらはAurora以外に24位のCrossroadsと196位のClementina XXIの3システムだが、CrossroadsがRpeak 40.18PFlops/Rmax 30.03PFlopsで74.76%、Clementina XXIも5.99PFlops/3.88PFlopsで64.7%とそれなりに高めなので、HBMのメモリー容量不足でXeon Maxがボトルネックというわけでもなさそうだ(少なくともそれを回避する方法はちゃんとあるのは間違いない)。
ではData Center Maxが戦犯か? というと、それも怪しい。今回だとAurora以外に41のDawnとClementina XXIの3システムがData Center Max GPU 1550を実装している。このうちDawnはRpeak 53.85PFlops/Rmax 19.46PFlopsで実に36.1%という凄まじい効率を叩き出しているが、Clementina XXIは上に書いたように64.7%なので、優秀とまでは言わないもののそこまで悪くはない。
ただClementina XXIはそもそも小規模なシステム(Rpeakが5990.87TFlopsなのでAuroraの176分の1の規模である)ことを考えると、この性能の低さはノード数が多いことに起因しているのでは? という気もしなくはない。
全体的に言って、Auroraはまだ最適化がかなり足りない気がする。ただこれをどう改善できるのか? というとかなり難しそうにも思える。最大のネックはとにかくノード数が多すぎることだ。これはFrontierも同じで、以前連載670回で触れたように、9248ノードのFrontierの初期構成の効率は65.4%で、一方128ノードのFrontier TDSの効率は83%に達している。
なにもしなくてもノード数が少なければ、それだけで効率は上げやすい。ちなみにFrontierは今年6月の時点で少し構成を変えており、現在コア数は869万9904個。ノード数は9216個に増えている。にもかかわらずRpeakは1685.65PFlopsから1679.82PFlopsに微減しており、ところがRmaxは1194.0PFlopsと8%ほど向上している。
消費電力は2万1100KWから2万2703KWにやや増えているが、電力効率は52.23PFlops/MWから52.59PF/MWに多少改善しているあたり、おそらくはノード数の追加に合わせて全体的にさらに動作周波数を下げ、効率を引き上げたものと思われる。
こうした改良を今後インテルとHPE、アルゴンヌ国立研究所は共同で行なっていく必要がありそうだ。ただそれをやって、さらに全ノードを利用可能にしても、その頃にはEl Capitanが投入されると予想されているわけで、AuroraがTOP500の1位を取るのはかなり難しそうである。
※お詫びと訂正:記事の一部に誤記がございました。訂正してお詫びします。(2023/11/22 16:00)

この記事に関連するニュース
-
Intelの「Gaudi 3」って何? AIアクセラレーターとGPUは何が違う? NVIDIAやAMDに勝てる? 徹底解説!
ITmedia PC USER / 2024年7月5日 17時5分
-
Intel Tech Talkで見えたLunar Lakeにおける低消費電力と高性能の両立へのこだわり
マイナビニュース / 2024年6月27日 6時45分
-
NTT開発のアルゴリズム、スパコン「富岳」の大規模グラフ探索性能を約20%向上
マイナビニュース / 2024年6月25日 15時51分
-
【Gaudiシリーズを解説】生成AIに対し、広がる選択肢―Fugaku-LLMも快適に動作
マイナビニュース / 2024年6月18日 11時0分
-
SuperMicroのCEOが語ったこれからのデータセンターサーバーの方向性 - COMPUTEX 2024基調講演
マイナビニュース / 2024年6月12日 6時30分
ランキング
-
1「鳥肌たった」「これこそアート」 SNSで約13万いいねを集めた1枚のイラスト、衝撃の種明かしに反響 作者に制作経緯を聞いた
ねとらぼ / 2024年7月6日 12時30分
-
23月末にコンビ解散したお笑い芸人、「また美人になった?」「見るたびにキレイになってく」と反響
ねとらぼ / 2024年7月5日 18時37分
-
3「マナー守れないなら釣りやめろ」テグス被害に遭った鳥のショッキングな姿に「胸が苦しい」 注意喚起に賛同の声続々
ねとらぼ / 2024年7月7日 6時30分
-
4Ryzen 5 8600Gを標準搭載する1.92LのBTO PC、超小型PCの決定版になりそう
ASCII.jp / 2024年7月7日 10時0分
-
5「これはやばいw」 モスバーガーの“狂気のLINEスタンプ”が話題 公式も認める異様な絵面に「夢に出てきそう」
ねとらぼ / 2024年7月6日 17時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください







