

Windows上でユニコードを「見る」方法
ASCII.jp / 2024年5月12日 10時0分
Windowsでは、文字コードに「ユニコード」を使う。Windowsに搭載されているフォントはさまざまあるが、ユニコード文字を表示できるように、多数の文字の形が組み込まれている。
今回は、Windowsでユニコードを“見る”方法について解説する。なお、WindowsではUTF-16LEエンコードをUnicodeと表記する。ここでは、エンコードと混同されないために、文字仕様のUnicodeは「ユニコード」とカナ書きすることにする。
GUIアプリでユニコードを使う
ユニコード文字は多数ある。それぞれの文字に割り当てられた文字コードをユニコードでは「コードポイント」と呼ぶ。コードポイントは、「U+」の後ろに16進数4桁または6桁で指定するのが正式な表記方法だ。たとえば、「漢」は「U+6F22」となる。ユニコード関連の文書やもちろん、インターネット内のウェブページでも同様の表記をすることが多い。
GUIアプリに対してユニコード文字の簡単な入力方法の1つは、日本語変換IMEを使う方法だ。
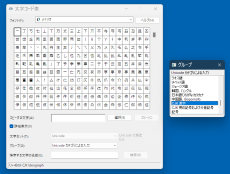
日本語入力IMEには、文字コード表からの入力を可能にしているものがある。Windowsには「文字コード表」というアプリケーションもある。これらを使うと、表から文字を探して、GUIアプリケーションに入力できる。
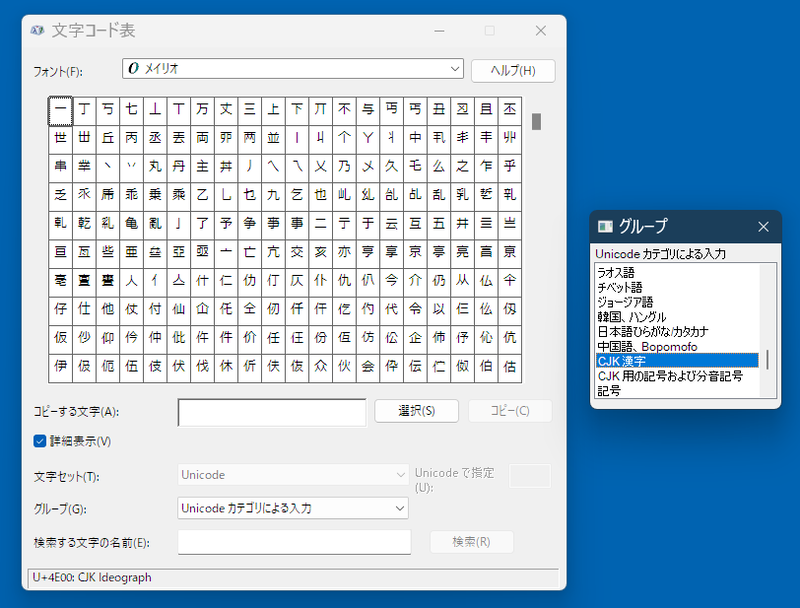
「Win+ピリオド」で「絵文字パネル」が開くが、最上段の「記号」アイコンを選択すると、ユニコードの記号文字を表から選択して入力可能。また、MS-IMEの使用時には、絵文字パネルで検索できる。また、一部のGUIアプリケーションは記号入力などとして、キーボードから直接入力できない文字を入力する手段を提供している。
このとき、「グループ」や「種類」などとして、ユニコード文字をカテゴリ分けしている。これは、ユニコードのブロックに相当する。ユニコードでは英語の名称で「Character Code Charts」(https://www.unicode.org/charts/)に一覧がある。
このページで検索欄にコードポイントの16進数表記を入れると該当のブロックの文書を探してくれる。ブロック名の日本語訳は、JIS X 0221:2020の附属書Aの「A.2 ブロックの一覧」に「日本語による通用名称(参考)」として表記されている。多くの文字コード表で使われる分類名はこれを元にしている。JIS規格書は、日本産業標準調査会(https://www.jisc.go.jp/index.html)で見ることができるがユーザー登録などが必要だ。
文字のコードポイントを調べる
PowerShellを使うと、文字のコードポイントを簡単に調べることができる。文字からコードポイントを調べるには、
[char]::ConvertToUtf32(<文字列>,<文字位置>)
を使う。
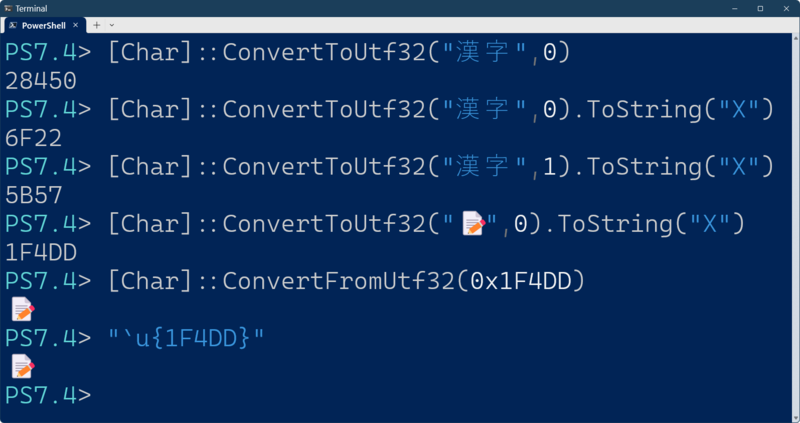
位置は、文字列内でコードポイントに変換したい文字の位置を指定する。先頭は0、次の文字は1である。
逆にユニコードのコードポイントから文字を表示させるには、
[char]::ConvertFromUtf32(<コードポイント>)
を使う。なお、PowerShell Ver. 6.x以上ならば、コードポイントから文字への変換にUnicodeエスケープシーケンス「`U{コードポイント}」を使うことができる。
一筋縄ではいかないのがWindows
Windowsでは、ユニコード文字列などにはUTF-16というエンコード方法を内部的に使う。これは、1文字を16bitで表現する方法である。しかし、ユニコードのコードポイントは、0x0000~0x10FFFFまであり、16bitではすべて表わしきることができない。そこでUTF-16では、「サロゲートペア」と呼ばれる方法を使い、0x10000以上のコードポイントを16bit文字2つを使って表現する。
ひらがなや数字など多くの文字がUTF-16の1文字で表現できる0x10000未満にあるとはいえ、場合によっては文字列にサロゲートペアが含まれる可能性がある。サロゲートペアが入ると、文字位置や文字列長が「見た目」と一致しなくなる。エクセルなどの文字列関数の結果が「考えていたのと違う」ことになる。
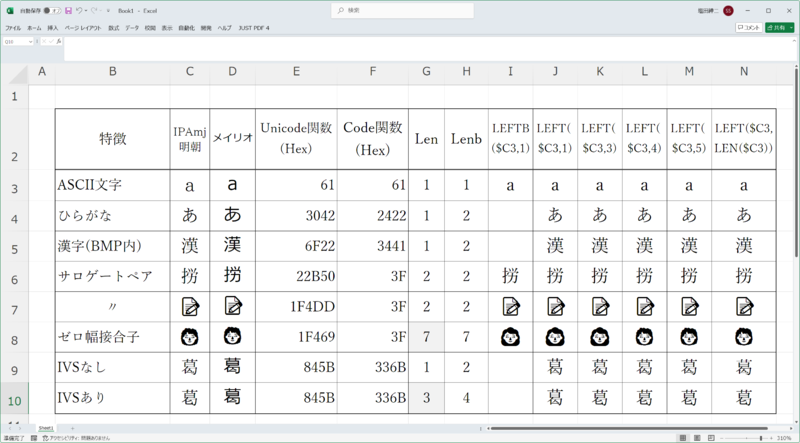
そうなる原因は、サロゲートペアだけでなく、絵文字などで使われる「ゼロ幅接合子」や、異体字セレクタ(Variation Selectors)の漢字異体字シーケンス(IVS。Ideographic Variation Sequence)もある。こちらはユニコードのルールなので、エンコードに関係なく文字列に含まれてしまう可能性があるが、面倒なのはこれにサロゲートペアが関わることだ。絵文字や異体字セレクタは、Windowsでは、サロゲートペアとして表現されるからだ。
絵文字は、Windowsの絵文字パレットで入力可能だが、IVSを含む文字は、日本語入力IMEから入力し、異体字を含むフォント(IPAmj明朝など)をアプリケーション(Excel)側で指定する。たとえばATOKならば、文字パレットを起動し、「異体字検索」タブで漢字とフォントを指定すれば、異体字が表示される。フォントに異体字が含まれていないと表示されないので注意してほしい。
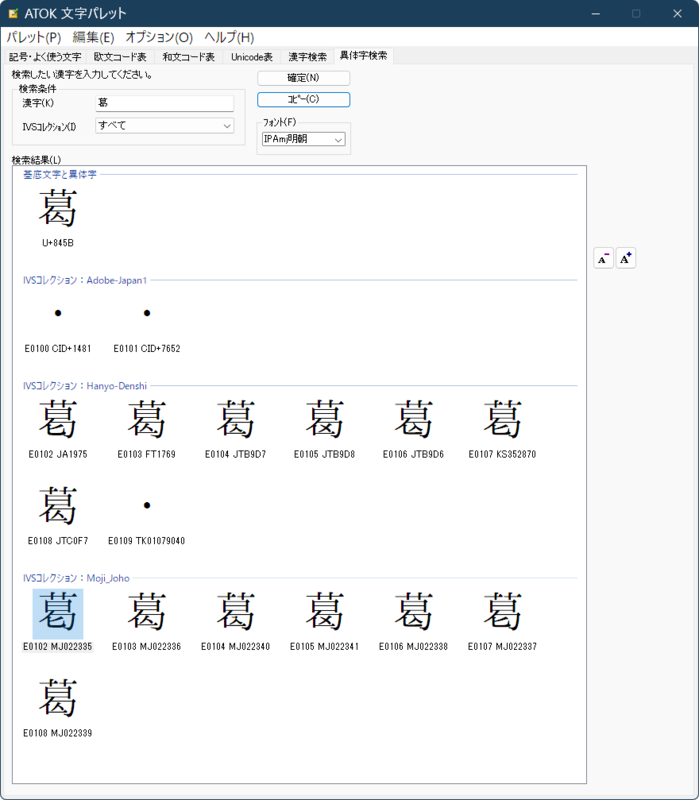
MS-IMEならば、文字パレットの歯車アイコンから「IMEの設定」を開き、「全般」にある「変換候補の一覧に含める文字セットを選択する」で「すべて」を選ぶと、変換候補に異体字が含まれるようになる。
ゼロ幅接合子を含む絵文字や異体字セレクタを含む文字列は、PowerShellのコマンドラインでも正しく表示されないことがある。これらの文字を含む文字列では、コマンドラインでカーソル位置がずれてしまう。
このような場合、対象の文字列をクリップボードに入れ、Get-Clipboardコマンドを使って参照するのが簡単だ。文字列を16進数で出力させたいなら「Format-Hex」コマンドで文字エンコードを指定する。メモ帳などにいったん対象を書き込み、クリップボードにコピーする。
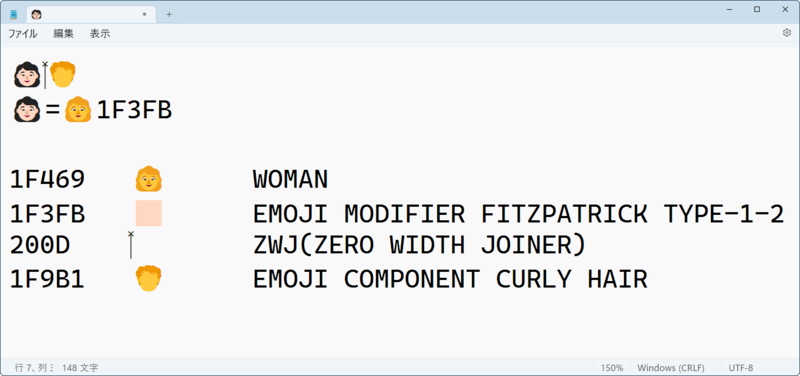
絵文字なら、「Win+ピリオド」で絵文字パネルを開いて、絵文字(たとえば「女性:巻き毛」)を選び、メモ帳に貼り付ける。右クリックメニューから「Unicode制御文字の表示」を選択すると、「女性:巻き毛」が3つに分かれる。このうちの先頭部分を「Alt+X」でコードに変換すると、「WOMAN」(U+1F469)と「EMOJI MODIFIER FITZPATRICK TYPE-1-2」(U+1F3FB)になる。
これに「ゼロ幅接合子。ZWJ(ZERO WIDTH JOINER)」(U+20D)と、「EMOJI COMPONENT CURLY HAIR」(U+1F9B1)が続く。結局4つのコードポイントから構成されていることがわかる。
メモ帳で「Unicode制御文字の表示」をオフにして、絵文字「女性:巻き毛」をクリップボードにコピーする。PowerShell Ver.6以降で以下のコマンドを実行すると、コードポイントをバイト単位で表示できる(残念ながらWindows PowerShellでは動かない)。
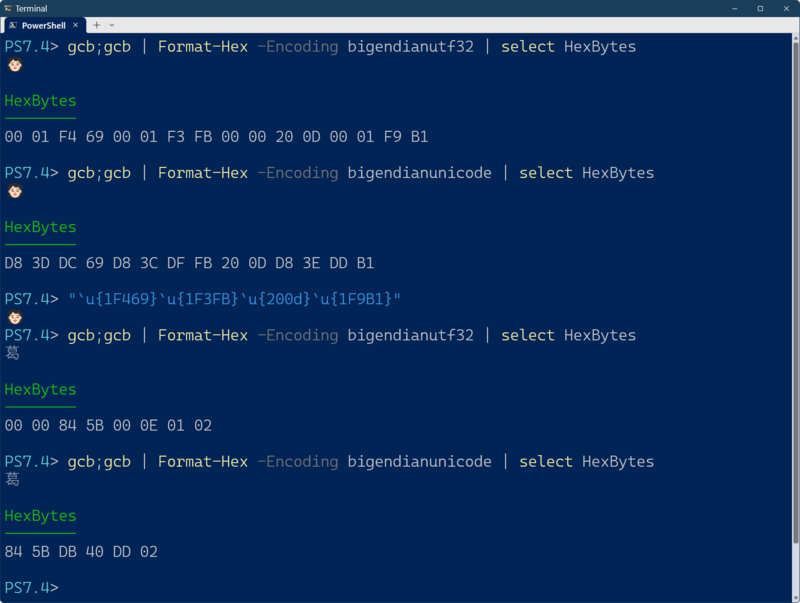
なお「gch」は、Get-Clipboardコマンドのエイリアスである。一回目は単に対象文字を出力し、2回目のgchをパイプラインで処理している。
gcb;gcb | Format-Hex -Encoding bigendianutf32 | select HexBytes
出力はバイト単位だが、32bit分つまり4バイトが1つのコードポイントになる。エンコードにビッグエンディアンのUTF-32を指定してあるので、バイトの並びは、上位から下位の順になる。先頭から4バイトごとに32bitのコードポイントを表す。
これをUTF-16で表現したものは、以下のコマンドで見ることができる。
gcb;gcb | Format-Hex -Encoding bigendianunicode | select HexBytes
出力はバイト単位なので今度は2バイトごとに見る。エンコードに「ビッグエンディアンのUTF-16」を指定しているので、バイト順は、上位・下位である。先頭がDで始まる2バイトがサロゲートペアになり、4バイト分で1文字に対応する。これをみるとコードポイントで0xFFFFを越えるものがすべてサロゲートペアになっている。
PowerShell Ver.6以上なら、この絵文字は、文字列「"`u{1F469}`u{1F3FB}`u{200d}`u{1F9B1}"」として表現できる。
ちょっとした文字列処理でも、サロゲートペアが入り込むと、スクリプト/マクロやセル数式などの出力が思いも寄らないものになる可能性がある。こうしたとき、PowerShellコマンドなどで、コードポイントやUTF-16での16進数出力を見ることができるなら、その原因を判別しやすい。

この記事に関連するニュース
-
河野太郎氏の「エゴサ」力、さらにアップ? ジョージア語、タイ語にも反応、駐日大使も「恐れ入りました」
J-CASTニュース / 2024年11月17日 13時25分
-
IPv6アドレスは先頭を見ればどんな種類かわかる
ASCII.jp / 2024年11月10日 10時0分
-
あらためてIPv6基本のキ
ASCII.jp / 2024年11月3日 10時0分
-
Excelをノーコードで自動化しよう! パワークエリの教科書 第25回 データの途中に文字を挿入する方法
マイナビニュース / 2024年10月28日 11時0分
-
Windowsで現在どのネットワークアダプタがインターネット接続に使われているかを調べる方法
ASCII.jp / 2024年10月27日 10時0分
ランキング
-
1ゲーム『まどマギ』来春に配信延期で謝罪「更なるクオリティアップを目指し…」
ORICON NEWS / 2024年11月20日 17時9分
-
2「まだ妊娠6ヶ月だよ? え???」 第2子妊娠の菊地亜美、“巨大すぎるおなか”に驚き隠せず ファンもびっくり「えーー!」「これは凄い」
ねとらぼ / 2024年11月20日 12時51分
-
3「Pixel 9」が実質1万8900円に Google ストアのブラックフライデー、11月21日~12月3日に開催
ITmedia Mobile / 2024年11月19日 12時1分
-
4「情報を漏らされ振り回され」「もう支えられない」 モデラー、Vtuberの“モデル使用権を剥奪” 「全サポート終了」
ねとらぼ / 2024年11月19日 16時23分
-
5薄型テレビで100V型オーバーの時代がやってくる!? REGZAビッグサイズラインアップ登場
ASCII.jp / 2024年11月20日 11時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





