

Lunar Lakeはウェハー1枚からMeteor Lakeの半分しか取れない インテル CPUロードマップ
ASCII.jp / 2024年6月24日 12時0分

6月4日から開催されたCOMPUTEX TAIPEI 2024は、こういうと失礼かもしれないが、予想外の盛り上がりを見せた。特集ページに記事一覧があるが、昨年のCOMPUTEX TAIPEI 2023と比較して記事の数が多いというのがその傍証ともいえる。
ちなみに主催者であるTAITRA(台湾貿易センター)の発表によれば、2024年の参加者は8万5179人。2023年が4万7594人なのでらほぼ倍増である。ちなみにコロナにより休止する前の2019年は4万2495人であり、今年がいかに盛況だったかがわかろうというもの。

筆者の個人的な感想で言えば、昨年は久しぶりの再会ということで出展者・参加者ともに様子見というか、恐る恐るという感じだったのが、今年は一気に弾けた感がある。昨年は「この調子だとCOMPUTEXは遠からずなくなるのではないか」という気がしたのだが、今年は見事に復調した。
そんな雰囲気に感化されてか、インテルも事前にプレスツアーを行ない、会期中も基調講演にブース展示となかなかに盛りだくさんな内容だった(いずれもレポートは中山智氏)。というわけで、今回はCOMPUTEXで判明したインテルのロードマップを説明しよう。
Snapdragon X Eliteの登場で 予定が前倒しとなったLunar Lake
Lunar Lakeの概略はプレスツアーレポートにまとまっているので、もう少し突っ込んだ話をしよう。まず基本的なポジショニングから。本来Lunar Lakeは、従来で言うところのY-SKUのリフレッシュにあたる製品で、いわゆるミニノート向けの製品である。
2024年発売ということは企画は2019年か遅くても2020年あたりであり、もう世の中にはSnapdragon 800ベースのWindows on Armマシンが存在していたから、これを意識したことは間違いない。結果的にQualcommのSnapdragon X Eliteと見事に競合できる製品になったあたりは、インテルによるQualcomm製品の見通しが間違っていなかった、というあたりだろうか。
予想外だったのは、登場する順番である。2022年におけるロードマップが下の画像であるが、本来はArrow Lakeの後にLunar Lakeが出てくるはずだったのが、Snapdragon X Eliteの出荷が予想より早かった(あるいはマイクロソフトによるCopilot+の実装が予想よりも早かった)あたりで、Lunar Lakeを前倒しにせざるを得なくなった。
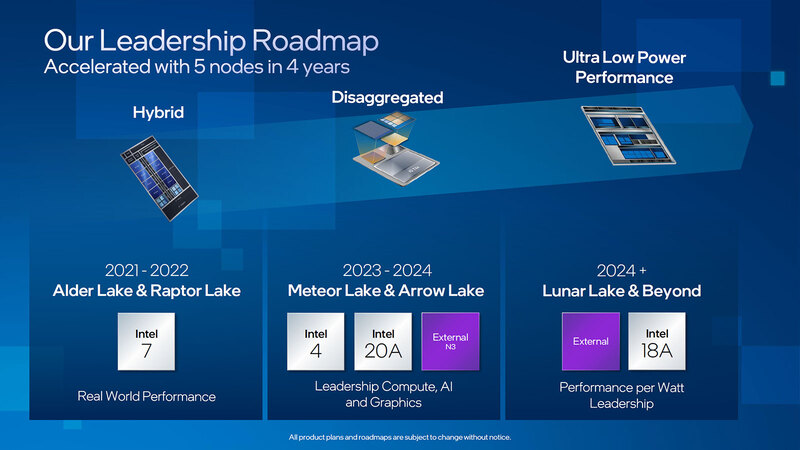
ここで問題になったのは、「前倒しするとして、ではどのプロセスを使うか」である。Intel 4は昨年無事にMeteor Lakeに実装されて出荷開始されたが、決して生産量は多くない。もっと言えば、Intel 4を使うのがMeteor Lakeだけであり、量産プロセスはIntel 3が主流になるのは明白である。
6月16日からホノルルでVLSI Symposium(正式名称は"2024 IEEE SYMPOSIUM ON VLSI TECHNOLOGY & CIRCUITS")が開催されているのだが、テクニカルセッションの最初でインテルが"An Intel 3 Advanced FinFET Platform Technology for High Performance Computing and SOC Product Applications"という講演を行なっている。
この講演の話はまた別の記事でお伝えするとして、ポイントは信頼性である。
Lunar Lakeは3nmプロセスのN3Bを採用
Intel 3はネイティブ1.2Vで動作するトランジスタを追加でサポートするのだが、その1.2V出力トランジスタの信頼性が「業界標準である動作寿命10年をサポートする」と書いてあり、逆に言えばIntel 4までの通常電圧トランジスタの寿命は? となるわけだ。講演では当然そのあたりには触れていない。
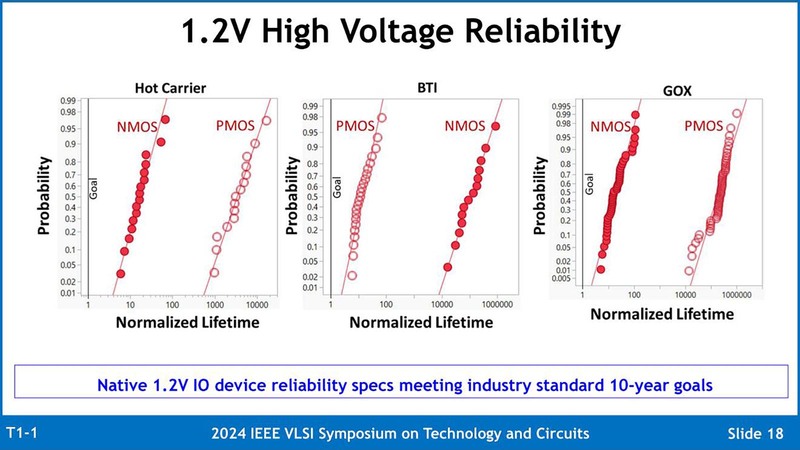
言ってみればIntel 4はIntel 3の先行試作プロセス的な位置付けと考えるのが妥当だろうし、そうであればMeteor LakeしかIntel 4を使わないというのも納得できる。
したがって、本来ならIntel 3あたりを使いたかったのだろうが、こちらはXeon 6向けにまず予約が入っており、Lunar Lakeの量産に使えるほどのキャパシティがなかったのだろう。それでも他に使えるプロセスがなければ、Xeon 6の量産スケジュールを調整するなどして無理やり突っ込むしかなかったのだろうが、ここで幸運にもTSMCのN3Bが空いていた。
TSMCのN3BはTSMCとしては3nmの最初のプロセスで、2022年末に量産がスタートするものの、当初全量をAppleが予約していた。ところがこのN3B、歩留まりが非常に悪いという欠点を抱えており、それもあってAppleは途中でこのN3Bプロセスの契約を解除し、Apple自身もN3Eプロセスへ移行した、という話は昨年10月に話題が出ている。
N3EはN3Bの改良型というか、本来は廉価版という位置づけであり、N3Bが25工程でEUV(極端紫外線)を利用するのに対し、N3Eは19工程に削減。さらに配線層をダブルパターニングからシングルパターニングに改めたという話が聞こえてきている。
ちなみにこのダブルパターニングからシングルパターニングへの更新、さすがに全配線層ではないだろうとは思うが、配線がN3Bより太くなったものと思われる。そもそも一般論としてM6やM7以上なら普通はシングルパターニングで実装できるからだ。
その分実装密度が下がりそうな気もするのだが、結果から言えば歩留まりが大きく向上(N3Bは試作段階での歩留まりが55%程度だったが、量産に入ってからも60%台だったという話を聞いている:N3Eは試作段階からもっと歩留まりが高かった)し、ダブルパターニングの廃止やEUVの工程数削減などで生産コストも下がり、それでいてなぜか性能も上ったそうで、それはみんなN3BよりN3Eを使いたがるわけである。
この結果N3Eは大人気であり、AMDですら今年提供できるN3Eプロセスの製品はTurinベースのEPYCだけで、Ryzenなどは引き続きN4での提供となっている。本当ならインテルもN3Eを使いたかったのかもしれないが、こういう事情で利用は不可能である。そこに来てN3Bの生産枠が余っているという話であれば、歩留まりの低さには目をつむってでも使わざるを得なかった、というあたりが正確なところかもしれない。
ただ実はこれ、けっこう厳しい話である。Lunar Lakeのパッケージはほぼ正方形に見えるが、微妙に縦長(27×27.5mm)である。なぜわかったかというと、パッケージに搭載されているLPDDR5Xの寸法が7×12.4mmだからで、ここからの推定である。

Lunar Lakeはウェハー1枚から426個しか取れない 歩留まりを考えると実質的に1枚から取れるのは255個ほど
Lunar Lakeの構造は下の画像のとおりであるが、同じようにコンピュート・タイルの寸法を確認したところ、16.3×8.6mmほどになり、140.18mm2という数字が出てきた。

連載734回でMeteor Lakeの寸法を推定した時が73.9mm2なので、ほぼ倍になる。Meteor Lakeならウェハー1枚から720個あまりのコンピュート・タイルが取れたのに対し、Lunar Lakeでは426個ほどになる計算だ。
おまけに歩留まりが、もし先程の60%という数字が改善していないとすれば、実質的にウェハー1枚から取れるのは255個ほどである。そしてTSMCのN3のウェハーの価格は2万ドルを超える(安価になったN3Eで2万ドルを切るかもしれない)そうで、ということはコンピュート・タイル1つあたりの製造原価は78ドルくらいになる。
これは結構な金額である。というのはLunar Lakeにはこれに加えてベース・タイル(Intel 22FFLベース)とプラットフォーム・コントローラー・タイル(これはTSMC N6)を、Foverosを使って積層し、そこにLPDDR5X-8533×2を載せ、さらに全体のパッケージが必要になるからで、製造原価を積み上げていったら200ドルでは効かないだろう(おそらく300ドル台)。
あくまでも製造原価でこれである。製品価格は倍では効かないだろう。それでいて最終製品はSnapdragon X Eliteベースの製品に対して相応の価格競争力を持たせないといけない。今回構成には相当悩んだものと思われる。最終的にPコア×4+Eコア×4という形にし、Meteor Lakeで実装されたI/OタイルのLP Eコアを省いた、というあたりもこのあたりの損得勘定を相当考えてのことと思われる。
「だったらなにも全部コンピュート・タイルに入れる必要はなかったのでは?」という疑問は当然湧くわけだが、競合がSnapdragon Xであることを考えるとNPUの絶対性能の向上は必須である。
Meteor LakeのNPU構成は連載740回で示したとおりだが、Copilot+の要件である40TOPSの性能を引き出そうとすると、4倍の性能改善が必要になる。
Meteor Lakeでは2つだったNCE(Neural Compute Engine)はLunar Lakeでは6個になり、しかも動作周波数は1GHz→1.6GHzに強化されたことで48TOPS(NCPの数が3倍、動作周波数が1.6倍)を実現したと考えられるが、まずNCEを3倍に増やす時点で、N6ではダイの面積が大きくなりすぎる。しかも動作周波数を引き上げつつ消費電力を抑えようとすると、N6やN5では厳しく、N3クラスのプロセスが必要になる。
GPUも同様に、限られたエリアサイズでそれなりの性能を発揮する必要がある。Meteor Lakeの場合と異なり、外部にディスクリートGPUを装着するという選択肢はあり得ないので、ある程度の性能を自前で確保する必要がある。
Lunar LakeではMeteor LakeのXe-LPGを改良したXe2を搭載するが、Xeコアの数は同じ(最大8)ながら、動作周波数をそこまで上げられない(Meteor LakeのハイエンドであるCore Ultra 9 185Hは最大2.35GHz駆動)。
もう1つの問題はメモリー帯域で、LPDDR5X-8533×2だが、帯域そのものは68.3GB/秒程度でしかない。というのはLPDDR5X-8533がx32構成のためである。これも筆者には疑問で、x64構成のものを使えば2つで128bit幅が実現でき、十分なメモリー帯域が確保できるはずなのだが、現状ではDDR5-5600搭載のMeteor Lake(89.6GB/秒)にも劣る帯域になっている。
パッケージ、あるいは配線の取り回しの関係でx64を選べなかったのか、それとも入手量の関係で選べなかったのか、あるいはなにか他の理由かはわからないが、とにかく利用できるメモリー帯域がMeteor Lakeより下がっている中で性能を確保するためにいろいろと仕組みに工夫を凝らさざるを得ず、結果的にこちらもN3Bでないと収まらなかったのではないかと想像される。
またGPUに関しては、現状少なからぬアプリケーションがGPUでAI推論を行なっており、こちらに向けての性能強化をしている中で、低い消費電力枠で相応に動作周波数を引き上げる(1.6GHz)ためにはN3Bが必要だった、という見方もできる。
といったあたりで、仮にGPUなどを別タイルにしても結局N3Bで製造するなら、もう一緒にした方が楽、という判断が下されたのではないかと筆者は想像している。
要するにLunar Lakeはいろいろと厳しい制約条件の中で、最大限Snapdragon Xに肩を並べる性能を確保するために、変な実装になっている感が非常に強い製品である。次回から、もう少しコンポーネント別に詳細を説明していく。

この記事に関連するニュース
-
Core Ultra 7 265K&RTX 4070 Ti SUPER搭載ゲーミングPC、空冷クーラーでも本当に大丈夫?
ASCII.jp / 2024年11月16日 10時0分
-
Lunar LakeはMeteor Lake比でどこまで性能向上? 最新ドライバ適用「Core Ultra 7 258V」搭載ノートを試す(後編)
マイナビニュース / 2024年11月14日 15時0分
-
Lunar Lake搭載で約946g! 超軽量ビジネスPCとして格が上がった新型「MousePro G4」を試す
ITmedia PC USER / 2024年11月6日 15時0分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
-
Lunar Lakeは省電力でも高性能! 仕事もAIもゲームも大幅強化な「Core Ultra 7 258V」搭載ノートを試す(前編)
マイナビニュース / 2024年10月22日 16時47分
ランキング
-
1「芸が細かいw」 プラレールのパーツをよく見たら……? “まさかの表記”に「なるほど!」と称賛集まる
ねとらぼ / 2024年11月16日 9時0分
-
2Bluesky、1日で100万人以上増加、エンゲージメントはXの10倍以上という調査報告も
マイナビニュース / 2024年11月15日 15時46分
-
3「怒らないから名乗り出なさい」 軟膏と一緒にしまわれていたのは…… “一歩間違えれば大惨事”のミスに背筋が凍る 「これはヤバい」
ねとらぼ / 2024年11月16日 20時0分
-
4吉野家の出前、ロボットで配送 出前館・パナと実証実験
ITmedia NEWS / 2024年11月15日 17時15分
-
5極薄な折りたたみスマホ「Galaxy Z Fold Special Edition」が登場 日本投入はある?
ITmedia Mobile / 2024年11月16日 10時5分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





