

ユニコードで文字数を数える方法
ASCII.jp / 2024年9月22日 10時0分
ユニコードでは複数の絵文字を結合させて 別の絵文字を表現することもある
Unicodeが一般的になって、日本語を含めて、さまざまな言語の文字を自由に使えるようになったが、「文字」を取り出す、あるいは数えるのが面倒になったのも確かだ。というのも、1つの文字が必ずしも1つのコードポイントで表現されるとは限らないからだ。
たとえば絵文字では、複数の絵文字をゼロ幅接合子(Zero Width Joiner:ZWJ、U+200D)で結合することで、別の絵文字を表現することがある。たとえば、「🐦 鳥(bird)」(U+1F426)と「🔥 火」(U+1F525)をゼロ幅接合子でつなげたものは、「🐦🔥フェニックス」(Unicode Emoji 15.1で定義)の絵文字になる。
コードだと「U+1F426」「U+200D」「U+1F525」なのだが、表示上は1つの文字に見える。なお、こうした組み合わせは、ユニコード仕様書で定められ、誰かが勝手に作っているわけではない。
漢字の場合には、異字体がある。こちらはコードポイントの後ろに「異字体セレクタ」が付く。簡単に言えば、ユニコードは32bitのコードポイントを使うが、人間が認識する文字である「書記素クラスタ」(grapheme cluster)は、複数のコードポイントから構成されることがある。文字列から、書記素クラスタを認識して境界を決定する処理を「テキスト・セグメンテーション」という。
これは人間が見たときに「1文字」に見えるようなコードポイントのつながりを認識して、切れ目を見つけるのが「テキスト・セグメンテーション」である。ユニコードの処理では、分割された1文字(人の目に見える1文字)を「書記素」(grapheme)と表現することがある。
テキスト・セグメンテーションに関しては、ユニコードでは「Unicode Standard Annex #29 (UAX#29) Unicode Text Segmentation」(https://unicode.org/reports/tr29/)に定義がある。
PowerShellなどで、文字列を正しく分割するには、.NETの「StringInfoクラス(System.Globalization)」(https://learn.microsoft.com/ja-jp/dotnet/api/system.globalization.stringinfo?view=net-8.0)を使うのが簡単だ。
まずは、文字(書記素)の先頭位置を求める。PowerShellでは、内部は、リトルエンディアンのUTF16(これをWindowsではUnicodeと呼ぶ)でエンコードされている。このため、一部のコードポイントは、サロゲートペアを使って16ビット文字コード2つで表現されている。
StringInfoクラスの「ParseCombiningCharacters」メソッド(https://learn.microsoft.com/ja-jp/dotnet/api/system.globalization.stringinfo.parsecombiningcharacters?view=net-8.0#system-globalization-stringinfo-parsecombiningcharacters(system-string))は、文字列を受け取って、その書記素の先頭部分の位置を返すものだ。これを使うことで、文字の「境界」を得られる。
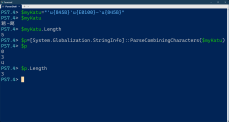
具体的には、PowerShellのコマンドラインで以下のようにする。
[System.Globalization.StringInfo]::ParseCombiningCharacters(<文字列>)
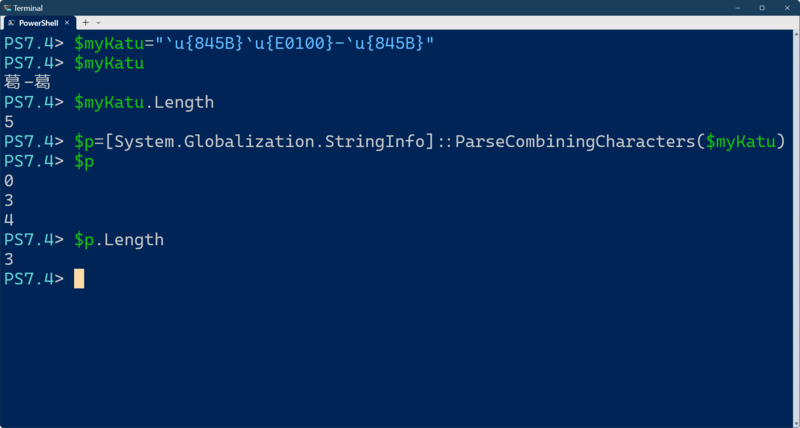
このメソッドは、書記素の先頭の位置を返す。たとえば、「葛󠄀-葛」という文字列は、コードポイントとしてみると、以下の図のようになっている。
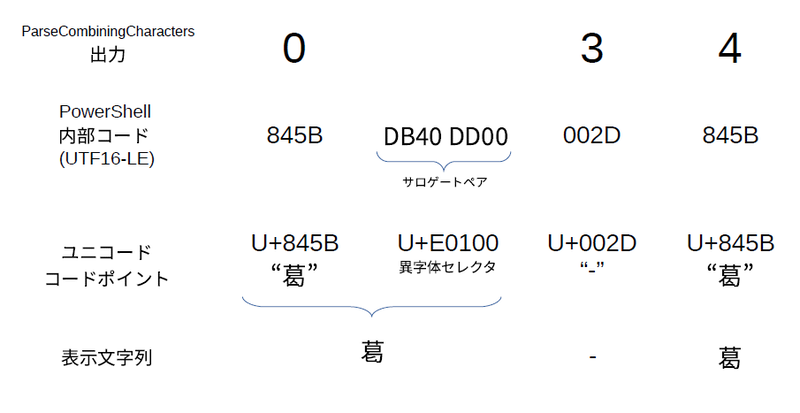
この文字列に対して、ParseCombiningCharactersを実行すると、「0、3、4」という位置が返る。これは、文字の先頭が0文字目、3文字目、4文字目にあるということだ。入力が面倒そうだが、正直にキーを打つ必要はなく、先頭部分は、「“[stringinfo”+Tabキー」で、後半は「“]::p”+Tabキー」で開きカッコまで補完できる。
なお、いわゆる文字数(書記素クラスタの数)は、ParseCombiningCharactersがいくつ整数を出力しているかを数えるだけでいいので、
([System.Globalization.StringInfo]::ParseCombiningCharacters($x)).Length
で求めることができる(コマンドラインならMeasure-Objectコマンドを使うこともできる)。
文字を取り出す
この文字先頭位置から「書記素クラスタ」(文字)を取り出すには、GetNextTextElementメソッド(https://learn.microsoft.com/ja-jp/dotnet/api/system.globalization.stringinfo.getnexttextelement?view=net-7.0)を使う。このメソッドは、コードポイントが複数あっても、1つの書記素クラスタ分を文字列として出力してくれる。
具体的には、ParseCombiningCharactersの出力(文字の先頭位置)を、2つ目の引数に入れて文字(書記素クラスタ。セグメント)を取り出す。ParseCombiningCharactersの出力する位置を変数に入れおく。
$p=[System.Globalization.StringInfo]::ParseCombiningCharacters($x)
次にこれを使って、文字を順次取り出す。
$p | foreach-object { [System.Globalization.StringInfo]::GetNextTextElement($x,$_)
とすればよい。
ついでに16進数でダンプさせるなら、
$p | %{ $t=[System.Globalization.StringInfo]::GetNextTextElement($myKatu,$_); "$_ $t`t$(([int[]][char[]]$t)|%{$_.ToString('X4')})" }
などとする。
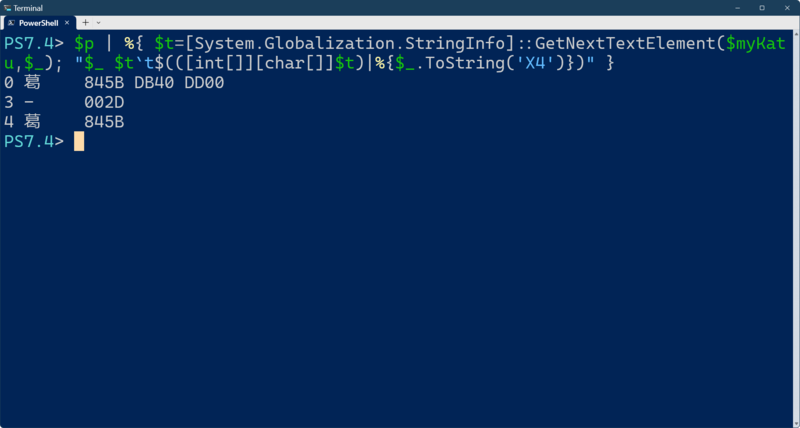
サンプルとしてもう少し複雑な文字列を使ってみる。
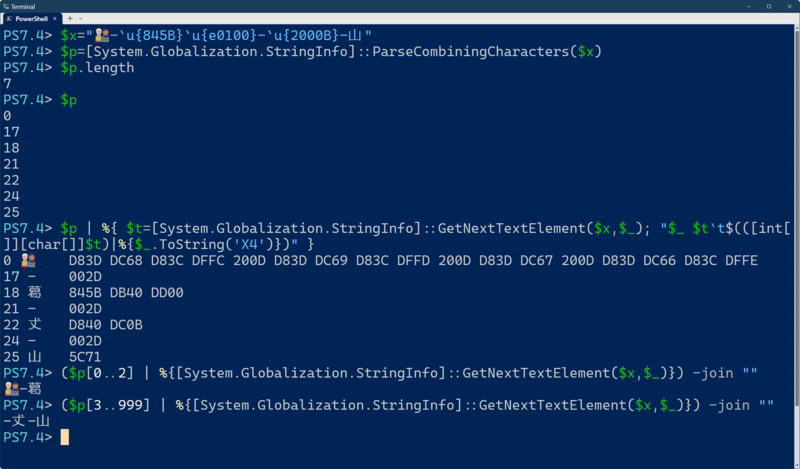
これは、家族4人の絵文字と異字体セレクタ付きの文字、サロゲートペアになる文字、それ以外の漢字の4つをハイフンでつなげたもので、$xに代入してある。まずは、$pに文字列内の先頭位置を格納しておく。このとき$p.lengthが書記素クラスタの数(文字数)となる。
$p=[System.Globalization.StringInfo]::ParseCombiningCharacters($x) $p.length $p
たとえば、先頭から3文字目(葛󠄀)までを取り出したいなら、
($p[0..2] | %{[System.Globalization.StringInfo]::GetNextTextElement($x,$_)}) -join ""
とする。前半の$p[0..2]は、3つ目の書記素クラスタの開始位置までの開始位置を取り出すもの(配列のインデックスなので0から始まることに注意)。後半の部分は、GetNextTextElementを使って、書記素に対応する文字列を取り出し、全体を-joinで結合して1つの文字列としている。
同様に後半4文字目から最後までを取り出したいなら。
($p[3..999] | %{[System.Globalization.StringInfo]::GetNextTextElement($x,$_)}) -join ""
とする。「[3..999]」は、書記素開始位置配列の4文字目から最後までを取り出すもの。範囲演算子では、対象配列の最大インデックスが分からないとき、それよりも大きなインデックス値を指定(ここでは999)を指定しておけば、エラーにならず、最大インデックスを指定したのと同等になる。もちろん「$p[3..($p.Length-1)]」などのように正しく計算してもいいが、最大インデックスを超えない大きな数を使うほうが簡単だ。
このようにすることで、文字列の前半部分(Left関数)、後半部分(Right関数)のようにユニコード文字列を正しい位置で分割することができる。
ユニコードになって、さまざまな文字を扱えるようになった反面、単純な文字列処理が不可能になり、今回のように、StringInfoクラスなどを使ってテキスト・セグメンテーションをして、その上で、分割などの処理をする必要がある。
なお、ユニコードの正しいテキスト・セグメンテーション(前述のUAX#29)には、.NET 5.0以降の対応なので、処理には、PowerShell(pwsh.exe)のほうを利用する。

この記事に関連するニュース
-
窓辺の小石 第193回 チルダの伝説
マイナビニュース / 2024年11月22日 14時53分
-
日本で生まれ世界が育てた「絵文字」、アップル「Genmoji」の登場でどう変わる?
マイナビニュース / 2024年11月21日 18時30分
-
河野太郎氏の「エゴサ」力、さらにアップ? ジョージア語、タイ語にも反応、駐日大使も「恐れ入りました」
J-CASTニュース / 2024年11月17日 13時25分
-
あらためてIPv6基本のキ
ASCII.jp / 2024年11月3日 10時0分
-
『ウマ娘』新シナリオ楽曲「O - ロライズ」に仕込まれた暗号に気づいた?思わずうるっとくる“粋なメッセージ”がそこに
インサイド / 2024年11月1日 16時0分
ランキング
-
1NHKのネット受信契約(案)が“ダークパターン”過ぎて見過ごせない件(前編) NHKの見解は?
ITmedia NEWS / 2024年11月28日 19時9分
-
2どうする? 大学生用パソコンの選び方 「4年通しよりも2年で買い替え」がオススメな理由
ITmedia NEWS / 2024年11月28日 13時26分
-
3「ミリ波対応スマホ」の値引き規制緩和で感じた疑問 スマホ購入の決め手にはならず?
ITmedia Mobile / 2024年11月28日 18時13分
-
4松屋が“店内持ち込み”で公式見解→解釈めぐり賛否 「何と言うサービス精神」「バレなきゃいいのか……?」
ねとらぼ / 2024年11月28日 20時2分
-
5えっ、プレステ2のゲーム高すぎ!? ここにきて中古ソフトが高騰している納得のワケ
マグミクス / 2024年11月28日 21時45分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





