

Lunar LakeはNPUの動作周波数がアップし性能は2倍、ピーク性能は4倍に インテル CPUロードマップ
ASCII.jp / 2024年7月29日 12時0分

前回はLunar Lakeに搭載されるGPUで話が終わってしまったので、今週はコンピュート・タイルで残るNPUの話となる。

Myriad XベースのVPUを改良したNPUを搭載
Lunar Lakeに搭載されるNPUは、Meteor Lakeに搭載されたMyriad Xベースのエンジンのさらに改良型となる。Meteor Lake世代のNPUの話は連載740回で紹介したが、基本はインテルが2016年に買収したMovidiusのMyriadシリーズVPUとなる。
このMyriadシリーズはインテル買収前から製品が出荷されており、インテルはこの第3世代に相当するMyriad XベースのVPUを改良したうえで、エンジン2つ搭載することで11.5TOPSの処理性能を実現している。要するにエンジン1つあたり5.75TOPSという計算だ。ちなみにこの11.5TOPSの数字の根拠がこちらである。


ではそのLunar Lakeに搭載されたNPU 4の構成は? というのが下の画像だ。エンジンの数が2→6で3倍に強化された格好となる。

NCE(Neural Compute Engine)はNPU 3の世代で導入されたものである。もともとのMyriad XはVPU、つまり映像を入力するとAIを利用して処理を行ない、その結果を返すような仕組みになっていたわけだが、NPU 3世代ではVPUを利用しなくてもISPが搭載されているので、ISPを使えばよい。
このため画像処理関連の機能は全部落とされ、その代わりに画像処理以外のネットワークも動作させられる、汎用的なAI処理が可能な仕組みに改められた。これがNCEになるのだが、現状でNCEは同時に1つのネットワークしか扱えない。
したがって、Meteor Lakeでは1つのNCEの下のMACユニットを倍増させるのではなく、1つのNCEはMyriad Xと同規模のMACユニットに留め、その代わりにNCEを2つ搭載するかたちになっている。
これにより、同時に2つのネットワークを並行して処理できるし、1つだけでよければ2つのNCEで処理を分担するようなことも可能になるわけだ。Lunar LakeのNPU 4ではNCEが6つになった、ということは要するに最大で6種類のネットワークが同時に実行可能だし、あるいは2つ/3つのネットワークを同時に実行することも可能である。
ただ現時点では、こうした複数のネットワークの実行時に、QoS的な処理が可能かどうかは明らかではない。例えばA/B/Cの3種類のネットワークがあったとして、A:B:C=2:2:2というように均等に割り振ることしかできないのか、それとも例えばA:B:C=4:1:1や3:2:1といった具合に、処理能力に重みを付ける形で分散させられるのかまでは現状定かではない。このあたりの割り振りはNPUというよりもCPU側処理の作業という気もするので、あるいは将来的には可能になるのかもしれないが。
NPUの動作周波数が向上 同じ消費電力なら性能は最大で2倍、ピーク性能は4倍に
次が動作周波数の向上である。今回Lunar LakeのNPU 4が実際にどの程度の動作周波数で稼働するかに関する明確な数字は示されていない。ただし性能/消費電力比に関しては示されており、同じ消費電力なら性能は最大で2倍であり、またピーク性能は4倍になるとしている。
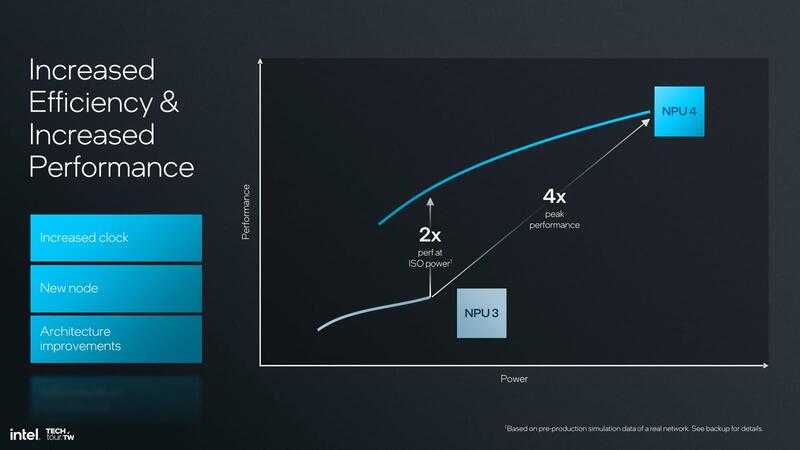
NPU 3の性能が相対的にそんなに高くないのは、そもそもNPU自身がSoCタイルという省電力ドメインで動作しているためで、TSMC N6プロセスだから動作周波数も上がりにくいし、面積的にもこれ以上NCEの数は増やしにくい。
Lunar LakeではこれがTSMC N3Bで製造されるコンピュート・タイルに移行したことで、ラフに言ってロジック密度は3倍(N7→N5で80%、N5→N3で72%のLogic Density向上とTSMCは説明しており、これをそのまま掛けると3.1倍くらいになる)に向上したことで、おそらくNPU 4はNPU 3からそれほど大きくは面積を増やさずに、2 NCE→6 NCEを実現している。
「大きくは増やさずに」というのは、NCEの中でもMACアレイなどはこの密度向上の効果が得られやすいが、スクラッチパッドや2次キャッシュはSRAMの塊であり、ここは密度向上が効きにくいためである。
さて問題は動作周波数の方である。上の画像を見ると、性性能は4倍ということになる。性能そのものは45.88TOPSほどになる計算で、この場合動作周波数は1.333...倍になるので、動作周波数は1.866...GHzになる。
これは切りが悪いので1.85GHzとすれば45.47TOPSほどでつじつまが合うし、TSMC N3Bならこの程度の周波数での動作は容易である。ただ問題は、画像のグラフと微妙に合っていないことだ。というのは、グラフ左下を原点とすると、NPU 4のピーク性能は3.67倍ほどになる計算だ。
「グラフが正確に描画されている」という前提であれば、原点は下の画像の位置になると思われ、この場合NPU 4がフルに稼働した場合の消費電力比は2.58倍ほどになる計算である。
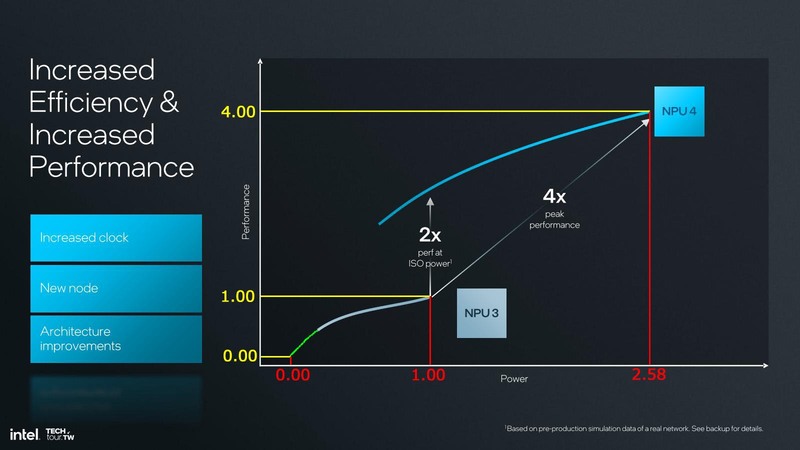
2.56倍の消費電力で4倍の性能なので、性能/消費電力比的には十分帳尻は合っているし、2 NPC換算で言えば1.3倍の動作周波数向上を15%の消費電力削減とともに実現している計算になるため、N6→N3Bの移行は正解だっただろう。
逆に言えば、コンピュート・コア側にNPUを移動させない限り、この性能と消費電力は実現できなかったという話で、単にエリアサイズ(3倍の規模のNCEを、ほぼMeteor Lakeと同等の面積に抑える)以外にもN3Bに移行すべき理由があった、ということである。
SHAVE DSPを大幅強化 ホストで処理していた作業をNCE側でカバーする
NPUの構造に話を戻すと、MACユニットの方はより効率を高めた、という説明はあるものの、どう効率を上げたのかの詳細は説明されていない。

活性化関数に関しては、NPU 3に比べて対応する関数を増やしたことが示されており、またデータ変換用の機能も搭載され、これまでだったらSHAVE DSPもしくはホストで処理していた作業をNCE側でカバーできるようになったとしている。
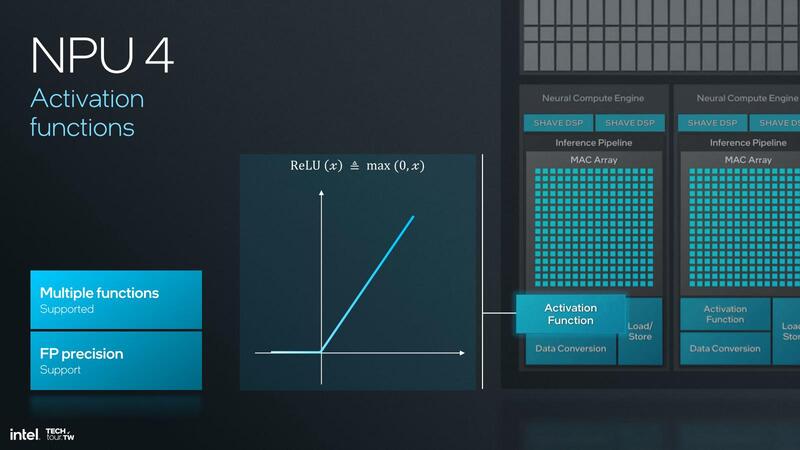
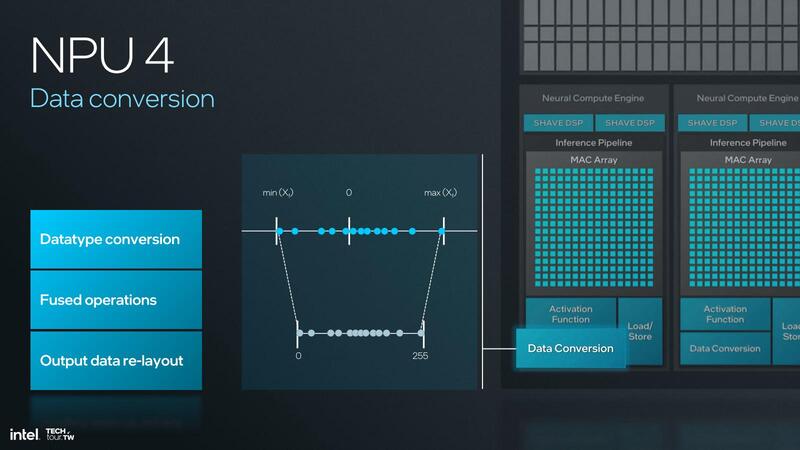
そのSHAVE DSPが、NPU 4では大幅に強化された。SHAVE DSPはもともと1つのNCEに2つ搭載されており、それぞれ128bit幅のSIMDエンジンを搭載。INT 8/16/32とFP16/32を扱えるようになっていた。
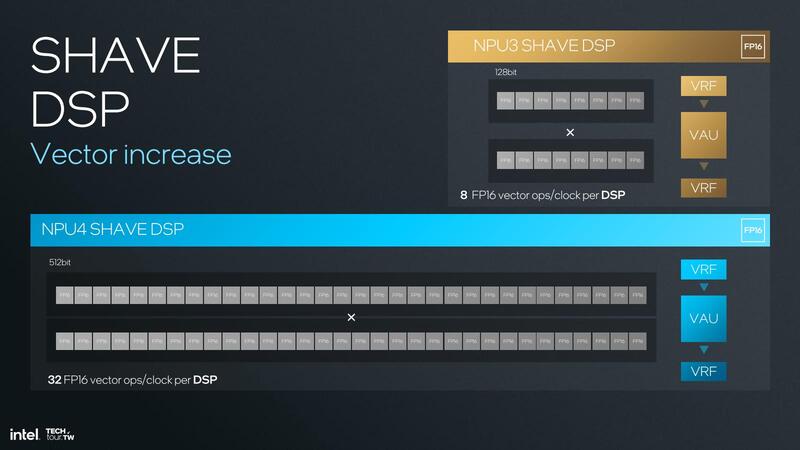
もちろんこれは通常のMAC演算も可能ではあるのだが、それは専用のMACアレイを使った方が効率が良い。なので、MACアレイでサポートしていないINT 16/32やFP32での処理、あるいは通常の乗加算以外の処理を行なう場合に利用されることになる。
さてそんなSHAVE DSPだが、NPU 4ではSIMDエンジンの幅が128bit→512bitと4倍に増強された。INT 8の場合で言えば64 Ops/サイクル(MAC演算の場合:通常の乗算なり加算なりだけなら32 Ops/サイクル)が可能であり、1個のNCEあたり128Ops/サイクルとなる。
先程の性能の試算ではMACアレイだけを使う計算になっていたが、SHAVE DSPの性能が大きく上がった関係で、実際にはこちらも加味して計算をしている可能性がある。NCE1つあたりの処理性能は4352Ops/サイクルとなり、これが6つでかつ1.7GHz動作だと性能は44.4TOPSほど。1.75GHzだと45.7TOPSになり、上の試算より100MHz動作周波数を落とすことが可能になっている。
このSHAVE DSPの性能を加味したものかどうかがハッキリしないので、動作周波数は一応推定1.85GHzとするが、実際は1.75GHzとか1.8GHzの可能性もある。
さて、その46TOPS程度のNPU 4の性能は? ということでインテルから示されたのはStable Diffusionを動かした場合の結果である。
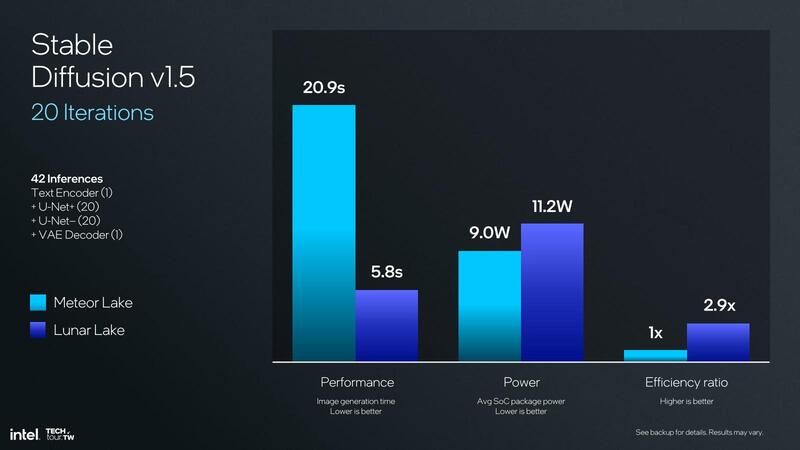
Meteor Lakeの時もStable Diffusionを実施した場合の性能が示されたが、この時は比較対象がなかったこともあり、CPUでやった場合とGPUでやった場合、NPUを組み合わせた場合の4パターンでの比較である。
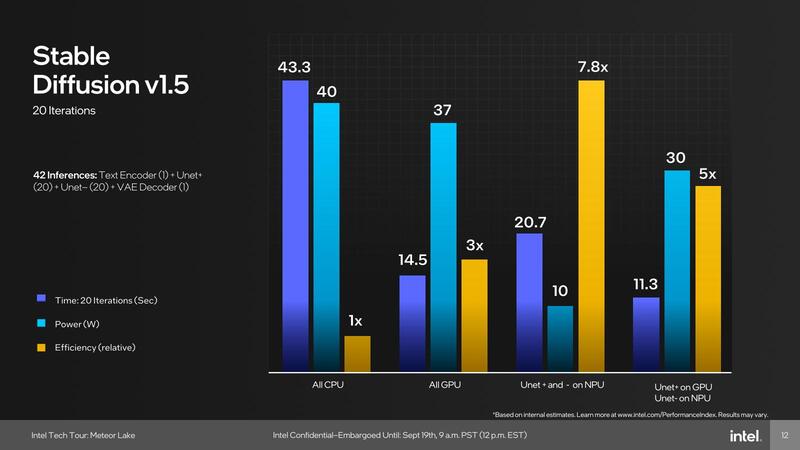
結果は連載740回の最後にも示したとおり、NPU 3を利用した場合の性能はGPUを利用した場合の7割程度に過ぎず、ただし消費電力が圧倒的に少ないというものだった。
一方今回はMeteor LakeとLunar Lakeとの比較になるので、直接前回との比較にはならないのだが、まず性能で言えば20回の繰り返しに要した時間が20.9秒→5.8秒で3.6倍の性能向上となっている。一方でシステム全体での消費電力は9W→11.2Wと若干ではあるが増えているのは当然ではある。
先に説明したように、NPU 4はNPU 3と比較してピークで4倍の性能になっているが、その一方でピーク時の消費電力は推定で2.58倍ほどになっている。実際はシステムの構成もメモリーの構成も異なるから無茶な計算ではあるのだが、この2.2Wの増分がNPU 3とNPU 4の消費電力の差だと仮定すると、NPU 3の消費電力は1.4W程度であり、NPU 4ではこれが3.6W程に増えたことになる。
この数字、厳密さには欠けるものではあるのだが、案外に外していないのではないかと思う。Meteor Lakeでは省電力のSoCタイルで実装され、省電力に注力した構成になっている。NPU 2、つまりMyriad Xの場合は当初TSMCの16nm、次いで12nmに移行しているが、これが大体3W程度であった。NPU 3ではプロセスの微細化と省電力プロセスの採用もあり、2W以下に押し込むことは可能だろう(Myriad X VPUに搭載されていたISPを省けたことも効果あると思われる)。
一方NPU 4の方は、1.8GHz前後の動作周波数ではあるが、これはTSMC N3Bプロセスとしてはかなり低い動作周波数レンジであり、消費電力もそれほど高くならない。3.6Wで収まるか? というともう少し行きそうな気はするが、5Wまでは行かないだろう。
ピーク性能はもちろんXe2コアには及ばないだろうが、この程度の消費電力でこの性能なのは十分評価できる。総じて、良いバランスのNPUと言って良いだろう。

この記事に関連するニュース
-
Lunar LakeはMeteor Lake比でどこまで性能向上? 最新ドライバ適用「Core Ultra 7 258V」搭載ノートを試す(後編)
マイナビニュース / 2024年11月14日 15時0分
-
Lunar Lake搭載で約946g! 超軽量ビジネスPCとして格が上がった新型「MousePro G4」を試す
ITmedia PC USER / 2024年11月6日 15時0分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
-
Lunar Lakeは省電力でも高性能! 仕事もAIもゲームも大幅強化な「Core Ultra 7 258V」搭載ノートを試す(前編)
マイナビニュース / 2024年10月22日 16時47分
-
Arrow LakeのCore Ultra 9 258KとUltra 5 245Kがやってきた! さっそく開封の儀を行おう
マイナビニュース / 2024年10月18日 15時47分
ランキング
-
1みずほと楽天の資本業務提携で何が変わる? 対面×デジタルの強みを掛け合わせ、モバイル連携は「できない」
ITmedia Mobile / 2024年11月14日 18時30分
-
2「これはひどい」 駐車場は“鳥のマーク”の階→元に戻ると…… “まさかの結末”に絶望 「なんてこった」
ねとらぼ / 2024年11月14日 19時30分
-
3これは合理的だわ!完全ワイヤレスと翻訳機が融合したぞ
&GP / 2020年10月23日 19時0分
-
4「セクシーギャル」ずーっとトレンド入り←『ドラクエ3』の話です! HD-2D版発売日
マグミクス / 2024年11月14日 22時22分
-
5これぞZ世代を体現したノートPC! NEC、エモいがテーマの「LAVIE SOL」
ASCII.jp / 2024年11月14日 20時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





