

大型言語モデルに全振りしたSambaNovaのAIプロセッサーSC40L Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年10月7日 12時0分

Hot Chips第5弾は、SambaNovaのSC40Lを取り上げたい。SambaNovaと同社の最初のプロセッサーであるSC10は連載595回で説明しており、今回はここからのアップデートになる。

前回は2020年12月で、ちょうどCardinal SN10というチップをリリースした直後である。この後2021年、SambaNovaはCardinal SN20をリリース、そして2022年にCardinal SN30をリリースしている。ただこのSN20とSN30は同じもので、SN20×2がSN30という構成である。スペックをまとめると以下になる。
要するにSN20はSN10のマイナーバージョンアップといった構成で、SRAM容量を若干増やしたのと、おそらくは動作周波数をやや引き上げた程度の差しかない(この話は後述する)。
SN20を利用した製品とサービスは存在はしたのだろうが、すぐにSN30に置き換えられることになってしまった。なぜ「存在はしたのだろう」と言えるかというと、同社の提供するSoftware Tuning ToolであるSambaTuneのRelease Notesに"Release 1.17 (2023-10-20) Added GPT13B examples for SN20 and SN30."の文言があるからである。ただ、どの程度の期間SN20を利用したサービスが提供されていたのかはやや疑わしい。
もう1つ謎なのが、DRAMの種別である。2020年にSN10が発表された時のスライドによれば、TBクラスのメモリーを外付けできるという話であった。これに関しては、Hot Chips 33のスライドで、SN10-8R(SN10を8チップ搭載したシステム)がDDR4-2677を48ch接続して容量12TBであると記述されており、つまり1個のSN10にはDDR4-2667を6ch接続でき、おのおの256MBで合計1.5TBの容量になる、と考えられる。
SN20/SN30に関してはDDR5、という話が出ている2021年4月にSamsung Electronicsが公開したTech Blogによれば、SambaNovaのプラットフォームはDDR5を利用する、と説明されている。帯域的に言えば2021年末の段階ではまだDDR5-4800がなんとか出てきた程度の段階なのでDDR4に比べて帯域が倍というわけにはいかないのだろうが、容量的にはDDR4の2倍までサポートしていることもあり、おそらくはチャネル数を半分に減らしても同程度の容量(最大1.5TB)が可能になったものと思われる。
時期的な問題を考えると、ここでDDR4を使い続けるメリットは乏しい。なのだが、これと矛盾した資料が(しかもSambaNova公式から)出てきているのが頭が痛い。下の画像はALCF(Argonne Leadership Computing Facility)に納入されたSambaNovaのSN30ベースのプラットフォームの説明なのだが、ここには"TBs of DDR4 off-chip memory"とか書かれているのがわかる。
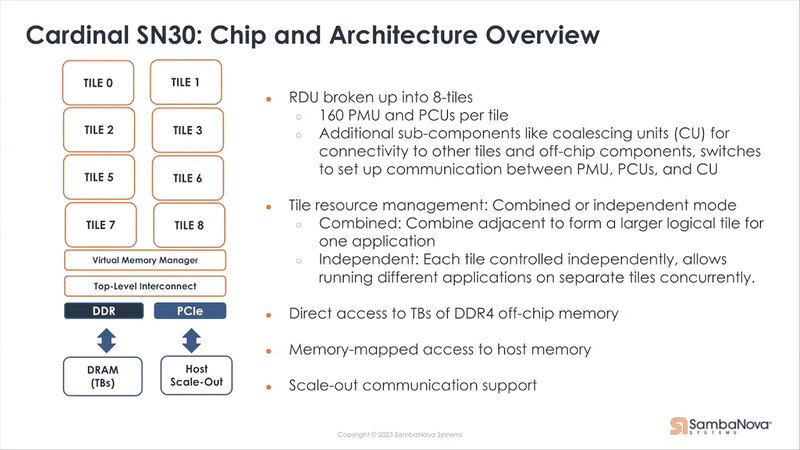
この"off-chip"がまた意味深だったりするのだが、それはともかくとして2022年にリリースされた製品がDDR4というのは正直考えにくい。ここはおそらくDDR5のタイプミスだと筆者は考えている。したがって、先の表は"DDR5?"としたわけだ。
DDR5を実装したSN30 中身はLPDDR5Xをベースにしたカスタム版メモリーか?
ちなみに同じ資料で、SN30のスペックが簡単に示されている。688TFlopsというのはチップ2つ分の性能と考えれば、SN20は半分の344TFlopsということになる。
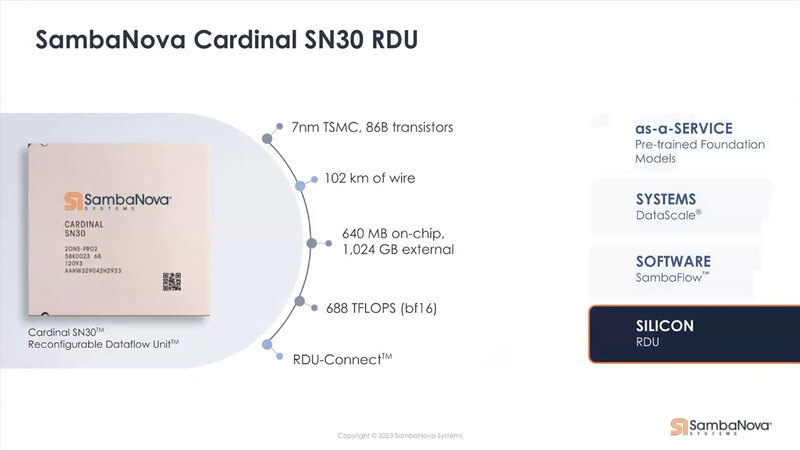
SN10の320TFlopsから7.5%ほどの性能向上である。この7.5%に近いものとしては、例えば元が1.3GHz駆動でこれを1.4GHz駆動にすると7.69%ほどの性能向上で、320TFlops→344.6TFlopsという計算になる。
もう1つの可能性としてはPCU(Pattern Compute Unit)の数が増えることだが、アルゴンヌ国立研究所が2023年10月に発表した"A Comprehensive Performance Study of Large Language Models on Novel AI Accelerators"という論文のなかに下のような表があり、ここでSN30はPCUが1280個と明記されている。なのでSN20は640個と推察できるし、これはSN10と変わらない。
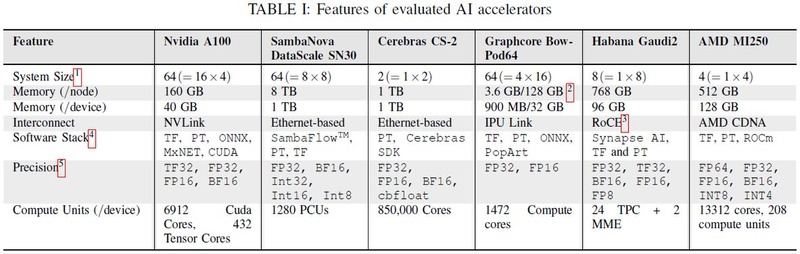
オンチップSRAMは? というと、SN10では"> 300MB on-chip memory"という表現になっており、正確なところはわからない。ただPCUとPMU(Pattern Memory Unit:SRAMである)が1:1で搭載されるのがRDUの基本構成であることを考えると、PMUの数もPCUと同じく640個で、おのおの0.5MBのSRAMを搭載して合計320MBと考えるのが妥当だろう(確証はないので、前掲の表では"?"を付けてある)。
では改めてSN10とSN20の違いを説明すると、動作周波数と外部メモリーのI/F以外にもう1つ、RDU-Connectの有無ではないかと筆者は考えている。プラットフォームの説明に戻るが、640個のPMUとPCUは、160個づつに分割されており、これをタイルと呼んでいる。
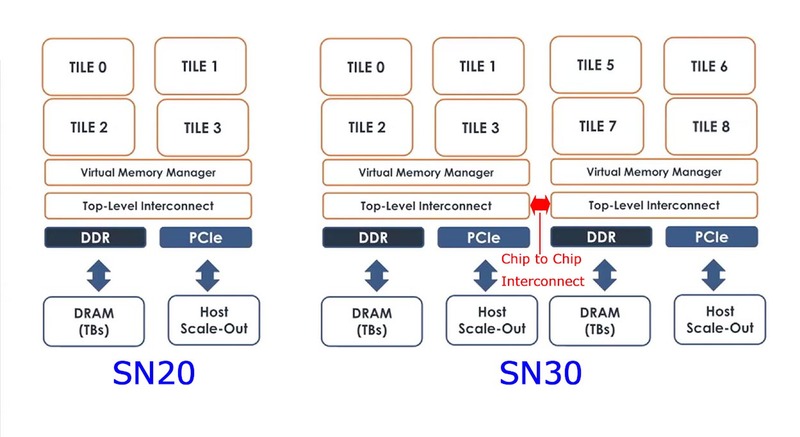
SN30では合計1280 PMU/PCUなので8タイルになり、SN20では半分の4タイルであるが、SN20ではSN10と異なり、Top-Level Interconnectに外部接続用のパスが追加されたものと考えられる。そしてSN30は、このSN20を2つパッケージに搭載し、間をインターコネクトで接続したような構成ではないかと考える。チップレットというよりはMCM(Multi-Chip Package)的な接続と思われる。
さらにもう1つ謎なのが、SN30のOff-Chip DRAMである。2022年9月28日付のEETimesの記事によれば「パッケージには2つのコンピュート・チップレットと、1TBの直接接続されるDDRメモリー(HBMではない)が含まれている」とあって、これが正確だとするとパッケージの中にDDR5チップを実装していることになる。
SamsungのBlogエントリーもあるようにSambaNovaはSamsungと協業しているようなので、Samsungのラインナップで見てみるとDDR5は最大でも32Gbit品しかないため、これで1TBを実装しようとすると256チップをパッケージ内に収める必要がある。言うまでもなく不可能だ。
GDDR6も最大で16Gbit品なので状況はむしろ悪化する。可能性があるのはLPDDR5Xで、こちらだと128Gbit品があるため1TBは64個でいける。まだかなり多いが、256個よりは現実的である。

これも筆者の推定なのだが、SambaNovaはLPDDR5Xをベースにしたカスタム版メモリーの開発を依頼したのではないだろうか。もちろん64個を平面的に実装するのは不可能だろうが、例えば下図のような構成はあり得るだろう。

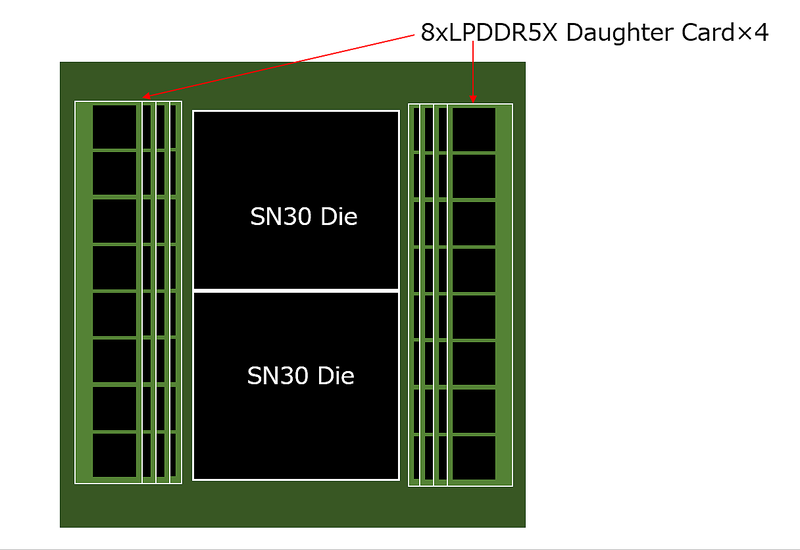
上図でいうところのドーターカードを薄くすれば現実的になるだろう(図では最下段もドーターカードにしているが、ここはパッケージ基板に直接実装でもいい)。ドーターカードを薄くすると機械的強度が気になるところだが、もともとLPDDR系は発熱が少ないので、例えば実装後に全部接着剤などで固めてしまえば(放熱には不利だが)機械的強度の確保は難しくない。というか、他の実装方法が思いつかないというのが正直なところだ。
HBMを搭載したSN40L On ChipとOff Chipの速度差を減らすためにメモリーを3階層にする
現在SambaNovaはSN10に代わり、このSN30をメインに据えてサービスを提供している。先程ALCFの説明スライドで示したように、ALCFにはSN10ベースのシステムに加えてSN30ベースのものが導入されている。また2023年3月には理研への導入が発表されたし、他にもいくつかの企業や研究所がSN30をベースとしたシステムを導入している。2023年11月には東京オフィスも開設された。
また同社は2020年までにシード200万ドル、シリーズAで合計6330万ドル、シリーズBで1億5000万ドルと合計2億1530万ドルの資金をファンドなどから調達していたが、2020年2月には2億5000万ドルをシリーズCで、2021年4月には6億7600万ドルをシリーズDでそれぞれ調達している。このシリーズC/Dの資金で開発されたのがSN20/SN30と、今回説明するSN40Lである。
SN10~30まではTSMC N7で製造されていたが、SN40LではTSMC N5に移行したほか、新たにHBMを64GB搭載した。引き続きOff Chip、つまりパッケージの「外」にDDR5を最大1.5TB接続できるが、SN30まではOn ChipのSRAMとOff ChipのDRAMの速度差が大きすぎるという問題があり、これへの対処としてメモリーを3階層にした格好だ。
内部構造も少し変更になった。SN10~SN30まではPCUとPMUが別々に存在する形でメッシュを構成していたが、SN40LではPCUとPMUが一体化する形でメッシュを構成するようになった。
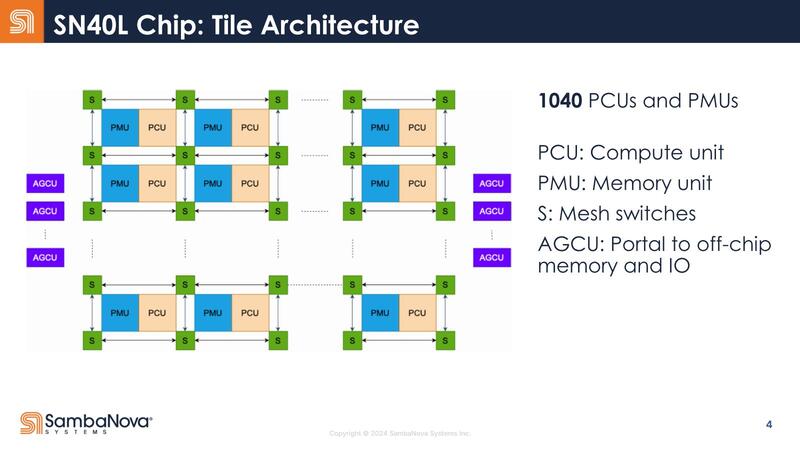
ただPMUのサイズは1個あたり0.5MBで、これはSN10~30までと変化がない。PCUの内部構造もSN10とほぼ同じに見えるし、PMUの方も表現こそ違うがSN10のものと基本的には変わらないように見える。
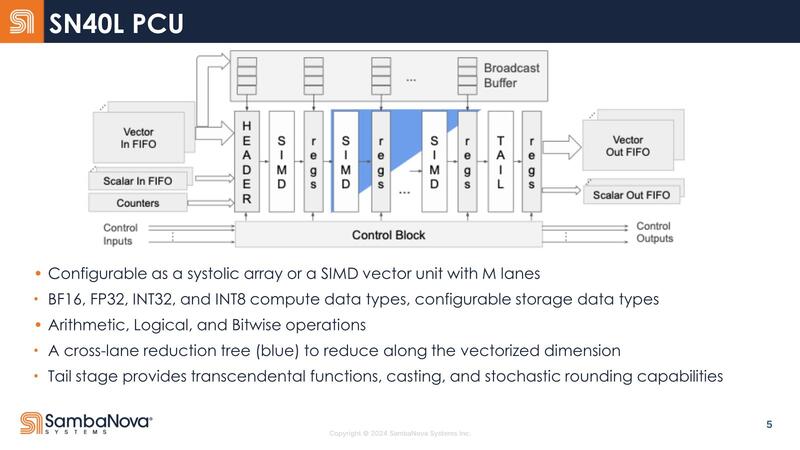
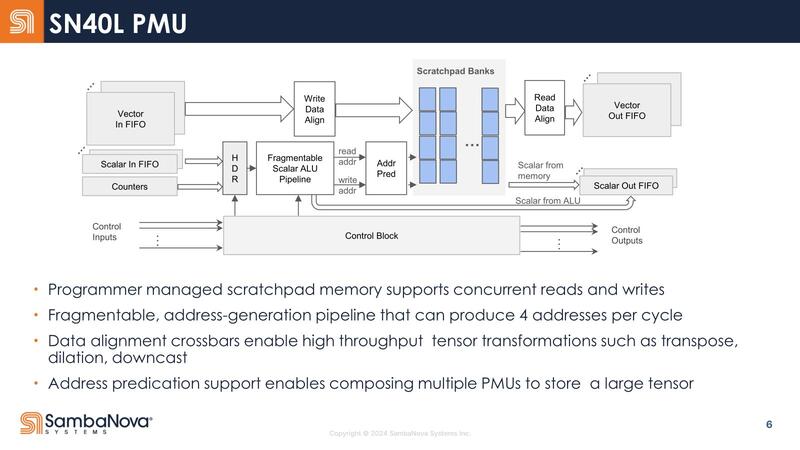
ちなみに今回Top-Level Interconnectが公開されたが、この概念図を見る限りでは2つのダイからなるSN40Lは内部のメッシュを2つのダイで共有しているように見えなくもない。
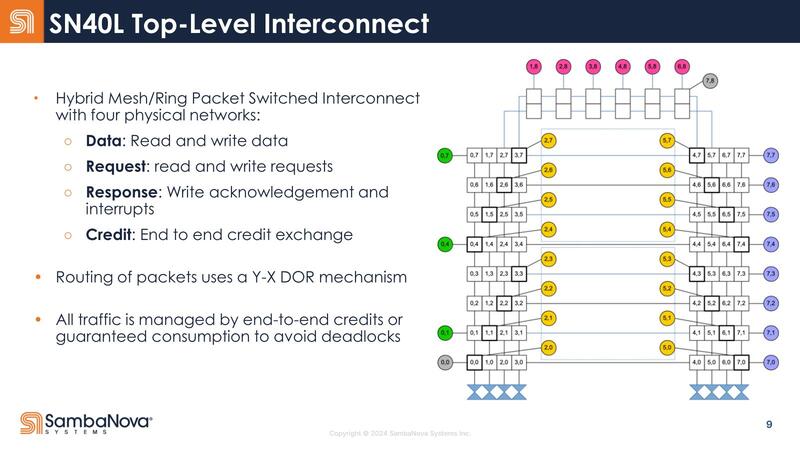
ちょうどSapphire Rapidsが内部のメッシュを隣接するタイルまでEMIB経由で延長して、4タイルで1つの巨大なメッシュを構成していたが、SN40もそんな形に2つのダイにまたがる形で1つの仮想的なメッシュ/リングネットワークを構成しているようだ。
下の画像はSambaNovaが今年5月に出した"SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts"という論文に記載されていた図であるが、RDUタイル同士をつなぐ縦方向のメッシュはそのままDie-to-Die I/F経由で隣接ダイにつながり、一方横方向のメッシュはTLN(Top Level Network)経由でやはりDie-to-Dieでつながる格好に見える。
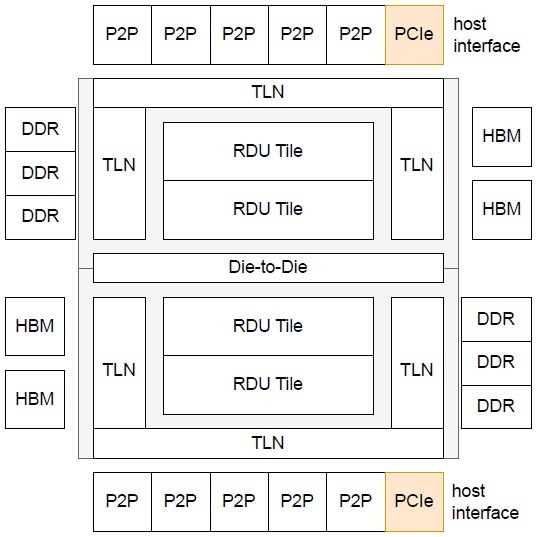
余談になるが、2つ上の画像にあるTop-Level Interconnectの概念図でP2Pと記載されている部分はおそらくイーサネットである。SN10世代ではSN10を2つ搭載するシャーシから、16本のQSFP28ポートが出ており、ここに100Gイーサネットをつなぐ構成になっている。
つまりSN10が1個あたり、100GbE×8である。これがSN30になるとQSFP56×18になっており、SN30が1つあたり200GbE×9という構成である。ここから考えるとSN40Lでは、400GbE×10が出るという感じになるのではないかと想像される。
SN40LはLLNに全振りしたAIプロセッサー
ところでSambaNovaではSN30とSN40Lの性能比を示していない。性能とはパラメーター数4050億個のLlama 3.1で114トークン/秒の処理性能が出せることが大きくアピールされており、競合との比較はViT(Vision Transformer)の結果が示されている、SN30との比較は一切ない。

これはある意味当然で、SN40は言わばSN30をさらにLLM向けに最適化したといった感じの構造になっているからだ。そもそもなぜLlama 3.1 405Bを大々的にアピールするかと言えば、現在リリースされているHBMベースのAIプロセッサーやGPUでは、メモリーに収まらずに扱いきれないほど巨大なモデルだからである。
ところがSN40の場合、HBMとは別に1.5TBのDDR5を用意できるので、こうした巨大なモデルであっても問題なく動作する。ピーク性能で言えばおそらくSN30の方が上で、小規模なモデルであれば多分性能差が付かないし、逆に性能差が付くようなモデルはそもそもSN30だと満足に動作しない可能性すらある。
こうした巨大モデルでは、処理性能そのものよりメモリー帯域の方がむしろ支配的であり、だから演算性能はやや落としつつ3 Tier(SRAM/HBM/DDR5)のメモリー構成を取ることでメモリー帯域を確保して効率を高める、というのがSN40Lの設計方針と考えられる。言ってみればLLNに全振りしたAIプロセッサーに生まれ変わった、というところだろうか。

この記事に関連するニュース
-
iiyama PC、Radeonグラフィックス搭載の『Call of Duty: Black Ops 6』推奨ゲーミングPC
マイナビニュース / 2024年11月26日 13時20分
-
世界最速に躍り出たスパコンEl Capitanはどうやって性能を改善したのか? 周波数は変えずにあるものを落とす
ASCII.jp / 2024年11月25日 12時0分
-
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分
-
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月11日 12時0分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
ランキング
-
1ECナビカードプラス、2025年3月で年間利用ボーナスポイントを終了
ポイ探ニュース / 2024年11月28日 11時26分
-
2そうはならんやろ! “炎の絵”を芸術的に描いたら…… “おきて破り”の衝撃ラストが1000万再生超え「泣いちゃいそう!」
ねとらぼ / 2024年11月28日 8時0分
-
3どうする? 大学生用パソコンの選び方 「4年通しよりも2年で買い替え」がオススメな理由
ITmedia NEWS / 2024年11月28日 13時26分
-
4Dynabook、セルフ交換バッテリー機構を搭載した14型ノートPC「X74」
マイナビニュース / 2024年11月28日 11時3分
-
510000mAh前後の「大容量コンセントプラグ付きモバイルバッテリー」おすすめ4選 USBケーブル内蔵の3in1モデルも【2024年11月版】
Fav-Log by ITmedia / 2024年11月28日 6時25分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





