

音楽生成AIの進化速度に舌をまく、無料でも試せるStable Audio 2.0を使う
ASCII.jp / 2024年4月7日 17時0分
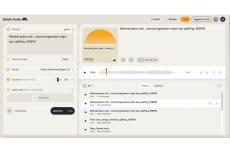
著作権侵害を未然に防ぐ機能も持つ
昨年紹介した音楽生成AI「Stable Audio」が「Stable Audio 2.0」となり大きく進化した。
生成AIがブレイクするきっかけを作った画像生成AI「Stable Diffusion」を開発したStability AIによる音楽生成AIだ。2023年8月にバージョン 1.0をリリースした際にはこの連載でも紹介した。グーグルの「MusicLM」のようにプロンプトを与えることで、音楽を作り出す音楽生成AIで、Stable Diffusionのようにステップを経て徐々に生成が完了する“拡散モデル”を使用しているのが特徴だ。Stable Audio 2.0では、モデルが新しくなったのが最大の改良点だ。ある入力に対応して生成される出力に関して、生成のルールやパターンを決めるのがモデルである。つまり、知識やアルゴリズムを持つ中核部分が改良されたことになる。
新しい高圧縮オートエンコーダーや拡散トランスフォーマーの導入により、より長い時間スケールでの性能が可能となっている。生成できる時間を3分に延長している。また、Audio to Audio機能も追加された。これはある曲を手本にして、別の曲を作る機能だ。サウンドエフェクト生成もでき、キーボードのタッピングや群衆の歓声なども生成できる。

AIで問題となる学習元は、AudioSparx.comと契約し、同社が持つ音楽ライブラリーから「音楽、効果音、単一楽器のステム、および対応するテキストメタデータ」など、80万以上のファイル、1万9500時間以上のデータセットを使用している。また、新たに著作権保護のためにAudible Magicと提携し、リアルタイムのコンテンツマッチングに対応した。ここは、著作権侵害につながりやすいAudio to Audio機能の追加とも関係している。Stable Audio 2.0では、より著作権の問題に対して有効な手段が講じられたと言えそうだ。ここは、新しいモデルを搭載したこと以上の目玉と言えるかもしれない。
異世界転生アニメに使えそうな曲を作ってみる
早速試してみた。無料版のユーザーは、月に最大20曲を作曲できる。ここは従来版と変わらないのだが、モデル2.0を使用した場合は生成に必要なリソースが増えるため、生成できる曲数は半分に減少するようだ。
以前試して分かったのは、Stable Audioではプロンプトを自然言語で入力するよりも、Stable Diffusionのようにジャンルや楽器、テンポなど単語を列挙して行くほうがいい結果を得られることだ。Stable Audioの自然言語解析能力は、グーグルのような先進的な自然言語処理技術と比較して、なんらかの制限があるからかもしれない。今回も同様に単語を列挙するプロンプトで試してみた。記事では日本語に訳すが、実際には英語で入力する必要がある。
はじめに前回と同じプロンプトを使用した。似たような曲にはなるが音質は高くなった。ビットレートが上がったのだろう。有料版ではWAVの出力に対応しているので、さらに良い音質が得られかもしれない。
新しい曲を作ってみた。異世界アニメのサントラを意識し、民族音楽の要素を加えようと考えた。プロンプトは次のようなものにした。「ケルト音楽風のアニメのサウンドトラック音楽。オーケストラがメインだが、民族音楽風のアレンジのためにフィドルとティンホイッスルも使用する。ゆっくりと始まり、徐々に壮大になり終わる」。ちなみにフィドルはバイオリンを民族音楽で使う時の弦楽器の名前で、ティンホイッスルはケルト音楽に特有の管楽器だ。
生成された曲はかなり完成度が高いので驚いてしまう。以前は複雑な曲が苦手という印象があたったので、シンプルなピアノ曲にしたのだが、モデル2.0では複雑な音楽の生成も十分にこなせる。また、指定した楽器の要素もきちんと含まれている。ティンホイッスルは、普通のリコーダーのように聞こえるが、これはトーンを高くするなどプロンプトで調整可能かもしれない。画像生成AIでも、特定の楽器を出すのは難しいが、一般的な楽器を描いて形をプロンプトで調整することはできる。
Stable Audio 1.0では実験室レベルの品質なので、ことさら課金しようとは思わなかったが、Stable Audio 2.0であれば課金して有料版で続け、もう少し修正して、追い込みたいと思わせるレベルになってきている。つまり、スタート地点(ユーザーが使いたいと思えるクオリティ)には立てたように思う。
時折、左右のチャンネルが混じってしまうなど、まだ改善すべき問題はあるようだが、著作権問題に対して前向きな姿勢が示されたのは注目すべきポイントだ。これでまた音楽生成AIの実用化が、一歩前進したと言える。次期バージョンでは、どのようになるのか期待は大きい。

ちなみに、あまり説明されず、リリース後すぐに使用できなくなった機能としてAIラジオ「Stable Radio」がある。これは従来のストリーミングサービスなどでのラジオ機能を、AIで生成するもののようだ。配信はYouTubeでなされている。もしかすると、ストリーミングサービスに音楽生成AIが参入する、そして取って代わる日は意外と近いのかもしれない。
いずれにせよ、前の記事で「音楽生成AIの先はまだ長い」と書いたことは、わずか半年で訂正しなければならなくなったようだ。筆者もAIの進歩については、だいぶフォローしているつもりだが、その進歩の速さに舌を巻くばかりだ。

この記事に関連するニュース
-
生成AI「リートン」、6月28日に「Stable Diffusion 3」をweb・iOS版アプリ両方でリリース
PR TIMES / 2024年6月28日 16時45分
-
Google DeepMind、テキストプロンプトで"口パク"にも対応するサウンドトラック生成技術
マイナビニュース / 2024年6月19日 10時29分
-
AIが作る3Dモデルの完成度が上がってきた 毎回異なるモンスターが生成されるゲームも実現か
ASCII.jp / 2024年6月17日 7時0分
-
Microsoftが「Recall」機能に関する追加情報を公開 プライバシーに配慮/iOS版「フォートナイト」が2025年後半に復活
ITmedia PC USER / 2024年6月16日 6時5分
-
AIによる画像生成がさらにリアルに、美しく。ファッション業界向け生成AIツール「MaisonAI」がアップデート
PR TIMES / 2024年6月12日 17時45分
ランキング
-
1「ロンハー」有吉弘行のヤジに指摘の声「酷かった」「凄く悲しい言葉」 42歳タレントが涙浮かべる
ねとらぼ / 2024年7月2日 15時31分
-
2老後の趣味で気軽に“塗り絵”を始めて1年後…… めきめき上達した70代女性の美麗な水彩画に「本当にすごい…」「感動です」
ねとらぼ / 2024年6月29日 22時0分
-
3マイナポータルで障害、一部機能が利用しづらくなった
ASCII.jp / 2024年7月2日 16時35分
-
4KADOKAWAの情報、さらに流出の可能性──ハッカーが追加で公開か 同社は信ぴょう性を調査中
ITmedia NEWS / 2024年7月2日 11時25分
-
5「昔のミスド良すぎる」「復活してほしい!」 30年以上前の“ミスドのドーナツ”に復活求める声相次ぐ
ねとらぼ / 2024年6月26日 12時30分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください







