

GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ
ASCII.jp / 2024年4月1日 12時0分

Blackwellアーキテクチャーは コンシューマー向けにも適用されるかもしれない
前回に引き続きBlackwellについて解説する。ちなみに現時点でもまだBlackwellのホワイトペーパーが公開されていない(Architecture Technical Briefは公開されたが、ここには個々のSMの構造などはまだ含まれていない)ので、前回説明した内容がどの程度妥当だったのかの確認はできていない。
あともう1つ。これは公式発表ではないのだが、このBlackwellアーキテクチャーはデータセンター向けだけではなく、コンシューマー向けにも適用される予定という話が流れている。実際以下のとおりリリースされてきている。
今年は刷新されると考えるのが普通だし、そうなるとBlackwellアーキテクチャーを使うと考えるのが妥当と言えば妥当である。ただその一方で、以下のようなあまりコンシューマー向けに向かない特徴が気になるところである。
- プロセスがTSMC 4NPで、多少速度は上がってるにしてもトランジスタ密度はどの程度向上しているか疑問
- NVIDIAはBlackwellでマイクロアーキテクチャーを刷新したと説明しているが、その一方で性能に関してはTensor Coreの大幅な性能改善がメインであって、CUDA Coreの方はどこまで性能が上がっているのか不明(スペックだけ見ているとCUDA Coreの方の性能向上はほぼなさそうに見える)
- Ada Lovelace世代のAD102は609mm2で128SMであり、つまりSMあたり5.97mm2ほどでの実装となっている。これに対しB100/B200のものは783.4mm2で80SMと前回推定できており、つまりSMあたり9.79mm2ほどのエリアサイズとなる。この大型化の理由はTensor Coreの大幅強化と筆者は考えているが、逆に言えばTensor Coreを利用しないGPU的な用途にBlackwellをそのまま持ち込むのは猛烈に効率が悪い
もちろん、例えばBlackwell世代はアプリケーションの設定と無関係に常時DLSSがTensor Coreで稼働しており、なのでGPUでのレンダリングの負荷が相対的に低くなって結果として性能が向上する、なんて方針であればこれでも良さそうだが、正直ちょっと考えにくい。あるいはTensor Coreが実はRay Tracing Engineの機能も搭載しているなどならあり得るのかもしれないが。
仮にBlackwell世代からそのまま持ち込んでうれしい機能があるとすれば、マルチチップ構成だろうか? もしこれがコンシューマー向けGPUにも適用できるのであれば、それは意味があるだろう。ただ同じくマルチチップ構成(正確に言えばマルチGCD)を目論みつつ開発中止で消えてしまったNavi 40のことを考えると、AI向けでうまくいったからといって、GPU向けにそのまま使えるとは限らないので、これも可能性は低いだろう。
まだ断言はできないが、今年登場すると思われるコンシューマー向けのアーキテクチャーは、Blackwellと異なるものになる気がする。これは過去にも事例がある。2018年はデータセンター向けがVolta、コンシューマー向けがTuringだった。Voltaも後追いでTitan Vというコンシューマー向け(?)のラインナップは用意されたが、基本はデータセンター向けのみである。
Blackwellも同様にメインはAI推論/学習向けで、コンシューマー向けはまた違ったもの(そのコード名がBlackwellを継承するかどうかも不明)になるのではないかというのが筆者の推定である。このあたり、Blackwellのホワイトペーパーが公開されたら、もう少しクリアになるのだが。
GB200 Grace Blackwell Superchipは Grace Hopper比で2.5倍~6倍の性能
さて今回のメインとなるのは、このBlackwellを利用したシステムの話だ。前回示したロードマップにもあるように、本来B100をベースに、ArmベースのGrace CPUを組み合わせたGB200やGB200NVLというソリューションと、x86と組み合わせるB100とB40というソリューションの2つが用意される。
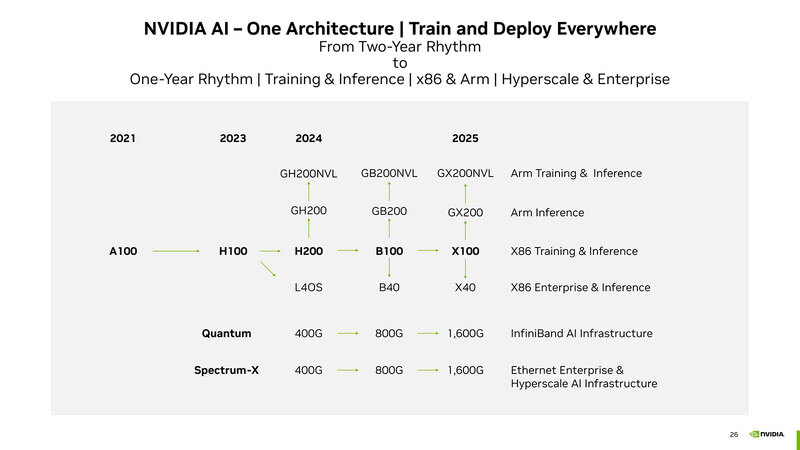
現時点で公開されているのは、以下の3種類のみである。
- B200×2+Graceを組み合わせた、GB200 Grace Blackwell Superchipと、これを36枚組み合わせたGN200 NVL72
- B200×8を1枚のキャリアボードに搭載した、HGX B200
- B100×8を1枚のキャリアボードに搭載した、HGX B100
まずGB200 Grace Blackwell Superchipというのが下の画像だ。その下の拡大図を見ると、Grace Hopper比で2.5倍~6倍の性能という数字が出てくるが、FP6やFP4を使った場合の数字ということを考えると、この性能が本当に発揮されるのかどうかはTransformer Engineの頑張り次第という感じがする。


基調講演ではこの開発用のボードも披露された。

このGB200 Grace Blackwell Superchip(ボードなのにチップ呼ばわりするのもどうかと思うが)を2枚、1Uのブレードに収めたのがBlackwell Compute Nodeであり、このブレードを18枚集積したのがGB200 NVL72となる。


I/Fチップは1つあたり4本のNVLinkを外部に出せる
インターコネクトは引き続きNVLinkが利用されるが、こちらもなかなか壮絶な構成である。今回利用されるNVLinkは第5世代になるが、I/Fチップは1つあたり4本のNVLinkを外部に出せるようになっている。

1本のNVLinkは18本の100Gbpsのレーンから構成される。上の画像には200Gbpsと書いてあるが、これはUp/Downの合計であり、1方向あたりでは100Gbpsになる。
NVLinkそのものは1本あたり1.8Gbpsの帯域を持つわけだが、Blackwell Compute NodeにはこのNVLink Switchが2つ搭載される。つまり1つのBlackwell Compute Nodeから8本のNVLinkが外部に引っ張り出せる計算だ。ちなみにインターコネクトとしては、これとは別にConnectX-800 InfiniBand Switchカードを4枚搭載できるようだ。

このNVLinkのI/F同士の接続に、9枚のInfiniBand Switchシステムが、Blackwell Compute Nodeの間に挟まるように入る。

これでBlackwell Compute Node同士の相互接続だけでなく、複数のNVL72同士の接続も行なう形であろう。ただこれはあくまでもBlackwell GPU同士の相互接続であって、Graceの方はこのNVLinkの接続の恩恵を受けない。いやがんばってGraceからBlackwell経由でNVLinkを使った通信を行なうことも不可能ではないのだろうが、効率が悪すぎる。

こちらの用途のために、TOR(Top of Rack)にInfiniBand Switchも搭載される格好だ。

これで1つのNVL72が構成されるわけだが、当然配線はすさまじいことになっている。

NVIDIAはこのNVL72を8本組み合わせた構成では、従来(おそらくGH200)比で冷却コストを半分にできるとしている。これは同一数のラックと比較してなのか、同一の演算処理で比較してなのかはっきりしないが、なんとなく前者な気がする。

要するにGH200ベースだと9本のラックのうち8本をGH200が占めるのに、GB200では4本なので半減という計算な気がする。さらに将来的には400本以上のNVL72を並べれば、645EFlopsの猛烈なAI Factoryが構成可能とアピールするが、そもそも16000枚のGB200 Grace Blackwell Superchipを製造できるのはいつのことなのか? というのが偽らざる感想である。

さて、ここまではGraceと組み合わせたGB200 Grace Blackwell Superchipの話だが、これ以外にキャリアボードに実装されたB100/B200のみの構成も用意されている。それがHGXB200/B100である。

8つのB100/B200をまとめて提供する形なのは、AMDのInstinct MI300Xなどと同じである。ロードマップ的にはB40という製品もあるようなので、いずれはPCIeカードの形の提供も予定されているのだろうが、当面はこのキャリアボードの形のみでの提供になると思われる。
フルスペックのB200はTDP 1200W、 HGX B200は性能が1割減、HGX B100は3割減
ところで先程からGB200 Grace Blackwell SuperchipとB100/B200が入り乱れているわけだが、要するにNVIDIAは今回の発表に合わせてB100/B200に3つのSKUを用意した形だ。SKUといっても基本的な同じパッケージ、同じダイであり、動作周波数を変えるか、あるいは一部のSMを無効にする形での対応になっている「らしい」。
「らしい」というのは、実際の動作周波数やSM数そのものはいまだに未公開で、ただ性能の数字のみが示されているからだ。下表は先程も説明したArchitecture Technical Briefから拾った数字をまとめたものだ。
一番左のB200はGB200 Grace Blackwell Superchipに搭載されているB200で、これがおそらくフルスペックのものである。次のHGX B200の方は、同じB200ながら性能が1割程落ちている。
そしてHGX B100に搭載されるB100は、フルスペックのB200と比べて3割ほど性能が落とされている。おそらくはこれはSM数の制限と動作周波数の変更の両方で実現しているのであろう。
結果、HGX B200に搭載されるB200はGPU1つあたりがTDP 1000Wなのに対し、B100は700Wに抑えられている。実際にはこれが8つなので、HGX B200のTDPは8KW、HGX B100でも5.6KWの消費電力になる。
GB200 Grace Blackwell Superchipの方はトータルで2.7KWという数字しか示されていないが、2チップのGraceを搭載したNVIDIA Grace CPU SuperchipのTDPが500Wと発表されているから、1個あたりで言えば250W。ということはGB200 Grace Blackwell Superchipに搭載されるB200のTDPは1個あたり1225Wという計算になる。実際はもう少し少ない1200Wあたりと想定される。
HGX B200がやや低めなのは、おそらく空冷の限界が1000Wあたりにあるためだろう。仮にGB200 Grace Blackwell Superchipと同じスペックなら8つでほぼ10KWにも達する。これはいろいろ厳しいと思われる(いや8KWでも十分厳しいと思うのだが)。
連載761回の最後のスライドで、2024年には液冷でTDP 1000Wになり、その後1300Wを超えるという予測が示されていたが、すでにこれを超える消費電力を実現しているあたりはさすがとしか言いようがない。


この記事に関連するニュース
-
GeForce RTX 50だけではない! 社会がAIを基礎にしたものに置き換わる? 「CES 2025」で聴衆を圧倒したNVIDIAの最新構想
ITmedia PC USER / 2025年1月10日 17時40分
-
NVIDIAが新型GPU「GeForce RTX 50シリーズ」を発表 新アーキテクチャ「Blackwell」でパフォーマンスを約2倍向上 モバイル向けも
ITmedia PC USER / 2025年1月7日 18時50分
-
NVIDIA Grace Blackwell がすべてのデスクと AI 開発者のもとへ
PR TIMES / 2025年1月7日 15時15分
-
PCテクノロジートレンド 2025 - GPU編「NVIDIA」を追う「AMD」と「Intel」
マイナビニュース / 2025年1月4日 10時0分
-
Ansys、NVIDIA GH200 Grace Hopper SuperchipでCFDシミュレーションを110倍高速化
Digital PR Platform / 2024年12月24日 10時42分
ランキング
-
1ひっきりなしに届く通知...しばらく黙らせるベストな方法は? - いまさら聞けないiPhoneのなぜ
マイナビニュース / 2025年1月22日 11時15分
-
2“映り込み”を防いでスマホ撮影するには……? 100均アイテムを使った目からウロコのライフハックに「これはスゴい」
ねとらぼ / 2025年1月22日 7時50分
-
3格安SIMでも海外ローミングを JCOMが「Airalo」と提携した狙い、J:COM MOBILEはシェア4位に躍進
ITmedia Mobile / 2025年1月22日 11時10分
-
4フジテレビの会見は「背信行為」「使命や責任を放棄」──メディア労組の連合会が声明
ITmedia NEWS / 2025年1月22日 8時20分
-
5【リメイク】100均靴下を切って貼るだけの簡単リメイク! 目からウロコのアイデアが「天才過ぎます」「材料買いに行かないと」
ねとらぼ / 2025年1月22日 9時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





