

「あはは」も再現? 味気ないAIとのおしゃべりを豊かにする音声対話技術
ASCII.jp / 2024年7月19日 10時0分

- 研究実施者:中田 亘、関 健太郎(東京大学大学院)
- 研究テーマ:音声対話システムにおける表現力豊かな音声合成のためのデータセット整備と大規模言語モデルの言語知識の活用
- 担当PM:谷中 瞳(東京大学大学院 情報理工学系研究科 准教授(卓越研究員))

無機質な音声を表現力のある声にどう近づけるか
スマホやスマート・スピーカーに話しかけると音声で応えてくれるSiriやAlexaといった音声アシスタントは、今や日常的に使われている。だが、その声はというと明らかに人工的で、どこか無機質でつまらないものだ。顔の見えない音声アシスタントであればそれでも問題はないかもしれないが、機械と人間との共生が進み、ロボットやAIアバターと対話する機会が増えていくにつれ、そうした不自然さが適切な意思疎通をする上での大きな障壁になる可能性もある。もし今より表現力のある音声対話システムを作ることができれば、もっと豊かなコミュニケーションができるようになるのではないか——東京大学大学院の中田 亘さん、関 健太郎さんが「覚醒プロジェクト」で取り組むのは、まさにそのための研究である。
「私たちの研究で目標にしているのは、人とロボットやAIとのコミュニケーションを円滑にする、音声対話の仕組みです。実現するための道筋としては大きく2つあり、1つは表現力のある大規模な日本語の音声対話データセットを整備すること、もう1つはLLM(大規模言語モデル:Large Language Model)の言語知識を融合した対話音声を生成することです。関はデータセットの構築、私はモデルの構築をそれぞれ担当しています」(中田さん)
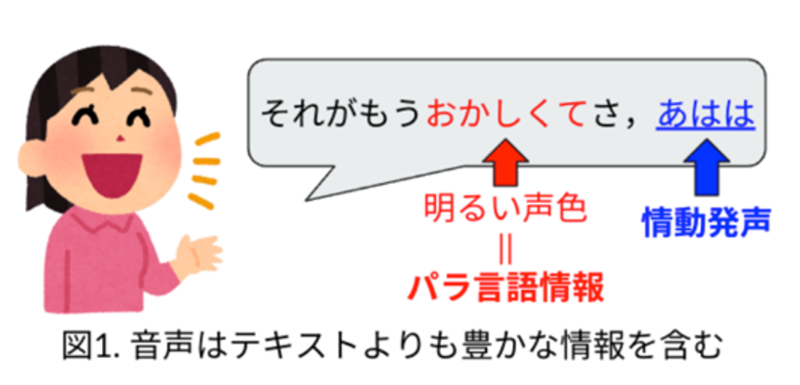
AIと人間がやり取りする一般的な音声対話システムは、音声をテキストに変換してAIに理解させ、それに対応する答えをテキストで生成して合成された音声で読み上げている。これらを実現する技術はすでに確立され、成熟しているものの、不自然さは残る。人間の音声をテキストに変換する際に、そこに含まれる感情が欠落してしまい、合成音声に反映されないためだ。そこで感情のある対話を実現するために中田さんたちが着目したのが、声の抑揚や印象に関わる「パラ言語情報」や、感情を表現する「情動発声」を付加することである。
テキストをただ読み上げるだけでなく、内容にあわせて明るさや大きさなどの声色を変えたり、笑い声や相槌を打つといったり、ちょっとした感情表現が追加できるだけでも、会話は自然で豊かなものになる。
バリエーションを増やして豊かな音声対話を実現
具体的な手法としては、まず、大規模な日本語対話音声データセットを整備する。このデータセットは、約7万時間規模になる予定だ。既存の日本語対話音声データセットとしては、台本を読み上げた音声を使って構築されたものが存在するが、時間にして約30時間分であり、パラ言語情報・情動発声のバリエーションは限られている。バリエーションを増やすため、中田さんらの研究では、台本読み上げではない対話音声をインターネット上で収集している。一般的な音声データセットのようなクリーンな音声だけでなく、ガヤガヤした場所で2人が会話しているような、ノイズを含むデータも使用するという。
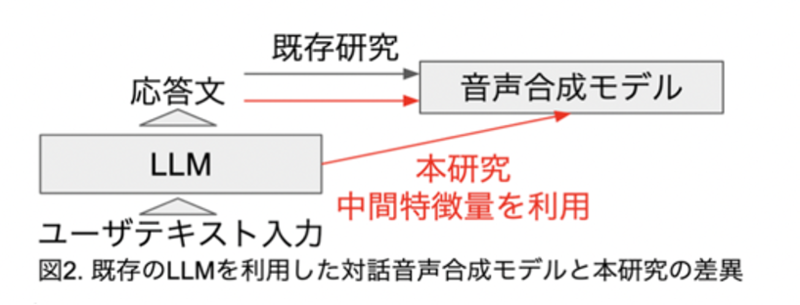
次に、このデータセットを用いて音声合成モデルを訓練する。ここでは、LLMの言語知識を活用するため、隠れ層出力とパラ言語情報・非言語情報の関係を学習させる。LLMの隠れ層(中間特徴量)を使うのは、対話音声のデータセット不足を補うためだ。先行研究では、ChatGPTを使って対話の台本を読み上げるためのパラ言語情報をテキスト化し、このテキストで音声合成モデルを条件付けるものがある。中田さんらは、LLM隠れ層出力は単語として離散化される前のニュアンスを適切に表していると考えられること、これらの情報はパラ言語情報・非言語情報の推測に有用であるとの仮説を立てた。これが、今回の研究のユニークな点となっている。
「そもそも日本語のパラ言語情報を扱った大規模なデータが、現時点ではあまり存在しない。あくまで私の考えですが、何かのタスクに特化したデータセットはもちろん重要ではあるものの、近年の研究動向を見ると、それよりも抽象的な人間の対話をデータセットにしてモデルを学習させることによって、結果的にパラ言語情報も扱えるようなモデルができるのではないかと考えています」
さらに、中田さんは会話をやりとりするタイミングも重要ではないかと考えている。
「例えば、LINE上のやりとりはターンが明確に決まっていますが、会話では自分が話している時に相手が相槌を打ったり、話すタイミングが重なったり、ターンがあまり明確ではない。対話ではそうしたやりとりもできるのが重要になのかもしれないと考えていて、そうしたところも含められたらおもしろいと思っています」
新しい視点がこれからの研究に必要
本研究でモデル構築を担当する中田さんは、高専を経て東京大学へ入学し、その後大学院へ進んだ。高専時代から音声分野の国際会議で受賞歴があり、学部3年次には注釈文を用いて音声合成による本の読み上げの演技力を向上させる手法を提案。トップカンファレンスで採択された経験がある。現在取り組んでいる研究テーマはどれも音声に関わるもので、それだけに音声分野の研究の難しさも強く実感している。
「最も難しいのが、何をもってして自然な声かを評価する方法です。指標としては生成した音声をたくさんの人に聞いてもらい、自然さや意味のある会話ができているかをアンケートする方法がよく用いられますが、聞く人によって考え方や感覚が全然違いますし、基準としては曖昧なところがあります。
以前に、何らかの評価基準につながるかもしれないと思って、人の話し声を部分的にAIで置き換えて模倣する研究をしたのですが、結果としてはうまく出来たものの、何が基準でうまくいったのかまでは分かりませんでした」
さらに、最近のAIブームの影響で、豊富な資金と人材を持つ企業や研究所が音声分野にも取り組むようになり、研究でも先行されることが増えてきた。研究を続けるためには常に新しい視野が不可欠だと感じているという。その点、覚醒プロジェクトのPM(プロジェクトマネージャー)の伴走支援が役立っているようだ。
「音声から見た言語を捉えている私たちに対し、自然言語処理が専門のPMの谷中 瞳先生からは言語学的な視点での指導を受けられる点が非常にありがたいですね。たとえば、言語学のデータセットや書き言葉への応用など具体的なアドバイスをいただいています。
もう一人、私が尊敬する先生は、これからは理系だけでなく文系の知識も使わないとよい研究はできないではないとおっしゃっていますが、その通りだと思っています。日本語は日本人しか研究する人がいないのでどうしても英語に比べて遅れますし、豊かなコミュニケーションの実現にはほかにも心理学的な要素なども必要になってくるでしょう。今のところはそこまでは手が出せていませんが、将来はそうした取り組みにも広げていきたいですね」
文脈を理解して楽しく雑談できるAIをつくりたい
中田さんたちの研究は、ロボットやAIとのコミュニケーションの改善にすぐに役立つように見える。「覚醒」終了後もこの研究を発展させ、社会実装を進めていくのだろうか。実は、中田さんの興味・関心はさらにその先にあるようだ。
「最近、人間はなぜ雑談をするのか? といったことをよく考えるようになりました。ChatGPTやSiriに人が話しかける場合、文章を要約したりとか翻訳をしたりとか、何かを教えてほしいとか、何らかの明確な目的がありますよね。でも、人が雑談をする時は目的がなくても、しゃべっているだけで楽しい。それはなぜなのか?それをどうやればコンピューターでも実現できるのか? もし実現できれば、将来的に接待するAIのようなものも出てくるのかな、と想像したりすることがあります。
人間は文脈によってどう話すかを普通に判断していますよね。そう考えると、私たちが研究したいのは音声の文脈のところなんですよね。どんなトーンでしゃべっていたとか、暗い感じがしたとかいったことから、どんなふうに読み上げるのが適切なのかを推定して、人とAIが人同士と同じような対話ができるようになればいいですし、誘い笑いとかそういうことができる、話していて楽しくなるようなAIができたらいいなと考えています」
■覚醒プロジェクト 公式Webサイト http://kakusei.aist.go.jp/

この記事に関連するニュース
-
【東芝デジタルソリューションズ】RECAIUS音声合成ミドルウェア「ToSpeak」のハイエンド機器向けラインアップを強化
Digital PR Platform / 2024年11月6日 11時27分
-
オルツの「LHTM-OPT2」、日本語RAG(検索拡張生成)で軽量型LLMとして世界最高の精度と推論速度を実現
PR TIMES / 2024年10月29日 14時45分
-
オルツの「LHTM-OPT2」、日本語RAG(検索拡張生成)で軽量型LLMとして世界最高の精度と推論速度を実現
共同通信PRワイヤー / 2024年10月29日 11時0分
-
押さえておきたいLLM用語の基礎解説 第3回 学習率・事前学習・クリーニング・ファインチューニング・インストラクションチューニング・プレファレンスチューニング
マイナビニュース / 2024年10月29日 9時0分
-
株式会社RATHが自分だけの“デジタル個人秘書”を育てるスマホアプリ『AIboW(相棒)』をリリース
@Press / 2024年10月22日 15時0分
ランキング
-
1写りがエモいとZ世代に人気“オールドコンデジ”、中古カメラを買う際に覚えておきたいこと
マイナビニュース / 2024年11月15日 16時30分
-
2Arm版Windows 11のISOイメージ配布開始 インストールがより手軽に
ASCII.jp / 2024年11月15日 13時20分
-
3「なんでこんなCM作ったのか・・・わかんないよ!」 日清とアニメ「異能バトルは日常系のなかで」が謎コラボ ネットは困惑交じりの好評
ITmedia NEWS / 2024年11月15日 14時26分
-
4ドコモのポイ活プラン「ahamo/eximo ポイ活」は誰向け? お得になる条件を検証した
ITmedia Mobile / 2024年11月15日 13時1分
-
5TikTokで「麻辣湯に幼虫が混入」投稿が拡散 若者に人気の飲食チェーンが謝罪 見解を発表 「防犯カメラの映像によると……」
ねとらぼ / 2024年11月15日 19時49分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





