

切り捨てられた部門が再始動して作り上げたAmpereOne Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年9月16日 12時0分

Hot Chips第2弾は、Ampere ComputingのAmpereOneをご紹介したい。こちらのコアは前回のOryonほどいわくつきではないのだが、会社がいわくつきだったりするので、まずはAmpere Computingの話をしよう。
完成直前に会社買収され、切り捨てられたプロセッサー部門
Ampere Computingの話は、連載446回の最後でチラっと話をしている。もともとはネットワーク関係のさまざな製品を手掛けていたAMCC(Applied Micro Circuits Corporation:のちに略称をAPMに変更)が、2013年に突如発表したX-Geneに行き着く。
X-Geneの発売に先立ち、同社はTitanと呼ばれるPowerPCベースの独自コアを開発していたものの商用には至らず、そこから完全に軸足をArmに切り替えた上で、しかもスクラッチから開発した最初のサーバー/組み込み向けのCPUコアとして登場した。初代のX-Geneに続き、X-Gene 2もリリースされ、さらにX-Gene 3に加え、その先のX-Gene 4の話も出ていた。
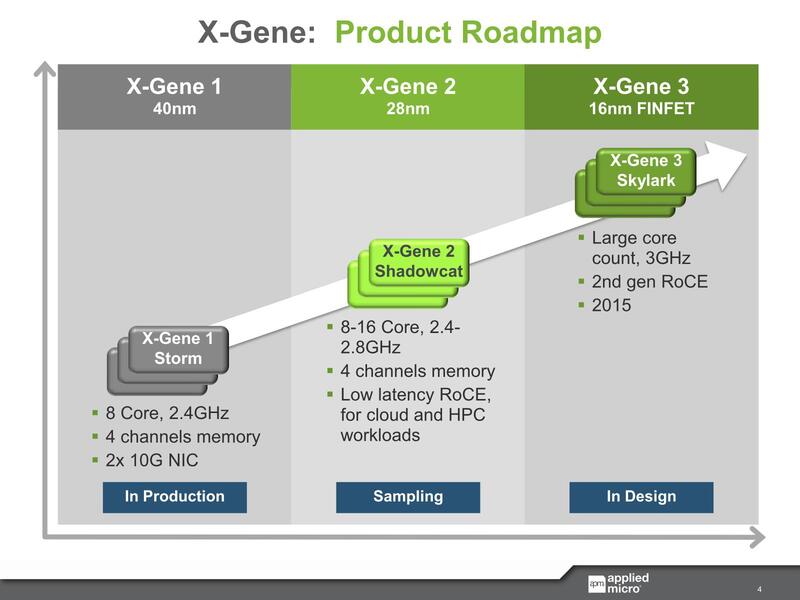
2016年には、そのX-Gene 3のSimulation結果をまとめたホワイトペーパーもリリースしており、2017年の出荷に向けて期待されていたのだが、その2017年1月に会社が丸ごとMACOMに買収され、同年10月にプロセッサーの部門はファンドに丸ごと売却された。
スピンアウトというよりも、MACOMにプロセッサー部門が不要なので捨てられたというのが正直なところか。そのファンドの親会社にいた、元Intel COOのRenee James氏が同部門の再生の指揮をとることになった。
X-Gene 3が完成直前に買収→売却となったことで、X-Gene 3そのものの開発はホールド状態にあった。というのは完成させるにも相応のコストが掛かるからで、ファンドはとりあえず会社が存続するのに必要な資金は供給してくれるにしても、プロセッサーの開発に必要なコストに関しては、それが間違いなく回収可能の見極めがつかない限り難しい。そのあたりの見極めをするとともに、今後の自立(≒新規上場株式)に向けての道筋を立てるのがJames氏の仕事だったわけだ。
インテルの元COOが指揮をとりプロセッサー部門が Ampere Computingとして立ち上がる
そのように、ファンドに所有される形で立ち上がったのがAmpere Computingであるが、2018年にはそのX-Gene 3ベースのコアを採用したeMAGプロセッサーを発表する。

なぜ発表のURLがamperecomputing.comではなくウェブアーカイブなのか? というと、Ampere Computing的にはすでにeMAGはなかったことになっているらしいからだ。eMAGはTSMCの16FF+で製造され、最大32コア、3.3GHz動作でTDP 125Wとされた。ただこのX-Gene 3の後に噂されていたX-Gene 4は一旦ご破算になったらしい。
その代わり、2020年に同社はAmpere Alterを発表する。こちらはArmのNeoverse N1コアを採用したクラウドサーバー向けの製品という位置づけで、最大80コアのNeoverse N1(専用2次キャッシュは1MB)に32MBの3次キャッシュを組み合わせた構成。3.3GHz動作でのTDPは250Wに抑えられ、8chのDDR4-3200と128レーンのPCIe 4.0を装備するほか、CCIXを利用して2プロセッサー構成を取ることも可能となっていた。
同年6月にはコア数を128に増やしたAlter MAXの発表もあり、2021年に発売開始されている。
Ampere Alter/Alter MAXは意外に(というのも失礼だが)好評だった。というのは、Neoverse N1を搭載したプロセッサーは数多く存在するが、その大半は大規模クラウド事業者が自社専用に利用しているパターン(一番有名なのがAWS Gravitonである)で、普通の開発者や中小のクラウド事業者には手が出なかったからだ。
こうした市場を、Ampere Alter/Alter MAXはうまく掴むことに成功する。実はこれに先立ち、Ampere Computingはさまざまな会社から投資を受けており、その中にはArmやNVIDIAの名前もあった。Neoverse N1コアをそのまま利用したのは、Armからの投資の見返りという側面もあったのかもしれない。もちろん後述する理由で、しばらく製品投入が遅れることになるので、その間を埋めるためにもNeoverseベースとするのは妥当な戦略だった。
NVIDIAに関しては、CUDAベースのHPCシステムのホストとしてAlter/Alter MAXを提供することに関しての協業という形で、見返りを提供している。今でこそNVIDIAは自前でHopper CPUを提供可能になったが、それまではx86ベースで提供するしかなく、これをArmに置き換えるための手段を欠いていた。Ampere Computingはこの手段を提供した格好だ。
2023年にクラウド向けのAmpere Oneファミリーを発表
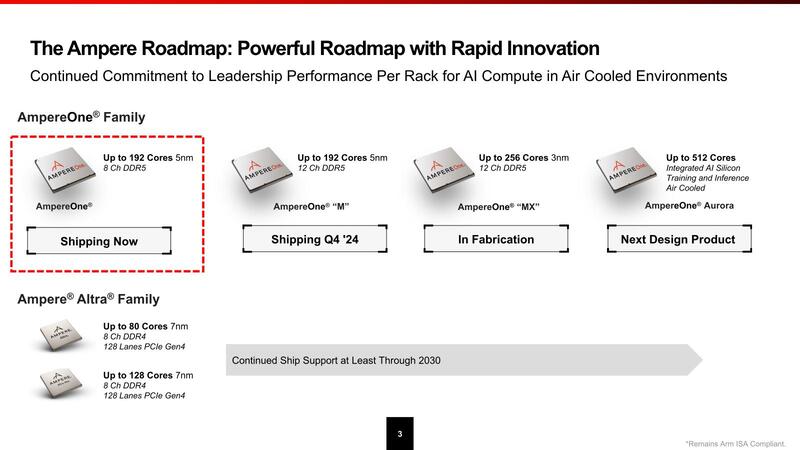
Ampere Alter/Alter MAXから3年あまり経過した2023年5月、Ampere ComputingはAmpere Oneファミリーを発表する。最大192コアの構成で、クラウドに最適化したカスタム構成と説明されていた。ただこの時点では、そういう製品が存在することだけがアナウンスされており、具体的な登場時期や詳細な構成などは一切明らかにされなかった。
2024年の5月にはアップデートが公開され、コア数は最大256まで増やされるとともに、QualcommのCloud AI 100 Ultraを組み合わせたAI推論向けのソリューションを提供することもアナウンスされたものの、詳細は引き続き明らかにされていない。
現実問題として2018年に一度X-Gene 4がご破算になり、そこから新規にCPUの設計をスタートすれば、5~6年かかるのはごく普通のことである。加えて言えば、Ampere Oneの最初のシリーズはTSMCの5nmを利用するが、ご存じの通りこのプロセスは大人気で、大口ユーザーはともかく会社規模としてはスタートアップ+αでしかない同社の優先度はどうしても下がるため、製造には時間を要するのも仕方がない。
それでもなんとか2024年8月には量産出荷を開始するとともに、今後のロードマップを開示した。
そんなAmpereOne、まずコアの内部構造が下の画像である。
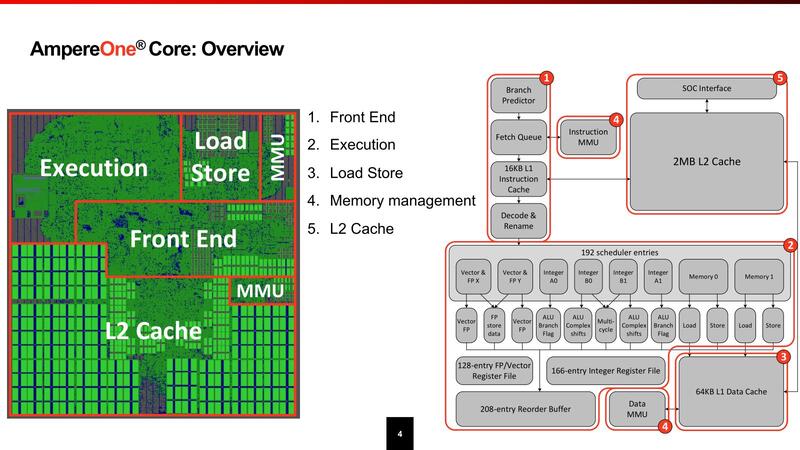
基本的なAmpereOneの設計方針だが、絶対性能よりも性能/電力比やコア数に比例した性能、それと汎用性といったものを重視するとしており、これはインテルで言えばEコアベースのSierra Forestやその後継のClearwater Forestの方向性に近い。

この思想はコアの内部構造にも反映されている。デコーダーは同時5命令で、これを4 MicroOpに変換してスケジューラーに送り込む格好だが、デコーダーそのものは最大で8命令/サイクルまで対応しているとする。
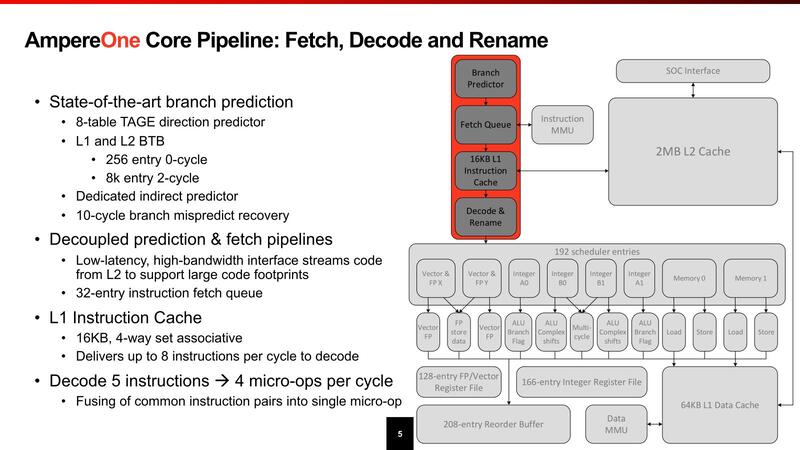
ここで性能を大幅に引き上げようと思ったらMicroOpキャッシュを設けるのが効果的だが、それをせずに32エントリーのフェッチキューのみで済ませているあたりは、AmpereOneのワークロードではMicroOpキャッシュが効くような処理はあまり多くないと考えているのかもしれない(API Server的な用途では、繰り返し処理の頻度が大幅に減るからMicroOpキャッシュが相対的に効きにくい)。
このあたりはピーク性能よりも性能消費電力比を重視して、あえてそこそこの性能に抑え、その分回路規模を小さくしたのかもしれない。
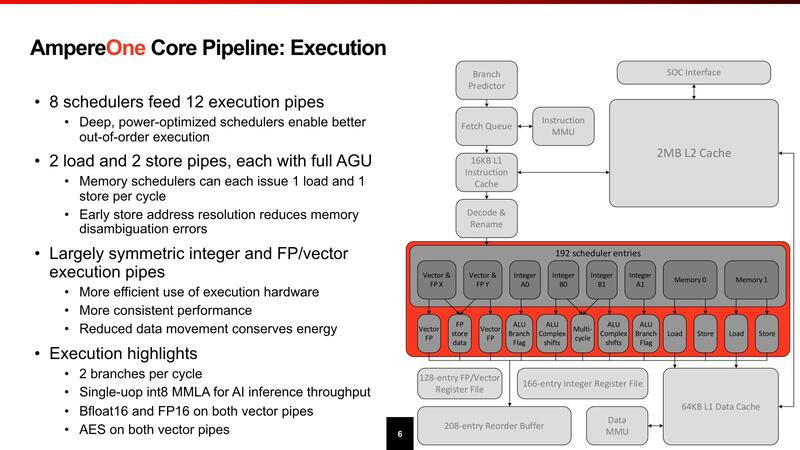
高密度/省電力な構成のAmpereOne
スケジューラーは192エントリーと、決して多くない。なんなら前回のOryonの方が倍以上ある。実行ユニットは全部で12とあるが、FPUが3つ、ロード/ストアーが4つなのでALUは5つ。実質的には1サイクルで4つのALU命令と、これに付随するロード/ストアー命令を1サイクルで2つ実行できる、という構成である。
FP/Vectorも同じで、3つと言いつつ1つはストアーデータだったりするので、実質2命令+2ロードといった形で、決して高性能ではない(この構成を見るとSVEのサポートはなくNeon止まりな気がする)。
レジスターファイルはALUが168、Vectorが128で、これもそれほど多くない。ただALUは実質4+2命令(Vectorなら2+2命令)ということを考えるとこの程度で十分なのだろう。むしろこの規模でありながら、分岐予測を1サイクルに2つ実施できるのが目を惹く。この規模の他のプロセッサーは1サイクルあたり1つだったことを考えると、ピーク性能を高めるよりも実効性能を落とさないことに力点が置かれているように感じる。
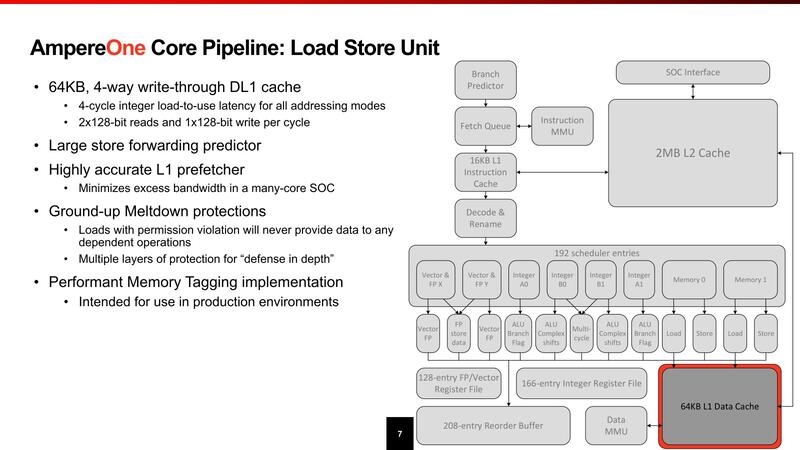
ロード/ストアーユニットは当然L1 Dキャッシュと密接に関係しているわけだが、Load-to-useは4サイクルと結構高速だし、store forward predictor(書き出したデータをプログラムの中で再び使うという処理で、メモリーまで書き出し終わるのを待って読み直すのは遅くなりすぎる、書き出しを掛けてもその値を保持していたレジスタファイルを破棄せずに再利用できるようにする仕組みだが、それを事前予測することで効率的にStore forwardを実行できるようにする)というメカニズムは初めて目にした。
TLBはそれなりに重厚ではあるが、これはサーバー向けということを考えればそれほど不思議ではないし、極端に多いわけでもない。
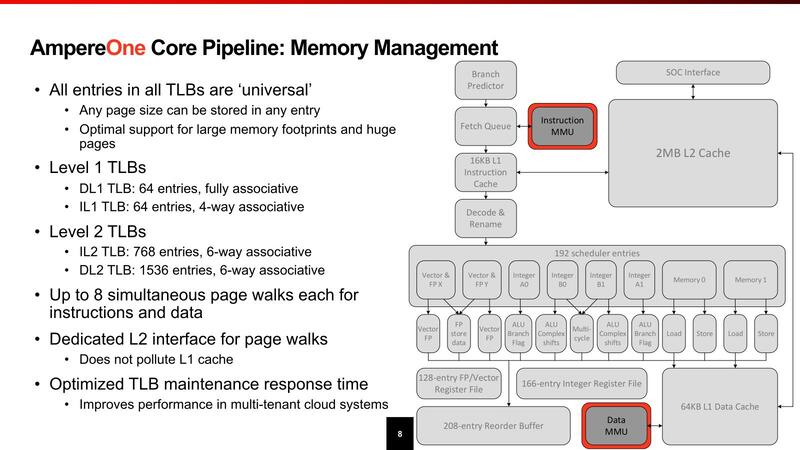
おもしろいのは、TLBが任意のページサイズをサポートできる(インテルのx86では、4KB/2MB/1GBで利用できるエントリー数が違う)あたりだろうか。あと同時に8つのPage Walkを同時に発行できたり、1次キャッシュと2次キャッシュを別々にPage Walkできたりするあたりは珍しい。このあたりも、Page Walkで余分なレイテンシーが増えることを極力避けるためと思われる。
2次キャッシュはコアごとにプライベートである。消費電力増加を避けるためか、Load-to-Useは11サイクルと大きめだが、これは2次キャッシュの速度としては妥当だろう。
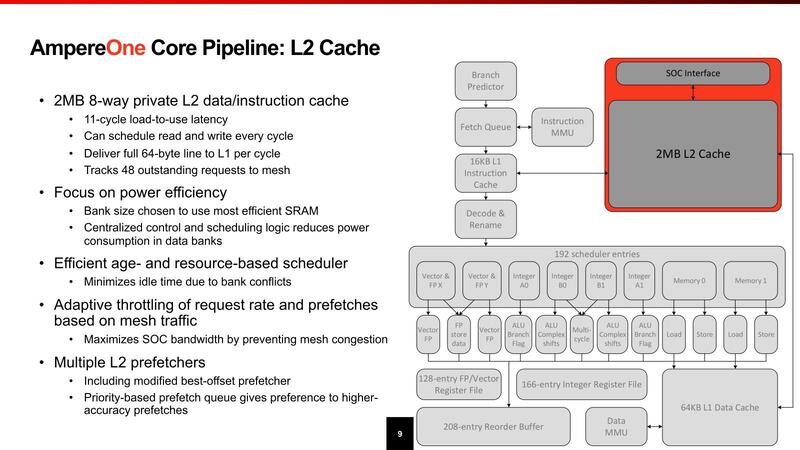
1次キャッシュとの帯域は64Bytes/サイクルで、このあたりは最近のプロセッサーらしい速度。3次キャッシュとの関係は不明だが、後述するように3次キャッシュは全部で64MBしかなく、しかもスヌープフィルターも兼ねていることを考えるとインクルーシブ・キャッシュ構成というのは考えられず、エクスクルーシブ・キャッシュ構成と思われる。
AMDのGenoaよりも性能消費電力比が30%以上高い
そんなAmpereOneであるが、同社初のチップレット構成である。メモリーコントローラーおよびPCIeは外付けのチップレットの構成となる。したがって、8ch DDR5のAmpereOneと12ch DDR5のAmpereOne Mは、同じダイであり単にメモリーコントローラーの搭載数が異なるという形になる。
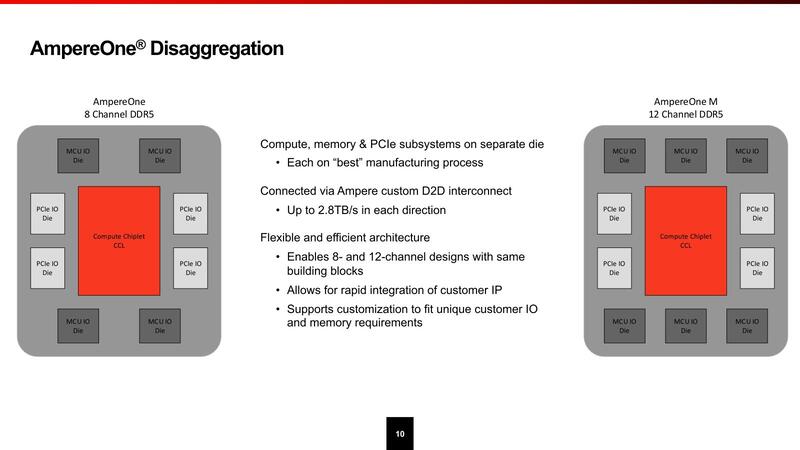
このチップレット同士の接続は、同社独自のインターコネクトを使っているという説明である。最大2.8TB/秒とあるが、これは全チップレットを接続した場合の数字であり、おそらくチップレット1個当たりは180GB/秒程度。16bit幅とすれば信号速度は11.2GT/秒程度と考えられる。あるいは32bit幅で5.6GT/秒かもしれないが、それだと配線が大変そうだ。
AmpereOneのドキュメントを読んでもDDR5とだけしか書かれていないが、8chで16DIMMが最大構成ということから1chあたり2DIMMになるので、すると速度としてはDDR5-4400のRegistered DIMMと考えられる。ということは1chあたり35.2GB/秒、2chでも70GB/秒少々なので、180GB/秒の帯域があれば十分だろう。仮に1DIMM/チャンネルに制限してDDR5-6400を使ったとしてもチャンネルあたり51.2GB/秒、2chで102.4GB/秒に過ぎないからだ。
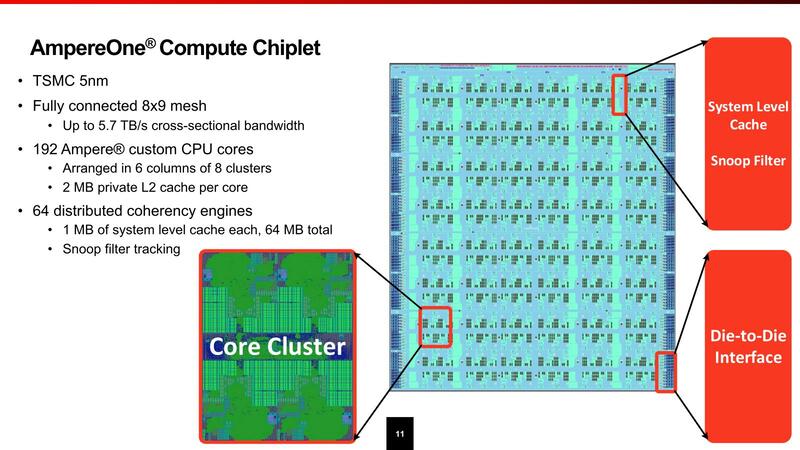
コンピュート・チップレットの構造が下の画像で、4つのCPUコアで1つのクラスターを構成し、このクラスターを6×8で48個搭載し、合計192コアという形だ。
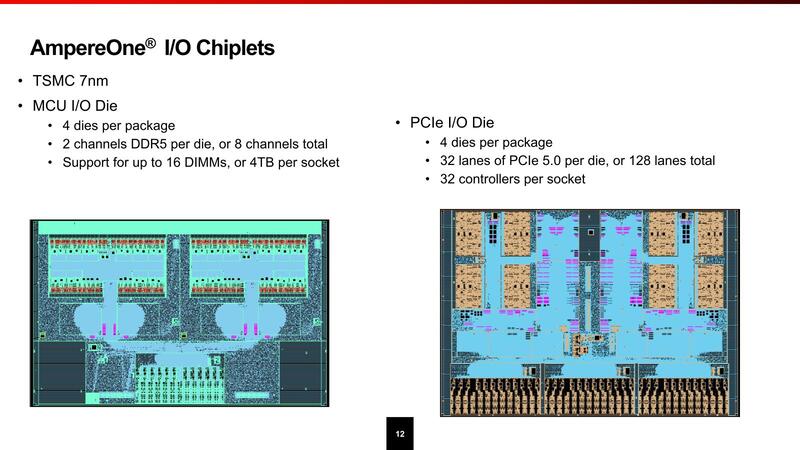
チップレットへの接続用のPHYは16グループ用意されており、当初からAmpereOne Mの構成を想定に入れていることがわかる。このコンピュート・チップレットはTSMC N5だが、I/Oチップレットの方はTSMC N7であると発表されている。
性能としては、SPEC CPUの結果はAMDのGenoa/Bergamoと比較して、Genoa比で最大50%、Bergamo比でも15%性能消費電力比が向上したとしており、ラック当たりの性能で言えば34%高いとしているが、性格からすればGenoaよりもBergamoとの比較が正しいと思われ、この場合は10%程度の向上に過ぎない。
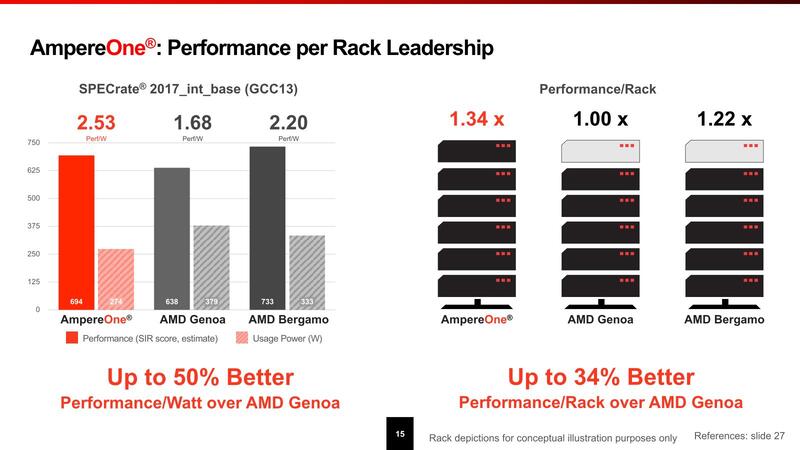
またクラウド・ワークロードに関してもGenoaと比較して性能消費電力比が32~58%向上、より少ないラック数/消費電力で同等の処理が可能としている。
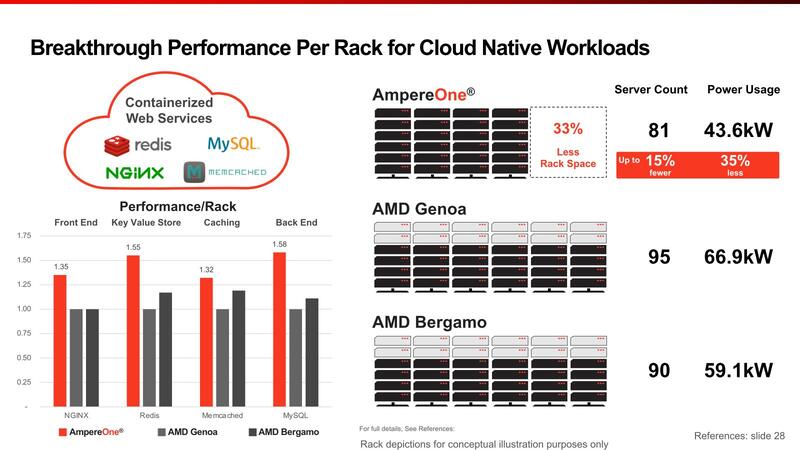
先ほども書いたが、現状Armベースでユーザーが購入できるサーバー向けプロセッサーは意外と少なく、それもあってAmpere Alter/AlterMAXが多く利用されていたわけだが、こうした市場向けにより高い性能消費電力比のプロセッサーを導入するという同社の目論見に対応した最初の製品が無事出荷開始されているのはとりあえずは喜ばしい。
Genoa/Bergamoには勝ててもTurinにはどうか? Sierra Forestとはどうだろう? などいろいろ疑問はあるが、そのあたりのデータも今後出てくるかもしれない。

この記事に関連するニュース
-
Intelが「Core Ultraプロセッサ(シリーズ2)」のラインアップを一気に拡大 ノートPC向けを中心にデスクトップPC向けや組み込み用も
ITmedia PC USER / 2025年1月6日 23時5分
-
2024年の自作PCトレンドはコレ! CPUの注目はCore Ultra 200S&Ryzen 9000
ASCII.jp / 2024年12月28日 11時0分
-
Intel×AMD×Qualcomm対決! 3プラットフォームの14型AI PC(Copilot+ PC)をテスト 比べて分かった違い
ITmedia PC USER / 2024年12月27日 12時0分
-
Intel×AMD×Qualcomm対決! 3プラットフォームの14型AI PC(Copilot+ PC)を横並びで比べてみた
ITmedia PC USER / 2024年12月24日 12時0分
-
GEEKOMの高性能ミニPCがCES2025で輝きを放つ
共同通信PRワイヤー / 2024年12月19日 17時40分
ランキング
-
12023年に急逝した五彩緋夏さんの親友、“2年前の写ルンです”を現像……緋夏さんとのお宝ショットに「この写真が見れてよかった」と大きな反響
ねとらぼ / 2025年1月13日 12時45分
-
2セザンヌの“700円福袋”を開封したら…… 予想以上の開封結果に驚きの声「太っ腹すぎる!」「プチプラでも優秀」
ねとらぼ / 2025年1月14日 19時30分
-
3IIJmio、mineo、NUROモバイル、イオンモバイルのキャンペーンまとめ【1月15日最新版】 110円スマホや高額ポイント還元あり
ITmedia Mobile / 2025年1月15日 10時34分
-
4「神ゲー」日本からの声高く翻訳後の日本売上7倍に、“日本人に何故か熱い注目あびたため”日本語実装のインディーSRPG―「実際は、賭けだった」語られる裏側
Game*Spark / 2025年1月11日 18時45分
-
5「配慮が足りない」 映画の入場特典で「おみくじ」配布→“大凶”も…… 指摘受け配給元謝罪「深くお詫び」
ねとらぼ / 2025年1月15日 7時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





