

Emerald Rapidsは32コアを境に性能に大きな差が出る インテル CPUロードマップ
ASCII.jp / 2024年1月1日 12時0分

連載750回に引き続き、12月14日の“AI Everywhere”イベントから、今度は第5世代Xeon ScalableことEmerald Rapidsの詳細を説明しよう。
Emerald RapidsにはXCC、MCC、LCCの3種類が存在する
まずダイの構成から。発表記事にもあるように、64コアで2タイルのXCC(eXtreme Core Count)と32コアで1タイルのMCC(Medium Core Count)、それと20コアで1タイルのEE LCC(Energy Efficient Low Core Count)の3種類が存在する。ここで問題になるのがMCCである。
まず順を追って説明すると、XCCは32コア×2なわけだが、上の画像にある右側のパッケージ写真を切り抜いて縦横補正を掛けたのが下の画像だ。

タイルの中は7×5=35個のブロックと、その上下に大きなエリアがある。そして赤枠のブロックだけ中央に縦線が入っており、他のブロックと様相が異なる。おそらくこれがDDR5のI/Fブロックと考えられる。
逆にPCIeやアクセラレーターらしきものは35個のブロックには見当たらない。ここから考えると、XCCのタイルは下図のような構造になっていると推定される。

このタイルを2つ用意し、片方を180度ひっくり返して接続することで、2タイルのXCCが完成するわけだ。このXCCのTileは連載715回でも推定した通り、25.2×30.9mmで778.7mm2という巨大なものになる。
ちなみにこの計算ではCPU+3次キャッシュのブロックが33個という計算になるが、それをアクセラレーターに割り振っている感じもしない。おそらくだが33個分のCPU+3次キャッシュのブロックが用意され、うち1つは冗長ブロックに割り当てているのだと思われる。
実際これだけ大きなダイサイズだと、冗長ブロックを用意しないと歩留まりがかなり悪くなりそうだからだ。ちなみにこのタイルを2つつなげると以下の構造になると考えられる。
- CPU/3次キャッシュブロック×66(うち2つは冗長ブロック)
- メモリーコントローラー×4(おのおの2ch)
- PCIe/CXL×6(うち1つはPCH接続用のDMIに割り当て)
- UPU×4
32コア以下の製品は3次キャッシュの容量が Sapphire Rapidsと変わらない
ではMCCは? というと、XCCのタイルをそのまま使うことはできない。というのはメモリーコントローラーとUPI/PCIeレーンの数が足りないからだ。SKU一覧では細かすぎるうえにいくつか落ちている項目があるので、Intel ArkからEmerald Rapidsのスペックを落としてまとめたのが表である。
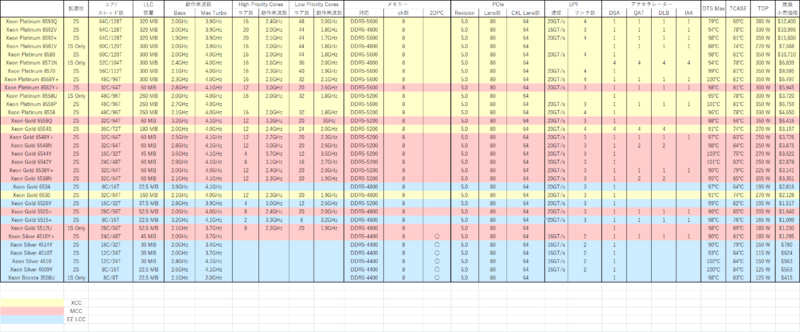
全SKUともにPCIeが80レーン、DDR5も8ch搭載されている。周辺回路周りで言えば、XCCとMCCの違いは以下になる。
- UPIが最大3ch(3×16レーン)に(XCCは最大4ch)
- アクセラレーター(DSA/QAT/DLB/IAA)が各1個(XCCはすべて最大4つづつ)
したがって、これをまともに構成した場合には、現在の7×5のブロックではどう考えても足らず、8×5ないし6×6ブロックになる。現実的に可能性が高いのは6×6ブロックで、構成としては下図のようになるだろう。
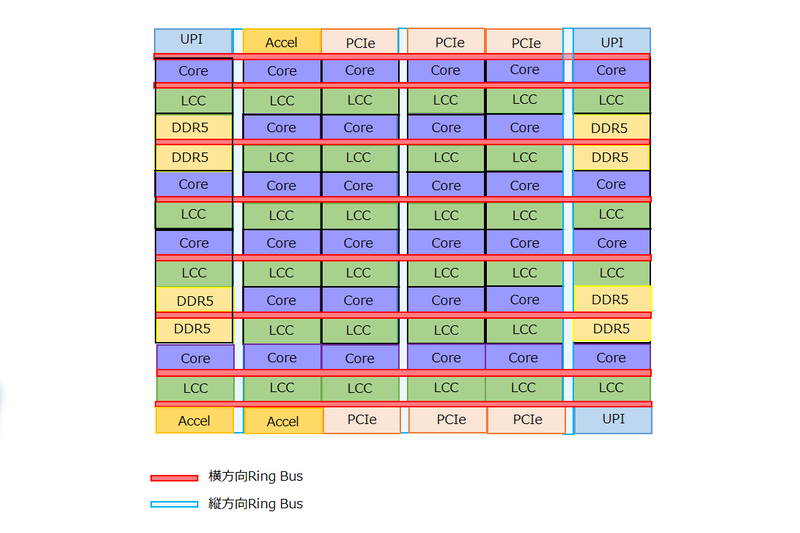
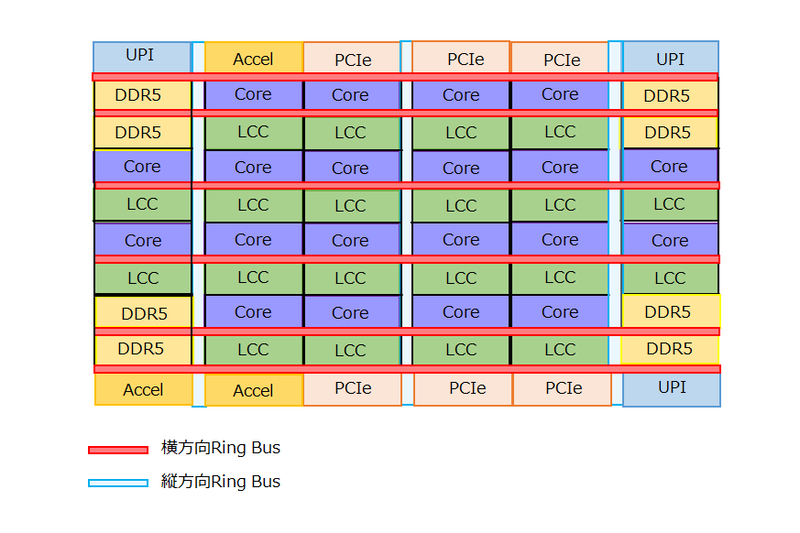
もしこれをXCCと「まったく同じ構成で」実現したとするとどうなるか? というと、XCCの7×6ブロック分の面積が28.2×20.5mmで、これを6×6ブロックに組み替えると24.1×24.5mmほど。さらにブロックの上下にアクセラレーターやPCIe/UPIブロックが配され、またブロックの横にはPHYのエリアが付くので、下の画像のような構成になるはずだ。

この場合最終的にタイルの寸法は26.8×31.2mmほどになり、面積は836.2mm2ほど。Reticle Limit(ダイサイズの限界)に挑戦というか、ややブッちぎっていないか? という寸法になる計算だ。いくらなんでもこれはおかしい。
実は上の画像の構成は、それぞれのコア+LCCがXCCとMCCで同じという前提で話をしている。ここでもう一度表を見て欲しいのだが、XCC、つまり黄色のものはLLC(Last Level Cache)容量がコア数×5MBになっている。ところがMCC、つまりピンクであるが、こちらは以下の4種類が存在する。
このうち24コアで60MBなのはXeon Gold 6542Yのみで、他はLLC容量がコアあたり1.875MBとSapphire Rapidsと変わらない数字になっているのがわかる。
これはEE LCCも同じであり、32コア以下の製品は3次キャッシュ容量を据え置きにすることで個々のブロックの面積を減らしており、結果としてタイルの面積(上の画像で言えば高さ方向)を減らせると思われる。どの程度か? というのはもう少し細かい写真が出てこないとなんとも言えないのだが、3次キャッシュの面積が6割強減っているのはそれなりにインパクトがある。
例えばブロックの高さがこれで1割減ったとすれば753.1mm2、2割なら670.0mm2ほどになる計算である。3割までは減らないと思うので、実際は700mm2弱くらいではないかと思うのだが、そこまで減ればXCCのタイルより明らかに面積が減るので、それだけ歩留まりが上がり、原価も下がりそうだ。
ちなみにXeon Gold 6542YだけLLCが60MBなのは、コアは24コアのみ有効にしつつ、LLCは32コア分すべてを有効にしているのだろう。
EE LCCもコア数が20に減った以外はMCCと同じなので、下図のような構成だろう。正確なダイサイズは不明だが、仮にLLC 5MBだったとしても617.3mm2ほどなので、実際には500mm2台あたりで収まるものと考えられる。
XCCは大幅に性能が改善したように見えるが MCC/EE LCCコアではどこまで性能が伸びるか怪しい
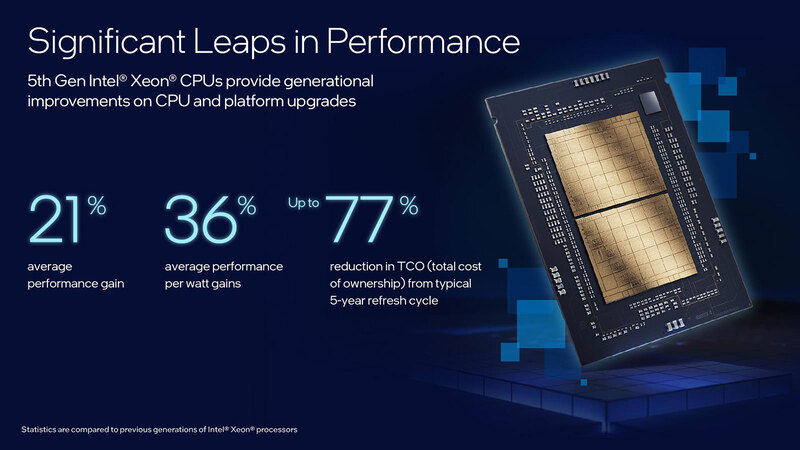
コア数に絡む性能の話を考えたい。記事冒頭の画像でも平均21%の性能向上とされており、また別のスライドでも似たような話が出ている。
ただSapphire RapidsはGolden Cove、Emerald RapidsはRaptor Coveであるが、もともとSapphire Rapids向けのGolden CoveはEmerald Cove同様に2次キャッシュが2MBだったのでここでの変化はなく、パイプラインの若干の改良に留まっているためIPCそのものはほとんど変わらない。
コア数も60コア→64コアだから6.7%程度の向上である。プロセスそのものは改良したIntel 7という言い方をしているので、Raptor Lakeと同じIntel 7+を利用して製造されているとは思うが、動作周波数そのもので言えば例えばSapphire Rapids世代のXeon Platinum 8490HがBase 1.90GHz/Max Turbo 3.50GHz、対してEmerald Rapids世代のXeon Platinum 8593QがBase 2.2GHz/Max Turbo 3.9GHzだから、Max Turbo同士の比較では11.4%ほどの改善である。
ただコア数×動作周波数で考えると1.067×1.114≒1.189で18.9%ほどの向上でしかないので、記事冒頭の画像にある“Average Performance Gain”が21%になるとは考えにくい。
実のところ、性能改善はそれ以外の部分で行われているように思われる。1つはタイル数減少によるレイテンシー削減である。
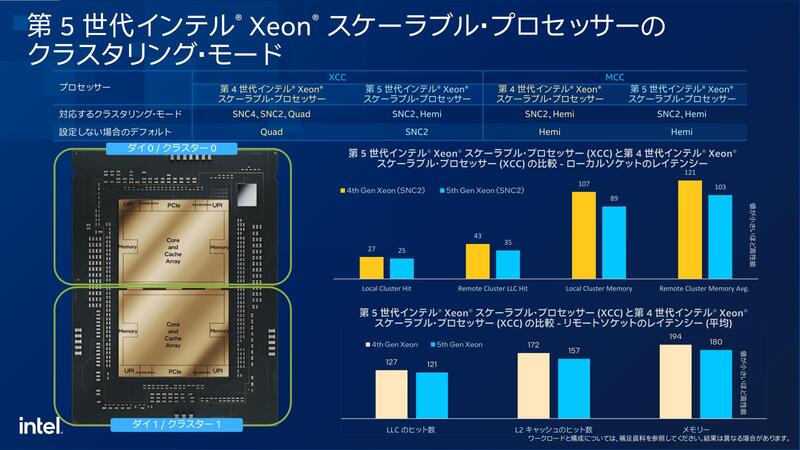
Sapphire RapidsのXCCでは縦方向と横方向のRing Busが全部EMIB経由で隣りのタイルに接続されており、つまり縦方向/横方向どちらに通信する場合でもEMIB部分のPHYを介する分、余分なレイテンシーが発生する。
ところがEmerald Rapidsでは横方向は同一タイル内であり、縦方向の通信だけ余分なレイテンシーが発生することになる。どちらがオーバーヘッドが大きいかは明白だろう。
もう1つは、プロセス変更の効果だ。Raptor LakeはAlder Lakeと比べると同一周波数なら電圧を下げられるし、同一電圧ならより動作周波数を上げられるようになったという話を連載686回で説明したとおりである。
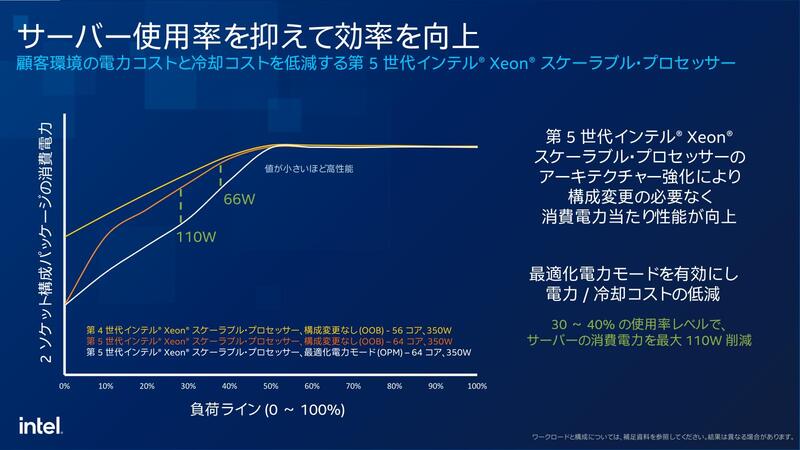
Emerald Rapidsが同じくIntel 7+であれば、同じ消費電力ならより平均的な動作周波数を引き上げられる。上の画像で、50%以下の負荷の場合はOPMを設定しなくてもEmerald Rapidsの方が消費電力が低いというあたりがこれを物語っている。
さらに、前頁の表にもあるがXCCではHigh Priority CoreとLow Priority Coreが設定されており、特にシングルスレッド性能を必要とするような負荷の高い処理はHigh Priority Coreに割り振られる=より高めの動作周波数で稼働するようになる、というあたりが実際の性能差につながっていると考えられる。
要するに記事冒頭の画像で性能/消費電力比を36%改善したとしているが、その性能/消費電力比をそのまま平均的な動作周波数向上に振った結果が今回の性能改善につながっていると考えられる。
もちろんここには、例えばLLCの大容量化による効果や、メモリーアクセスそのものの高速化(DDR5-5600のサポート)なども含まれるだろうが。
もう1つ、AVX Offsetに関しても違いがある。AVX Offsetは、特にターボが掛かっている際にAVXユニットをフルに動かすと電力がオーバーしてしまうため、動作周波数を下げて稼働する仕組みであるが、Emerald Rapidsではこれを5段階に変更している。
AVX512にしてもAMXにしても、フルに動かした際に負荷が重い命令と軽い命令が混在している。そこで、負荷が軽い命令に関してはオフセットの値を小さくして、より高い動作周波数で動作できる仕組みだ。これが一番顕著なのは、AIやHPC向けの処理をさせた場合であり、実際パフォーマンス向上の比較からもこれがうかがえる。
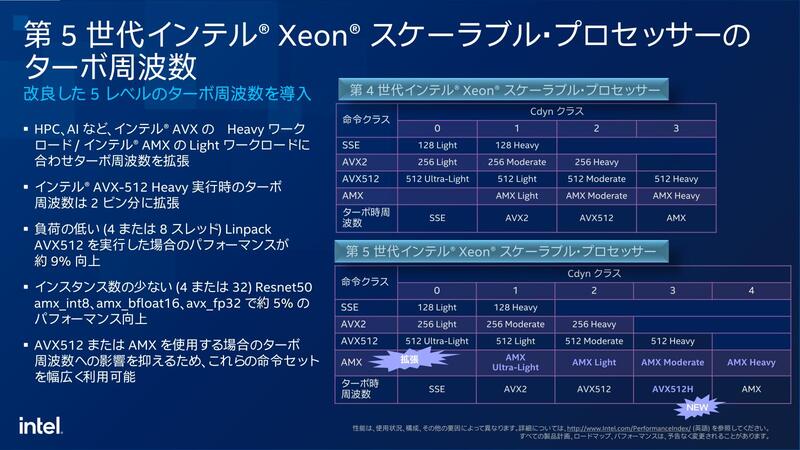
以上のことから、確かにXCC同士で比較すれば大幅に性能が改善したように見えるEmerald Rapidsであるが、MCC/EE LCCコアを使う、つまり32コア以下のSKUではどこまで性能が伸びたのか、少し怪しい。最大の理由は先にも書いたがLLCが1.875MBに留まっていることだろう。
したがって、平均的な動作周波数の向上による性能向上は期待できるが、違いはそこだけである。加えて言えばMCCでDDR5-5600をサポートしているのは唯一Xeon Platinum 8562Y+で、他の製品はすべてDDR5-5200以下。EE LCCに至ってはDDR5-4800以下になっているあたりは、メモリー高速化の恩恵も期待できないことになる。このMCC以下の製品に関しては、性能向上はそこまで期待できないだろう。
なんというか、どうせならMCCも2タイル構成にすればこんな無理をする必要はなかったのにと思わなくもないのだが、一番下では1295ドル(Xeon Silver 4516Y+)のSKUまであることを考えると、2タイル構成は価格的に難しかったのかもしれない。
XCCとMCC/EE LCCでかなり性能ギャップがありそうな構成に仕上がってしまったのがEmerald Rapids世代のXeon Scalableというわけだ。

この記事に関連するニュース
-
リブランドした「Intel Xeon 6」はどんなCPU? Intelの解説から分かったことを改めてチェック
ITmedia PC USER / 2024年7月2日 16時5分
-
Lunar LakeではPコアのハイパースレッディングを廃止 インテル CPUロードマップ
ASCII.jp / 2024年7月1日 18時0分
-
「Lunar Lake」Deep Diveレポート - 【Part 1】P-Core&E-CoreとPackageについて
マイナビニュース / 2024年6月29日 12時31分
-
Intel Tech Talkで見えたLunar Lakeにおける低消費電力と高性能の両立へのこだわり
マイナビニュース / 2024年6月27日 6時45分
-
Lunar Lakeはウェハー1枚からMeteor Lakeの半分しか取れない インテル CPUロードマップ
ASCII.jp / 2024年6月24日 12時0分
ランキング
-
1Google検索も不要に? 検索AI「Perplexity」がスゴすぎてちょっと怖い
ITmedia NEWS / 2024年7月5日 19時16分
-
2プリングルズ価格改定 ショート缶は容量そのままサイズ変更して空間率減少へ
ねとらぼ / 2024年7月5日 16時20分
-
3「コレのせいやったんか」 最近スマホが重い → “とんでもない理由”が判明……!? 「自分もやってた」「4年以上経ちました」と猛者たち集結
ねとらぼ / 2024年7月5日 16時0分
-
4楽天ペイと楽天ポイントのキャンペーンまとめ【7月4日最新版】 楽天ペイアプリでポイント最大10倍もらえる
ITmedia Mobile / 2024年7月4日 10時5分
-
5「ドコモ光 1ギガ」旧プランを2025年6月に提供終了、解約金の安い新プランへ自動移行
マイナビニュース / 2024年7月4日 19時15分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください







