

医師とのタッグで挑む、医療用マルチモーダルAIの先駆け的研究
ASCII.jp / 2024年7月2日 10時0分

- 研究実施者:助田一晟、澤野晋之介(東京大学大学院)
- 研究テーマ:JMed-LMM:医療分野における大規模マルチモーダルモデルの開発
- 担当PM:瀬々 潤(ヒューマノーム研究所代表取締役社長)

医療テキストに心電図、レントゲン画像を組み合わせたマルチモーダルモデル
東京大学大学院の助田一晟さんと澤野晋之介さんが覚醒プロジェクトで取り組む研究テーマが、「JMed-LMM:医療分野における大規模マルチモーダルモデルの開発」である。JMed-LMM は「Japanese Medical Large Multimodal Model」の略で、今話題の生成AI系技術を活用した医療AIの土台となる基盤モデルの開発を目標とするものだ。
テキストや画像、音声などの入力情報(モーダル)を単一で処理するのではなく、同時に扱うAIを「マルチモーダルAI」と呼ぶ。助田さんたちの研究では、このマルチモーダルAIのうち、医療かつ日本語に特化した大規模モデルの構築を目指している。
具体的には、循環器内科に焦点を当て、医療レポートなどの日本語テキストデータ、オープンデータとして入手可能な心電図データ、レントゲン画像データを用いて統合的に学習し、医療診断や治療支援、病態解析、患者ケアなどで、問診や症例判断など多岐にわたる医療タスクに適用できる基盤モデルを開発する。
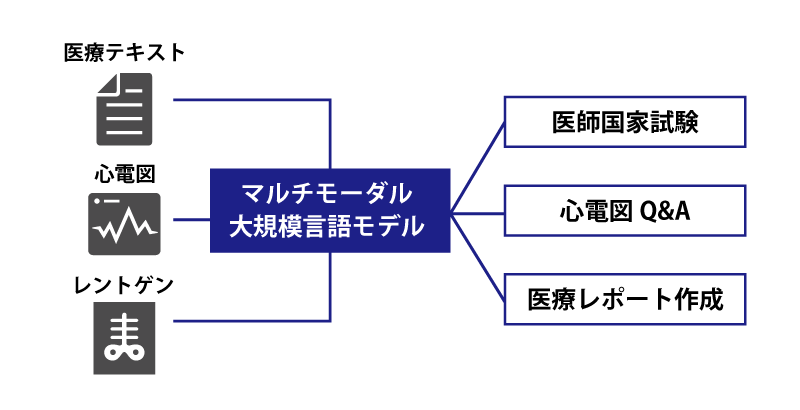
医療分野では、レントゲンや胃カメラなどの画像データから異常所見を見つけるタスクなどでAIを活用する動きが数年前からあるものの、広く普及しているとは言いがたい。また、多岐にわたる医療行為において既存のAIが活用できる範囲は狭く、限られた業務効率化での利用にとどまっている状況だ。画像データとテキストデータを組み合わせたマルチモーダル化が実現すれば、医師の負担軽減や、病気の早期発見、治療の精度向上が期待される。そもそも医療の現場では複数の情報を統合して病状を判断するため、マルチモーダル化は医療AIにおいて必然的な流れだと言えるだろう。
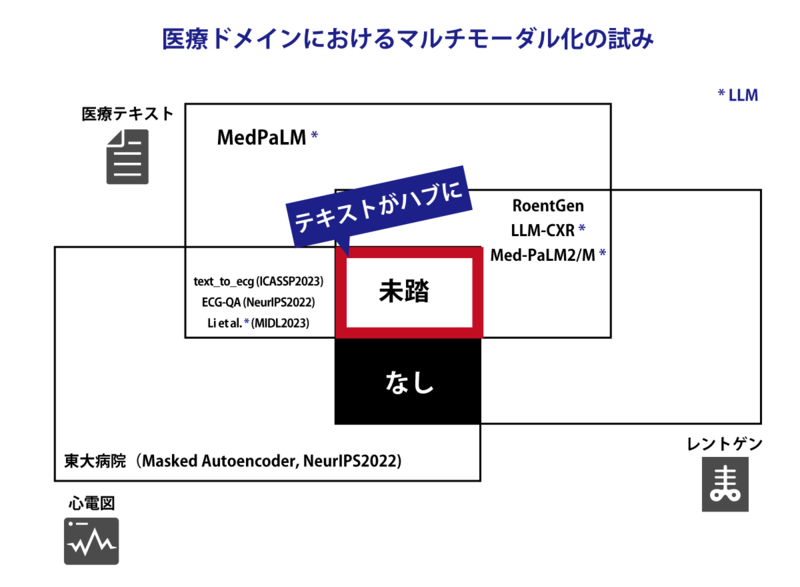
ただ、世界的にも医療AIにおけるマルチモーダル化の取り組みは始まったばかりで、必要な学習データの条件や効果はまだ十分明らかになっていない。助田さんらの研究ではそうした未解明の部分に着目し、異なる医療データを効率的に学習するための新たな手法についても検討。将来はさまざまなAIサービスの開発に使える基盤モデルの先駆けとなる存在を目指す、意欲的な研究となっている。
医師と数理工学の学生がタッグを組んで医療AIに取り組む
今回の研究で一つのポイントになっているのが、タッグを組んでいる二人の立ち位置の違いだ。助田さんによると、多くの医師も医療AIに関心を持っており、本業と並行して一からプログラミングを勉強し、休む暇を削ってAIの開発に取り組んでいる状況があるという。研究メンバーの澤野さんもまた、そうした医師の一人であり、医療AIの研究で医学博士の学位を取得し、東大病院/東京大学医学部附属病院を経て、現在は医療現場の負担軽減を目指してJDSCで勤務している循環器内科専門医である。
一方の助田さんは数理工学を専門としており、東京大学松尾研究室認定の学生AIベンチャー「EQUES」の創業者兼CTOでもある。あの松尾研関係者ということは、以前からAI研究に強い関心があったのだろうか。
「もともと数学が少し好きで、高校生の時に数理工学を学ぼうと思った時はまだAIに興味はありませんでした。AIに興味を持ち始めたのは実は大学に入ってからです。もっというと、それまではプログラミングに触れたことすらありませんでした。大学でも理論研究に惹かれたのですが、学ぶにつれて数理工学はAI技術等を通して社会に役立てられるのが醍醐味だと感じるようになりました」
助田さんは学部生時代の2年ほど前から、東京大学医学部循環器内科のAIグループの研究開発に参加している。澤野さんとの出会いもこのグループだった。グループには医療のバックグラウンドがない助田さんら情報系の学生も複数人参加しており、互いにアイデアを出し合いながら研究を進めてきた。
「工学的なアプローチで医療に貢献できるAI開発に魅力を感じました。いろいろなアイデアがありましたが、ちょうど2022年末にChatGPTがリリースされたタイミングで、LLM(Large Language Model:大規模言語モデル)がブームになったことから、それまでの画像系を中心とした方向から転換しました。日本でもいち早く医療LLMを開発する必要があると考え、事前学習済みのLLMをファインチューニングして、医療分野に適応させる研究に取り組んだのです」
この研究では、日本語LLMとして当時最大規模だったサイバーエージェントの「OpenCALM」と、英語LLMとして当時最高性能だったメタの「Llama2」をベースに、日本語の医療用LLMを開発。研究成果は論文にまとめ、学会でも発表した。ただ、開発したモデルの性能を医師国家試験の5択問題などで評価したところ、残念ながらChatGPTに性能が及ばなかったという。
そこで助田さんらは、LLM本体の性能向上ではなく、病院や医学系学会で収集される多様な医療データを包括的に統合する、マルチモーダルモデルの開発に舵を切る。
覚醒プロジェクトに採択された今回の研究では、OpenAIが開発しているChatGPTのモデルの基にもなっているTransformerベースの単一モデルに、プライバシー情報を含まない医療データを可能な限り学習させる。心電図、レントゲン画像、テキストデータともにオープンデータセットを利用する予定だ。
難しい挑戦、まずは最後まで走りきる
今回の研究で開発されるマルチモーダルは将来的に、患者と対話する問診AIや医師のカルテ記入を自動化し、医療現場全体の業務効率化と支援に役立つ可能性がある。だが、助田さんらは目指すのは、こうしたAIアプリケーションそのものではなく、あくまでも基盤モデルだ。医療機関や研究機関が保有する医療データでモデルをチューニングし、独自のアプリケーションを実装することを想定している。健康診断や人間ドッグなど、幅広いデータをモデルが扱えるようになれば、この分野を大きく成長させる可能性も高まるはずだ。
「今回作ろうとしているモデルは、全体から見ればあくまでも構成要素の一つでしかありません。それでも学生が取り組むには壮大で、覚醒プロジェクトで提供されるABCI(AI橋渡しクラウド)のような計算資源がなければ、とても不可能なことに挑もうとしています。かなり実験的な研究であり、成功例がまだない中で、難しい挑戦だと感じています。プロジェクトマネージャー(PM)の瀬々先生からも『まずは走り切ることが大事』だと言われていますが、とにかく今は手を動かして、失敗してもその成果を発表することが社会の役に立つような、取り組むこと自体に価値がある研究だと捉えています」
欧米に目を向ければ、医療分野のAI研究は医師だけではなく情報系の研究者も専門に取り組んでおり、2022年末にはGoogleが医療に特化した大規模言語モデル「Med-PaLM」の論文を発表するなど、取り組みが活発化している。
「日本では医療AIの研究はまだまだ足りてないと思います。取り組みが足りないので、新しいインパクトは生まれてきませんし、そもそも現段階でどこまでできていて、どれくらいできないのか、といった情報も不足しています。今回の私たちの取り組みが、国内での着火剤の1つになればうれしいです」
最後に、今後の課題や研究のあり方について、助田さんは次のように語ってくれた。
「本当はもっと僕たちのような情報系の研究者が、医療分野にもしっかり入っていって、一緒に戦わなければいけない。ただ、残念ながら医療AI研究に取り組むインセンティブが、特に学生視点だと見えにくいこともあり、なかなか参加者が増えない現状があります。医学の知識が乏しくてもデータの扱いに長けることで、お医者さん方と手を組めば、医療AIに貢献できる成果が出せることもあるはずです。
覚醒プロジェクトに採択されたみなさんは志が高く、コミュニティとして交流も盛んに行なわれると聞いています。今後は、そうした人たちともつながりながら新しいチャレンジをするなど、将来につなげていきたいと考えています」
■覚醒プロジェクト 公式Webサイト http://kakusei.aist.go.jp/

この記事に関連するニュース
-
松尾研究所、「IoT × GenAI Lab」の研究成果に関する論文が「BuildSys 2024」にて採択
PR TIMES / 2024年11月15日 12時15分
-
自治医科大学とDeepEyeVision、LMM(大規模マルチモーダルモデル)による眼底読影所見の自動生成機能を構築
PR TIMES / 2024年11月12日 16時15分
-
押さえておきたいLLM用語の基礎解説 第3回 学習率・事前学習・クリーニング・ファインチューニング・インストラクションチューニング・プレファレンスチューニング
マイナビニュース / 2024年10月29日 9時0分
-
RUTILEAのGPUクラウドサービスをGENIAC採択事業テーマの実施予定先の事業者に活用いただきます
PR TIMES / 2024年10月25日 16時45分
-
Qualcomm、モバイル向け新フラッグシップ「Snapdragon 8 Elite」発表、Oryon CPU搭載
マイナビニュース / 2024年10月22日 9時17分
ランキング
-
1歴史的名作『Half-Life 2』20周年!期間限定無料配布、拡張パック同梱するアプデ、資金不足やハッキング被害にも触れるドキュメンタリー映像などでお祝い
Game*Spark / 2024年11月16日 13時52分
-
2Amazonブラックフライデーで出品されたら即ポチ必至「PC&スマホ・タブレット」5選【ネット通販傑作遊びモノ】
&GP / 2024年11月16日 20時0分
-
3あれ、意外とイイかも? 電車派必見なiPhone「マップ」アプリの便利機能3選
&GP / 2024年11月16日 7時0分
-
4極薄な折りたたみスマホ「Galaxy Z Fold Special Edition」が登場 日本投入はある?
ITmedia Mobile / 2024年11月16日 10時5分
-
5不具合続いた『Wizardry Variants Daphne』実装予定機能を時期未定に―開発・運用体制の大幅増強を宣言
Game*Spark / 2024年11月16日 14時57分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





