

AI性能を引き上げるInstinct MI325XとPensando Salina 400/Pollara 400がサーバーにインパクトをもたらす AMD CPUロードマップ
ASCII.jp / 2024年10月28日 13時0分

前回に引き続きAMDのAdvancing AI 2024イベントの詳細であるが、まずは前回宿題にした質問の返答が返ってきたのでお伝えしよう。
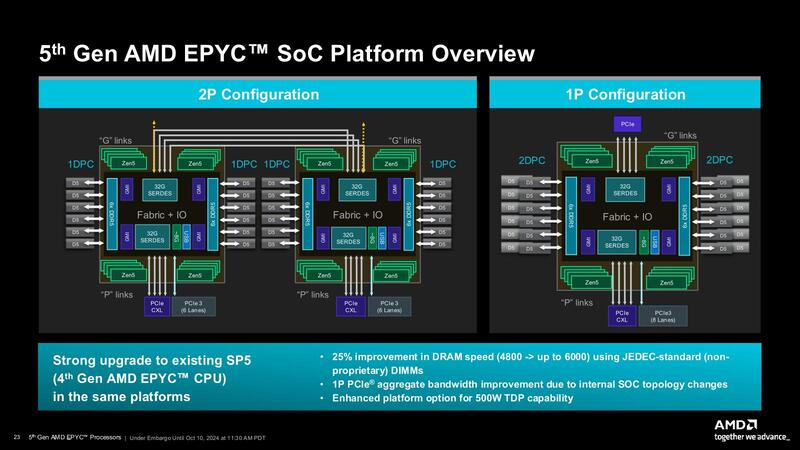
第5世代EPYCのMRDIMM対応はJEDEC次第との返答 Zen 5cはGMI3-Wideの接続をサポートしていた
MRDIMMのサポートについてだが、返答は「MRDIMMは、本質的にはインテルが市場で使用したマーケティング名です。MRDIMMは独自のテクノロジーであるため、現在サポートされていないのは正しいことです。JEDECが技術の標準化を決定した場合は、その時点で決断します。ただし、ご存知のとおり、当社にはデータセンターのエコシステム全体でオープンな標準ベースのテクノロジーをサポートしてきた長い歴史があります」だそうだ。もっともこれには事実誤認(あえて知らないふりをしてると言うべきか)があり、インテルが提唱しているのはMCRDIMMである。
そして連載723回でも触れたが、MRDIMMはもともとHB-DIMMという名前でAMDが開発を始め、これがMRDIMMに改称されたという経緯があるし、そのMRDIMMをJEDECに標準規格化する提案をしているメンバーにはAMDも当然含まれている。
したがって「本質的にはマーケティング名」という返事は間違ってこそいないものの正確ではないと思うのだが、それはさておき。AMDによればJEDECがMRDIMMの標準化を完了したら「決断する」としているあたりは、おそらく準備はできていそうだ。ただそれを公式にサポートするのは標準化完了後になるだろう。水面下ではベンダーを巻き込んでの事前Validation/Certification(検証/認証)は行なっていそうだが。
メモリーについてはもう1つ、1 DIMM/chであればDDR5-6000まで可能だが、2 DIMM/chだとDDR4-4400に落ちるのでは? と確認したところ、その通りとの話であった。また、Zen 5cのCCDでGMI Wideを利用可能かどうか判断つかなかったのだが、返答によれば「CCDの種類は問いません。パッケージ上のCCDが8つ以下である限り、GMI Wideを使用できます」とのことで、Zen 5cのCCDもGMI Wideをサポートできることになる。
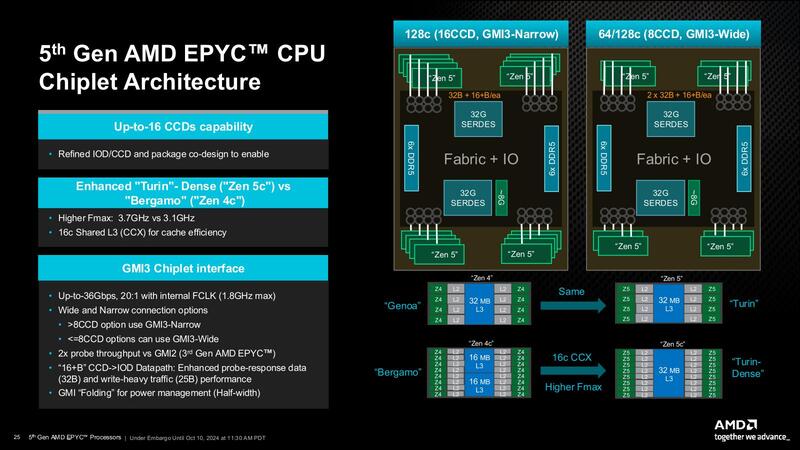
ということでZen 5cベースの製品のうち、EPYC 9965(192core/12CCD)/EPYC 9845(160core/10CCD)/EPYC 9825(144core/12CCD)の3製品はいずれもGMI Narrowでの接続であるが、8CCD以下となるEPYC 9745(128core/8CCD)およびEPYC 9645(96core/8CCD)の2製品はGMI Wideでの接続になるわけだ。
カタログ性能はあまりMI300Xと差がないが、実際の性能は期待できそうな AIアクセラレーターInstinct MI325X
さて今週の最初の話はInstinct MI325Xとその後継製品の話である。まずInstinct MI325Xについて。6月のCOMPUTEXの際にアナウンスはされていたInstinct MI325Xが、今回正式に発表になった。

Instinct MI300Xとの最大の違いはメモリー容量で、Instinct MI300Xが192GB、つまりHBM 1スタックあたり24GBだったのに対し、Instinct MI325Xでは256GB、つまり1スタックあたり32GBに強化されている。おそらくInstinct MI300Xの時は、3GBのDRAMダイを8Hiで積層したのに対し、MI325Xでは4GBのDRAMダイを8Hiで積層したものに変更したのだと思われる。
またHBM3の速度も、MI300Xが5.3TB/秒(*1)、つまりHBM3Eの信号速度は5.18Gbpsほどに抑えられていたが、MI325Xでは6TB/秒になっており、5.86Gbpsほどに引き上げられている。連載749回でもこの話には少し触れたが、まだ6.4Gbpsを達成できるHBM3Eのスタックの入手は難しいようだ。それでもだいぶ6Gbpsに近づいた感はある。
(*1) AMDのプレゼンテーションでは5.2TB/秒になっているが、Instinct MI300Xのホワイトペーパーでは5.3TB/秒になっているので、ここではホワイトペーパーの数字を採用した。
さて一方XCDの方であるが、スペックはまったくMI300Xと変化がない。有効CU(XCU)数は304(つまりXCD 1つあたり38個)なのに変化はないし、動作周波数も2.1GHzのまま据え置きになっている。上の画像で示されたピーク性能もMI300Xと違いがない。にもかかわらずMaximum TBPはMI300Xが750Wだったのに、MI325Xでは1000Wに増えている。
HBM3の転送速度が5.18Gbps→5.86Gbpsまで引きあがったから当然この分で多少のTBP増加は発生するが、さすがにこれで250Wも上るわけがない。これはメモリー帯域の向上にともない、若干ながら実効動作周波数も引き上げられることになったものと考えられる。
そもそも2.1GHzという動作周波数はピークで、実際には温度や消費電力の範囲内で動作周波数を動的に変化させながら稼動させることになるが、この消費電力の範囲を少し緩めた、ということかと思う。変な言い方だが、NVIDIAのBlackwellが1000Wの定格で製品を発表し、これに向けてSuperMicroその他のサーバーベンダーが、この1000W向けの液冷ソリューションを提供し始めている。
こうしたベンダーは当然AMD向けにも同じソリューションを提供するわけで、BlackwellのおかげでモジュールのTBPに1000Wが許容範囲となったので、これにあわせて上限を1000Wまで広げた、というあたりが正しいところだろう。AMDの提供するInstinct MI325Xの写真は空冷ソリューションになっているが、実際には1000Wを使い切ろうと思ったら液冷ソリューションが必須になりそうだ。

ちなみに現時点ではピーク性能ベースの数字しか示されておらず、また実際のベンチマーク結果などもNVIDIAのH200との比較しかないので、これでどの程度性能が上がったのか、は不明である(10%もあがったりはしないと思われる。せいぜいが数%のオーダーだろう)。
むしろ最近は、モデルの規模が大きくなり、パラメーター数が億を超えて兆の単位に膨れ上がり始めた。こうした状況ではオンチップメモリーの容量そのものが性能のボトルネックになりやすいわけで、大規模LLMではGPUがどの程度の利用率なのかという数字を見てみたいものだが、実際にどうかというのはわからない。
1つの目安として、Weights & Biasesの"Monitor & Improve GPU Usage for Model Training"という記事によれば、GPUの利用率が15%未満のケースが全体の30%超えであり、半数は45%以下。90%超えのケースは10%に満たないそうだ。
こんな状況では演算側の性能を引き上げても(カタログ性能はともかく)実際のアプリケーション性能にはほぼつながらないわけで、むしろボトルネックになるメモリーアクセスの帯域や容量を引き上げる方がはるかに性能の底上げに効果的というのは理解しやすい。その意味では、カタログ性能はあまりMI300Xと差がないが、実際のアプリケーション性能はそこそこに改善されることが期待できそうである。
「そこそこ」というのは、帯域の向上率が13%程度(5.18Gbps→5.86Gbps)に留まるからで、良くてこの帯域の向上率程度だろうか。あと、パラメーター数が兆を超え、MI300Xでも収まらないような規模のものでもMI325Xでは収まる場合は考えられるから、こうしたケースでは効果的であろう。
8ch構成か12ch構成かの判断が難しい 後継機種のInstinct MI335X
説明ではさらに次の製品であるInstinct MI350シリーズへの言及もあった。具体的な製品名はInstinct MI335Xになり、スペックとしてFP8/FP16ではそれぞれMI325Xの1.8倍の演算性能、そして新たにFP4/FP6をサポートし、こちらでは9.2PFlopsに達するとの説明があった。

この9.2PFlopsというのは、Blackwellの20PFlopsの半分という見方もできるのだが、Blackwellも実は2ダイで20PFlopsであり、1ダイだと10PFlopsでしかない。あとBlackwellの方は、例えばGB200 NVL2では1本のシャーシにGB200が2つで40PFlopsがピーク性能ということになるが、もしMI355xが現在のMI325と同じように1つのシャーシに8個搭載可能ならば73.6PFlopsという計算になるわけで、もうそろそろチップ単体の性能というよりもシャーシの構成を考えないとどちらが高速か判断が付かない領域になってきた。
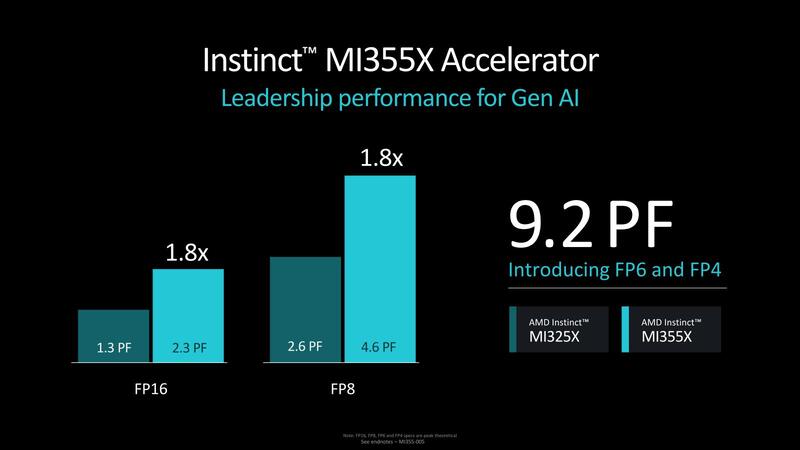
メモリーは288GB HBM3Eで帯域は8TB/秒におよぶ、とする。これまでが8ch構成で、これを1.5倍にするとなると単純に考えれば12ch構成となるわけだが、ということは24GBのHBM3Eを利用する形になり、この際の信号速度は5.46Gbpsとけっこう低めになる。

あるいは32GBスタック×9でも288GBとなるが、こちらだと信号速度7.28Gbpsとなり、HBM3Eがスペック上は9.6Gbpsまでいけるとは言え、市場にこうした高速品がほとんど投入されていないことを考えるとやや難しいのではないかと考える。
可能性としては8chのまま(信号速度は8.19Gbps、スタックあたり36GBのHBM3Eが必要)、10ch(信号速度6.55Gbps、スタックあたり28.8GB)、11ch(信号速度5.957Gbps、スタックあたり26.2GB)あたりが思いつくが、どれも中途半端というか、イマイチしっくりしない。
最初に挙げた12ch構成で信号速度を5.46Gbpsにした構成が一番実現可能性は高いと思うのだが、それならHBM3EでなくHBM3のままで十分なわけで、やはり今ひとつ構成がしっくりこないことに変わりはない。このあたりはもう少し詳細が明らかになったらまたレポートしたい。
このInstinct MI355Xも従来同様OAMで個々のGPUが提供され、これを8つ集積した形でのリリースになる模様だ。提供予定は2025年後半ということなので、おそらくは2025年の今頃であろう。

AIネットワークを最適化するPensando Salina 400と ネットワークカードのPollara 400
もう1つ説明があったのが、新たに投入されるPensando Salina 400/Pollara 400である。このPensandoシリーズはこれまでも軽く流してしまっていたので、説明しておこう。2022年にAMDはPensandoを約19億ドルで買収した。このPensandoの買収により、AMDはIPU(Infrastructure Processing Unit)を手に入れることになった。ちなみにAMDはこれをDPU(Data Processing Unit)と称している。
IPUの話は連載634回でインテルのMount Evansをテーマにして説明しているが、Pensandoの製品はこのIPUの機能に、ついでにイーサネットまで一体化したような構造になっており、これを利用することでEPYCベースのサーバーのネットワークインフラ周りを丸ごとオフロードできるようになった。
PensandoはAMDの買収前にCaprlと呼ばれる第1世代の製品と第2世代のElbaを開発してほぼ完成していたところで、AMDはElbaをベースとした第2世代+に相当するGiglio、それと第3世代のSalinaの開発から加わることになる。といってもAMDはPensandoの開発チームをほぼそのまま残したようで、ほぼPensandoのロードマップ通りに製品が投入されることになった。
AMDはGiglioを"Pensando 2nd Gen Plus DPU"という名称ですでに発売しており、今回発表があったPensando Salina 400は第3世代製品としてロードマップ通りに出荷された形になる。

Salina 400はP4言語(*2)を利用したネットワーク専用プロセッサーで、AMDによれば例えばSalina 400を使うことでネットワーク経由でクラスターを組んでAIの学習処理をする場合のネットワーク待ち時間を平均30%減らせるほか、AI向けネットワークの利用効率を95%以上に高められる、としている。
(*2) 連載634回でも少し触れたが、ネットワーク機器でデータパケットの処理を柔軟に定義するための言語。P4.orgで仕様が策定されている。


さてこの同じPensandoのブランドで投入されたのが、Pollara 400である。こちらは業界初のUEC(Ultra Ethernet Consortium)準拠のイーサネットである。UECはLinux Foundation傘下の団体であり、2013年12月にAMDが開催したAdvancing AIイベントでその結成が発表された。

ちなみにこのUECのステアリングメンバー(運営委員)にはAMDだけでなくインテルも加わっており、ジェネラルメンバー(一般会員)にはNVIDIAも名前を連ねているあたり、別にAMD専用のネットワークというわけではない。
主要な目的は、HPCやAIなどにおける大規模ネットワークの効率化を図るというもので、物理層は既存のイーサネットそのままであるが、その上を独自の高効率なネットワーク・スタックを搭載することで性能を改善しよう、という試みである。実際UECを利用した場合、従来のTCP/IPベースのイーサネットと比較してより高速であるとする。

UEC自体の結成は2013年7月であり、UEC Specification 1.0のリリースは2025年第1四半期を予定しているが、これに先駆けてすでにUEC Readyのイーサネットを市場投入したことの意味は大きい。これまでHPCやAIのネットワークは汎用のイーサネットか、NVIDIAベースのソリューションだとそこにInfiniBandという2択になっていたが、今回のPollara 400の投入で汎用イーサネット/InfiniBand/UECの3択になる。地味ながら大きなインパクトのあるニュースと言えよう。

この記事に関連するニュース
-
Supermicro(スーパーマイクロ)、液冷NVIDIA Blackwell ソリューションを提供
共同通信PRワイヤー / 2024年11月22日 15時8分
-
IBM、AMDとのさらなる協業を発表。AIアクセラレーターの提供を拡大
PR TIMES / 2024年11月21日 16時45分
-
HPE、直接液冷スーパーコンピューティング ソリューションの展開を拡大、同時にサービスプロバイダーおよび大企業向けAIシステム2機種を発表
PR TIMES / 2024年11月19日 17時15分
-
AMD、CXL 3.1/PCIe Gen6/LPDDR5に対応するアダプティブSoC「Versal Premium Series Gen 2」を発表
マイナビニュース / 2024年11月13日 6時45分
-
吉川明日論の半導体放談 第318回 データセンター市場で着々と地盤を強化するAMD
マイナビニュース / 2024年11月6日 7時15分
ランキング
-
1Twitter Japanが社名変更、「X Corp. Japan」に
ITmedia NEWS / 2024年11月24日 15時8分
-
2“熱狂”のファミコン版『ドラクエ3』発売日を、当時の新聞各社はどう報じた?後世まで語り継ぐべき名記事も発掘
インサイド / 2024年11月24日 17時0分
-
3「ドラクエ3」HD-2D版にファミコンで挫折したおっさんマンガ家も夢中! ネットで評価が割れた理由とは?
ITmedia NEWS / 2024年11月24日 12時20分
-
4Minisforumが「ブラックフライデー」を開催! 新商品も最大41%お得に買える
ITmedia PC USER / 2024年11月24日 0時0分
-
5【格安スマホまとめ】povo2.0、ローソンに行くと月1GB貰える! コラボが本格スタート
ASCII.jp / 2024年11月24日 15時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





