

Lunar LakeではEコアの「Skymont」でもAI処理を実行するようになった インテル CPUロードマップ
ASCII.jp / 2024年7月8日 12時0分

前回はLunar LakeのPコアであるLion Coveを解説したので、今週はEコアのSkymontを解説しよう。

TremontとGracemontの違いはキャッシュ容量だけ Skymontの前身であるCrestmontではそれなりに強化された
Pコア同様、Eコアの方もAlder LakeからRaptor Lakeまではあまり変わっていない。もっと正確に言えば、Alder LakeのGracemontの元になったのはLakefield/Elkhart Lakeで採用されたTremontコアである。これがAlder Lake/Raptor LakeではGracemontになったが、違いは1次命令キャッシュが32KB→64KBに増量されただけである。
このGracemontはSierra Forestでも採用されたが、2次キャッシュの容量が4MB決め打ちになった以外に外から見える違いはない。Meteor Lakeで採用されたCrestmontは、Tremontからそれなりに強化された。
Core Ultra特集の第3回で下のスライドが示されているが、こちらではIPC向上以外に分岐予測の強化とVNNIを始めとするAI関連命令、それとThread Directorの対応強化などが挙げられている。

IPC向上であるがインテルのIntel 64 and IA-32 Architectures Optimization Reference Manual Volume 1の最新版(Version 50)からTremontとCrestmontのブロック図を抜き出してまとめたのが下の画像である。

フロントエンド、つまりPrefetch~Allocation/Renameまではほとんど差がない(1次命令キャッシュと、新たに追加されたOD-ILD(On-Demand Instruction Length Decoder)が目立つ程度でしかない。
ところが発行ポートの方はだいぶ増えており、ALUが7→12、FPU/Vectorが3→5に増えている。これにともない実行ユニットもALUが同時4つ、AGUも4つ、さらにJMP/STDも2つづつになっているし、FPU/Vectorの方もLoad/Store以外に3命令の同時実行が可能になるなど、かなり強化されているのがわかる。
Skymontはフロントエンドを大幅に強化
Crestmontの構造を念頭に置いたうえでSkymontの説明であるが、設計目標が下の画像だ。

Vectorの性能を倍にする、というのはAI PC向けとしてNPUなりGPUなりを使わないアプリケーションがまだそれなりに存在しており、こうしたアプリケーションでAI処理を高速化するためのものだが、これまでであればこうした処理はPコアの仕事であって、EコアはAI「以外」を処理するという流れだったはずだ。
ところがLunar Lakeの場合は、そもそものコア数が少ないからAI処理を行なう際にはPコアとコア、両方をフルに使うという方向性に変わったらしい。
そのSkymontのフロントエンド。まずPrediction/Fetch Unitであるが、128Bytesを対象とするPredictionはCrestmontと変わらない。ただしParallel fetchが最大96 Instruction Bytesに強化された。

なぜフェッチのサイズが1.5倍になったか? と言えば、デコードが3命令×3に強化されたからだ。

もともとTremontの時からこの構造は実装されていた。ただしTremontは3命令のデコーダーが2という構造で、ハイパースレッディング有効時はこのそれぞれのスレッドに3命令のデコーダーが割り当てられ、ハイパースレッディング無効時は6命令のデコーダーとして動作する、という構造だった。
この仕組みをこの図に当てはめると、ハイパースレッディング有効時は3スレッドを同時に扱えるようになる。ハイパースレッディングを無効化したLion Coveとは逆に、Skymontではさらにハイパースレッディングの性能を強化したわけだ。
なせこのようなことになったのか? は、Lunar Lakeだけを見ていてもわからないし、おそらくこの後出てくるArrow LakeもEコアはハイパースレッディングを無効化していると思われるので無関係であろうが、間もなく出荷されるSierra Forestの後継となるClearwater ForestではこのSkymontコアをハイパースレッディングを有効化して搭載されると筆者は推定している。
Sierra Forestの話はいずれするが、Sierra Forestの2ダイ構成の物は288コアで576スレッドを同時に実行可能だった。これをコア数を変えずにSkymontに入れ替えた場合、864スレッドの同時実行が可能になる計算だ。おそらく今回のSkymontの大幅なフロントエンド強化は、Clearwater Forest以降のEコアベースXeonに向けた施策と思われる。

ちなみに上の画像に戻ると、各デコーダーは最大32のμOp Queueを持つ関係で合計の容量は64μOpから96μOpに増えた格好だが、それよりも特筆すべきはNanocodeである。
通常のデコードでは処理できない複雑な命令についてはMicrocodeを利用して処理するわけだが、Microcodeそのものは同時に1命令しか処理できなかった。
Skymontではこれを改良、クラスター(要するに3命令デコードとその前後のQueueを合わせた塊)単位で処理が並行してできるようになった。ハイパースレッディング有効時には、各スレッドごとに同時に1命令のMicrocodeを利用したデコードが可能で、無効時にはトータルで3命令のMicrocodeを利用したデコードが可能になるという計算だ。
フロントエンドに合わせてバックエンドも強化 FPU/VectorもLoad/Storeユニットも性能が向上
さて、フロントエンドをこれだけ強化した以上、バックエンドも相応に強化する必要がある。Allocationは6-wideから8-wideに、Retirementも8→16に強化された。

Dependency breakingというのは、後述するように発行ポートを大幅に増やしたことで、発行ポートの取り合いが大幅に減ることが期待できることを指しているものと思われる。そして発行ポートを増やすというのは扱うべき命令の数も増えるということで、それに合わせてバッファ類も大幅に増量された。

そして実行ユニットだが、まずALU系は、なんとInteger ALUが6→8、分岐も2→3と大幅に強化。AGU(アドレス生成ユニット)もLoad×3、Store×4になっており、Load/Storeがそれぞれ2のCremont世代から倍増とは言わないものの大幅に強化されている。それはIPCも向上するはずである。

同様にFPU/Vectorも大幅に強化されている。Cremont世代ではAVX128命令が2命令/サイクル、あるいはAVX256命令が1命令/サイクルで実行できる構成になっていたが、Skymontはこれが倍増しており、AVX128で4命令/サイクル、AVX256でも2命令/サイクルが可能になった。
これはおそらくVNNI関連命令のスループット向上がメインと考えられる。またFPU周りでもレイテンシーの削減などが行なわれ、全体として結構なFPU/Vector性能の向上が実現したものと思われる。
処理性能が向上したら、それに合わせてLoad/Storeユニットも強化しないと、処理が終わっても結果がメモリーに書き戻せないことになる。
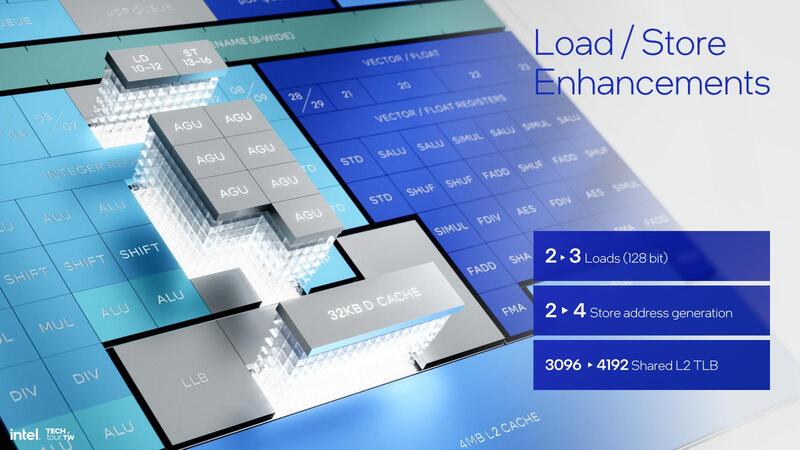
先程も触れたが、Load AGUが2→3、Store AGUが2→4に強化されている。このStore AGUの強化はFPU/Vectorのスループットが実質2倍になった以上、結果の書き戻しも2倍になるために必要な対策である。そしてこのStore AGUの倍増に合わせてか、2次のBandwidthも128Bytes/サイクルに倍増されており、かなり足回りも頑丈になった格好だ。

Eコアは省エリアサイズ/省電力向けのため 動作周波数をあげても性能はほとんど上がらない
これだけ内部が強化されているとなると、もうPコアは要らないのではないかと思うのだが、Pコアと異なりどうも物理実装が高動作周波数向けではなく省エリアサイズ/省電力向けになっているようで、Pコアのように動作周波数を高く引っ張ることで性能を上げる、という設計には向かないようだ。
インテルとしては、モバイル向けの場合には効率を最優先する実装をしているとしており、実際Meteor LakeのLP Eコア(つまりSoCタイルに入っているコア)と比較した場合、Integer(整数)で38%、Float(浮動小数点)で68%の性能改善が実現した、としている。


またプロファイルを見ても、シングルスレッドなら同じ性能なら消費電力がLP Eコアの3分の1、同じ消費電力なら1.7倍の性能が実現できるとし、またマルチスレッド環境ではコア数も多いこともあって、同じ消費電力なら2.9倍の性能、ピークで4倍の性能が実現できるとしている。


ただこの数字はアーキテクチャーの違いによるものだけではなく、プロセスの違い(TSMC N6→TSMC N3B)も含まれているので、アーキテクチャーだけでここまで性能差が出たというわけではないことに注意されたい。
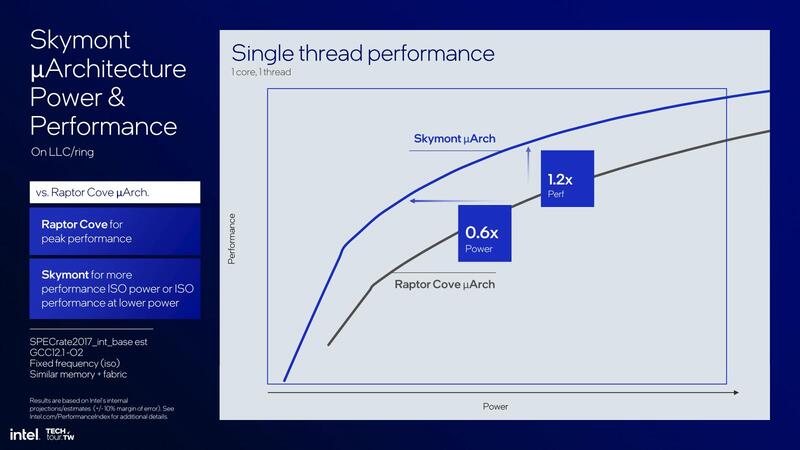
次いで、Desktop Compute Tileについての言及もあった。まずはシングルスレッド性能をRaptor LakeのPコアであるRaptor Coveと比較したものだが、平均してInteger/Floatで2%ほどの改善があるとしており、また性能/消費電力カーブもRaptor Lakeより優れている(ただし低消費電力の範囲)としている。



上の画像の中で、比較的低消費電力の範囲を拡大したのが下の画像であるが、同じ消費電力なら20%の性能改善が、同じ性能なら40%の消費電力削減が可能、としている。
おもしろいと思うのは、4つ上の画像には"Multi-threaded throughput scenario"と書いておきながら、そのマルチスレッド性能の比較が示されていないことで、おそらくArrow Lakeではハイパースレッディングを有効化しない予定であることと無縁ではないように思う。
ハイパースレッディングを有効にしたときにどの程度性能が上がるかはClearwater Forestが出てくるまではお預けになりそうだ。
※お詫びと訂正:用語の誤字がありました。お詫びして訂正します。(2024年7月9日)

この記事に関連するニュース
-
Lunar LakeはMeteor Lake比でどこまで性能向上? 最新ドライバ適用「Core Ultra 7 258V」搭載ノートを試す(後編)
マイナビニュース / 2024年11月14日 15時0分
-
Lunar Lake搭載で約946g! 超軽量ビジネスPCとして格が上がった新型「MousePro G4」を試す
ITmedia PC USER / 2024年11月6日 15時0分
-
Intelの新型「Core Ultra 200Sプロセッサ」は何がすごい? 試して分かった設計方針の成果と限界
ITmedia PC USER / 2024年10月25日 6時0分
-
Core Ultra 9 285KとCore Ultra 5 245Kの実力検証! Arrow Lakeは本当に高速省電力? 対14900K&9950Xベンチマーク
マイナビニュース / 2024年10月25日 0時0分
-
Lunar Lakeは省電力でも高性能! 仕事もAIもゲームも大幅強化な「Core Ultra 7 258V」搭載ノートを試す(前編)
マイナビニュース / 2024年10月22日 16時47分
ランキング
-
1あれ、意外とイイかも? 電車派必見なiPhone「マップ」アプリの便利機能3選
&GP / 2024年11月16日 7時0分
-
2極薄な折りたたみスマホ「Galaxy Z Fold Special Edition」が登場 日本投入はある?
ITmedia Mobile / 2024年11月16日 10時5分
-
3Steamクライアント最新版、Windows 7/8では動作せず
ASCII.jp / 2024年11月11日 13時30分
-
4TikTokで「麻辣湯に幼虫が混入」投稿が拡散 若者に人気の飲食チェーンが謝罪 見解を発表 「防犯カメラの映像によると……」
ねとらぼ / 2024年11月15日 19時49分
-
5オーテクの完全ワイヤレスイヤフォンで充電ケースから発煙・焼損のおそれ 「直ちに使用や充電を中止して」 無償交換へ
ITmedia NEWS / 2024年11月16日 12時35分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





