

スーパーコンピューターの系譜 本格稼働で大きく性能を伸ばしたAuroraだが世界一には届かなかった
ASCII.jp / 2024年5月20日 12時0分

2024年5月12日よりドイツのハンブルグでISC24が開催され、この2日目になる5月13日にTOP500の最新リスト(2024年6月版)が公開された。結論から言えば、引き続きAMDのFrontierが1位を堅持。これで5期連続での1位となった。Auroraは大きく性能を伸ばし、こちらもRmax(実効性能)で1EFlopsを超えたものの、Frontierを超えることはできず、2位に終わった。まずはこのあたりから説明したい。

Auroraの理論性能は1980.01PFlops ダイナミックに動作周波数を下げて電力効率を上げる
2023年11月に初ランクインした際のAuroraの詳細は連載746回で説明したが、おおよそシステムの半分を稼働させた段階で実効585.34PFlopsほど。消費電力は24.687MWと発表されていた。
コア数は474万2808で、この際の構成は5439ノードと筆者は推定した。ノード構成はXeon Max 9470(52コア)×2+Data Center Max 1550×6という構成。Xeon Max 9470は2.4GHz駆動と発表されており、一方Data Center Max 1550の方は970MHzあたりの駆動速度と推定した。
さて今回であるが、Auroraのページによればコア数は924万6128個で、2023年11月比で1.95倍程になる。逆に言えば2023年11月の稼働状況は51.2%ほどになる計算で、当時の推定は正しかったようだ。

意外なのはRpeak(理論性能)で、ギリギリ2EFlopsに届かない1980.01PFlopsとされている。まずノード数の方からいくと、構成が同じくXeon Max 9470×2+Data Center Max 1550×6だとすればノードあたり872コアであり、総ノード数は1万624となる。
Rpeakから逆算すると、ノードあたりの理論性能は186.37TFlopsほど。これは2023年11月の数字(194.76TFlops)からさらに下がっている。CPUは2.4GHzとこちらも明示されているから、Xeon Max 4970の性能は1個あたり1996.8GFlopsで変わらず。つまり6つのData Center Max 1550あたりの理論性能が30396.1GFlopsとなる。これは動作周波数をさらに引き下げ、928MHzあたりで稼働させているという計算になる。
もっともインテルのプレスリリースによれば、今回の結果は10624ノードのフル構成ではなく、全体の87%にあたる9234ノードを利用しての結果、としている。
これを加味するとノードあたりのRpeakの数値は214.43TFlopsになるのだが、今度はコアの数字が合わない。どうもTOP500に対する報告では、RpeakやTotal Coresなどの数字はフル構成(10624ノード)のもので、Rmaxや消費電力などだけが9234ノードでの数字ということらしい。これが正しいとしても、ずいぶんダイナミックにData Center Max 1550の動作周波数を下げたものである。
理由の1つは消費電力だろう。今回Auroraの消費電力は3万8698.36KWとなった。前回が2万4686.88KWなので、56.8%ほどの増加に留められている。筆者は連載746回でフルシステムのAuroraの消費電力を39.5~42.0MW程度と見積もったが、これよりも若干下回っているあたりは、かなり努力したものと思われる。実際Rpeakに対する電力効率は下表となり2割弱の効率改善が図られている。
無理に動作周波数を引き上げると急速に性能消費電力比が悪化するので、より最適なバランスを狙った結果、ということなのだろう。
それは良いのだが、インテルが2023年5月に発表した公約である"Aurora is expected to offer more than 2 exaflops of peak double-precision compute performance when launched this year."(今年立ち上げられるAuroraは、倍精度演算性能が2EFlopsを超えることを予定している)を実現できていないことになる。
おそらくインテルにも、これを実現できない自覚があったのだろう。すでにプレスリリースが落とされている(したがって、上のリンクはウェブアーカイブである)。むしろAuroraの問題は、上がらない効率である。理論性能であるRpeakと実効性能であるRmaxの数字は以下のようになっており、効率は51.1%まで落ちている。
もっとも先に書いたようにRpeakは1万624ノードのものである公算が高い。仮にこれが9234ノードだとすると1720.95PFlopsになる計算で、効率は約58.8%になる。51.1%よりはだいぶマシであるが、TOP500の順位は300位前後でしかない。まずはこの電力効率の悪さをなんとかするのが最初の仕事だろう。ちなみにFrontierは70%である。
余談だがプレスリリースではHPCG(High Performance Conjugate Gradient: https://hpcg-benchmark.orgで示される、共役勾配法などを利用したベンチマーク)の結果もランキング3位に入ったとしている。この際にはシステムの39%を利用したとのこと。なのだが、HPCG 500のリストによれば以下のようになっている。
仮に100%のフル構成で稼働させ、これに応じて性能が向上したとしても14391.28TFlopsで、ギリギリFrontierと同等といったところ。性能が本当に向上するのか怪しいあたり、手放しで褒めるにはやや厳しい数値ではある。
5期連続で世界一のFrontierは 消費電力が少ないのが強み
今回間に合うかと思ったEl Capitanであるが、残念ながらデータは登録されていない。連載751回でも触れたように、すでに納入と設置はスタートしているのだが、まだ今回はデータを出せるところまではたどり着かなかったようだ。引き続きTOP500にはFrontierが君臨しているわけだが、今回アップデートがあった。

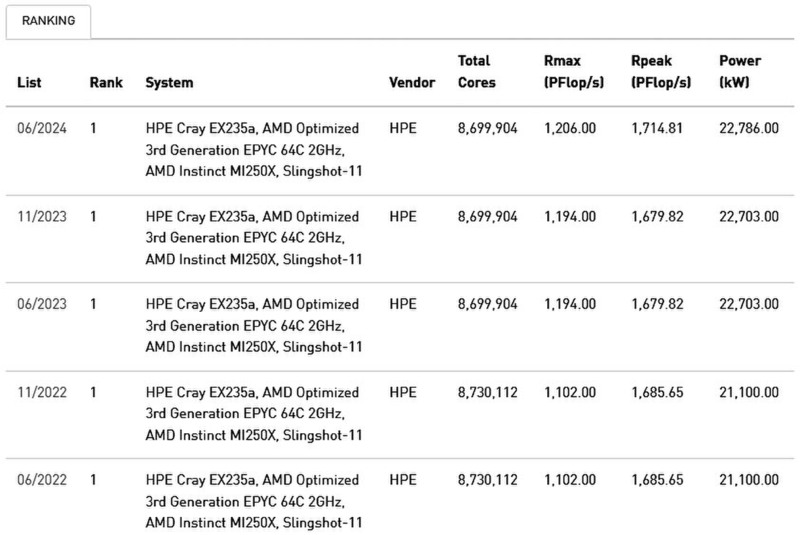
以前Frontierのノード構成は連載670回で説明したが、これは2022年6月初登録のもの。2023年6月以降はTotal Coreが869万9904個になっている。2022年11月までは9248ノードだったが、2023年6月以降は9185ノード+208コア、という不思議な数字になっている。
まさか既存のノードにInstinct MI250(208XCU)を1つ追加したわけではないと思うが、そのあたりはいい。不思議なのはこれでRpeakが次第に増えていることだ。連載670回で筆者はInstinct MI250Xの動作周波数を1.6GHz程度に落として運用しているのだろうと推定したが、チューニングが進んで動作周波数を引き上げているのかもしれない。
電力効率は下表のとおりで、2024年は2023年より効率こそわずかに落ちているものの性能消費電力比はむしろ向上しており、また実効性能も1.2EFlopsに達しているなど、かなり実用的であることがわかる。
前述ようにHPCG 500では富岳におよばないものの、富岳はFrontierよりも消費電力が多い(LINPACKの場合だからそのまま数字を当てはめて良いか疑問は残るが2万9899KWである)ので、HPCGの場合でも性能消費電力比はFrontierが富岳を上回っているかもしれない。
運用コストという意味では、同じ量の計算をするならFrontierの方がやや安価になる(≒消費電力が少ない)というのは、Frontierの強みの1つだろう。次回のTOP500にはEl Capitanが出てくることになるので、このあたりがどう変わるか楽しみである。

性能消費電力比を重視したGreen 500では Grace Hopper GH200がトップ10の半分を占める
もう1つの今回の目玉はGrace Hopperの躍進である。電力効率を評価するランキングGreen 500のTop 10は下の画像のとおり。
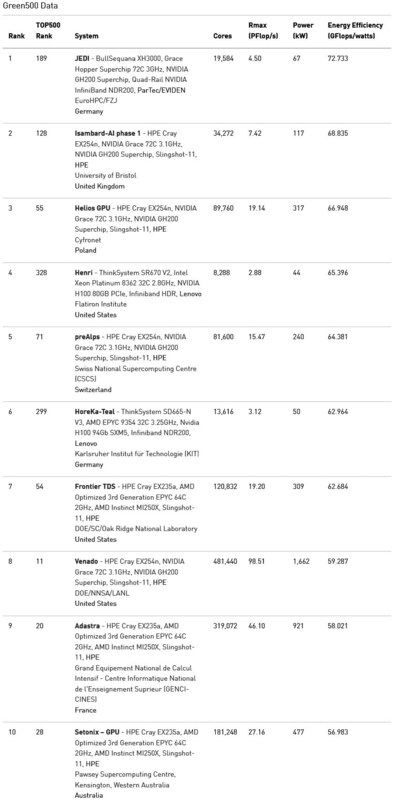
これは性能消費電力比を重視したリストだが、Top 10の1/2/3/5/8位と半分をGrace Hopper GH200が占めている。絶対性能という意味では11位に入ったロスアラモス国立研究所のVenaroがGH200では一番高いが、コア数48万1440個。2560ノードのGH200と920ノードのGraceチップを組み合わせた構成である。
ただ、ピーク性能は100PFlopsに届かない程度でしかない。とはいえ、ローレンス・リバモア国立研究所のSierraや国立エネルギー研究科学コンピューティングセンターのPerlmutterと同等以上の性能を、比較的コンパクトに構成できる(価格は不明だが、Sierraよりも間違いなく安いだろう)のは大きな強みである。
Venadoは演算性能よりもむしろMemory Wall(メモリー帯域のボトルネック)に向けた構成なのだそうで、これをそのままほかに利用できると考えるのはまた違う話なのだろうが、運用コストを抑えつつそこそこの性能を発揮できる、というのはHPCの分野でも重要になりつつあることを考えると、次のTOP500ではさらにGraceやGrace Hopperを採用するノードが増えるかもしれない。


この記事に関連するニュース
-
AMD、EPYC 4004シリーズを発表 - Zen 4 Raphaelベースの1 Socket EPYC、Xeon E対抗
マイナビニュース / 2024年5月21日 22時0分
-
Supermicro、業界最新のアクセラレータを搭載した ラックスケール液冷ソリューションで、AIとHPCの融合を目指す
共同通信PRワイヤー / 2024年5月17日 9時41分
-
Intel「Aurora」スーパーコンピューターが“エクサスケール”突入 - 運用容量は87%まで上昇
マイナビニュース / 2024年5月14日 14時1分
-
2024年6月版スパコンランキングTOP500が発表、米国の「Frontier」が5連覇を達成
マイナビニュース / 2024年5月13日 18時59分
-
NVIDIA Grace Hopper、AI スーパーコンピューティングの新時代を先導
PR TIMES / 2024年5月13日 18時15分
ランキング
-
1「こんなに種類あるんですね」 コレクターが収集した交通系ICカードの数々に「すごい」「素敵です」
ねとらぼ / 2024年6月2日 20時45分
-
2「LUMIX S9」のストックフォト問題は何がいけなかったのか?
ITmedia NEWS / 2024年6月2日 7時20分
-
3AIの急速な導入がWindowsの予定を変えた!? Windows 12がすぐには出ない可能性
ASCII.jp / 2024年6月2日 10時0分
-
4タイヤを転がし続けて16年!? マルゼンCMが令和にバズる CM誕生のきっかけや16年継続した理由を本人に聞いた
ねとらぼ / 2024年6月1日 20時30分
-
5その「スタート」ボタン、広告かも 国民生活センターが注意喚起 意図しないサブスク契約の可能性も
ITmedia NEWS / 2024年5月31日 21時39分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





