

妙に性能のバランスが悪いマイクロソフトのAI特化型チップMaia 100 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年9月30日 12時0分

Hot Chips第4弾は、マイクロソフトのMaia 100である。Maia 100はマイクロソフト初の自社製AIチップということで、昨年11月に開催されたMicrosoft Ignite 2023で発表された。
ちなみにこの時にはMaia 100に加え、Armベースの汎用プロセッサーであるCobalt 100も発表、AmpereのArm CPU(おそらくAmpere Alter/Alter MAXだろう)より40%高速といった数字は示されていたが、これはそもそもの世代の違い(Alter/Alter MAXはNeoverse N1ベースである)を考えれば妥当な数字である。


マイクロソフト独自設計のAI特化型チップMaia 100
Maia 100はマイクロソフトの独自設計となっている。構成的にはコンピュート・チップレットに4つのHBM2Eを集積した構成である。

発表された内容は以下のとおりで、設計はOpenAIと共有しており、OpenAIによる改良もあったとする。
- AIの訓練と推論の両方に対応
- 5nmプロセスで製造、トランジスタ数1050億個
- チップの冷却には液冷を利用。これに対応してMaia 100専用のラックを製造。冷却ユニットを裏側から見ると巨大なラジエーターが斜めに鎮座している




Maia 100は、今年からAzureへの展開を予定するという話であった。ちなみに同じ基調講演で、そのAzureにはNVIDIAのH100/H200とAMDのInstinct MI300Xのインスタンスも用意されることが明らかにされており、要するにマイクロソフトはAI向けインスタンスはMaia 100のみとするわけではなく、顧客ニーズに応じてNVIDIAとAMDのソリューションも同時に提供していくとした。クラウドプロバイダーとしては当然のスタンスだろう。
Ignite 2023で説明されたのはこの程度で、これ以上の詳細は未公表のままだったのだが、それが今回Hot Chipsで公開された。これにあわせてマイクロソフトのブログでも、ほぼ同じ内容を記したエントリーが公開されたので、両方の情報をまとめて説明していこう。
まさかの6bitマシンが復活
基本的な構成は、ここまで説明したことのまとめみたいなものである。

ここからもう一段踏み込んだスペックが下の画像だ。ここで気になるのは「なぜHBM2Eなのか?」であるが、これはおそらくASICパートナー側の問題だったものと思われる。
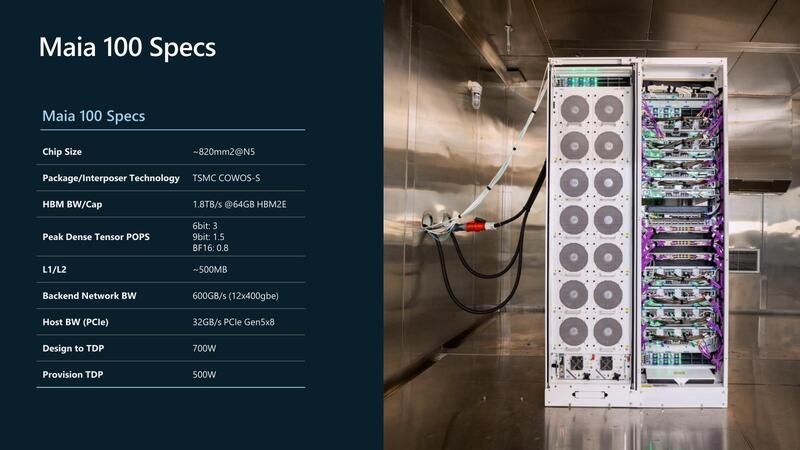
マイクロソフトも小規模なASICはこれまで自作してきていた。FPGAでまず回路を起こし、次いでそのFPGAをそのままASICにするような形だ。ところが5nmで800mm2を超えるような規模のASICは、そもそもFPGAでのプロトタイプ作成は極めて困難である(Virtex Ultrascale+を100個くらい並べても収まりきるかどうか……)。
しかも、FPGAのプロトタイプは論理設計の検討やソフトウェアの先行開発には非常に便利だが、物理設計には全然役に立たない。そこでこうした先端プロセスの物理設計のノウハウを持つデザインサービスを提供する企業と提携し、論理設計はマイクロソフトが担い、その先の物理設計をデザインサービス企業に任せるといったことが普通に行なわれている。
Dan Nystedt氏によれば、Maia 100の物理設計パートナーは台湾のGUC(GLOBAL UNICHIP CORP.)だったらしい。GUCは今でこそHBM3Eまでの設計をサポートしている(9月24日には、9.2GbpsのHBM3Eまでをカバーした事を発表した)が、これはわりと最近の話である。
Maia 100の場合は2023年11月にチップが発表されているということはおそらく物理設計は2022年中には完了しているわけで、逆算すると2021年末あるいは2022年初頭あたりに物理設計がスタートしたことになる。この時期のGUCは、まだHBM3に関するノウハウは十分ではなかった時期である。
GUCとしてはマイクロソフトに、ノウハウが十分にあり確実に設計できる代わり、速度がやや遅いHBM2Eと、ややリスクはあるが速度の速いHBM3/3Eのどちらを使うかの選択肢を示し、結果としてマイクロソフトがリスクの低い方を選んだのではないかと思う。
それはともかく、一番利用を想定しているのが9bitないし6bitというのがおもしろい。構成的には6bitが基本で、9bitは6bit×2で12bitのうち9bitを利用、BF16は6bit×4で24bitのうち16bitを利用といった形になるのだろう。6bit×3だと性能が1POPsにならないとおかしいからだ。
おそらく仮数部と指数部、それぞれに12bitずつ割り振ってうち8bitづつを使うといった形になっているのだろう。まさかここに来て6bitマシンが復活するとは思わなかった。
クラスター同士の接続はメッシュ・ネットワークを経由
Maia 100の内部はTensor Unit(TTU)とVector Engine(TVP)、それとデータ移動用のTile Data Movement Engine(TDMA)、Tile Control Processor(TCP)とL1 SRAMから構成されるタイルが基本単位である。
このタイルを4つとNOC、L2 SRAM、CCP(Cluster Control Processor)とCDMA(Cluster Data Movement Engine)から構成されるクラスターがある意味処理の最小単位である。Maia 100はこのクラスターを16個搭載する。
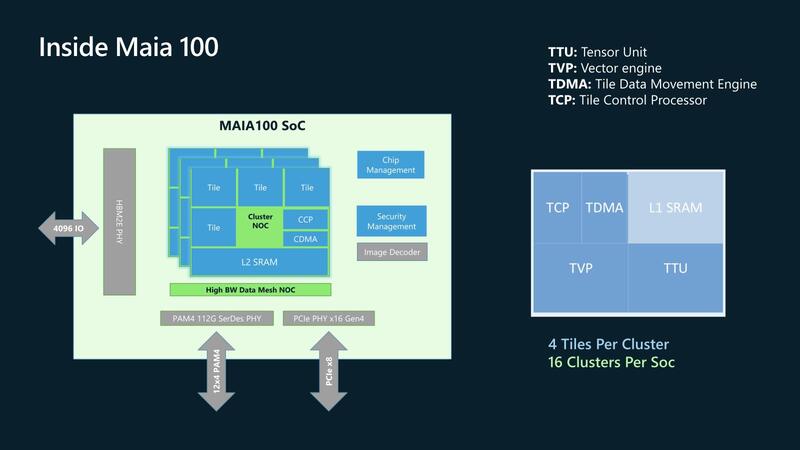
ちなみに先程6bitマシンと言ったが、それが実装されているのはTTUの方であって、TVPの方はFP32やBF16をサポートするというあたり、比較的普通の8bitマシンベースのSIMD Engineの模様だ。

特徴的なのはまずDMA Engine。単にL2 SRAMとL1 SRAMの間でデータ交換をするのみならず、6bitデータと9bitデータの型変換までしてくれるようだ。
Hardware Semaphoreだが、これはCCPとTCPの間での制御に用いられるようだ。そもそもタイルの中でTVPとTTU、それとブロック図には出てこないがRead Copy Engine/Write Copy Engineの4つのエンジンは独立して勝手に動作する。この4つのエンジンの制御はTCPのお仕事なのであるが、4つのタイルの間で作業を分割するようなケースでは、タイル間の同期を取る必要があり、ここでHardware Semaphoreが利用されるということらしい。
クラスター間の同期にも使われるかどうかは不明で、こちらはメッシュ・ネットワークを経由してのデータフロー式なのかもしれない。そのクラスター同士の接続方法が下の画像だ。
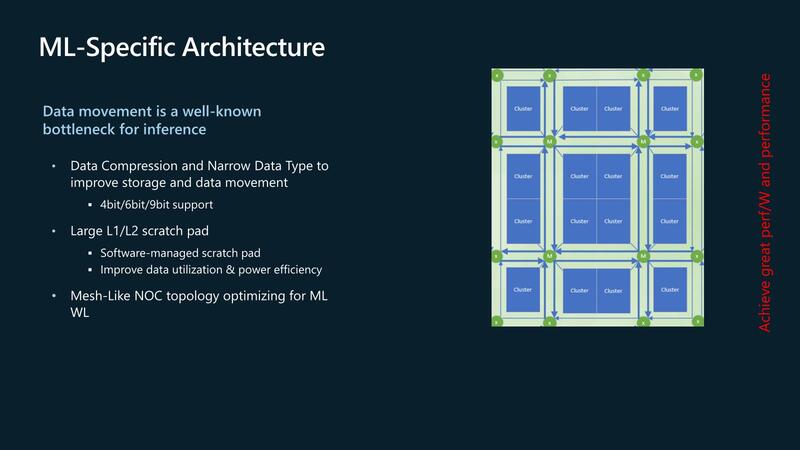
一見すると良くあるメッシュ構成であるが、よく見ると、4つのMesh Stop(図中の(M))から4つのクラスターに線が伸びているあたり、データの移動をする場合、以下の過程になる。
(1) あるタイルのL2 SRAMからCDMA経由でネットワークのMesh Stop((M)部)にデータを送り出す。 (2) 送られたデータは、目的のタイル(が接続しているMesh Stop)に転送される。運が良ければ1hopで転送できるが、運が悪いと2hopかかる。 (3) Mesh Stopから目的のタイルのL2 SRAMに送り込まれる。
ここで謎なのは、だとしたら「そもそもメッシュ要らなくね?」という話である。4クラスターごとに1つMesh Stopがあるから全部で4つのMesh Stopでいいわけで、それならそもそもMesh Stop同士を相互接続するのはそれほど難しくないだろう。
あと、もう一度上の画像を見ると、(M)とは別に(x)という別のMesh Stopがチップの周辺に置かれているが、この(x)の用途が明らかにされていない。
ここからは筆者の想像なのだが、実はこの(x)は、Chip-to-Chip接続のためのMesh stopなのではないかと考えている。つまりチップレット的に複数のMaia 100を接続可能であり、その際には個々のチップの(x)同士がインターコネクト(UCIeかなにかだろうか?)で接続されるという方法だ。
正直この程度の規模でメッシュライクなNOCを使うのはやや大げさすぎる。が、もしチップレット的に複数チップを接続して使うのであれば、メッシュ風にするのは極めて妥当である。
難点を挙げるとすれば、現在公開されているMaia 100チップはもうパッケージに載せているので、この状態では複数チップを相互接続するには配線長が長すぎて現実的ではないことだ。ただ現状公開されているのはMaia 100が1個のバージョンで、現在複数のMaia 100を搭載するパッケージを開発中だとすれば、これは大きな問題にならない。
Maia 100は単体で820mm2の巨大なダイで、それにHBM2Eが4つ付くから、全体の面積は軽く1000mm2を超える。これを複数搭載しようとすると、巨大なシリコン・インターポーザーが必要になるが、TSMCのCoWoSでこれが可能になるのは早くて2026年だろう(現状でも80×80mmのパッケージは作れるが、これでは2つ載るかどうか微妙なところだ)。
ゆえに、この世代ではメッシュの実装はするものの、複数チップの接続を実際に行なうのは次世代Maia向けといったところが実情ではないかと考える。
タイル1個あたりの性能が妙に高すぎてバランスが悪い これをどう料理していくかが見もの
では現状ではチップ間をどう接続するか? であるが、400Gイーサネットを3本束ねて1200Gbpsのリンクを作り、これでチップ間接続およびノード間接続を行なう仕組みだ。1200Gbpsが4対分あるので、トータルで4.8Tbpsもの巨大な帯域を確保している。
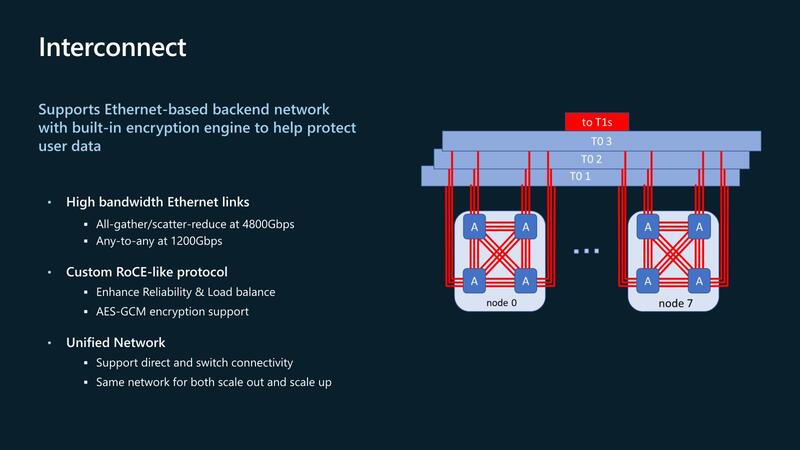
なお、マイクロソフトはUltra Ethernet ConsortiumのSteering Memberの1社でもあり、現在は独自プロトコルを実装しているとされるが、将来はウルトラ・イーサネットに置き換えられることになると思われる。
そのMaia 100のSoftware Stackが下の画像で、Pytorchベースの他にTritonベースとMaia APIの、合計3種類に対応する。Pytorchは広く使われているが、TritonはOpenAIが発表したOpen Sourceの言語で、Maia APIは名前の通りMaia専用のライブラリーとなっている。
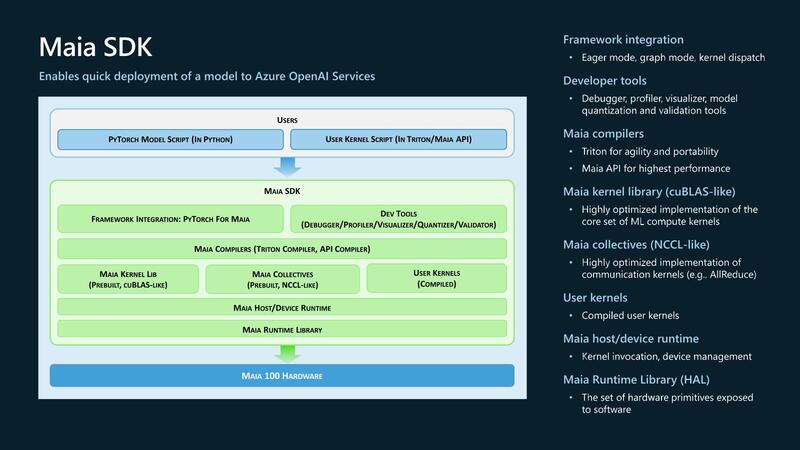
以上がMaia 100に関する現時点で公開された情報である。なんというか、タイルの中の詳細などは一切明らかになっていないし、そのあたりを公開するつもりもない(おそらくMaia APIを使う際には必要なのだろうが、Maia APIを外部に公開するつもりがないのかもしれない)。
ただ冷静に考えると、BF16でも0.8POPs(800TOPS)である。16個のクラスターおのおのに4つのタイルが内蔵されているから、タイルあたりで言えば50TOPSの演算性能になる。これを実現するのはそう簡単ではない。動作周波数も不明だが、例えば2GHzだとすると1サイクルあたり2万5000 Op/サイクルになる計算だ。
この数字はTTUとTVPを合わせてのものだろうが、例えばTTUが24000 Op/サイクル、TVPが1000 Op/サイクルとしてもけっこう実装は難しい。なんというか、タイル1個あたりの性能が妙に高すぎるのである。SIMDで言えば1000Op/サイクルということは1万6000bit幅のSIMDとかいうバカげた代物になりかねない。
妙にバランスが悪い気がするのである(Granularityが大きすぎる、という表現ならおわかりいただけるだろうか?)。そうした部分も含めてまだ謎は多い。現在マイクロソフトはGen 2 Maiaを開発中という話で、先ほどのメッシュのところで触れたチップレットの可能性を含め、どんなふうに進化していくのか楽しみである。

この記事に関連するニュース
-
世界最速に躍り出たスパコンEl Capitanはどうやって性能を改善したのか? 周波数は変えずにあるものを落とす
ASCII.jp / 2024年11月25日 12時0分
-
【新刊案内】世界のチップレット・先端パッケージ 最新業界レポート 発行:(株)シーエムシー・リサーチ
PR TIMES / 2024年11月19日 10時45分
-
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分
-
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月11日 12時0分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
ランキング
-
1NHKのネット受信契約(案)が“ダークパターン”過ぎて見過ごせない件(前編) NHKの見解は?
ITmedia NEWS / 2024年11月28日 19時9分
-
2どうする? 大学生用パソコンの選び方 「4年通しよりも2年で買い替え」がオススメな理由
ITmedia NEWS / 2024年11月28日 13時26分
-
3「ミリ波対応スマホ」の値引き規制緩和で感じた疑問 スマホ購入の決め手にはならず?
ITmedia Mobile / 2024年11月28日 18時13分
-
4松屋が“店内持ち込み”で公式見解→解釈めぐり賛否 「何と言うサービス精神」「バレなきゃいいのか……?」
ねとらぼ / 2024年11月28日 20時2分
-
5ローン・クレカ審査可否の背景が分かる 信用スコア開示サービスがきょうスタート
ITmedia NEWS / 2024年11月28日 13時59分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





