

Lunar LakeではPコアのハイパースレッディングを廃止 インテル CPUロードマップ
ASCII.jp / 2024年7月1日 18時0分

前回はLunar Lakeのプロセスとタイル構造で話が終わってしまったので、今回はもう少し内部の話をしよう。
Lunar LakeはPコア4つとEコア4つの珍しい組み合わせ
まずは一番の要であるプロセッサーの構造である。Lunar LakeもPコアとEコアの組み合わせであり、その意味ではAlder Lake(Lakefield)以降で採用されているハイブリッド・テクノロジーを継承した構成である。ただそれが4+4という構成なのはやや珍しい。
もちろん技術的には可能であるのだが、Eコアが4つというのは、これまでの同社のプロセッサーからするとかなり少ないように感じる。おそらくはであるのだが、1つには次回説明するようにEコアの性能が大幅に上がり、性能的にバランスが取れると判断されたのかもしれないし、Eコアを8つにすると面積的に厳しかったのかもしれない。
だったらPコアの数を2つに減らせば良かったようにも思うのだが、ハイパースレッディングなしでの2コアはコア数というか同時処理スレッド数が不足すると判断されたのかもしれない。なんというか、微妙なバランスを取った構成になっている。
またMeteor Lakeで搭載されたI/Oタイル上のLow Power EコアはLunar Lakeでは省かれている。その代わりというべきか、EコアそのものがLow Power Configurationで構成されている。N6プロセス上のLP Eコアより、N3BのLP Eコアの方が消費電力が少なかったのかもしれない。結果としてパワーマネジメント系はMeteor Lakeとまったく異なるものになっている。
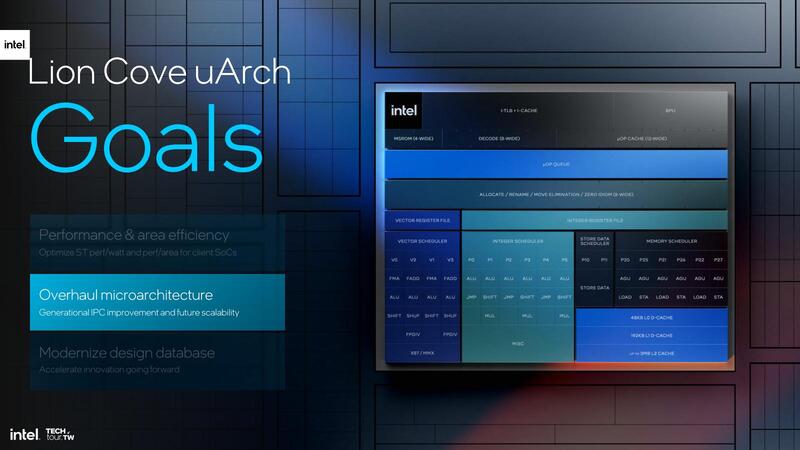
そのあたりの話はいずれ話をするとして、まずはPコアとEコアについて。今回PコアはLion Cove、EコアはSkymontと呼ばれるコアがそれぞれ採用されているが、このLion Cove/Skymont共に、従来のコアから大幅に中身が変わっている。
Alder LakeのGolden CoveからMeteor LakeのRedwood Coveまでは基本同一コアで Golden Cove→Raptor Cove(L2:1.25MB→2MB)→Golden Cove(L1 I-Cache:32KB→64KB) とキャッシュサイズの増量が主要な違い(細かなアップデートは除く)でしかない。
ということで、Alder Lakeに搭載されたGolden CoveとLion Coveを比較すると下表のように、猛烈に強化されているのがわかる。
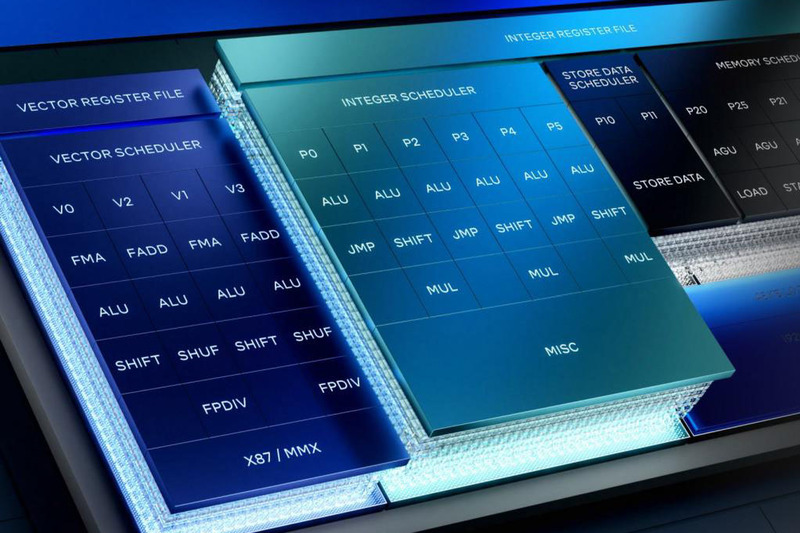
もう少し細かく見てみよう。まずフロントエンドであるがDecodeは1サイクルあたり8 x86命令を処理可能であり、μOp Cacheは最大12 wideまで拡張されている。以前の説明が正しければ、1つのx86命令は1つないし2つのμOpに分解されるので、μOp Cacheは最低でもx86換算で6命令/サイクル、平均しておそらく9命令/サイクル程度の供給が可能になると思われる。

次にIssue Port周りだが、そもそもポートの数が大幅に増やされ、かつ同時発行命令が増えたことに対応して内部バッファの容量(ROBやInstruction Windowなど)も増量されている。

実行ユニットに関して言えば、Golden CoveではPort 00/01/05をIntegerとVectorで共用、という形になっていたが今回これが分離された。これがスループット向上につながるか? というと、短期的にはNoである。

例えばAVX命令などで計算を行ない、その結果を格納するような処理では以下の形で処理される。
Vector→ALU→Vector→ALU→...
Vectorの処理が終わるまでALUが動くことはない。これはVectorの結果を取り込む、あるいは次の計算のためのパラメーターをレジスターにセットするから、Vectorの処理が終わってからでないと意味がないからで、ポートを共用していても別にそこがボトルネックになるわけではないし、ポートを分けても並列度が上がることはない。
しかし、これスケジューラーの方からすれば1つのポートにALUとVectorがつながっているのはスケジューリングが複雑になるだけだし、スライドにもあるように将来の拡張性を考えたらポートを分離した方が良い、という判断になったものと思われる。
Pコアのハイパースレッディングを廃止
ALUはALUが同時に6個動作するほか、シフトや乗算(MUL)、分岐(JMP)も3つずつに増量された。

またFPU/Vectorも同時4命令処理に拡充されている。FMAが256bitとあることからもわかるように、まず間違いなくAVX512は実装されていない。ただほぼ同じアーキテクチャーを利用すると想定されるGranite Rapidsの場合、V0~V3にAVX512の実行ユニットを追加する形になると思われる。

データキャッシュも変更になった。Golden Cove~Redwood Coveでは48KBのL1 D-CacheとL2という組み合わせだったが、Lion CoveではL1 D-CacheがL0 D-Cacheになり、新たに中間的なLatencyを持つ192KBのL1 D-Cacheが追加された。

つまりデータ側はL0~L3まで4レベルのキャッシュ構造となった格好だ。レイテンシーも若干削減されているが、帯域幅自体は変わらないことになっている。
そして実行ユニットが強化された分、ロード/ストアーユニットも当然強化する必要がある。AGUが6個となり、またロードアクセスとストアーアクセスの両方が3個づつになった。これに合わせてData TLBのエントリー数も96→128に強化されている。

もう1つの大きな変更は、Pコアでハイパースレッディングを無効化(というか、削除)したことだ。ハイパースレッディングというか一般にSMT(Symmetric Multi-Threading)のメリットは以下の2つある。
- メモリーアクセスのレイテンシーの遮蔽(あるスレッドがメモリーアクセス待ちをしている間、他のスレッドがコアを利用することで、無駄な待機時間を減らす)
- 実行ユニットの利用効率向上(アウト・オブ・オーダー実行では、必ずしも全部の実行ユニットがフルに使われるとは限らないので、複数スレッドを同時に実行することで実行ユニットの利用効率を上げる
インテルがPentium 4にハイパースレッディングという名前でSMTを実装した時の最初の目的は2番目であり、これで最大30%性能が向上する、とされていた。実際現在でも、ハイパースレッディングを有効にした場合、IPCないしスループットが30%ほど向上し、その一方で消費電力が20%ほど増加するとしている。20%の消費電力増加で30%性能が向上するなら、これは悪くないバーターなわけだ。
ただ、Lunar Lakeの場合には少しシナリオが異なる。もともとMeteor Lakeの頃からそうだが、雑多な処理はEコアに任せて、処理負荷の重い物だけをPコアに行なわせることで効率を上げるのがインテル・ハイブリッド・テクノロジーであり、これを効果的にするためにAlder Lakeで導入されたのがインテル・スレッド・ディレクターである。
そしてデスクトップ向けはともかくLunar Lakeの使われ方を考えた場合、シングルスレッド処理性能が高いのが重要で、Pコア全体でのマルチスレッド処理はそれほど重要視されないシナリオが考えやすい。こうなると、ハイパースレッディングというかSMTはむしろシングルスレッドの性能を妨げる要因になりえる。
つまり本来なら効果的に全部の実行ユニットをフルに使うことで性能が上げられるはずなのに、SMTを利用することで別のスレッドと実行ユニットの取り合いになる可能性があるからだ。

またSMTを実装する際には、ある程度エリアサイズのオーバーヘッドが発生する。以前Core 2の時は10%程度とされていたが、具体的には完全にスレッドごとに独立して持つもの(例えばPC:Program Counterなど)はそれほど多くない。
ただ、例えば内部のレジスターファイルは、どちらのスレッド用かを管理するために1bitの管理フラグを追加する必要がある(から、64bit長のものが65bit必要になる)といった具合に、あちこちに余分な回路が必要であり、そうしたものの合計が大体10%ほどになるわけだ。
これはデスクトップあるいはサーバー向けには許容されるのだろうが、前回も説明したようにギリギリまで面積を詰めたいLunar Lakeにはこの10%も惜しかったのだろう。
そしてSMTを無効化することで、消費電力も若干減る(扱うスレッドが1つで済むから、スレッド間の調停も不要だし、SMTをサポートするための回路もなくなる分、そこで費やしていた消費電力も削減できる)。こういう判断に基づき、Lunar Lakeではハイパースレッディングが廃止された。「無効化」ではなく「廃止」なのだそうで、物理的にLunar Lakeではハイパースレッディングが利用できなくなっているらしい。
このあたりはまだ明確ではないが、おそらくLion CoveもXeon向けに利用されるだろう。それがGranite Rapidsなのか、その次のDiamond Coveなのかは不明だが、こうした転用を考えた場合、ハイパースレッディングの機構そのものは論理設計上は残っており、ただしそれを物理設計に落とす段階で機構そのものを省いた、という形で実装されていると筆者は考えている。これは、同じダイをEPYCとRyzenで共有する(からSMTを無効化することはできても省けない)AMDとの違いである。
なお、2022年頃はGranite RapidsはRedwood Coveベースという報道もあったが、あれからだいぶロードマップが変わっているので、まだRedwood Coveベースなのかは不明で、Lion Coveベースの可能性もある。
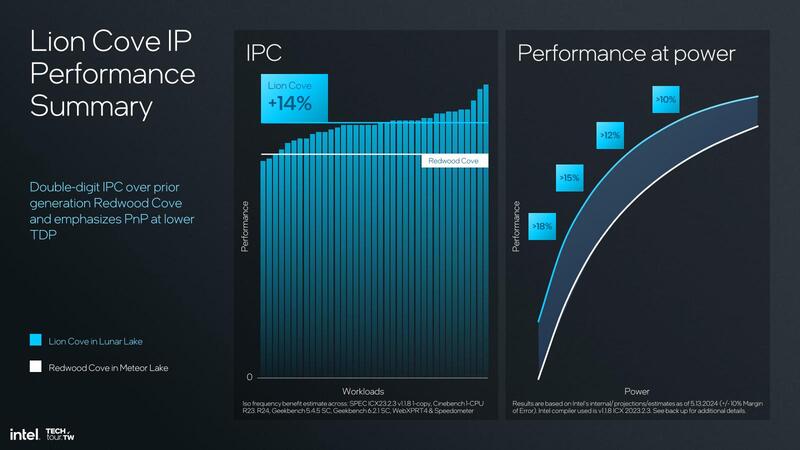
こうした改良の積み重ねで、Lion CoveのIPCは平均14%の向上を実現したとされている。特に消費電力が少ない(≒動作周波数が低い)時のIPC向上率は18%以上としており、これでSnapdragon Xシリーズに搭載されたNuvia由来のOryonコアを圧倒したい、というわけだ。
動作周波数の倍率指定が従来の100MHz刻みから16.67MHz刻みに
ほかにRedwood Cove(というか、Golden Cove世代)からの違いとして、内部の電力管理が完全にダイナミックになったこと、動作周波数の倍率指定が従来の100MHz刻みから16.67MHz刻みになったこと。それと内部の作り方が変わったことも示された。



こちらはユーザーには関係ない話であるが、これまでPコアはインテルの工場のみで製造されていたのが外部(TSMC N3B)の製造に切り替わったことと無縁ではないだろう。
Pコアだけで文量があふれてしまったので、Eコアは次回説明する。

この記事に関連するニュース
-
Lunar LakeはMeteor Lake比でどこまで性能向上? 最新ドライバ適用「Core Ultra 7 258V」搭載ノートを試す(後編)
マイナビニュース / 2024年11月14日 15時0分
-
薄軽VAIOの旗艦モデル「VAIO SX14-R」の“数値以上の変化”を知る
マイナビニュース / 2024年11月1日 8時0分
-
Intelの新型「Core Ultra 200Sプロセッサ」は何がすごい? 試して分かった設計方針の成果と限界
ITmedia PC USER / 2024年10月25日 6時0分
-
Core Ultra 9 285KとCore Ultra 5 245Kの実力検証! Arrow Lakeは本当に高速省電力? 対14900K&9950Xベンチマーク
マイナビニュース / 2024年10月25日 0時0分
-
Lunar Lakeは省電力でも高性能! 仕事もAIもゲームも大幅強化な「Core Ultra 7 258V」搭載ノートを試す(前編)
マイナビニュース / 2024年10月22日 16時47分
ランキング
-
1歴史的名作『Half-Life 2』20周年!期間限定無料配布、拡張パック同梱するアプデ、資金不足やハッキング被害にも触れるドキュメンタリー映像などでお祝い
Game*Spark / 2024年11月16日 13時52分
-
2Amazonブラックフライデーで出品されたら即ポチ必至「PC&スマホ・タブレット」5選【ネット通販傑作遊びモノ】
&GP / 2024年11月16日 20時0分
-
3あれ、意外とイイかも? 電車派必見なiPhone「マップ」アプリの便利機能3選
&GP / 2024年11月16日 7時0分
-
4極薄な折りたたみスマホ「Galaxy Z Fold Special Edition」が登場 日本投入はある?
ITmedia Mobile / 2024年11月16日 10時5分
-
5不具合続いた『Wizardry Variants Daphne』実装予定機能を時期未定に―開発・運用体制の大幅増強を宣言
Game*Spark / 2024年11月16日 14時57分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





