

Lunar LakeのGPU動作周波数はおよそ1.65GHz インテル CPUロードマップ
ASCII.jp / 2024年7月22日 12時0分

前回に引き続き、Lunar Lakeのコンピュートタイルについて解説しよう。残るのはGPUとNPU、それと周辺回路周りである。
Xe-LPやXe-LPGで省かれていたAI関連の命令が復活
Meteor Lake世代は、GPUにXe-LPGが搭載されていたが、Arrow LakeではXe2に進化した。

そのXe2の進化ポイントが主に効率(Efficiency)の向上、というのは単にLunar Lakeの実装に当たっては効率の向上に係る部分の機能を実装したという話なのか、それともXe2世代全体の特徴が効率の向上のみ(性能向上はEU数の増加で担う形とし、その際のスケーラビリティの確保などは効率向上の中に含まれる)であるのかは、現時点では判断できない。
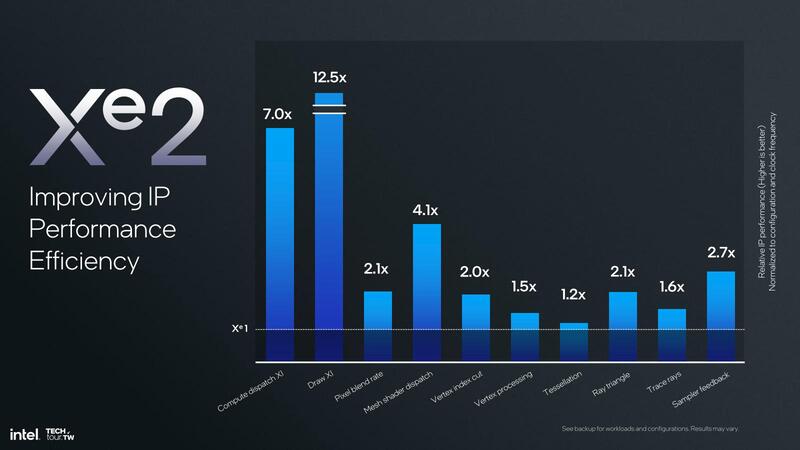
ただこの効率、コンポーネント単位では(コンポーネントによって差が大きいが)1.2~12.5倍改善しているとする。また、Xe世代では1つのレンダー・スライスあたりXeコアが4つで、あとはレンダー・スライスを何個搭載するかでシステム全体の構成が決まる格好だったが、Xレンダー・スライス2ではレンダー・スライスの数だけでなく、個々のレンダー・スライス内部のXeコアの数も可変になった。

そしてXeコアの内部も変更になった。

Meteor LakeのXeコアの内部構造とは、以下の違いがある。
- 256bit×16のVector Engineが512bit×8に変更された
- XMX Engineが復活した
- 新たに64bit Atomic Opsがサポートされた

このうちXMX EngineにHA、もともとXeコアにはXMXエンジンが搭載されており、ところがXe-LPやXe-LPGではそこまでAI関連命令が必要ないということで省かれていた経緯がある。
ではなぜXe2では復活したか? といえば、AI PCということで単にNPUを強化するだけでなく、現在のアプリケーションではGPUを使ってAI処理をするものも多く、こうしたものでも性能を発揮させるためにはXMXがあった方が有用だから、というあたりが理由と思われる。
後述するが、Lunar LakeのGPUはトータルで67TOPSの処理能力を持つとしており、これはNPUの処理能力である45TOPSを超える。この67TOPSの処理能力の大半はXMXによって実現しているので、AI PCを名乗る以上外すわけにはいかない。
Lunar LakeのGPU動作周波数はおよそ1.65GHz
Vector Engineの構造もだいぶ変わった。というよりもともとのXeが変だったのかもしれないが、従来は2つの256bit Vector Engineで1つのスレッドコントロールを共有する、つまり1つのスレッドコントロールが2つの256bit Vectorを管理する)という構造で、それぞれ別にレジスターファイルを持つ構造だったのが、今回1つにまとめられることになった。
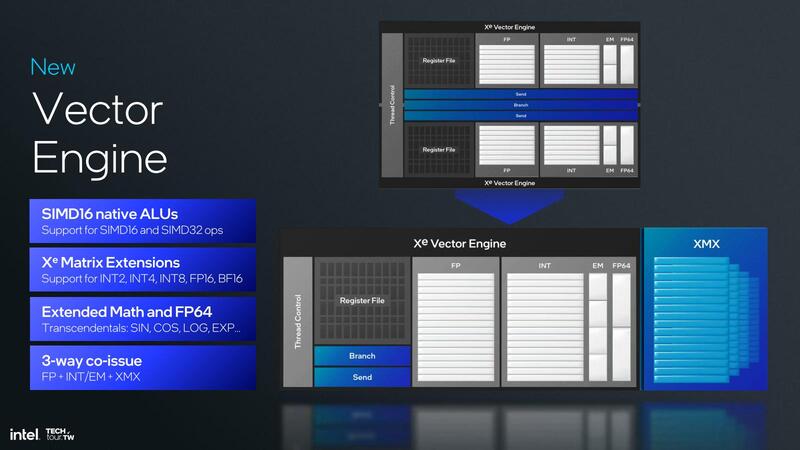
おそらくはこれによって、内部のスケジューリングが多少簡単になり、それが冒頭の画像に出てくる"Higher utilization"につながっていったと考えられる。
ちなみにMXMの構成は1サイクルあたり2万48Ops(FP16)ないし4096Ops(INT8)となっており、これは現在のIntel Arcで利用されているXe-HPGのものと同じ性能である。

ここからLunar LakeにおけるGPUコアの動作周波数が推定できる。上の画像にあるように、XMXはINT8なら4096 Ops/サイクルとなっている。これとは別にVector Unitの方ではDP4A命令が実行できる。
MXMはMeteor Lakeの時代にも搭載されていたもので、XeSSなどでも利用されているものだ。その処理性能をまとめたのが下の画像であるが1024 Ops/サイクルとなっており、合計で5120 Ops/サイクルとなる。
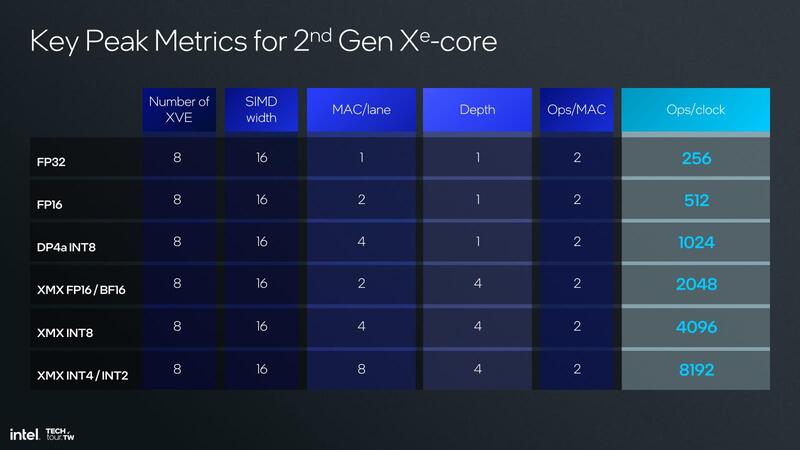
これはXe-Core1つあたりの処理性能なので、8 Xe-CoreのLunar Lakeでは4万960 Ops/サイクルとなる。この処理性能で67TOPSを実現しようとすると、動作周波数は1.6357...GHzとなる計算だ。
1.6GHzでは65.5TOPS、1.65GHzだと67.6TOPSほどになるので、現実問題としては1.65GHzで、これを丸めて67TOPSと称しているのではないかと推定できる。
この数字、Meteor Lake世代は1.75~2.35GHzとやや高めだったことを考えると低いという感じもするが、前回説明したようになにしろメモリー帯域がMeteor Lakeよりも低めである。
また前回説明はしなかったが、Memory Side CacheはGPUからアクセスできないことが質疑応答の際に明らかになっている。これはどういうことかというと、Memory Side CacheをGPUのワークエリアとして利用することは一切想定していないという話である。
8MB程度では、テクスチャーキャッシュ、あるいはレイトレーシング用のワークエリアとしては明らかに不十分であって、しかも前回の筆者の推定が正しければMemory Side Cacheはスヌープキャッシュやライトバックキャッシュとしても使われるため、GPUに割けるような領域はほとんどないだろう。
ということは、Lunar LakeはMeteor Lakeと比べても6割程度のメモリー帯域でGPUのやりくりをしないといけないわけで、無駄に動作周波数を上げてもメモリー帯域が間に合わないからGPUが空転することになりかねない。この1.65GHzというのは、メモリー帯域を使い切るギリギリの数字なのかもしれない。
ちなみにVector EngineやXMXだけでなく、レイトレーシング・ユニットの強化も行われている。ただこれに関しては、Meteor Lakeの時代からどの程度向上したのかが明確にされていない。

効率は間違いなく向上しているのだろうが、絶対性能という観点で見るとMeteor Lakeと比較して同等くらいが精いっぱいかと想像される。理由は、レイトレーシングもまたメモリーアクセスを多用するためだ。
Lunar Lakeの性能はMeteor Lake比で1.5倍 eDP 1.5のサポートも追加される
その他のレンダー・スライスの改良点として説明されている項目としては、以下のとおり。
- 全項目を見直して最適化を図った
- レイテンシーを極力減らすような最適化を図るとともに、ドライバーからGPUをアクセスする際の方法も改善した
- DirectX 12の目玉の1つである描画間接実行という技法を直接実行可能になった。これは12.5倍高速になったというDrawXIが該当するほか、4.1倍高速になったというMesh shader dispatchもこれに関係している
- 頂点計算をより迅速に行なえるようになった
- テクスチャーのサンプリングをより高速化した
- 陰面処理に関わる処理の高速化
- Pixel Backendの処理を高速化するとともに、2次キャッシュに対してのプリフェッチを実装した
- 2次キャッシュの圧縮メカニズムの実装と、シーンチェンジなどにともなうキャッシュクリアの高速化
最終的なLunar Lakeの構成が下の画像であり、先に示したように動作周波数は最大1.65GHzあたりと想定される。

絶対的な性能はまだ示されていないのだが、効率ということでMeteor Lake-UおよびMeteor Lake-Hと比較したのが下の画像だ。
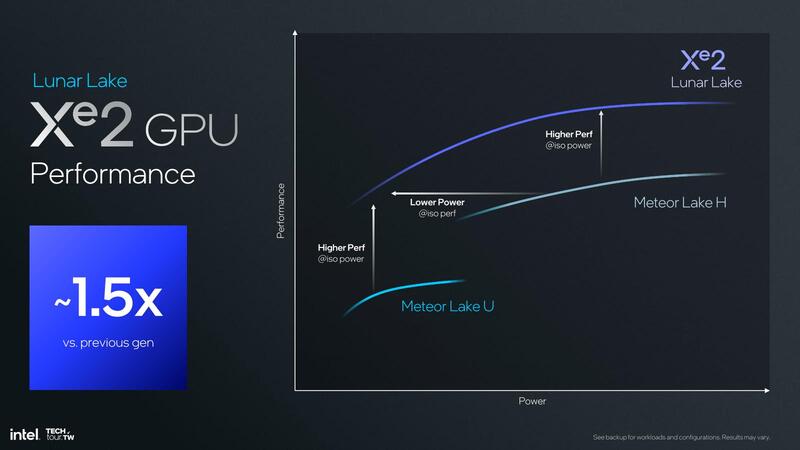
前世代と比較して1.5倍、というのはおそらく"Lower Power@iso perf"のものかと思われる。28Wや45Wが可能だとしても、その域ではメモリー帯域がボトルネックになってそれほど性能の伸びはなさそうである。またAI PCの競合がSnapdragon Xということは、Base Powerは15W枠の公算が高そうに思える。その枠内でMeteor Lake比1.5倍の性能を実現、という話であろう。
実際、COMPUTEXの会場ではF1 24を2Kで実行するデモが実行されていたが、これは実際にはXeSSをフルに使っての話だそうで、XeSSなしでは2Kは満足に動作できないようだ。効率はともかく、絶対性能に過大な期待は禁物だと思われる。
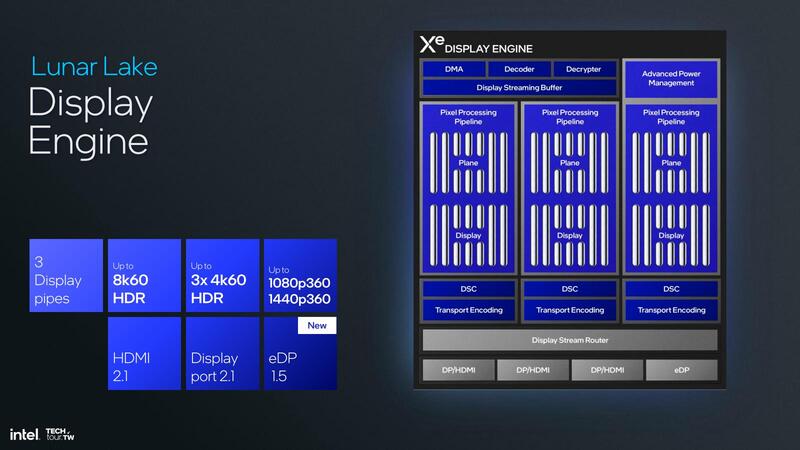
Display Engine周りでは、新たにeDP 1.5のサポートが追加された。eDP 1.5ではPSR(Panel Self Refresh:VRAMから画像を送らなくても、直前に送られた映像を液晶の側で保持し、それを表示する機能)を搭載している。
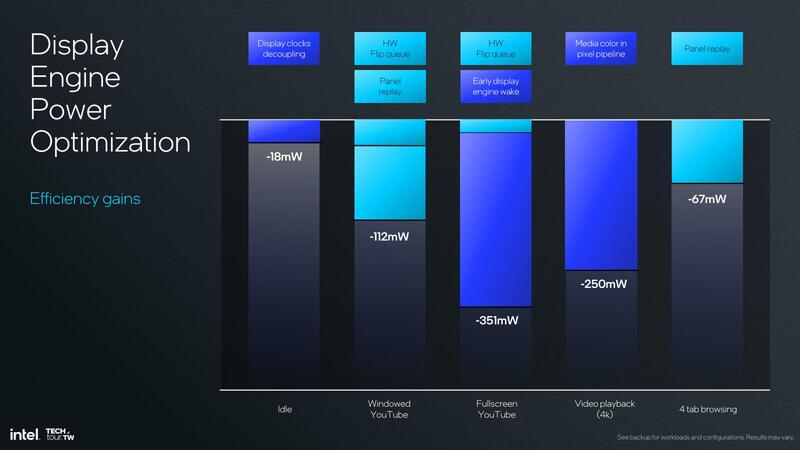
画面に変化がなければデータ転送を省ける分、消費電力の削減につながる。実際にいくつかのシーンでの節電の効果を示したのが下の画像である。
Media Engine周りでは、VVCのサポートが追加されたことが大きなポイントである。VVC(Versatile Video Coding)、あるいはH.266と呼ばれることもあるが、こちらはHEVCことH.265に比べても倍近い圧縮率を誇る一方、H.265と比べてもさらにエンコード/デコードが重いフォーマットである。

Lunar LakeではH.266のデコードをサポートするが、ただ問題はこれがどの程度利用されるか、というあたりだろうか?

この記事に関連するニュース
-
Lunar LakeはMeteor Lake比でどこまで性能向上? 最新ドライバ適用「Core Ultra 7 258V」搭載ノートを試す(後編)
マイナビニュース / 2024年11月14日 15時0分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
-
どの「M」が一番速い? Apple Mプロセッサーを今一度整理してみよう(後編)
マイナビニュース / 2024年10月28日 16時4分
-
Lunar Lakeは省電力でも高性能! 仕事もAIもゲームも大幅強化な「Core Ultra 7 258V」搭載ノートを試す(前編)
マイナビニュース / 2024年10月22日 16時47分
-
Arrow LakeのCore Ultra 9 258KとUltra 5 245Kがやってきた! さっそく開封の儀を行おう
マイナビニュース / 2024年10月18日 15時47分
ランキング
-
1写りがエモいとZ世代に人気“オールドコンデジ”、中古カメラを買う際に覚えておきたいこと
マイナビニュース / 2024年11月15日 16時30分
-
2「なんでこんなCM作ったのか・・・わかんないよ!」 日清とアニメ「異能バトルは日常系のなかで」が謎コラボ ネットは困惑交じりの好評
ITmedia NEWS / 2024年11月15日 14時26分
-
3Arm版Windows 11のISOイメージ配布開始 インストールがより手軽に
ASCII.jp / 2024年11月15日 13時20分
-
4元国民的美少女、 “直視できない状態”の顔面大やけどから1週間……現経過に医師も驚き「赤いところも薄くなっていくから」
ねとらぼ / 2024年11月15日 13時25分
-
5「Salesforce」で障害発生 金曜夕方直撃で、ユーザーからは悲鳴
ITmedia NEWS / 2024年11月15日 17時44分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





