

10月25日登場のArrow Lake、強みはどこ?アーキテクチャーのポイントをおさらい
ASCII.jp / 2024年10月11日 0時0分

“Arrow Lake”こと「Core Ultra 200Sシリーズ」の アーキテクチャーに迫る
2024年10月25日0時(日本時間)、インテルは新デスクトップPC向けCPU「Core Ultra 200Sシリーズ」の販売を解禁する。具体的な予想価格については速報記事(https://ascii.jp/elem/000/004/227/4227230/)をご覧いただきたいが、最上位かつ流通量が少量と推測される「Core Ultra 9 285K」を除けば、前世代の同格モデルの初値とほぼ変わらぬ価格設定になっている。

Core Ultra 200Sシリーズのアーキテクチャーは、系譜で言えばモバイル向けの最新設計である「Lunar Lake」をベースにした「Arrow Lake-S」が採用されている。
Lunar Lakeと完全に同一にしなかった(できなかった)理由は、Arrow Lakeはエンスージアスト向けの製品であり、Lunar LakeにはないPCI Express Gen 5対応が盛り込まれているからである。ちなみにLunar Lakeは薄型軽量ノートPC向けのCPUであるが、パフォーマンス志向の「Arrow Lake-HX」および「Arrow Lake-Hを採用したノートPCも2025年Q1より発売される。



プロセスの“Grab Bag”
Arrow Lakeは、同社のデスクトップPC向けCPUとしては初めて“タイルデザイン”を採用したCPUとなる。これまでのデスクトップ(かつメインストリーム)PC向けCPUはほぼ全てが14nmやIntel 7(10nm)というような単一のプロセスルールで製造されたモノリシックダイを採用してきた。
だがMeteor Lakeからは、異なるプロセスルールで製造された回路(タイル)を組み合わせるというタイルデザインを採用することで、製品展開をより柔軟にする手法が採用された。Arrow LakeもCPUコアを格納する“コンピュートタイル”、内蔵GPUの“GPUタイル”、メモリーコントローラー等を擁する“SoCタイル”、さらにPCI ExpressやThunderboltコントローラー等を格納する“I/Oタイル”で構成される。
このうち、コンピュートタイルはTSMC「N3B」プロセス、GPUタイルはTSMC「N5P」プロセス、SoCおよびI/OタイルはTSMC「N6」プロセスと、それぞれバラバラのプロセスルールで製造されている。
これらをインテルの「1227.1」プロセスで製造されたベースタイルの上に載せ、Foverosで配線することで1基のCPUに仕上げているのである。インテルはこの構造を“Grab Bag”と称した。わかりやすい日本語で言うならば“プロセスのごった煮”といったところか。



SMTを廃止し、ワットパフォーマンスに強く振ったPコア&Eコア
まずはコンピュートタイルの中身から見ていこう。第12世代(Alder Lake-S)以降、インテルはPコアとEコアで構成されるハイブリッドデザインを採用しているが、Arrow Lake-SではPコアにLion Cove、EコアにSkymontと呼ばれるコアが採用されている(HXも同じ。以下HXに関しては省略)。
特に重要なのはPコアのSMT(Hyper-Threading)が廃止されたことだ。1コアで2スレッド分の処理ができるということでPentium 4以降のCPUの標準装備となってきたが、今のインテル製CPUデザインだとSMTを実装するために必要なトランジスタ数も必要になり、性能の向上分に比して消費電力の増大が割に合わなくなってしまった。
さらにThread Directorでコアの利用を最適化しはじめると、CGレンダリングや動画エンコードでもない限りPコアの論理コア側は遊んだままになる事も珍しくない(=SMTを実装するだけ無駄)。つまりインテルの今のCPU運用スタイルではSMTはデメリットの方が大きく、Lunar LakeでCPUデザインを大きく変える機会に思い切って切り捨てたといったところだ。
SMT廃止はマルチスレッド性能的にはインパクトの大きい改変だが、Lion Coveでは命令実行に関わる部分の機能が強化され、より処理効率を上げる方向に舵を切っている。



EコアはPコア以上にエリアあたりの電力効率に特化した設計であるのは今まで通りだが、従来(文脈的にLunar Lakeは除外する)のEコアよりもベクトル演算が大幅に強化されている。
Arrow Lake-Sには内蔵GPUもあるし、何ならNPU(後述)もあるのでベクトル演算はそっちに振れば良いと思ってしまうが、処理によってはCPUで実行したほうが良い場合もある(NPU用にプログラムを改変する余裕がない、等の理由も含まれる)。あらゆる処理の中にAIが組み込まれる時代を見据えると、Eコアもきちんと戦力として組み込めるようにしておこう、というのがベクトル演算強化の理由だ。



PコアとEコアの使い分けは、これまで通りThread DirectorがOSのスケジューラーに対し割り当てるコアをサジェストする形で実行される。
Alder~Raptor Lake-Sまでの時代のThread Directorはバックグラウンド処理はEコアに、計算負荷の高い処理はPコアにといった比較的シンプルな使いわけだったのに対し、Lunar LakeやArrow Lake-Sでは、まずEコアに処理を振り、パワーが必要と判断されたらPコアに移すというより動的な運用のほか、特定の処理はEコアから出さないようにしてPコアを空けるという運用も可能になった。
また、最適な割り振り先を判断する機構に関しても新たに予測モデルを搭載するなど、よりアグレッシブに運用する方針になっている。


コンピュートタイルを離れる前に、オーバークロック(OC)に関する情報もまとめておこう。まずArrow Lake-SにおけるOCに必要な要素は変わっていない。即ちK付きのCPUとZ付きチップセット(つまりZ890)が必須だ。だがArrow Lake-Sでは以下の点に注意したい。
・倍率1binで変わるクロックは16.67MHzに細分化(従来は100MHz) ・ベースクロックはコンピュートタイルとその他で異なる値が使用される ・タイル間接続のクロックは固定もしくはベースクロックに対する倍率として設定可能
特に重要なのは最初の倍率1binあたりのクロック変動量の変更だろう。従来よりも細かい調整が可能になったことで、より限界まで追い込めるようになったと言える。ただ筆者の手元には現物がないので、これらの変更がOCのワークフローにどう影響するかまでは考察することはできない。

GPUタイルはあえてAlchemist(Xe)を選択
続いてGPUタイル(以前はグラフィックスタイルと呼んでいたような気がするが……)の話題だ。Lunar Lakeでは、内蔵GPUに最新の「Battlemage」ことXe2アーキテクチャーを採用したことでグラフィック性能が大きく伸びた。まだXe2世代のディスクリートGPUは存在していないが、今後登場すれば現行のArc Aシリーズ(Alchemist)の上位存在になることは間違いない。
だがArrow Lake-Sの内蔵GPUはXe2アーキテクチャーではなく、Arc Aシリーズと同じXeアーキテクチャーをベースにしたものである。今回発売されたCore Ultra 200Sシリーズがエンスージアスト向け製品であり、ユーザーは何らかのビデオカードと組み合わせて使用することを想定しているなら、費用対効果の面でXe2を使わないというのは合理的な判断だ。




GPUの話はここまでだが、ここでSoCタイルに含まれるNPUの話もしておこう。Eコアの所で触れたように、今のAI実装(学習ではなく推論処理運用が主体のライトユーザー向けのもの)のトレンドはCPU/ GPU/ NPUの使い分けにある。
Arrow Lake-SにもNPUが搭載されているが、Lunar Lakeに搭載された第4世代のNPU(Intel AI Boost)ではなく、Meteor Lakeに搭載された第3世代のNPUが実装されている。第4世代のNPUが48TOPSなのに対し第3世代のNPUは13TOPSと寂しいばかりだが、Arrow Lake-SのNPUは画像生成やLLMのような重い処理ではなく、Webカメラの映像で顔を認識するような、ちょっとした処理においてCPUやGPUの手を煩わせたくない時に使うデバイスといった印象だ。



最後にCore Ultra 200SシリーズのAI性能に関してのパフォーマンスデータを紹介しておこう。現時点における実アプリの実装では、大抵の場合CPUコアを利用してAI処理が実行され、次に多いのがGPU、NPUを利用してくれるのはかなりレアだ。
ただ「Geekbench」や「UL Procyon」で同じ条件の下パフォーマンスを比較することはできる。CPUコアだけで処理する場合、Core Ultra 9 285KとCore i9-14900Kの性能はかなり近い(INT8演算を利用した場合)が、内蔵GPUを利用する場合はCore Ultra 285KならCore i9-14900Kの2倍程度のパフォーマンスを期待できるという。
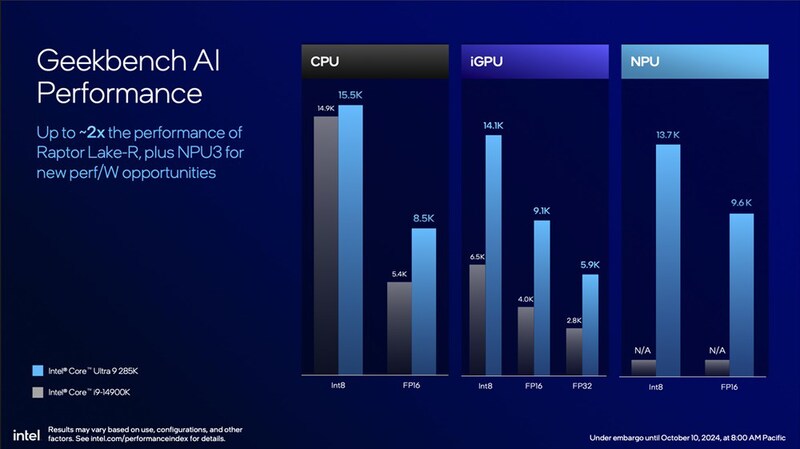


以上でCore Ultra 200Sシリーズのアーキテクチャーやパフォーマンスに関するまとめは終了だ。全体として、インテルはパワーを限界まで使って性能を出すという手段が封じられたため、アピールに苦労している感が強かった。TDPを絞った状態での比較資料を見るのは別に今回が初めてではないが、今回見たデータがどこまで現実で通用するか筆者には見当すらつかない。いつから実際の製品を試せるのか不明だが、ここは25日の販売解禁を楽しみに待つとしよう。


この記事に関連するニュース
-
Core Ultra 7 265K&RTX 4070 Ti SUPER搭載ゲーミングPC、空冷クーラーでも本当に大丈夫?
ASCII.jp / 2024年11月16日 10時0分
-
Lunar LakeはMeteor Lake比でどこまで性能向上? 最新ドライバ適用「Core Ultra 7 258V」搭載ノートを試す(後編)
マイナビニュース / 2024年11月14日 15時0分
-
Lunar Lake搭載で約946g! 超軽量ビジネスPCとして格が上がった新型「MousePro G4」を試す
ITmedia PC USER / 2024年11月6日 15時0分
-
メインマシンにも使える! 1kgアンダーで最新「Core Ultra 7」搭載の14型モバイルノートをレビュー!
ASCII.jp / 2024年11月6日 12時0分
-
今週の秋葉原情報 - 時代は「Core i」から「Core Ultra」へ、新世代CPU「Arrow Lake」が発売に
マイナビニュース / 2024年10月31日 18時5分
ランキング
-
1携帯ショップで働きたい人が減っている――現役店員が語る“理由”とは?
ITmedia Mobile / 2024年11月27日 17時5分
-
210000mAh前後の「大容量コンセントプラグ付きモバイルバッテリー」おすすめ4選 USBケーブル内蔵の3in1モデルも【2024年11月版】
Fav-Log by ITmedia / 2024年11月28日 6時25分
-
3そうはならんやろ! “炎の絵”を芸術的に描いたら…… “おきて破り”の衝撃ラストが1000万再生超え「泣いちゃいそう!」
ねとらぼ / 2024年11月28日 8時0分
-
4「Windows 11 2024 Update(バージョン24H2)」の既知の不具合まとめ【2024年11月27日現在】
ITmedia PC USER / 2024年11月27日 17時50分
-
5「声出して笑ったwww」 お母さんからLINE → 思わず目が覚める“衝撃のメッセージ”が590万表示 「戦況報告すぎる」
ねとらぼ / 2024年11月28日 7時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





