

生成AI向けGPU「Instinct MI300X」はNVIDIAと十分競合できる性能 AMD GPUロードマップ
ASCII.jp / 2023年12月11日 12時0分

AMDは米国時間の12月6日に、"Advancing AI"イベントを開催し、ここでいくつかの新製品や新情報を発表した。タイトルのとおりAIに絡んだ話ではあるが、そのAI向けの新CPUなども一緒に情報解禁されたので、このあたりをまとめて解説しよう。
"Hawk Point"ことRyzen 8040シリーズを発表 Meteor Lakeを牽制か?
まずはクライアント側であるが、Hawk PointことRyzen 8040シリーズが発表された。


そのSKUだが、上の画像ではわかりにくいので、ここに出てきていないベースクロックを追加したうえでSKU別に並べなおしたのが下表である。
Phoenixこと7040シリーズと比較した場合、若干SKUの数が増えているように見えるのだが、よく見ると例えばRyzen 7 8840HSとRyzen 7 8840U、あるいはRyzen 5 8640HSとRyzen 5 8640UはデフォルトTDPまで含めてスペックが同一(28W)で、cTDPの範囲がUは15~30W、HSは20~30Wなのが唯一の違いである。
Ryzen 7040HSシリーズの場合、デフォルトTDP/cTDPともに35~54Wだったので、これは型番だけHSを付けているものの、実質的にはHSシリーズを減らしたようなものである。一応まだ35~54W枠(デフォルトTDP:45W)の製品も3つ残ってはいるが、これは今のところHSシリーズの売れ行きが今一つということなのかもしれない。
話を戻すとコア数や動作周波数、GPUの動作周波数なども7000シリーズと8000シリーズでは完全に同じ構成であるのが表からわかる。ではなにが違うのか? というとRyzen AIの性能で、7000シリーズはRyzen AIの性能が10TOPSなのに対し、8000シリーズは16TOPSになっている。

要するにNPUの性能の底上げが最大のポイントである。実際イベントの中ではこれに合わせ、マイクロソフトがCoPilotなどでこのNPUを利用することを発表しており、NPUの性能が差別化要因になることをアピールした。

問題はこのNPUの性能底上げをどうやって実現したか、である。今年1月のCESでPhoenixが発表されたときのダイレイアウトと、今回発表されたRyzen 8040シリーズのダイレイアウトがまったく同じであり、そう考えるとNPUのエンジンそのものを1.6倍に増やしたという可能性は非常に低い。普通に考えて、NPUの動作周波数を1.6倍に上げたのだろう。要するにHawk PointはPhoenixのリフレッシュ版で、NPUだけ動作周波数を上げたものと考えればいい。


なぜこのような製品を今発表したか? というのもわかりやすく、Meteor Lake登場前の軽いジャブみたいなものだろう。Meteor LakeもやはりNPU性能を売りにしているという話は連載740回で説明した通りであり、これに対する軽い先制攻撃といったところか。
ただ本命はこれに続くStrix Pointの方であり、こちらはHawk Point比で3倍のNPU性能となるXDNA2が搭載されると説明されている。現時点ではどんな構成になるのかは明らかにされていない。登場時期は2024年中とだけ説明されているが、その2024年中にインテルはMeteor Lakeに加えてArrow Lakeも投入予定なだけに、具体的な登場時期が気になるところだ。
動作周波数が2.1GHz程度になるであろう AMD Instinct MI300X
Ryzen 8040シリーズはいわばオマケで、本題はInstinct MI300XとInstinct MI300AがNVIDIAのH100やGH200と十分競合できる製品であることをアピールすることだった。まずはInstinct MI300Xについて説明しよう。
MI300Xの構造は連載726回で説明しているが、4つのIODの上に8つのCDNA 3ダイ(XCD)が載り、さらにそれぞれのIODに2つづつHBM3 スタックが接続される構造である。

この構造であるが、今回以下のことが示された。
- IODは合計256MBのインフィニティ・キャッシュを搭載する。つまりIODあたり64MBとなる。
- XCDは合計で304XCUを搭載する。つまりXCD 1個あたり38XCUという計算になる。
- HBM3の合計帯域は5.3TB/秒になる。

また上の画像には入っていないが、Lisa Su CEOの説明の中でFP16で1.3PFlops、FP8で2.6PFlopsの処理性能があることが示された。ちなみに競合のH100は、Tensor Coreを利用した場合にFP16で989.4TFlops、FP8で1978.9TFlopsとなっている。これもいろいろあって、Sparsity Featureを利用すると性能が倍になる(1978.9TFlops/3957.8TFlops)といった数字も出ているが、とりあえずこれはまた別の話なのでおいておく。
まず演算性能について。そもそもXCDあたり38CUというのは中途半端だし、連載726回で紹介したようにInstinct MI300XのXCDにはXCUが40個づつ搭載されているように見える。おそらくハードウェア的には40XCUで、うち2つが冗長XCUに充てられているものと考えられる。
問題はXCUの中身だ。連載726回で、Instinct MI300のXCUは、Instinct MI200の2倍の処理性能ではないか? と仮定したわけだが、この計算が正しいとすると、1つのXCUあたりの処理性能は以下の計算になる(Vectorの場合はFMAを利用して1回の計算が2Flopsとしている)。
システム全体で308CUなので、1サイクルあたりの処理性能はMatrix FP16/BF16の場合で630784Flops、FP8では1261568Flopsになる。この処理性能で、先に書いた「FP16で1.3PFlops、FP8で2.6PFlops」を達成しようとすると、だいたい動作周波数は2GHzほどになる計算だ。
正確に言えば2.06GHzくらいになるので、実際は2.1GHz程度かもしれない。ちなみに2.1GHz駆動だとFP16で1.32PFlops、FP8で2.65PFlops程度になる。Instinct MI250XがTSMC N6を利用してピーク1.7GHz駆動だったことを考えれば、Intinct MI300XはXCUはTSMC N5だしピークが2.1GHz程度であるのは不思議ではないだろう。正確なスペックはまだリリースされていないが、そうは外れていないはずだ。
転送速度が落とされている Intinct MI300XのHBM3
それとやや謎なのが、HBM3である。本来HBM3は6.4Gbps/pinの帯域を持つ。Hostとは1024bit I/Fで接続されるので、メモリー帯域は1スタックあたり6.4Tbps=819.2GB/秒である。Instinct MI300Xはこれを8スタック搭載するので、本来ならば819.2×8=6553.6GB/秒、つまり6.5TB/秒のメモリー帯域がある計算になる。
ところが実際には5.3TB/秒の帯域と説明されている。ということは、HBM3の転送速度が5.2Gbpsかそのあたりまで落とされているわけだ。可能性として考えられるのは以下のとおり。
(1) 6.4GbpsのHBM3 スタックの供給が間に合わなかった、もしくは速度の歩留まりが低くてもう少し動作周波数を下げないと満足に入手できない。 (2) 6.4Gbpsで転送すると消費電力が過大になるので、転送速度を下げた。 (3) XCDがそこまでのメモリー帯域を必要としないので、バランスをとれるところまで下げた。 (4) メモリーコントローラーが追い付かない
このうちありそうなのは、(1)と(2)である。実際、同じくHBM3を実装しているNVIDIAのH100は4.8Gbps/pinに転送速度を落としているという話は連載661回で説明したとおり。
メーカーの方を見てみると、SamsungのIceboltは6.4Gbps/pinと言いつつまだサンプル出荷段階、SK HynixのHBM3も、MP(Mass Production)なのは5.6Gbps/pinで、6Gbps/pinはまだCS(Customer Sample)状態。MicronはそもそもHBM2Eの後、直接HBM3Eに行くようで、HBM3の製品ページ自体がない状態だ。
6.4Gbps品の製品開発そのものは各社とも完了し、すでに9.6GbpsのHBM3Eの開発完了を発表しているところもあるが、量産はまた別ということだろう。またInstinct MI300XのIODはTSMC N6だが、確かにこれで6.4GbpsのPHYを動かすと、それなりに発熱がすごそうだ。
6.4Gbpsという信号速度はDDR5-6400と同じだが、こちらは64bit幅なのに対してHBM3は1024bitなので16倍になる。もう少し動作周波数を落として消費電力を下げたい気持ちはわからなくもない。
(3)に関しては、AIはもうメモリー帯域はあればあるだけ良いので考えても無駄として、ではHPC系の科学技術計算は? というのを試算してみる。上の表にあるように、FP64のVectorでは128Flops/cycleなので、308XCUで78848Flops/Cycle。先の試算の2.1GHz動作だとすると165.5TFlopsほどになる。Instinct MI250Xがピークで47.9TFlopsなので4倍ほどの性能になる計算だ。
さてこの場合のB/F値(Bytes/Flops)だが、5.3TB/秒に対して165.5TFlopsになるので、全然お話にならない(0.03Bytes/Flops)数値であり、このあたりを考えても(3)はあり得ないところだろう。
(4)については、例えばRadeon RX 7000シリーズの上位グレードはXCDを同じくTSMC N6で製造しているが、こちらは19Gbpsにも耐えられるわけで、発熱の問題はあるにしても考えにくい。ということで可能性としては(1)と(2)あたりが理由となりそうだ。
ちなみにこのInstinct MI300Xであるが、H100との比較ではLLM Kernelの演算性能で1.1~1.2倍、8 GPU構成でのトレーニング速度はH100と同等、130億パラメーターのLlama 2の推論速度はH100の1.2倍といった数字が示されている。
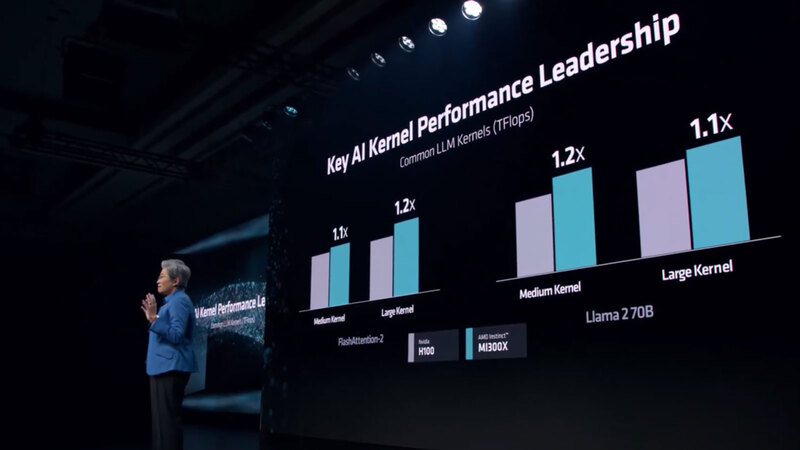


連載730回で触れたが、同じモデルを実行した場合、ソフトウェア側の問題で性能が出ない件に関しても、今回発表されたROCm 6では特に生成AI向けに大幅な最適化をしたとしている。

MI300Xでページを費やし過ぎてしまったので、MI300Aに関しては次回お届けしたい。

この記事に関連するニュース
-
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分
-
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月11日 12時0分
-
Ryzen 7 9800X3Dを試す - ゲーミングCPUの本命か? 第2世代3D V-Cacheの威力を徹底検証
マイナビニュース / 2024年11月6日 23時0分
-
6Gにおけるサブテラヘルツ帯の超高速無線を実現する小型無線デバイス ~InP集積IC技術により300GHz帯において世界最高の160Gbpsデータ伝送に成功~
Digital PR Platform / 2024年10月28日 15時7分
-
AI性能を引き上げるInstinct MI325XとPensando Salina 400/Pollara 400がサーバーにインパクトをもたらす AMD CPUロードマップ
ASCII.jp / 2024年10月28日 13時0分
ランキング
-
1イオンカード、不正利用に関するテレビ報道受け声明 「一日も早く安心してもらえる環境整備に努める」
ITmedia NEWS / 2024年11月21日 15時27分
-
2ダイソーの“フィギュアに最適”なアイテムが330万表示 驚きの高品質に「めっちゃいいやん……!」「価格バグってるw」
ねとらぼ / 2024年11月21日 20時0分
-
3「スンスンが餌食に」 販売から“全店舗3分で完売”→高額転売で「怒りが込み上げる」 スシロー×人気キャラコラボが物議
ねとらぼ / 2024年11月21日 19時2分
-
4「迷惑国際電話」を拒否できますか? - いまさら聞けないiPhoneのなぜ
マイナビニュース / 2024年11月21日 11時15分
-
5【便利】100Wにして本当に良かった、小さいのにあれもこれも充電できるスグレもの
ASCII.jp / 2024年11月21日 17時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





