

B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ
ASCII.jp / 2024年3月25日 12時0分

消え去ったI/F史は中断し、今回と次回は、3月18日からサンノゼで開催されたGTC 2024におけるNVIDIAの発表、特にBlackwellについて解説したい。
B100のダイサイズは850平方mm前後?
2023年10月に行なわれた投資家向けカンファレンスで示されたのが下の画像にあるロードマップである。今回GTC 2024で発表されたのはB100、つまりH200の後継となる新サーバー向けチップとこれを利用した派生型である。
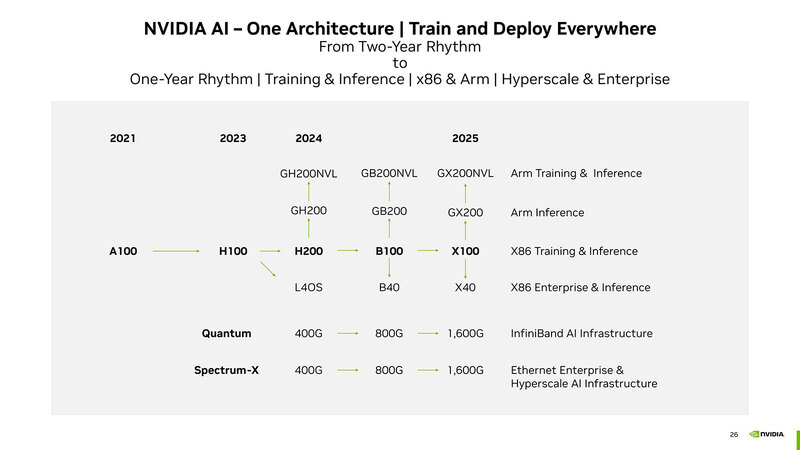
最初にお断りしておくと、本稿ではB100とひとくくりに説明しているが、これは上の画像で"B100"と記されているのでこれを使っているだけで、実際にはB100/B200という2種類の製品名が混在、しかもB200には2種類のSKUがある「らしい」。
まだ正式に商品名とスペックが公開されていないので、ここではBlackwellアーキテクチャーを搭載したチップの総称として"B100"と説明することにする。
まずB100の元になるBlackwellチップであるが、製造はTSMC 4NPである。4N"P"がなにを意味しているのか公式には明らかにされていない。ただH100/H200世代は、TSMCのN4をベースにしたNVIDIAカスタム版であるTSMC 4Nプロセスを採用していた。
同じようにBlackwellでは、TSMCのN4P(N4の高性能版)をベースにNVIDIAカスタム版プロセスを利用しており、それがTSMC 4NPではないか? という気がする。トランジスタ数は1040億個で、H100が800億個と説明されていたので、3割程トランジスタ数は増えたことになる。

ちなみにダイサイズは後で推定するが、そもそもH100の時点でダイサイズは814mm2と発表されているため、単純に1.3倍にすると1058.2mm2となり、Reticle Limitをはるかに超えてしまう。トランジスタ数とダイサイズは単純に比例しない(構成によって変わる)から、実際にはReticle Limitの限界(26mm×33mmの858mm2)に限りなく近い程度に収まっていると思われる。
これは逆に言えば、SRAM(L1/L2/L3キャッシュ)の容量はH100からそれほど増えておらず、演算器のみ増やした、あるいは演算器の複雑さが増したことを示唆していると考えられるが、このあたりはホワイトペーパーが出てもう少し正確な情報が手に入らないとはっきりしたことは言えない。ただ"The Largest Chip Physically Possible"とまで言ってるので、限界にチャレンジしたのは間違いなさそうだ。
ちなみに純粋に技術的に言えば、Reticle Limitを超えるサイズのダイを作ることは不可能ではない。例えばチップの上半分と下半分に分けて、それぞれ別のマスクで露光をすることで、Reticle Limitを超えるダイを露光することは可能だ。
ただしその場合、2回の露光のずれが1nm未満のオーダーで一致していないと、使い物にならないチップもどきが完成する。しかもこれをトランジスタ層(ここだけで10回を超える露光がある)だけでなく配線層まで全部実行するので、露光の回数は下手をすると3桁に行きかねない。
このどこか1回だけでもずれたらパーなわけで、歩留まりは猛烈に低いと予測できる。したがって、さすがにそこまでの冒険はNVIDIAもやらないだろうし、そう考えるとダイサイズはReticle Limitにかなり近い数字、850mm2前後になるだろう。
Blackwellのダイはかなり大きいが、B100はこのBlackwellのダイを2つ組み合わせた格好となる。要するにAMDのInstinct MI250Xと同じ構成である。2つのダイの間は独自のインターコネクトで接続される格好だ。

Full-cache coherencyの意味は、2つのダイのおそらく2次キャッシュ同士をダイの外で接続しているものと思われる。もともとHopperの世代では、2次キャッシュは物理的に2つに分割され、これがダイの内部でつながっている構造だった。

B100では、1つのダイには2次キャッシュが1つのブロックとして構築されているが、2つのダイの2次キャッシュが外部のインターコネクト経由で相互接続されているのだろう。
BlackwellのダイそのものはHopperよりもやや小さい
前ページでBlackwellのダイサイズを推定したが、実際にHopperのパッケージと比較したのが下の画像だ。

パッケージ全体で言うと、下の画像のとおりB100は一回り以上巨大である。

実際に上の画像を回転させ、歪みを補正したのが下の画像である。ここからダイサイズを計算したところ、意外もBlackwellのダイそのものはHopperよりもやや小さく、783.4mm2と算出された。

あるいは2次キャッシュの容量そのものが少し減り(これで大きく面積が削減できる)、CUDA Coreの方にトランジスタを割いた(これはSRAMほど面積が増えない)のが大きいのかもしれない。
ところで今回の基調講演を含む一連の説明の中で、一度も「2つのダイをどう接続しているか」に関する説明がなかった。可能性が一番高いのはTSMCのCoWoSだろうが、CoWoS-S(シリコン・ インターポーザーを使った2.5D積層)は最大でも1700mm2(Reticle Limitの2倍)となっており、Blackwell×2だけならともかくHBM3e×8を搭載まで搭載するのは絶対に不可能である。
ではCoWoS-R(有機パッケージを使ったインターポーザー)は? というと、HBM3eが本当に通るのかがまだ未知数である。一番可能性が高いのは、インテルのEMIBと同じく、有機パッケージの中にシリコン・ インターポーザーを埋め目込んだCoWoS-Lであろう(AMDのInstinct MI250Xのように、ASEのFOCoSを使う可能性は低いはずだ)。
B100はAI性能がH100の5倍
次は性能の話だ。"5X the AI performance"というのがB100の特徴である。つまりAI性能がH100の5倍というわけだ。もちろんこれはピーク性能なのだが。それでもB100が1個あたり20PFlopsのAI処理性能、192GBのHBM3eでメモリー帯域は8TB/秒とされている。

これに絡んで今回発表されたのが、第2世代のTransformer Engineと、これを利用することでFP4/FP6のサポートが可能になった、という話だ。

Transformer EngineはA100/H100世代のGPUで搭載されている機能で、動的に変数の型を変更して精度のリキャストやスケーリングの自動調整が可能なものだが、第2世代ではFP4/FP6が追加された。
まだFP4の詳細は不明だが、普通に考えれば符号1bit、仮数部1~2bit、指数部2~1bitの合計4bitであり、FP8の半分で表現できることになる。ということは同じ規模の演算器なら2倍の処理が可能になる。性能5倍のうちの2倍が、このFP4のサポートで賄われると考えられる。
また2ダイ構成ということは、これで2倍の性能になるということで、FP4のサポートと併せて、4倍の性能向上が確保された格好だ。ということで残り1.25倍が、ダイそのものの構成あるいは動作周波数によるものと考えられる。
B100の1ダイあたりの性能はH100を下回る つまり性能改善はTensor Coreだけ
ここで少しH100に戻る。H100はフル構成では144 SMで、おのおののSMは128個のCUDA Coreが搭載されている。ひるがえってB100は、1つのダイに搭載されているSMらしきものの数は20×4で80個である。2ダイ構成では160個なのでH100を超えることになるが、1ダイ同士でも1.25倍の性能向上があるはずなので、つじつまが合わない。とすると考えられるのは以下の4つのいずれかになる。
(1) ダイの写真を見るとSMが80個しかないように見えるが、これが160個分である。 (2) SMは80個であるが、一つのSMの中のCUDA Coreが倍増(256個)している。 (3) SMの数もCUDA Coreの数も同じだが、CUDA Coreあたりの性能が倍になっている。 (4) 性能改善はTensor Coreだけで、CUDA Coreの方は一切変更がない。
現時点ではなにしろホワイトペーパーも出ていないのでこのあたりはさっぱり不明である。ただ演算ユニットの数は160:144=1.11倍になっているのではないと判断している。あとは動作周波数の調整であって、仮に動作周波数がH100と比べて12.5%向上していれば、1.25倍という性能向上が実現できる計算になる。
TSMCの2021年10月の発表によれば、N4PはN4と比較して6%の性能改善(同一消費電力で動作周波数が向上)が図られたとしている。4NPが本当にN4Pベースなら、N4ベースの4Nに比べてやはり6%程度の性能改善が期待できるわけで、それほど消費電力を増やさずに動作周波数を引き上げることも不可能ではないだろう。
性能に関してもう少し話そう。H100とB100について、理論上のフルスペック性能(実際の製品ではなく、無効化されたコアなどもない状態でのピーク性能)を比較した場合、下表となる。
B100は2ダイ構成でこれなので、1ダイあたりの性能で言えばH100を下回る計算になる。もっともSM数の比では、FP64がB100では0.281TFlops/SM、H100では0.258TFlops/SMで大差なく、動作周波数の比で考えればほぼ同等ということになる。要するに先の構成案の(4)が一番実情に近いのではないか、というのが筆者の考察である。
だとすると、ダイサイズがかなり大きいのも理解できる。1ダイあたりのSM数は144→80なので56%強であり、また2次キャッシュのサイズもダイ写真を比較する限りあまり差がない。TSMC N4→N4Pではエリアサイズの縮小の効果はないので、同じ面積≒同じ容量と考えていいからだ。
それにもかかわらずダイサイズがそれほど変わらず、トランジスタが増えているというのは、SMのサイズそのものが大型化していることになるし、ところがFP32/FP64では性能向上の効果がほとんど見られないというのは、要するにCUDA Coreの方は(内部のアーキテクチャーがどうなっているかはともかく)基本変わらないことになる。
であれば変更はTensor Coreの方が中心であり、こちらを大幅に強化したためにトランジスタ数も増え、エリアサイズも増えたということだと考えるのが妥当だろう。これは、AI性能だけでなくFP64の性能の強化も行なったAMDのInstinct MI300X(こちらはFP64で81.7TFlops)と非常に対照的である。
もっともMI300XはFP8のTensorで5.2PFlops程度でしかなく、20PFlopsのB100には遠くおよばないことになるわけで、そういう意味ではBlackwellはAI性能に全振りした、と評してもいいだろう。HPCに使えないわけではないが、性能/消費電力比や性能/コストを考えると無駄が多すぎる。
ただHPC市場とAIの市場、どちらが市場規模が大きいかを考えたら、AIに全振りするNVIDIAの戦略は妥当ではないかと思う。
長くなりすぎたので、システムの話は次回解説する。

この記事に関連するニュース
-
Core Ultra 200H/U/Sをあえて組み込み向けに投入するのはあの強敵に対抗するため インテル CPUロードマップ
ASCII.jp / 2025年1月20日 12時0分
-
NVIDIAが新型GPU「GeForce RTX 50シリーズ」を発表 新アーキテクチャ「Blackwell」でパフォーマンスを約2倍向上 モバイル向けも
ITmedia PC USER / 2025年1月7日 18時50分
-
PCテクノロジートレンド 2025 - GPU編「NVIDIA」を追う「AMD」と「Intel」
マイナビニュース / 2025年1月4日 10時0分
-
PCテクノロジートレンド 2025 - プロセス編「Samsung」と「Intel」
マイナビニュース / 2025年1月2日 10時0分
-
PCテクノロジートレンド 2025 - プロセス編「TSMC」
マイナビニュース / 2025年1月1日 10時0分
ランキング
-
1ローソンが238円で具なしカップラーメン発売へ 「高くない?」「カップヌードルとほぼ同額」異論も
iza(イザ!) / 2025年1月22日 17時7分
-
2快活CLUBに不正アクセス、個人情報が一部漏えいか
ASCII.jp / 2025年1月22日 13時15分
-
3“映り込み”を防いでスマホ撮影するには……? 100均アイテムを使った目からウロコのライフハックに「これはスゴい」
ねとらぼ / 2025年1月22日 7時50分
-
4父「若いころはモテた」→娘は半信半疑だったが…… 当時の“まぶしすぎる姿”に40万いいね「俳優さんみたい!」「衝撃的」【海外】
ねとらぼ / 2025年1月22日 17時20分
-
5サンリオに不正アクセス ピューロランドのチケット購入などが不可能に 情報漏えいについては調査中
ITmedia NEWS / 2025年1月22日 17時12分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





