

Lunar Lakeに搭載される正体不明のメモリーサイドキャッシュ インテル CPUロードマップ
ASCII.jp / 2024年7月15日 12時0分

前回まででLunar LakeのPコアとEコアの説明が終わったので、今回はその周辺の機能を。コンピュートタイルにはPコアとEコア以外に以下が搭載されている。
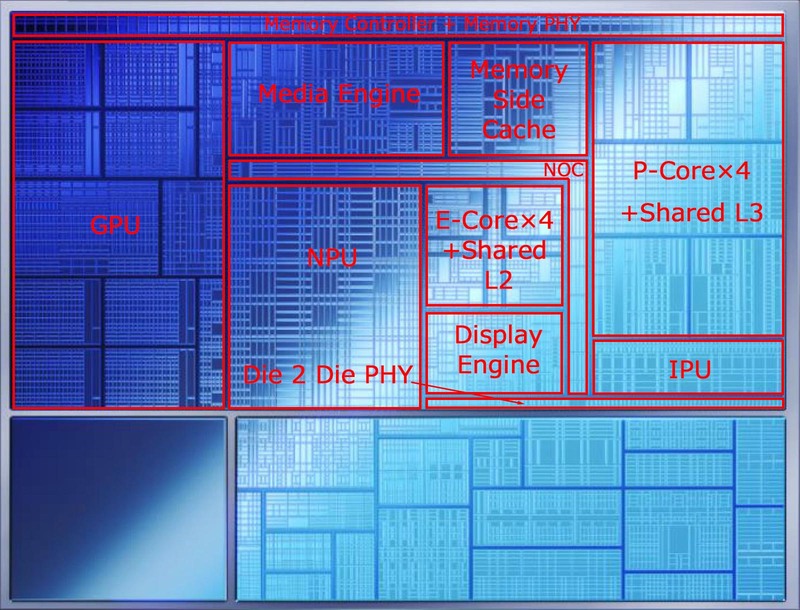
- メモリーコントローラーとメモリーサイドキャッシュ
- GPU
- NPU
- メディアエンジン/IPU/ディスプレーエンジン
- 全体を接続するNOC(と、チップレット間接続用のPHY)
このうちNOCはNetwork On Chipの略で、コンピュートタイル上に配される個々のユニット同士を接続する、いわば内部バスであるが、これの説明は不要だろう。
また一番最下段にあるDie 2 Die PHYは、プラットフォーム・コントローラー・タイルとの接続用である。Foverosを利用しているので、プラットフォーム・コントローラー・タイル側と長さをそろえる必要は必ずしもない(EMIBなら長さをそろえる必要があるのだが、Foverosなら面積が合っていれば配線はわりとどうにでもできる)が、なるべく最短距離にする方が好ましいわけで、こんな位置に置いたものと考えられる。
ここからは、その他のユニットの説明をしていこう。
Lunar LakeではMeteor Lakeの6割弱のメモリー帯域しかない
メモリーI/Fに関しては連載777回でも触れたが、Lunar LakeではLPDDR5X-8553のDRAMチップを2つ、パッケージ上に実装している。

問題はこのDRAMチップが32bit幅なことで、トータルでは64bit幅でしかない。Meteor Lakeは128bit幅でLPDDR5x-7467がサポートされるから、メモリー帯域は119.5GB/秒に達するのにLunar Lakeでは68.3GB/秒と6割弱の帯域しかない。これが特にCPUとGPUの性能を律速することになっているのは、構成上致し方ない。
それとメモリー容量も、64GbitのDRAM(=合計16GB)と128GbitのDRAM(=合計32GB)の2種類のSKUしかない。これ、Copilot+はともかくとして、AI PCを名乗るにはギリギリな状況である。16GBは容量的にAIを利用した処理がかなり厳しく、AI PCらしく使うには実質32GB SKUが必要だからだ。残念ながらLunar Lakeは外部にメモリーバスが出ていないので、後から増設という技が一切使えない。
このあたりに関して、「128bitバス版や4チップで64GB容量のSKUは出ないのか?」という質問がTech Daysで出ており、その際の返事は「今後はより大容量、より高速なチップが出てくる(かもしれない)」という頼りないものだった。
COMPUTEXで展示されたサンプルはSamsungのES品が搭載されていたのだが、そのSamsungのLPDDR5(X)製品一覧を見ると、最高容量が144Gbit品もの物がすでに量産開始しているし、速度の方も9600Mbpsの製品がサンプル出荷を開始している。
144Gbit品の方は、これを使っても合計容量が36GBになるだけであまりうれしくはないが、9600Mbpsの方はメモリー帯域が76.8GB/秒まで増えるから多少マシである。そのSamsungは今年4月に10.7Gbpsで容量256Gbitの製品の開発完了を発表している。
量産は今年後半ということで、もしこれを利用できれば帯域は85.3GB/秒、容量64GBとなってかなり不満が解消されそうには思うが、残念ながらこうした製品を搭載したLunar Lake改が出てくる公算はかなり低いと筆者は考える。理由は簡単で、今年後半(ほとんど年末に近いだろう)にはArrow Lakeが投入される予定だからだ。
Lunar Lakeがターゲットとする市場にもArrow Lakeが当然投入されると考えられるため、その時点でまだLunar Lakeをアップデートする公算は非常に低い。またLunar Lakeで利用されているLPDDR5xのパッケージは連載777回でも触れたが7×12.4mmの563ball MO-350Bというパッケージに準拠したものである。
これ、JEDECの標準規格には含まれているのだが、先のSamsungのLPDDR5x一覧を見ても存在しないことがわかる。561-ballの製品は3つリストアップされるが、こちらは561ball MO-352というパッケージで、寸法は8×12.4mmとLunar Lakeに搭載されているものよりやや大きい。
おそらくLunar Lakeに搭載されているLPDDR5xが標準品ではないのは、寸法がこの小さいサイズであることが理由と思われる。
逆に言えば、高速品あるいは大容量品を使おうとすると、現在のLunar Lakeのパッケージに収まらなくなるので、無理に搭載するとパッケージの互換性がなくなる。これはOEMメーカーには絶対受け入れられないだろう。x128を使わない(使えない)のは、このあたりにも理由の一端がありそうな気はする。
以上のことから、今後Lunar Lakeのメモリー構成が変わる可能性は非常に低いと見ている。もし可能性があるとすれば、なんらかの理由でArrow Lakeも遅れてU-SKUが予定通りに投入できず、Lunar Lake Refreshを投入せざるを得なくなったケースだろう。
その場合でも、メモリーバス幅を128bit化するのは無理なので(パッケージだけでなくメモリーコントローラーそのものの作り直しになる)、またSamsungあたりに561ball MO-352を利用した10.7Gbps 256Gbit品のメモリーを特注することになるかと思われる。あるいはSK Hynixの可能性もある。Micronは可能性が低そうだ。
正体がわからないメモリーサイドキャッシュ メモリーバスの利用率を下げるらしいのだが……
さてそのメモリー帯域の低さを補うためのもの、と思いそうだが正体がわからないのが、Pコアの左に位置するメモリーサイドキャッシュである。インテル自身が明確に説明を避けているのがこれまた謎なのだが、一つ使い方として説明されているのが、メディアエンジンと組み合わせて利用することで、メモリーバスの利用率を下げるというものだ。
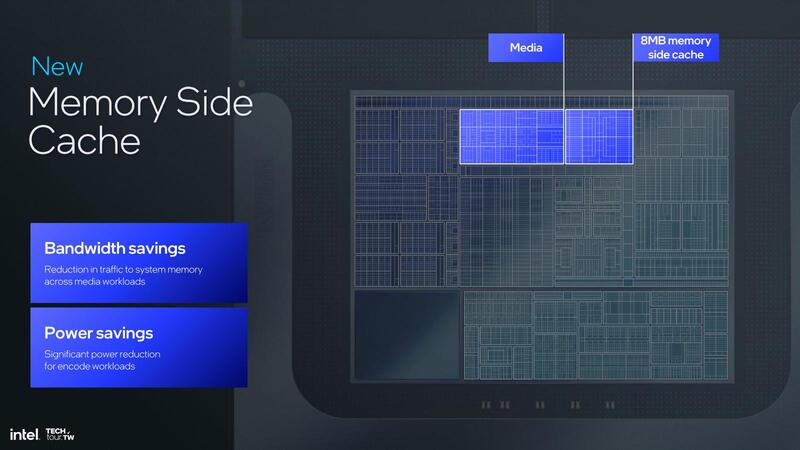
メディアエンコードの場合、現フレームと前フレーム、場合によってはもっと前のフレームの画像を比較して差分を取る、という作業が煩雑に行なわれるのでメモリーバスへの負荷は高い。が、手前にキャッシュがあればその中で処理が完結する。当然メモリーバスを利用するより消費電力は下げられるし、メモリーバスを利用する帯域も減らせることになる。ただ、これだけのためにメモリーサイドキャッシュを搭載するというのは考えにくい。
話を戻すと、COMPUTEXにおけるGelsinger CEOの基調講演で示されたスライドが下の画像であるが、これだけではなにを目的としてメモリーサイドキャッシュを搭載しているのかさっぱり理解できない。
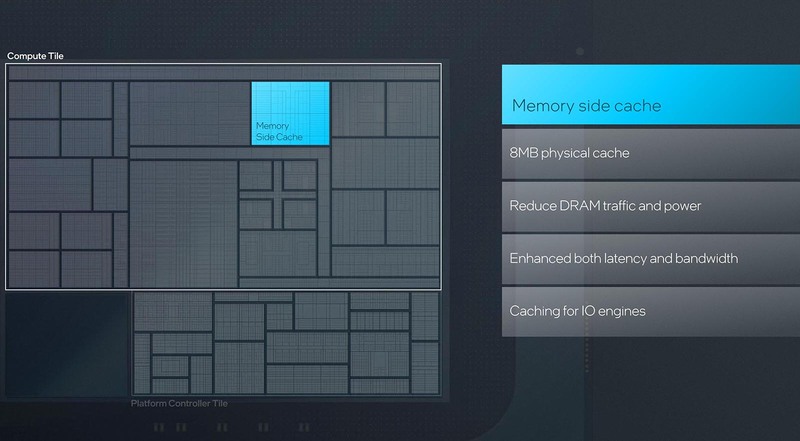
ところがこの後で下のスライドが出てきたことで、ある程度メモリーサイドキャッシュの目的がクリアになってきた。
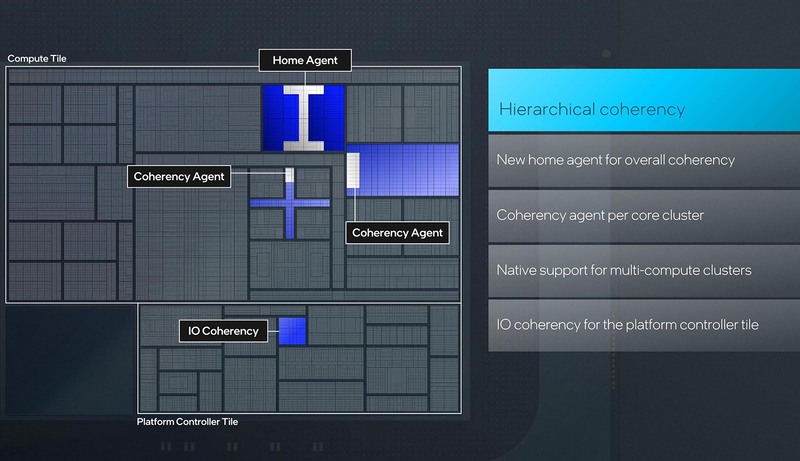
そもそもマルチコアCPUのシステムでは、キャッシュ・コヒーレンシーが重要になる。CPU #1とCPU #2がそれぞれ抱えているキャッシュの情報が異なっていた場合、データの不整合が起きるからだ。したがって、あるCPUがキャッシュの内容を書き換えたら、それを他のCPUに伝える必要がある。
正確に言えばあるメモリーの領域を(キャッシュ経由で)書き換える際には、他のCPUに対して「そのメモリー領域のキャッシュ情報を破棄すべし」と伝えるわけである。幸いにもPコア同士、あるいはEコア同士で言えば、そもそも共通の3次ないし2次キャッシュがあるので、ここでコヒーレンシーを担保しているが、問題はPコアとEコアの間のコヒーレンシーである。
当然これはPコアの3次キャッシュとEコアの2次キャッシュが、なにか書き換えを行なうたびにそれを相手に通知するという形でコヒーレンシーを確保していたが、これは効率が悪い。そこでであるが、おそらくメモリーサイドキャッシュは以下の2つの目的に利用されている。
(1) Snoop Cache:どちらかのコアがキャッシュを書き換えた際に、それをもう片方のコアに通知すると、それを受け取った側は自身がそのアドレスをキャッシュしているかどうか確認することになるが、それは無駄が多すぎる。これは特にコア数の大きなXeonでは大問題であり、そこでSnoop Filterというものが登場した。
最初に実装されたのはIntel 5000Xで、この時は実装に問題があってSnoop Filterを使うとむしろ遅くなったのだが、その後改良されており、Xeon Scalableは全製品Snoop FilterをCPU内部に搭載している。
メモリーサイドキャッシュの8MBのウチのある程度(キャッシュの内容そのものを保持するのではなく、タグ情報だけなので、トータルしても1MB程度で済むだろう)がSnoop Filter用に割り当てられていると考えられる。
これを利用することで、例えばあるPコアがあるアドレスに書き込みをしても、そのアドレスの内容をEコアがキャッシュ内に持っていなければ、別にその情報をEコアに送る必要がなくなる。これによりEコアが無駄にキャッシュをチェックする必要もなくなるし、NOCのトラフィックも減ることになる。
(2) Write Back Cache:例えばあるPコアがデータをあるアドレスのメモリーに書き込むと、それはPコアの3次キャッシュ経由でメモリーに書き出される。そして通知を受けたEコアは、自分のキャッシュからそのアドレスの内容を排除した上で、書き出した新しい内容を読み込むことになるが、これをいちいちメモリーから読み出すのは無駄が多い。
書き出す内容はいったんページサイドメモリーに補完し、Eコアはそこから読み出すようにすることで無駄なメモリー読み込みを省ける。
もう一つ考えられるのは、待機時の対応である。稼働時はともかく、待機時になると積極的にブロックごとパワーゲーティングで電力をカットして消費電力を下げる、というのはインテルのプロセッサーでは長らくの伝統である。
Lunar Lakeの場合Eコアの性能がかなり上がっているので、特にバッテリー動作の時などは煩雑にPコアが電力カットの対象になりそうである。
ここで問題になるのは、Pコアを丸ごとカットしてしまうと、復帰に時間がかかることだ。特に12MBもの3次キャッシュの内容を、そのたびごとにメモリーに格納したり、そこから復帰させるのは時間もかかれば消費電力も増えやすい。
そこで、復帰の際に必要になる分だけはメモリーサイドキャッシュに移動させておき、ここだけ電力を供給しておけば、Pコアが電源オフから復帰する際も素早くキャッシュの内容を復元できるし、メモリーバスを使わない分消費電力も下がる。
もちろん、これはPコアだけでなくEコアも対象だろう(例えばメディアエンジンを使って動画の再生中などは、Pコア/Eコア共に電源オフ状態になっていることが考えられる。ここでマウスとかが操作されたら、まずEコアを素早く復帰させる必要があり、この際にもメモリーサイドキャッシュから内容を復元できれば効果的と思われる。
Meteor LakeではLP Eコアがあったから、このLP Eコアだけ動かすことでこのあたりの問題を解決していたが、Lunar LakeではLP Eコアが省かれた関係で、こうした工夫で待機状態からの復帰を高速化するという効果が期待できると思われる。
最初に説明したメディアエンジンの話以外は筆者の推定ではあるのだが、それほど外れていないと考えている。

この記事に関連するニュース
-
AMD、CXL 3.1/PCIe Gen6/LPDDR5に対応するアダプティブSoC「Versal Premium Series Gen 2」を発表
マイナビニュース / 2024年11月13日 6時45分
-
Apple「M4」シリーズのメモリ仕様、どう変わったかを解説 LPDDR5X初採用の効果は
ITmedia NEWS / 2024年11月6日 16時12分
-
Lunar Lake搭載で約946g! 超軽量ビジネスPCとして格が上がった新型「MousePro G4」を試す
ITmedia PC USER / 2024年11月6日 15時0分
-
薄軽VAIOの旗艦モデル「VAIO SX14-R」の“数値以上の変化”を知る
マイナビニュース / 2024年11月1日 8時0分
-
Lunar Lakeは省電力でも高性能! 仕事もAIもゲームも大幅強化な「Core Ultra 7 258V」搭載ノートを試す(前編)
マイナビニュース / 2024年10月22日 16時47分
ランキング
-
1Arm版Windows 11のISOイメージ配布開始 インストールがより手軽に
ASCII.jp / 2024年11月15日 13時20分
-
2写りがエモいとZ世代に人気“オールドコンデジ”、中古カメラを買う際に覚えておきたいこと
マイナビニュース / 2024年11月15日 16時30分
-
3TikTokで「麻辣湯に幼虫が混入」投稿が拡散 若者に人気の飲食チェーンが謝罪 見解を発表 「防犯カメラの映像によると……」
ねとらぼ / 2024年11月15日 19時49分
-
4郵便局で「ゆうゆうポイント」始動 あえて「共通ポイントを狙わない」ワケ
ITmedia Mobile / 2024年11月15日 21時15分
-
5ドコモのポイ活プラン「ahamo/eximo ポイ活」は誰向け? お得になる条件を検証した
ITmedia Mobile / 2024年11月15日 13時1分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





