

5nmの限界に早くもたどり着いてしまったWSE-3 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年10月14日 12時0分

Hot Chips第6弾は、CerebrasのWSE-3を取り上げる。Cerebrasは連載572回で紹介したが、Celebrasは2019年のHotChips 31でWSEを発表して以来、HotChipsの常連となって毎年のようになにか発表している。
もちろんIBMやインテル/AMDのように毎年多数のチップを発表しているメーカーならこれは珍しくないのだが、WSEシリーズしかないメーカーでこういうのは珍しい(単に発表の場をスポンサー枠で購入しているだけ、というのは口の悪い言い方かもしれないが)。
ちなみに同社は2018年にTraining Session 3(Accelerating Training in the Cloud)も実施しており、これまで入れると7年連続での登場になる。
85万コアを有するウエハースケール計算エンジンWSE-2
HotChips 32から今年のHot Chips 2024までの間の発表を簡単にまとめると、まず2020年のHotChips 32は"Software Co-design for the First Wafer-Scale Processor (and Beyond)"と題して、初代WSEことWSE-1上でどうソフトウェアが動作するのか、あるいは逆にソフトウェアでどうWSE-1の上の動作を制御できるのかの説明があった。詳細は割愛するが、この講演の最後で第2世代製品に関するプレビューが示された。

翌2021年のHotChips 33ではWSE-2ことWSE-2が発表された。チップの面積そのものはWSE-1と同じく46,225mm2であり、一方でトランジスタ数やコアだけでなく、オンチップメモリーは18GB→40GB、メモリー帯域は9PB/秒→20PB/秒といずれも2.2倍ほどに膨れ上がっている。要するにプロセスをTSMC 16FFからTSMC N7に変更しただけで、これだけのコアやメモリー容量向上が実現した格好だ。

WSE-1からWSE-2の変更はこれだけでなく、新たにSwarmXおよびMemoryXという名称のシステムが提供開始され、これで最大192台のWSE-2でクラスターを構築可能になったとしている。

このクラスターの目的は、大規模ネットワークへの対応である。オンチップメモリーで40GBというのはある意味驚異的ではあるのだが(なにせこれは全部SRAMである)、絶対的な量という意味では全然足りていない。
そもそもNVIDIAのA100ですら40GB版に加えて80GB版をリリース。H200は141GB、GB200ではHBMだけで384GBを搭載する。AMDもInstinct MI300Xで192GBを搭載したが、次のInstinct MI325Xでは288GBに増量することを発表している。LLMの規模がどんどん大きくなることでメモリー不足になるのは明白である。
これはCerebrasも認識しており、そのための対策として提供されたのがチップの外にメモリープールを置き、これをインターコネクトで接続するという上の画像の構成である。

このMemoryXを併用する場合、重みデータはすべてMemoryXに置かれる形になり、アクティベーションのみがWSE-2のSRAMに格納される形になる。またこの重みのアップデートはMemoryX内のプロセッサーで行なうため、WSE-2には負荷をかけずにできるとする。
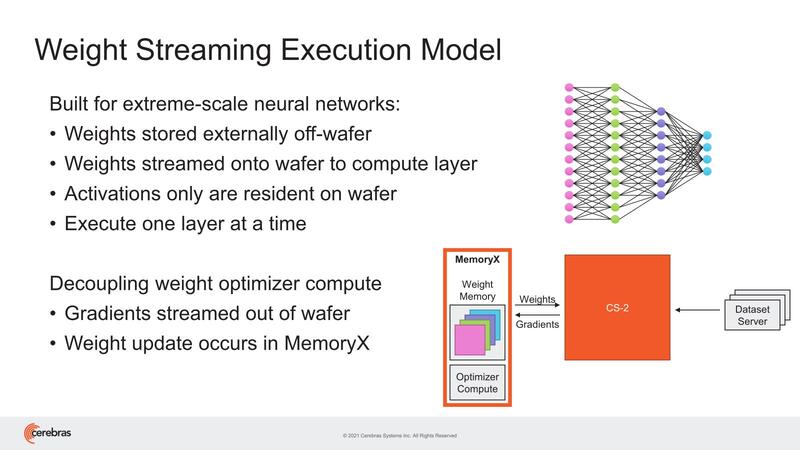
ちなみにこのMemoryXは、2~192台までのWSE-2に対応し、4TB~2.4PBまでのメモリー搭載量であるとしている。

4TBの場合で200B個、2.4PBなら120T個のパラメーターを格納できるとしているほか、内部動作をパイプライン化することでレイテンシーを遮蔽できるとしているが、このあたりの詳細は語られていない。
全体でクラスターをいくつまで論理的に分割できるのかは明示されていない。分割可能であることはわかっているが、その1つの論理的なクラスターに所属するWSE-2は、すべて同じネットワークを動かし、重みも共通して持つ形になる。
2つ上の画像で"Execute one layer at a time"という言い方をしているあたり、ネットワークのある層を複数のWSE-2で分割して処理する形であり、その際にMemoryXはSwarmX経由で、その層の重みを対象のWSE-2にブロードキャストするようだ。
この方式のメリットは、WSE-2の台数にほぼ比例する形で性能がスケールすることだとしている。従来のGPUやAIプロセッサーの場合、結局重みをおのおののローカルメモリーで保持するこになるため、最初にメモリーネックになる。結果、多数のAIプロセッサーやGPUをクラスターにしても、性能が生かしきれない(煩雑にホストとの間で重みのやり取りが発生する)。ところがMemoryX+SwarmXを組み合わせると、この問題が一気に解決するこになる。
もちろんメリットばかりではない。MemoryXを組み合わせると、1層の処理ごとにMemoryXから重みを受信する必要があるので、カード1枚当たりの性能はオンチップSRAMだけを使った場合に比べれば落ちることは避けられない。
もっとも先に書いたようにWSE-2でも40GB「しか」メモリーはないので、大規模LLMを稼働させようとするとホストから煩雑に重みを受け取る必要があり、それよりはMemoryX+SmarmX経由で重みを受け取る方が速い上にスケールする、というわけだ。
WSE-2は事前に処理が必要なGPUと違い 200倍の帯域が利用できて効率が10倍良い
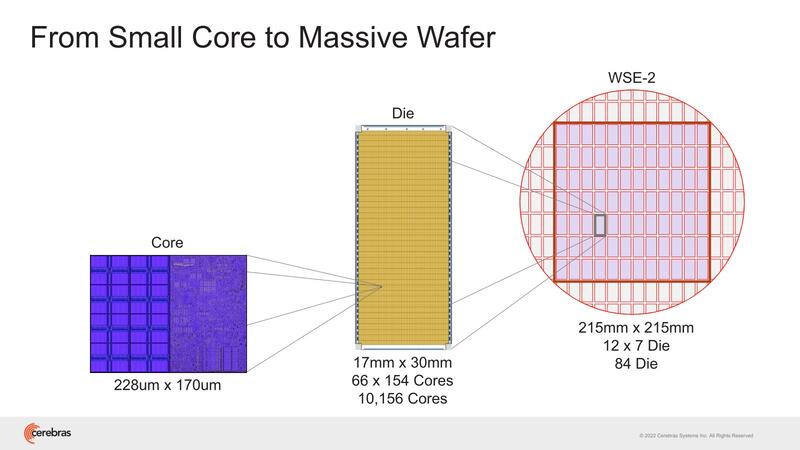
2022年のHotChips 34では"Cerebras Architecture Deep Dive:First Look Inside the HW/SW Co-Design for Deep Learning"と題し、WSE-2の内部構造の説明が行なわれた。そもそもWSE-1の時も非常にラフな構造の説明しかなかった。まずWSE-2では85万個存在する、個々のコア(Cerebras用語ではPE:Processor Element)が下の画像だ。
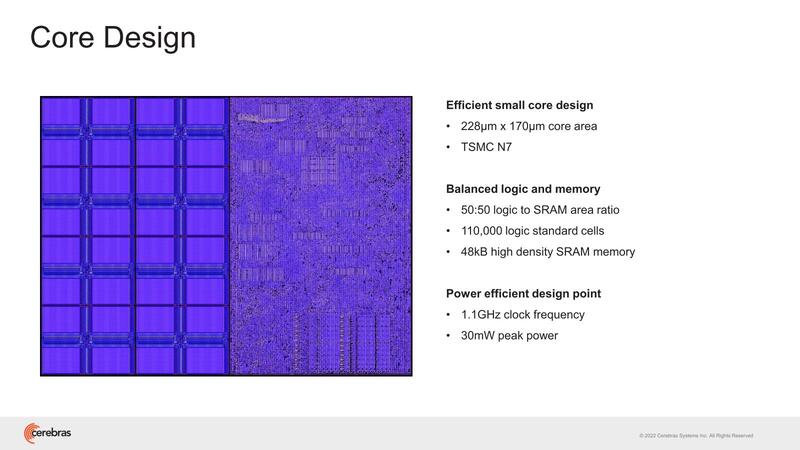
1.1GHz駆動と動作周波数は控えめだが、ピークでも30mWと控えめではある。もっともこれが85万個あるので、本当に全コアがフル稼働するとピークでは25.5KWもの消費電力になる。もっとも前ページのウェハー写真でもわかるように、実際にはこの85万個のPEが84個のダイに分割されており、個々のダイの消費電力は300Wほどになるため、妥当と言えば妥当な数字である。
ここのPEの内部が下の画像で、6ステージのパイプライン構造のインオーダー構造の演算器であるが、FP16を1サイクルで4演算できるようになっている。ここで言う演算はFMAC(Multiply and ACcumulate:積和演算)で、なので見かけ上は1サイクルで8演算になる。
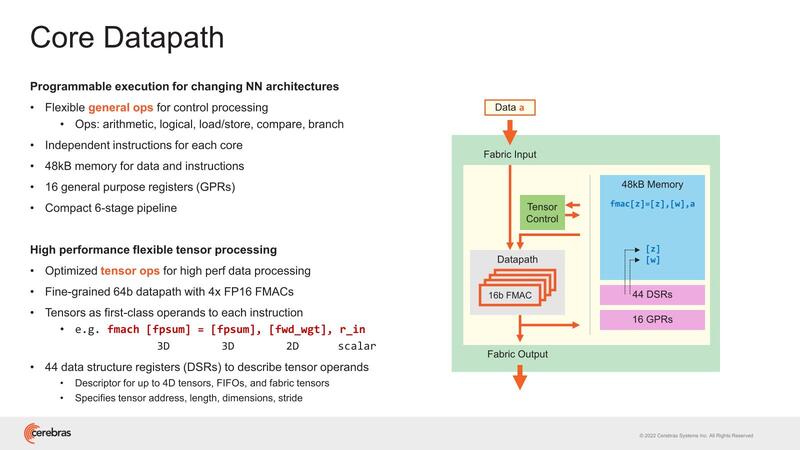
このPEはデータフローの形で動作する、というのは前回の記事でも説明した通りで、なにもしなくてもSparsityを実現できることになる。このあたりが、事前に処理が必要なGPUとの違いであり、結果効率が10倍良いとするのは大げさではあるかもしれないが、嘘ではないだろう。
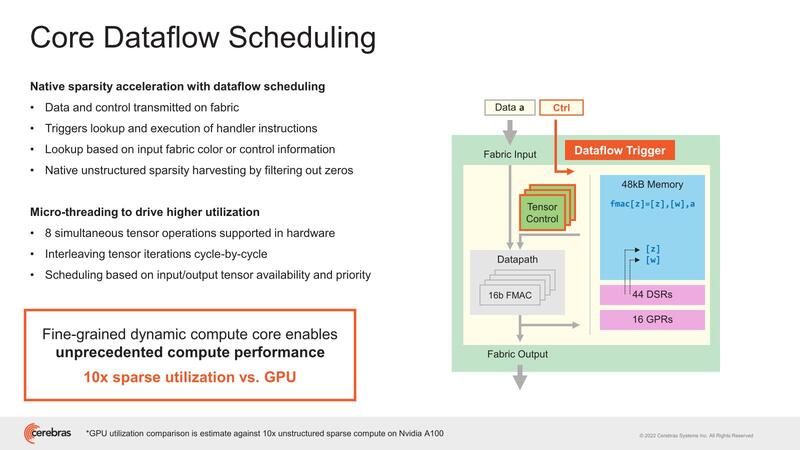
SRAMブロックの構成が下の画像で、6KBのバンク×8が用意され、かつSWキャッシュが256B搭載される仕組みになっている。SWキャッシュがスクラッチパッドなどではなくキャッシュなのは、これは外部から書き込みするだけで、PE自身にはキャッシュを変更できないためと思われる。
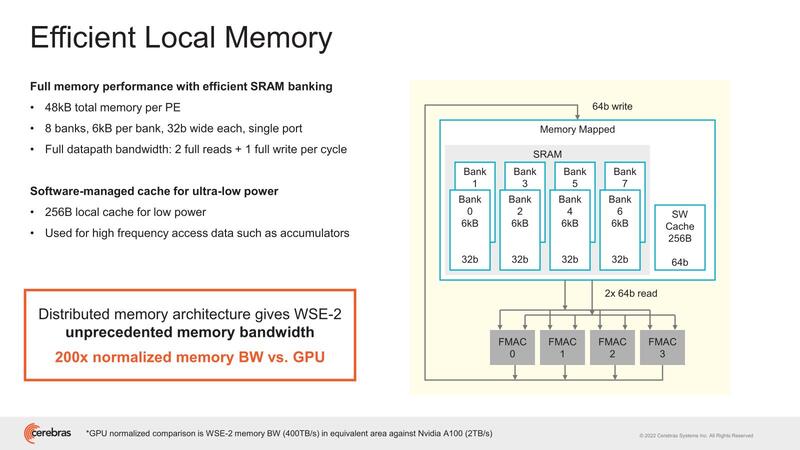
ここの表現を見ると、特にテンソル演算の場合など、同じ処理をずーっと繰り返す、DSP的な動き方になる。PE自身でこれを制御するためには、分岐予測やBTB的なものを用意して、処理が終わったら次のコードに移行するのではなくまた元に戻って繰り返すことをハンドリングする必要があるが、PEにそれを持たせるのは無駄が多いと判断したのだと思われる。
結果的に、DSP的にぶん回すような用途で、GPUと比較して200倍の帯域が利用できるとしているが、この数字が正しいのかどうかは判断がつきかねる。
ちなみにその帯域の話で言えば、処理内容に応じて要求される帯域にはけっこう差があるのは知られた話である。
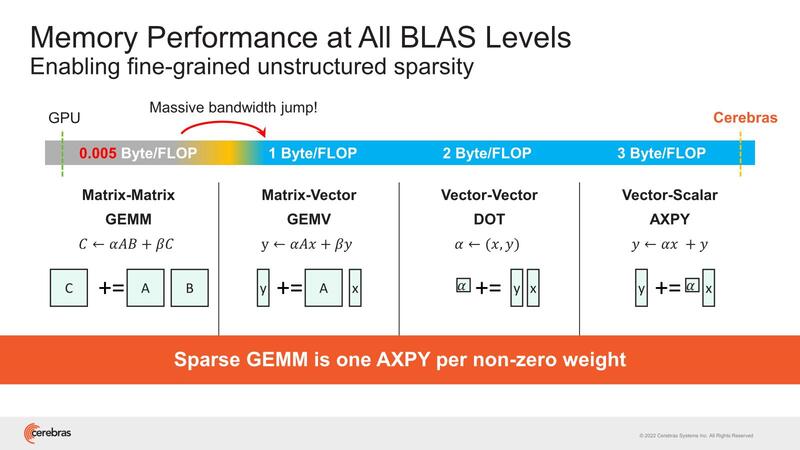
例えばNVIDIAのBlackwellは20PFlops演算性能と8TB/秒のメモリー帯域とされているわけだが、ということは2万TFlopsと8TB/秒だから、演算当たりのメモリー帯域は0.0004Bytes/Flopsという計算になる。
実際には内部の2次キャッシュの帯域はもう少し大きいが、容量は小さいのですぐに使い切ってしまい、結局HBMアクセス待ちになる。これがWSE-2では16bitのFMAC×4に対して、64bit/サイクルの読み込み×2 + 64bit/サイクルの書き込み×1で、3Bytes/Flopsになる計算で、圧倒的に有利としている。
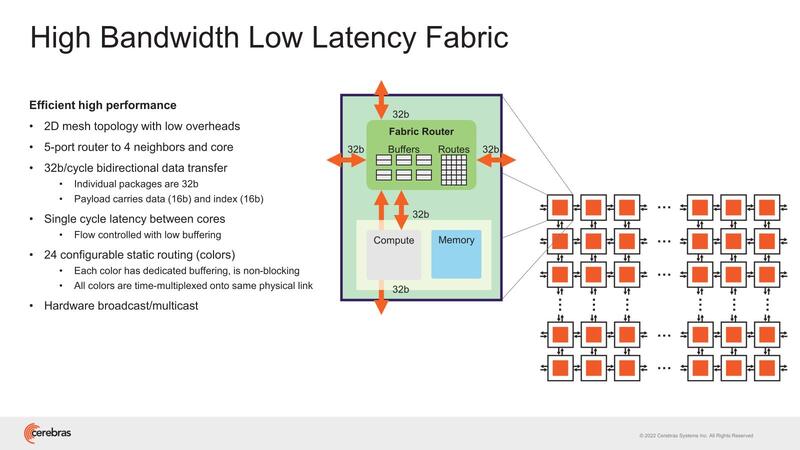
WSE-2ではこのPEを1万156個集積したダイを84個つなぐ形で構成される。おのおののPEの外には5ポートのルーター(うち4ポートは隣接ノードに、1つはPEに接続)が設けられ、これで2次元メッシュを持つ構造だ。バス幅は32bitで、ただしデータは16bit(残りはIndex)なので、PEをまたいでのメモリー参照などはあまり現実的ではない。あくまでPEは自身のSRAMだけを対象に演算すると思われる。
続く2023年のHotChipsでは、クラスターに関する詳細が示された。まずMemoryX、2021年には「2~192台までのWSE-2に対応し、4TB~2.4PBまでのメモリー搭載」と発表されていたが、2023年には多少アップデートされた。
このスペックからすると、どうも1ノードのMemoryXは1Uのシャーシに収まる規模になり、あとは顧客のニーズというか、どの規模のメモリーを必要とするかで最大12台まで接続できるようになっている模様だ(Dedicated interfaces to WSE-2 and *other MemX*とあるあたり、MemoryX同士での相互接続も可能になっているようだ)。
下の画像はCerebrasが提供するAndromedaという1 Exaflopsのシステムの写真だが、左から9ラック目に12本装着されているのがMemoryXではないかと思われる。

ちなみにこのシステムは他にEPYC Gen3を合計1万8176コア搭載しており、左から1~8および9・10・12ラックに収められた1Uシャーシ(合計132枚)と、11・14~16ラック目の2Uシャーシ(合計12枚)には、全部64コアの2ソケットEPYCが搭載されているものと考えられる。
同様にSwarmXもシャーシが複数必要である。4×WSE-2で12ノードだから単純計算すればWSE-2 1つあたり3ノードのSwarmXが必要になる計算だが、これはノード数が増えるほど大規模になる。
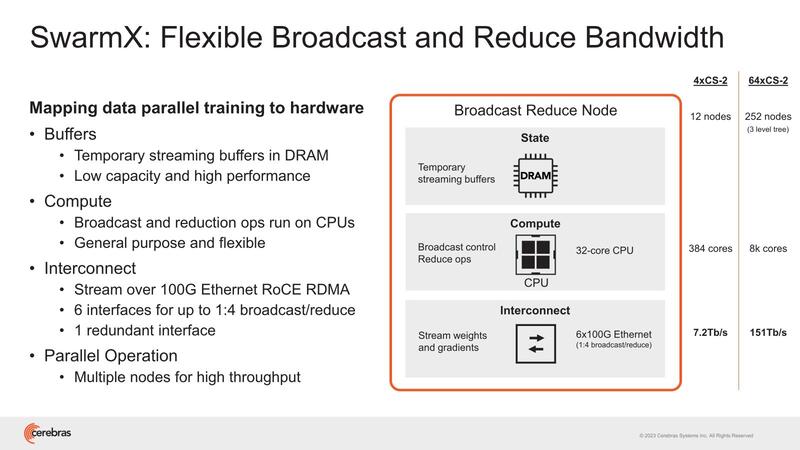
WSE-2が64ノードだと3 level tree(おそらくFat Treeを構成するのだろう)が必要で、合計252ノードなどになるのは少し多すぎる。独自のプロトコルを実装している関係で、既存のスイッチが使えない結果がこの有様で、このあたりは今後スイッチベンダーと協業して、もっと大規模かつ高速なスイッチになるかもしれない。
128bit SIMDに変更されたWSE-3 DGX-H100と比較しても5倍以上高速
やっと2024年のHotChipsでの発表に移る。今回Cerebrasは第3世代のWSE-3を発表した。ただTSMC N7→N5ではあまり微細化の効果が得られていない。トランジスタ数こそ2.6兆個→4兆個で、倍増とは言わないまでも54%程増えているが、PEの数は85万個→90万個で5.8%増。搭載メモリー量は40GB→44GBだから10%増と、ほんのわずかでしかない。

なぜPEの増加量とメモリーの増加量が一致していないかは後で説明するとして、7nm→5nmではロジックは微細化の恩恵を多少は受けるが、SRAMの微細化はほとんどない、という実例のような結果になってしまった。もちろんそれでも動作速度向上(あるいは同じ動作周波数で消費電力削減)の効果は見込めるため、意味がないわけではないのだが。
さてWSE-3では、PUの内部が大幅に変更になった。WSE-2までは16bit FMAC×4の構成だったのが、WSE-3では128bit SIMDに変更され、また8bitでは16個のデータを同時に処理できるようになった。演算性能だけで言えば、16bitで従来の2倍、8bitなら4倍になる計算である。
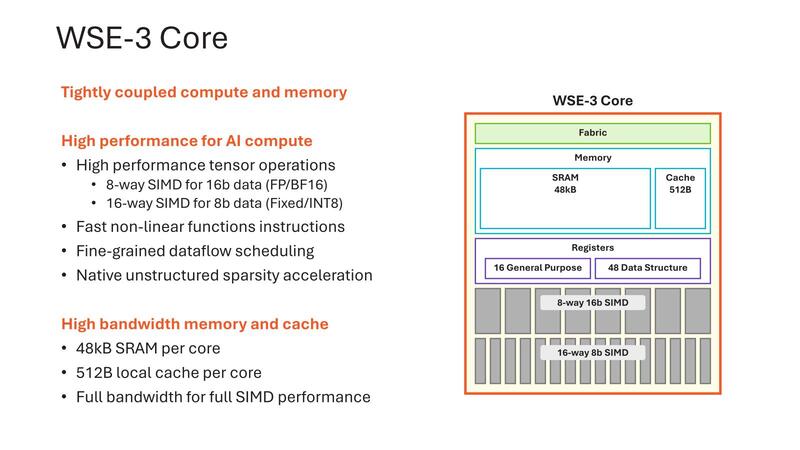
ただ、演算性能が2倍なり4倍になったりするのであれば、それに合わせてメッシュネットワークの高速化もしないと追い付かない気もするのだが、それに関する説明は今回なかった。変更がないのか、変更はあるけどまだ未公開なのかは不明である。
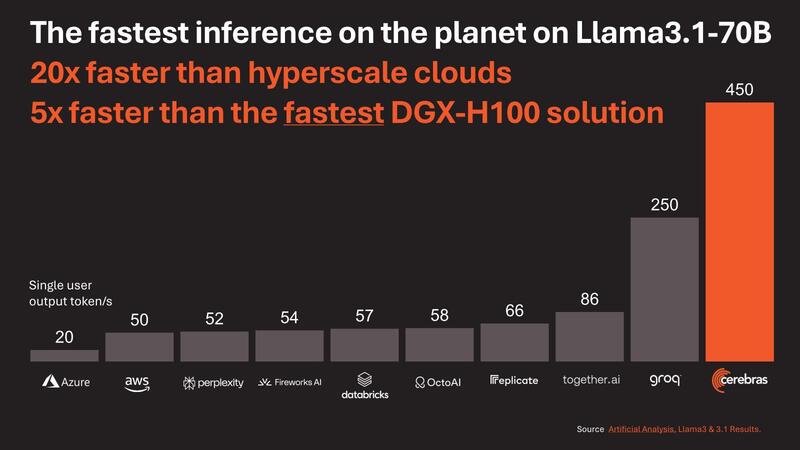
性能という意味で示されたのが下の画像である。Llama 3.1-70Bの推論が、Cloudベースのソリューションは元より、DGX-H100と比較しても5倍以上高速としている。
ちなみにこの理由に関してのCerebrasの説明が下の画像だ。要するにHBMの帯域がネックになっているから、ということだ。
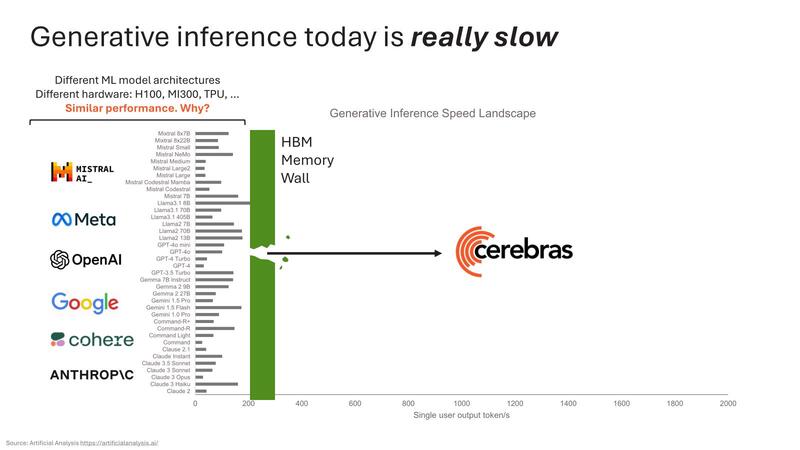
そうなると、WSE-3とH100を比較するとメモリー帯域は7000倍と言っているわりに性能は5倍にしかならないのか? という疑問が出てくるわけだが、これは実際には大規模ネットワークを稼働させると煩雑にMemoryXから重みを読み出す必要がある。層ごとにこの読み出しが入るわけで、これがボトルネックになっているものと思われる。
それにしてもWSE-3はもう5nmの限界にたどり着いてしまった感がある。これ、このまま3nmに持っていっても性能が大して上がらずにコストだけが跳ね上がりそうだ。WSEの欠点は少ないメモリー量で、これを補うためには次世代ではロジックウェハーの下にSRAMウェハーを3D接続するなどしてローカルのSRAM量を増やすとともに、SwarmX/MemoryXとの帯域を大幅に引き上げる必要がある。
ただ現状でもSwarmXが明らかに能力不足の感がある。これをスイッチメーカーと協業するなどして改善できれば、もう少し性能の伸びが期待できそうではある。

この記事に関連するニュース
-
AI向けシステムの課題は電力とメモリーの膨大な消費量 IEDM 2024レポート
ASCII.jp / 2024年12月30日 12時0分
-
NVIDIA、AIコンピュータ「Jetson Orin」にSuperモード追加、Nano開発者キット半額に
マイナビニュース / 2024年12月18日 15時31分
-
NVIDIA、前モデル比70%性能向上なのにほぼ半額になった「NVIDIA Jetson Orin Nano Super」発表
マイナビニュース / 2024年12月18日 13時54分
-
“GeForce RTX 4060以上”って本当? 新型GPU「Intel Arc B580」は想像以上に優秀な良コスパGPUだった!
ITmedia PC USER / 2024年12月12日 23時5分
-
M4 Maxチップ搭載「16インチMacBook Pro」の実力をチェック 誰に勧めるべきモデルなのか?
ITmedia PC USER / 2024年12月6日 12時35分
ランキング
-
1アップル初売り、1月2日スタート! ギフトカード対象のApple Watch Series 10が人気
マイナビニュース / 2025年1月2日 22時0分
-
2『ポケモン』『メトロイド』最新作も!“2025年のスイッチ独占タイトル”を見逃すな─待望の再誕や名コンビの復活も
インサイド / 2025年1月2日 17時0分
-
3『グラブル リリンク』や『CC FFVII -リユニオン-』も!約2,000円以下のゲオ店舗セールソフトをチェック─「3本購入で半額」の1,480円以下もまとめて紹介
インサイド / 2025年1月2日 22時30分
-
4【ハードオフ】2750円のジャンク品を持ち帰ったら…… まさかの展開に驚がく「これがジャンクの醍醐味のひとつ」
ねとらぼ / 2025年1月2日 11時0分
-
5100均のカードスタンドの“じゃない使い方”に反響 推し活に最適なアイデアに「凄すぎるぞ」「めっちゃいいなこれ」
ねとらぼ / 2024年12月30日 20時10分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください






