

CDNA3のホワイトペーパーで判明した「Instinct MI300X/A」の性能 AMD GPUロードマップ
ASCII.jp / 2023年12月25日 12時0分

今回は連載749回の続きであるが、CDNA3のホワイトペーパーが公開されたことで、Instinct MI300X/300Aの正確なスペックが判明した。まずは連載749回の訂正からスタートする。
Instinct MI300XはMI250世代からMatrix Engineのみが強化
XCDのスペックについて連載749回で、XCDが1つあたり38XCUと書いたのは正確であったが、XCDの性能はInstinct MI250Xの2倍になると推定したのだが大外れであった。下の画像がホワイトペーパーに記載された性能である。
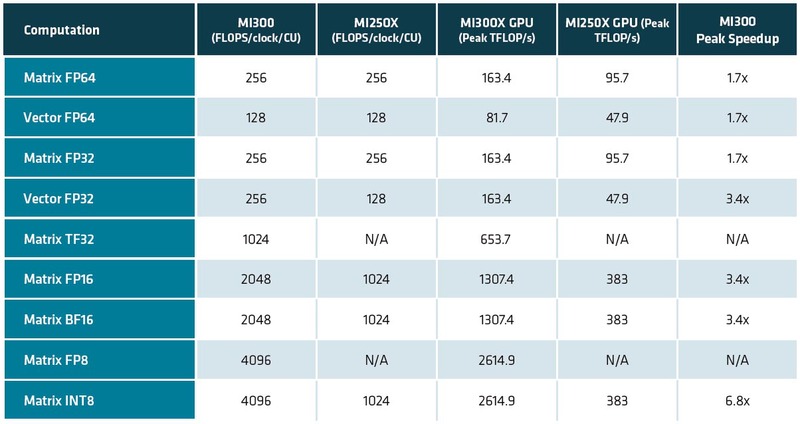
この性能と連載479回の結果を比較したものが下表である。MI250世代からMI300世代では、Matrix Engineのみが強化されたわけで、CUそのものは変わっていなかった。
つまりHPC向けの演算性能は、基本的な部分がMI250世代と変わっていないので、なるほどAMDがMI300XシリーズでAI性能の高さを大々的にアピールしていたわけである。また、MI200世代ではXCUという表記だったのが、MI300世代ではCUに戻っている。したがって、以下は表記をCUに戻す。
Matrixに関しても、FP64/FP32が全然変わっていない。もちろん科学技術計算でMatrix Engineを利用する可能性があるので、ここはMI250世代と同じスペックは維持している。一方でAI向けで言えば、学習用途でFP64を使う可能性はまずなく、FP32も最近はあまり使われなくなっている。
ただFP16/BF16では精度的にやや足りない用途向けに新たにTF32が追加され、これが1024Flops/サイクルとMI250のFP32から8倍のスループットになった。TF32は仮数部10bit、指数部8bit、符号1bitの合計19bitのフォーマットである。
FP32は仮数部23bit、指数部8bit、符号1bitの32bit、FP16は仮数部10bit、指数部5bit、符号1bitの16bitであり、「FP32並みの指数部とFP16並みの仮数部」のフォーマットだ。
最初にTF32を採用したのはNVIDIAで、連載730回で説明したとおり、A100でTensorFloat-32として導入したものだ。
またMatrixのINT8は2倍でなく4倍の4096Ops/サイクルまで強化されている。16bit幅で2048Flops/サイクルなのだから、8bit幅なら当然その倍になるわけだ。ちなみに動作周波数は推定通り2.1GHzになる。
ただそれでもCU数そのものがMI300Xは304CUと多い(MI250Xは220CU)うえ、動作周波数も高い(MI250Xは1.7GHz)こともあり、CU数で38.2%、動作周波数で23.5%の向上がある。結果、Vector Engineを使った場合でも軒並み70%の性能向上、Matrix Engineでは性能が3.4倍なり6.8倍に向上するわけだ。
ちなみに上の画像の数字はオプションなしでの数字となるが、Matrix Engineに関してはMI300世代でSparsityをサポートした。これは入力する4要素のうち2つ以上が0だった場合には疎行列として扱うことで性能を引き上げるという、NVIDIAのA100以降で搭載された技術と同じものだ。
Sparsityを利用した場合、TF32で10.5FPlops、FP16とBF16で20.9PFlops、FP8とINT8では41.8PFlops/41.8POpsまで処理性能が向上するとしている。そういう意味でもH100と肩を並べる性能になったわけだ。
もう1つ肩を並べるものとしては、仮想化のサポートもある。NVIDIAはA100世代でGPCごとにインスタンスを実行できるので、見かけ上最大7つのGPUを同時に使えるようになる、という話は連載663回で説明したが、同様にMI300も最大8つまでのインスタンス(AMDはこれをパーティションと呼ぶ)を同時に利用できるようになった。このあたりもA100/H100と肩を並べた格好だ。

Instinct MI300Xは単体販売はなくプラットフォームの提供のみ
また今回XCDの2次キャッシュ容量も4MBであることが公開された。十分か? と言えば十分とは言い難いのだろうが、このあたりはダイサイズとの兼ね合いもあるから、最大限努力したというあたりだろうか。
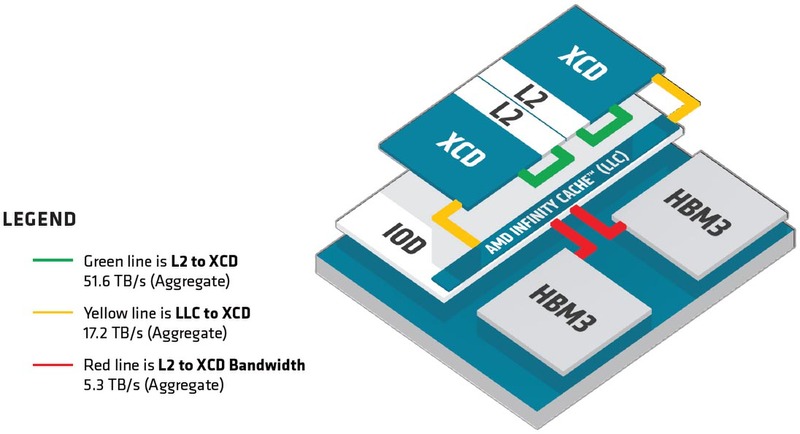
XCDと2次キャッシュの間の帯域は51.6TB/秒、インフィニティ・キャッシュとは17.2TB/秒、インフィニティ・キャッシュとHBM3の間の帯域は5.3TB/秒とされる。ただこの5.3TB/秒というのは8つのHBM3での合計の帯域になるので、CU1つあたりの帯域であれば実質665.6GB/秒という計算だ。
連載749回では科学技術計算向けにB/F値を計算してみたが、いろいろ計算の前提が間違っていたことがわかったので、計算しなおしてみる。システム全体でなくXCDあたりの性能で計算してみると、Vector FP64では128Flops/サイクル×38CU×2.1GHz動作なので10.2TFlopsという計算になる。この数字をベースにするとB/F値は以下のようになる。
さすがに4MBの2次キャッシュでは一瞬で使い切るので、B/F値が5を超えていると言ってもあまり喜べない。ただインフィニティ・キャッシュでもB/F値は1を超えているのはかなり優秀だが、こちらもわずか64MB。そしてHBM3にアクセスになった瞬間にB/F値は0.1を下回っているわけで、B/F値が効いてくるアプリケーションは、いかにプリフェッチを効果的に行なってインフィニティ・キャッシュにヒットするようにするかを細工しないと性能が出しにくそうである。
もっともこれをGPUにやらせるのはかなり無理があり、こうした処理はやはりCPUも一緒に搭載したInstinct MI300Aで行なう方が妥当と考えられる。その意味でも、やはりInstinct MI300XはAI向け製品として扱うのが妥当なのだろう。
ところでInstinct MI300XはOAM(OCP Application Module)の形で提供されるが、どうも単体販売はなく、Instinct MI300X×8をUBB(Universal Base Board) 2.0と組み合わせた形でのプラットフォームの提供のみになるようだ。
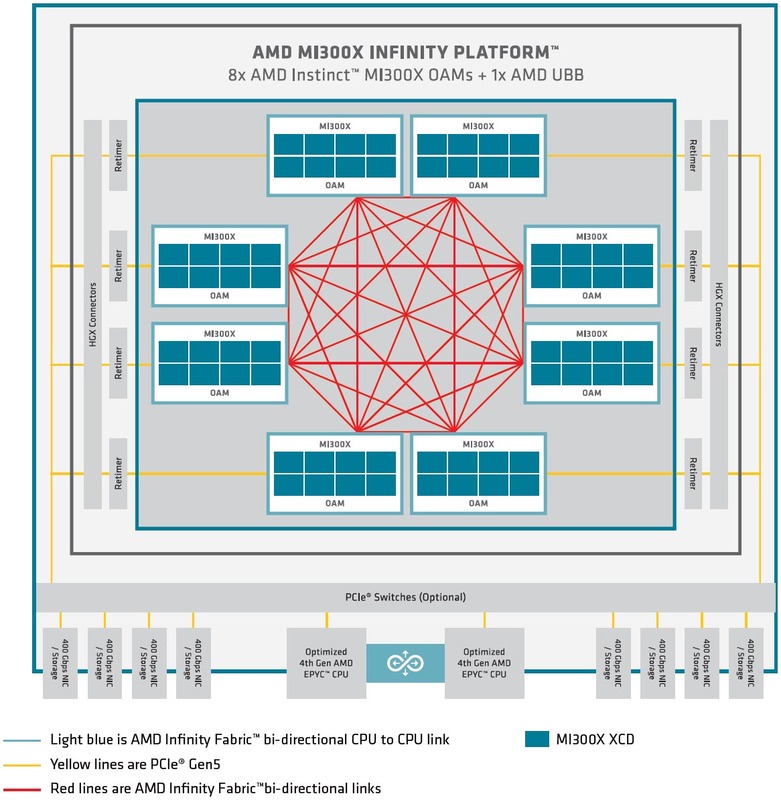

8つのOAM同士はインフィニティ・ファブリックでピア・ツー・ピアで接続され、ホストとはPCIe 5.0 x16レーンでの接続となる。このPCIe 5.0を直接ホストにつなぐのか、あるいは間にPCIeスイッチを挟むのかは、実際にこのプラットフォームを提供するOEMベンダーが決める話になる。
OAMの1つあたりの最大電力は750W。つまりプラットフォーム全体で最大6KWを消費する計算になる。昨今の「普通の」データセンターの供給電力はラック1本あたり15KW程度が上限のことが多いので、このプラットフォームにフロントエンドのCPUやネットワークのI/Fなどを含むと、7.5KWで収まるかどうか。つまりラック1本にこのシステム2つを収められればラッキー、というなかなか厳しい状況である。
もっともこれはNVIDIAのHGXも同じであり、最近はHigh Density Rackと呼ばれる50~100KWを供給できるラックがこうした用途に利用されつつある。おそらくInstinct MI300Xのプラットフォームもこうしたラックを利用するのが一般的になるだろう。
Instinct MI300Aは MI250Xから28%ほどの性能向上
次はInstinct MI300Aである。何度か書いたが、XCD×6+Zen 4 CCD×3という構成であり、これが4つのIODの上に載る形になる。XCDが載るIODはInstinct MI300Xと共通と思われるが、Zen 4 CCDが載る方は専用のIODを開発したものと思われる。
XCDのスペックそのものはInstinct MI300Xと同じであり、動作周波数も2.1GHzと発表されている。ただしCU数はInstinct MI300Xの4分の3になる228個となっており、この結果処理性能は下表となる計算だ。Instinct MI250XのVector FP64が47.9TFlopsだったので、28%ほどの向上に留まることになる。
ちなみにこの計算にはZen4コアの分は含まれていないが、実際にはZen 4コアは先程も書いたようにGPUに対してのコマンド発行やキャッシュのプリフェッチなどの作業がメインとなるので、ここはあまり考えなくて良いように思われる。
むしろ興味深いのはインフィニティ・キャッシュの位置付けである。ホワイトペーパーには明白に「MI300A APUでは、XCDとCCDの両方がインフィニティ・ファブリック経由でインフィニティ・キャッシュと8層のHBM3の両方を共有する」と記載されており、ということはXCDから見ればインフィニティ・キャッシュは3次キャッシュとして見えるがZen 4 CCDからは4次キャッシュとして見えることになる。
問題はこのZen 4 CCDから扱う場合の話である。Zen 4には4次キャッシュのプリフェッチを制御するような命令はそもそも含まれていない「はず」であり、だからといってインフィニティ・キャッシュがZen 4 CCDから完全に透明に見える(=触れない)わけでもないだろう。
おそらくはIODの側に、インフィニティ・キャッシュのプリフェッチを制御するようなレジスターが追加されており、これを操作する形になるのではないかと思うが、このあたりに関する詳細は今のところ明らかにされていない。
Instinct MI300XとInstinct MI300AはこのXCDの数やCCDの搭載、それとHBM3の容量(12層→8層になり、HBM3は1つあたりの容量が24GB→16GBになっている)のほかに、外部I/Fの違いがある。
Instinct MI300Xは7×インフィニティ・ファブリック+PCIe Gen5 x16という構成だったが、Instinct MI300Aは4×インフィニティ・ファブリック+4×PCIe Gen5 x16になっており、システム構成も下の画像のとおり。
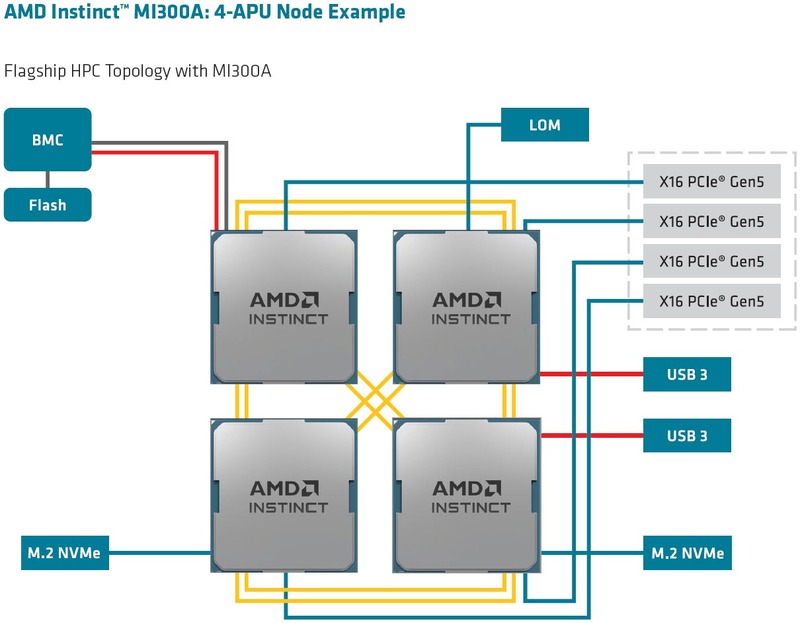
もっとも実際はインフィニティ・ファブリックにもPCIeにも使えるPHYが搭載されており、あとはどっちを選ぶかというだけであろう。
インフィニティ・ファブリックが4ch分ということは、無理なく構成できるのは上の画像の4 APUの密結合構成で、これを超える例えば8 APUなどを構成しようとすると昔の8P Opteronのように非対称構成になって、レイテンシーがややこしくなるのでHPCには向かないように思われる。ノード間の通信のレイテンシーのばらつきが大きくなり、結果として一番レイテンシーの大きいところに合わせて同期することになるので性能が低下するからだ。
この構図は、ローレンス・リバモア国立研究所に納入されるEl Capitanの構成にかなり近い。連載726回の際に行なったEl Capitanの推定は数字が間違っており、FP64 Vectorは61.3TFlopsでしかないから、1ノードが4つのInstinct MI300Aだとすると(*1)、ノードあたりの性能はFP64 Vectorで245.2TFlops。1枚のブレードに2ノードが実装されるので、ブレードあたり490.4TFlopsという計算になる。
つまりブレード2枚で約1PFlops。2040枚で1EFlopsを超える。El Capitanの目標性能は「2EFlops超え」であって、最終的にシステムが理論性能でどの程度まで積み上げるつもりなのかは不明だが、Frontierが理論性能で1.68PFlops程度であることを考えると、仮に2.1EFlops程度をターゲットにしたとすれば4283ブレード、8566ノード程でこれを達成できる計算になる。Frontierのノード数は9216だったので、これは十分に可能性がある構成だ。
ちなみに上の490.4TFlopsという数字はGPUが2.1GHz駆動の場合の数字だが、Frontier同様にこれを引き下げて使う可能性も十分にある。というのはInstinct MI300Aの最大電力は550Wあるいは760Wと記されている(*2)からで、550Wとは言わないまでも600Wあたりまで下げられればかなり性能/消費電力比は向上しそうに見える。
問題はどこまで動作周波数を下げればこれが実現できるか? で、2GHz駆動でこれが可能なら、ノード数は9000弱(8995ノード)でギリギリ、理論性能2.1 EFlopsのマシンができあがる格好だ。
今年10月には、ローレンス・リバモア国立研究所が“Building El Capitan: How LLNL’s Exascale Supercomputer Came to Be”と題する動画をYouTubeに上げており、すでに順調に設置がスタートしていることをうかがわせる。来年のTOP500では、フル稼働体制になったであろうAuroraとの一騎打ちになるわけで、今から結果が楽しみである。
(*1) 連載726回のスライドが正しいとすれば、Instinct MI300A×4+Gen 4 EPYC×1になるのだが、EPYCは無視する。 (*2) AMDのウェブサイトの記述はTDP 550W/瞬間最大電力760Wでこちらが実情に近い気がする。

この記事に関連するニュース
-
Intelの「Gaudi 3」って何? AIアクセラレーターとGPUは何が違う? NVIDIAやAMDに勝てる? 徹底解説!
ITmedia PC USER / 2024年7月5日 17時5分
-
「Lunar Lake」Deep Diveレポート - 【Part 2】Memory、GPU、NPUについて
マイナビニュース / 2024年7月4日 14時23分
-
Intel Tech Talkで見えたLunar Lakeにおける低消費電力と高性能の両立へのこだわり
マイナビニュース / 2024年6月27日 6時45分
-
COMPUTEXで判明したZen 5以降のプロセッサー戦略 AMD CPU/GPUロードマップ
ASCII.jp / 2024年6月17日 12時0分
-
Zen 5 CCDとX870とRyzen AI、AMDのCOMPUTEX講演にいくつかの補足情報
マイナビニュース / 2024年6月6日 16時1分
ランキング
-
1Google検索も不要に? 検索AI「Perplexity」がスゴすぎてちょっと怖い
ITmedia NEWS / 2024年7月5日 19時16分
-
2プリングルズ価格改定 ショート缶は容量そのままサイズ変更して空間率減少へ
ねとらぼ / 2024年7月5日 16時20分
-
3「コレのせいやったんか」 最近スマホが重い → “とんでもない理由”が判明……!? 「自分もやってた」「4年以上経ちました」と猛者たち集結
ねとらぼ / 2024年7月5日 16時0分
-
4清春、27年前にブチギレた“因縁の大物芸人”と対峙 トガっていた時期に頭たたかれ“殺しのリスト”入りへ「テレビナメるな」「パーンって」
ねとらぼ / 2024年7月5日 16時5分
-
5ランサムウェア被害、報告続出 イセトーサイバー攻撃で今わかっていること(7月5日時点)
ASCII.jp / 2024年7月5日 15時45分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください







